







文章目录
1.介绍
Go Fiber是一个轻量级的Web框架,专注于提供快速、灵活和高性能的HTTP处理。它基于Go语言的Fasthttp服务器引擎构建,因此具有出色的性能和低内存消耗。
同时Fiber的路由树是线性的路由栈,所以Fiber路由支持路径的正则匹配,相对gin、go-zero更加灵活。
2. Fiber路由解析
2.1 添加路由
路由结构体
type Route struct {
pos uint32 // 处于路由栈的位置
use bool // 是否为中间件
mount bool // Indicated a mounted app on a specific route
star bool // 是否可匹配所有路径
root bool //是否为根路径
path string // 美化的路由路径
routeParser routeParser // 路径解析器
group *Group // Group instance. used for routes in groups
//nolint:revive // Having both a Path (uppercase) and a path (lowercase) is fine
Path string `json:"path"` // 原始路径
Params []string `json:"params"` // 路径参数
Handlers []Handler `json:"-"` // 所有的处理器
}
路由接口
type Router interface {
Use(args ...interface{}) Router
Get(path string, handlers ...Handler) Router
Head(path string, handlers ...Handler) Router
......
Add(method, path string, handlers ...Handler) Router
......
}
在fiber中有两个对象实现了Router接口
- fiber.App:几乎每个添加路由的操作,都只是对Add方法的形参填充,而Add底层实际就是register路由的操作
func (app *App) Get(path string, handlers ...Handler) Router { return app.Head(path, handlers...).Add(MethodGet, path, handlers...) }
- fiber.Group:group只是在App的基础上进行路径参数修饰,无其他特别处理
func (grp *Group) Get(path string, handlers ...Handler) Router { grp.Add(MethodHead, path, handlers...) return grp.Add(MethodGet, path, handlers...) }
- 调用Group方法注册的路由,会被定义为 isuse=true,即为中间件,所以只要路径匹配的上,即会被执行
func (app *App) Group(prefix string, handlers ...Handler) Router { grp := &Group{Prefix: prefix, app: app} if len(handlers) > 0 { app.register(methodUse, prefix, grp, handlers...) } ...... }
2.2 注册路由
func (app *App) register(method, pathRaw string, group *Group, handlers ...Handler) {
//此处主要判断请求方式是否合法,请求路径是否合法,保证路径第一字符为'/',是否路径匹配忽略大小写等
......
// 创建路径副本,判断是否转全小写,去除后缀'/',判断是否为路由中间件
pathPretty := pathRaw
......
//是否为中间件?
isUse := method == methodUse
// 是否为根路径通配符
isStar := pathPretty == "/*"
// 是否为根路径
isRoot := pathPretty == "/"
// 解析路径参数
parsedRaw := parseRoute(pathRaw)
parsedPretty := parseRoute(pathPretty)
route := Route{
use: isUse,
mount: isMount,
star: isStar,
root: isRoot,
path: RemoveEscapeChar(pathPretty),
routeParser: parsedPretty,
Params: parsedRaw.params,
group: group,
Path: pathRaw,
Method: method,
Handlers: handlers,
}
// 增加全局的handler数量
atomic.AddUint32(&app.handlersCount, uint32(len(handlers)))
//判断是否为中间件
if isUse {
//将该路由添加进所有指定http方法的路由栈中
for _, m := range app.config.RequestMethods {
r := route
app.addRoute(m, &r, isMount)
}
} else {
app.addRoute(method, &route, isMount)
}
}
func (app *App) addRoute(method string, route *Route, isMounted ...bool) {
......
// 根据请求方法类型获取指定的路由栈
l := len(app.stack[m])
//判断待添加路由是否与当前路由栈的最后一个路由、是否路径相同、是否都为中间件、是否都为挂载
if l > 0 && app.stack[m][l-1].Path == route.Path && route.use == app.stack[m][l-1].use && !route.mount && !app.stack[m][l-1].mount {
//匹配相同,把待添加的路由的所有hanlder追加到最后一个路由的hanlder切片中
preRoute := app.stack[m][l-1]
preRoute.Handlers = append(preRoute.Handlers, route.Handlers...)
} else {
//匹配失败,
route.pos = atomic.AddUint32(&app.routesCount, 1)
route.Method = method
//将待添加路由追加到路由栈尾部
app.stack[m] = append(app.stack[m], route)
app.routesRefreshed = true
}
// Execute onRoute hooks & change latestRoute if not adding mounted route
if !mounted {
app.mutex.Lock()
app.latestRoute = route
if err := app.hooks.executeOnRouteHooks(*route); err != nil {
panic(err)
}
app.mutex.Unlock()
}
}
注意:如果连续调用多次注册路由,相同路径的hanlder有可能会被分配到同一个路由,也有可能分裂到多个路由,取决于调用的先后顺序
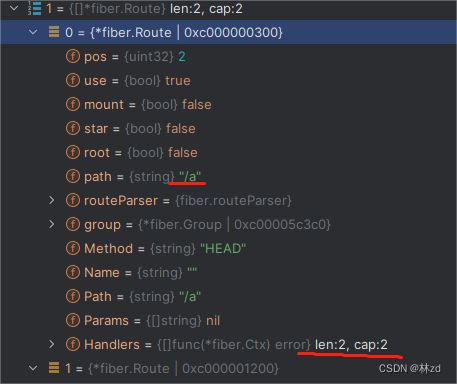
- 同一个
tmp:= func(ctx *fiber.Ctx) error { return nil } group1 := app.Group("/a",tmp) app.Group("/a", tmp) app.Group("/b", tmp)
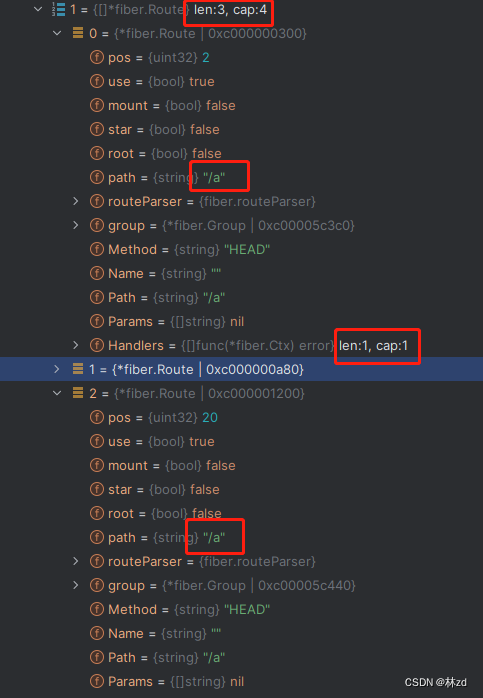
- 不同个
tmp := func(ctx *fiber.Ctx) error { return nil } group1 := app.Group("/a", tmp) app.Group("/b", tmp) app.Group("/a", tmp)
3. Fasthttp解析
3.1 介绍
fasthttp 是为一些高性能边缘情况而设计的。除非您的服务器/客户端需要每秒处理数千个中小型请求,并且需要一致的低毫秒响应时间,否则 fasthttp 可能不适合您。对于大多数情况来说net/http要好得多,因为它更容易使用并且可以处理更多情况。在大多数情况下,您甚至不会注意到性能差异。
3.2 fasthttp vs net/http
- net/http接收一个连接就会新起一个goroutine去处理,连接关闭后goroutine就结束,fasthttp则是对goroutine进行反复利用,处理完一个连接任务后会接收下一个连接进行处理,减少了goroutine创建以及垃圾回收的影响带来的性能问题。
- fasthttp采用零拷贝即指针转换进行string->[]byte的数据转换,减少内存分配,减少gc压力
- fasthttp会采用sync.Pool反复利用对象资源,减少Ctx对象指针的产生
3.3 调用关系图
3.3 fasthttp 连接传递解析
工作池结构体
type workerPool struct {
// Function for serving server connections.
// It must leave c unclosed.
WorkerFunc ServeHandler //func(ctx *RequestCtx)类型,会传递请求体、响应体等对象信息,可由第三方框架实现接入自定义的请求处理逻辑
MaxWorkersCount int //最大并发数
LogAllErrors bool
MaxIdleWorkerDuration time.Duration //worker最大闲置时间,默认超过10秒工作协程就会被清扫协程关闭
Logger Logger
lock sync.Mutex //保证该结构体的并发安全
workersCount int //当前处于活跃的worker数量
mustStop bool
ready []*workerChan //这是个就绪队列。存储着与活跃worker的通信方式。
stopCh chan struct{}
workerChanPool sync.Pool //回收或新建与worker的通信channel,减少内存分配
connState func(net.Conn, ConnState)
}
//该结构体有两个字段,一个是上次任务的结束时间,一个是与活跃worker的通信channel
//清扫协程会依靠这两个字段来判定worker是否关闭,是的话会通过传递一个nil接口通知worker结束循环阻塞从而结束协程
type workerChan struct {
lastUseTime time.Time
ch chan net.Conn
}
开启服务
func (s *Server) Serve(ln net.Listener) error {
//进行监听连接前的参数初始化,如获取最大并发数等
...
wp := &workerPool{
//s.serveConn会将从连接处获取的request、response、header等信息,
//并将这些数据传给Fiber实现的func(ctx *RequestCtx)方法,从而达到由Fiber接管完成路由匹配、请求逻辑处理等剩余操作,最后再由fasthttp把结果进行返回
WorkerFunc: s.serveConn,
MaxWorkersCount: maxWorkersCount,
LogAllErrors: s.LogAllErrors,
MaxIdleWorkerDuration: s.MaxIdleWorkerDuration,
Logger: s.logger(),
connState: s.setState,
}
//Start会初始化与worker的通信channel池,后续会将连接通过channel传递给worker,并开启一个清扫协程
wp.Start()
......
for {
//接收连接
if c, err = acceptConn(s, ln, &lastPerIPErrorTime); err != nil {
wp.Stop()
if err == io.EOF {
return nil
}
return err
}
s.setState(c, StateNew)
atomic.AddInt32(&s.open, 1)
//尝试将连接传递给worker
if !wp.Serve(c) {
//该代码块主要是应对并发数达到最大值进行连接关闭以及进行睡眠缓冲等操作
......
}
c = nil
}
}
清扫协程
func (wp *workerPool) clean(scratch *[]*workerChan) {
maxIdleWorkerDuration := wp.getMaxIdleWorkerDuration()
//获取当前时间,在后续二分查找定位空闲时间大于最大等待时间的worker
criticalTime := time.Now().Add(-maxIdleWorkerDuration)
wp.lock.Lock()
//生成就绪队列的结构副本,底层数据仍是同一块内存
ready := wp.ready
n := len(ready)
//因为就绪队列的元素是有序追加的,元素是与worker通信的channel,早进入等待的channel在前
//可以通过二分查询定位出最晚超过最大等待时间的channel的索引号
l, r, mid := 0, n-1, 0
for l <= r {
mid = (l + r) / 2
if criticalTime.After(wp.ready[mid].lastUseTime) {
l = mid + 1
} else {
r = mid - 1
}
}
//i为最晚达到最大空间时间的索引位
i := r
if i == -1 {
wp.lock.Unlock()
return
}
//将要清理的worker 信道追加到可重复使用的缓冲区,从缓存区的0索引位开始填充
*scratch = append((*scratch)[:0], ready[:i+1]...)
//将要留存的worker 信道往队列前部分进行覆盖
m := copy(ready, ready[i+1:])
//将多余的位置进行取零值处理
for i = m; i < n; i++ {
ready[i] = nil
}
//因底层实际指向同一块内存,该操作相当于仅修改wp.ready的长度
wp.ready = ready[:m]
wp.lock.Unlock()
//通知达到最大等待时间的worker关闭等待,即结束goroutine
tmp := *scratch
for i := range tmp {
tmp[i].ch <- nil
tmp[i] = nil
}
}
尝试进行任务传递
func (wp *workerPool) Serve(c net.Conn) bool {
//尝试获取与worker通信的信道 channel
ch := wp.getCh()
if ch == nil {
return false
}
//成功获取,将连接传递给正在监听等待的worker
ch.ch <- c
return true
}
尝试获取与就绪worker的通信
func (wp *workerPool) getCh() *workerChan {
var ch *workerChan
createWorker := false
wp.lock.Lock()
//从就绪队列中获取与worker通信的信道
ready := wp.ready
n := len(ready) - 1
if n < 0 {
//无空闲的worker,判断是否有条件创建新的worker,即判断已创建的worker是否小于最大并发数
if wp.workersCount < wp.MaxWorkersCount {
createWorker = true
wp.workersCount++
}
} else {
//成功拿到与正处于就绪worker的信道
ch = ready[n]
ready[n] = nil
wp.ready = ready[:n]
}
wp.lock.Unlock()
if ch == nil {
if !createWorker {
//获取通信失败
return nil
}
//有条件创建新worker
vch := wp.workerChanPool.Get()
ch = vch.(*workerChan)
go func() {
wp.workerFunc(ch)
//worker关闭后将通信channel放到池子进行复用,减少内存分配
wp.workerChanPool.Put(vch)
}()
}
return ch
}
worker协程工作内容
func (wp *workerPool) workerFunc(ch *workerChan) {
var c net.Conn
var err error
//接收任务
for c = range ch.ch {
//如果接收为nil,则代表该worker的空闲时间达到了默认最大空闲时间,清扫协程发送了关闭通知
if c == nil {
break
}
//会进入请求的实际处理流程,会调用(s *Server) serveConn方法,从而调用RequestHandler func(ctx *RequestCtx)进入逻辑处理流程
if err = wp.WorkerFunc(c); err != nil && err != errHijacked {
......
}
......
//记录当前worker处理完任务的时间,并把通信channel放回就绪队列中
if !wp.release(ch) {
break
}
}
......
}
func (s *Server) serveConn(c net.Conn) (err error) {
......
//将请求内容交由该控制器进行处理,作为第三方框架接入的入口
if continueReadingRequest {
s.Handler(ctx)
}
......
return
}
4. Fiber如何基于fasthttp处理请求
4.1 Fiber启动流程
创建fiber.App
func New(config ...Config) *App {
//进行一系列的参数初始化
......
// 该方法是关键,app对象包含着fasthttp.Server对象,该方法是对server对象的参数填充。
app.init()
return app
}
对fasthttp.Server对象进行初始化
func (app *App) init() *App {
......
// 创建fasthttp.Server
app.server = &fasthttp.Server{
Logger: &disableLogger{},
LogAllErrors: false,
ErrorHandler: app.serverErrorHandler,
}
//将fiber.App实现的 func(ctx *RequestCtx)类型方法指针赋值给server,后续由fasthttp进行回调,将请求的处理权交给fiber
app.server.Handler = app.handler
//对fasthttp的最大并发大小、超时时间、请求体大小等参数进行初始化设置
......
return app
}
启动fiber,随后fasthttp也将如fasthttp解析所描述地流转起来
func (app *App) Listen(addr string) error {
......
//此处fiber会基于已经添加的路由,创建一颗内存路由树,供后续请求进行匹配
app.startupProcess()
//打印操作
......
//此处也正式开启fasthttp
return app.server.Serve(ln)
}
fasthttp会在此处对fiber实现的RequestHandler类型方法进行回调,从而由fiber接手对请求的处理
func (app *App) handler(rctx *fasthttp.RequestCtx) {
// 为了节省内存分配,对上下文对象*Ctx进行复用,由sync.Pool管理,该对象存储着fiber的元数据以及请求内容等
c := app.AcquireCtx(rctx)
// 进入路由匹配
match, err := app.next(c)
if err != nil {
if catch := c.app.ErrorHandler(c, err); catch != nil {
_ = c.SendStatus(StatusInternalServerError)
}
}
//将*Ctx放回池子
app.ReleaseCtx(c)
}
路由匹配以及hanlder的执行
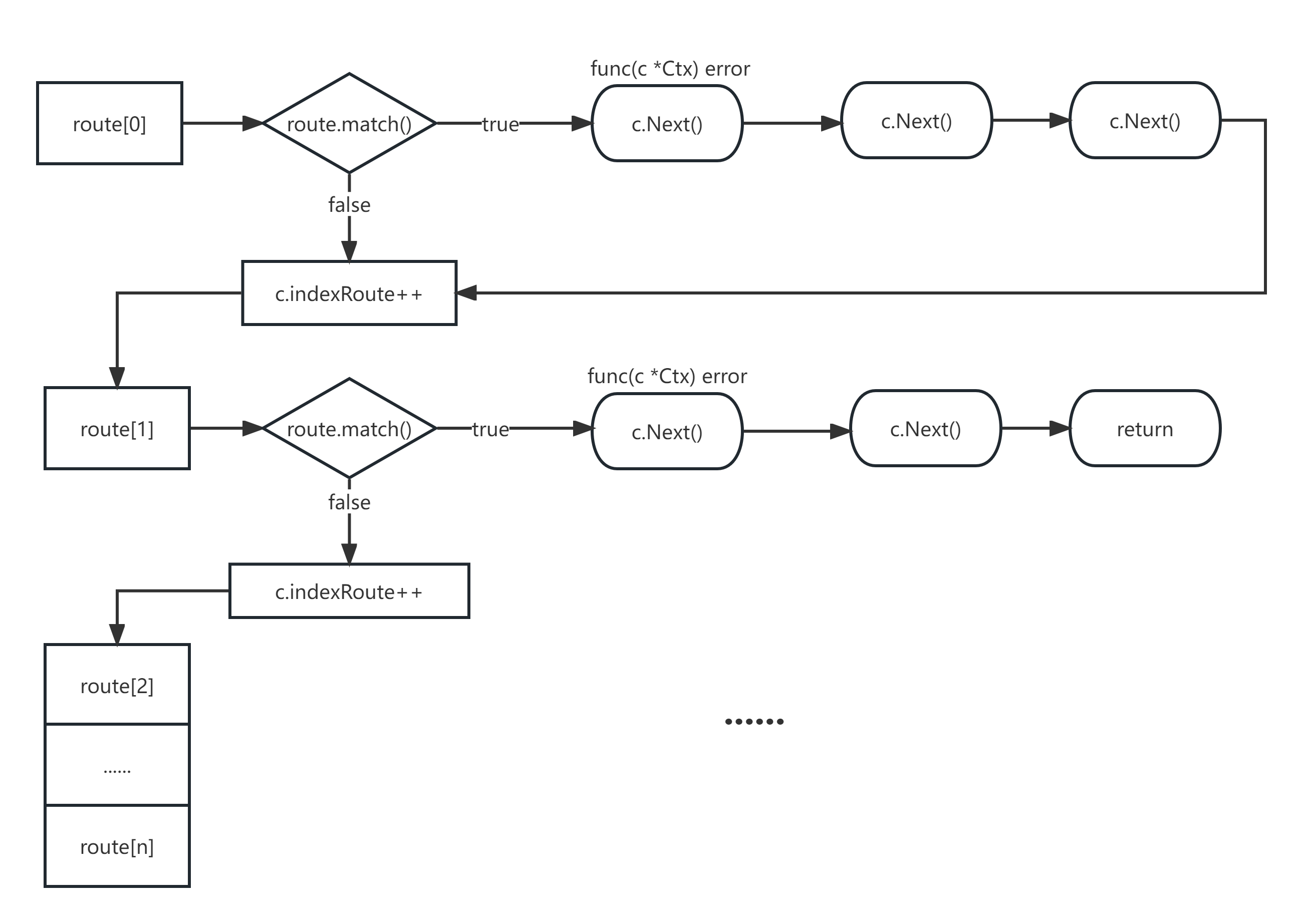
func (app *App) next(c *Ctx) (match bool, err error) {
//通过请求方式+路径前缀获取路由栈
tree, ok := app.treeStack[c.methodINT][c.treePath]
if !ok {
tree = app.treeStack[c.methodINT][""]
}
lenr := len(tree) - 1
//开始遍历路由栈
for c.indexRoute < lenr {
c.indexRoute++
// 获取当前索引位置的路由
route := tree[c.indexRoute]
// 判断当前路由与路径是否匹配、是否为中间件
match = route.match(c.detectionPath, c.path, &c.values)
// 如果匹配不成功,则对下一个路由进行匹配
if !match {
continue
}
//将路由存储到上下文Ctx
c.route = route
// 修改标志,表示该请求匹配到了非中间件的路由
if !c.matched && !route.use {
c.matched = true
}
//获取路由的第一个hanlder进行执行
//如果hanlder中调用了c.Next,则会执行路由的下一个handler或进行下一个路由的匹配
c.indexHandler = 0
err = route.Handlers[0](c)
return match, err //结果返回
}
//如果结束了路由栈的遍历,即使中途匹配到了非中间件的hanlder,也会被判定为404
//所以要拒绝毫无目的且无止境的c.Next
err = NewError(StatusNotFound, "Cannot "+c.method+" "+c.pathOriginal)
//如果未匹配到,则扫描其他请求方式的路由栈是否存在与该请求相符的路由,是的话则判定为错误的请求方式
if !c.matched && methodExist(c) {
err = ErrMethodNotAllowed
}
return
}
//一般在中间件handler中调用
func (c *Ctx) Next() (err error) {
c.indexHandler++
// 判断是否执行到当前路由的最后一个handler
if c.indexHandler < len(c.route.Handlers) {
// 否:执行当前路由的下一个handler
err = c.route.Handlers[c.indexHandler](c)
} else {
// 是:继续遍历路由栈
_, err = c.app.next(c)
}
return err
}
4.2 为什么Fiber不使用Trie tree
基于前面的讲解,我们也知道fiber实现的路由并不是常见前缀树或者基数树,而是切片,fiber的开发者是这么认为的,对于一个http请求,即使你的程序存在成百上千个route,最终完成的匹配时长都是在纳秒级别,远远比不上请求中进行一次IO操作,而是用切片路由栈更加灵活,可以完成路由的正则匹配,使得一次请求可以成功匹配多次路由,增大了路由的可复用性。像gin或者go-zero都是一个请求只能匹配成功一个路由,也代表者相同的handler会重复出现在不同的route中。
同时,fasthttp并不适用于短时间接收大量瞬时结束的请求的场景,这也会使fasthttp退化成http/net甚至更差,也起不到协程复用的初衷,所以fiber将路由选择为更加灵活易懂的切片路由栈














 2648
2648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









