







文章目录
导入模块/包
本质上模块和包一样,都是把一些特定功能的代码封装在一起,方便我们访问和使用。
模块其实就是我们把一些公用的功能代码写入在一个py文件中,在其他模块中可以随意的使用该文件中的代码。导入一个模块的语法:
import 模块
from 模块 import 功能
time模块
一般使用time模块让程序休息n秒,或者计算简单的时间差。
import time
# 控制程序执行的频率
print(1)
time.sleep(3) # 让程序睡3秒
# 简单的计算时间差
start = time.time() # 当前系统时间,从1970年1月1日0点0份0秒开始到现在经过了多少秒
for i in range(10000):
print(i)
end = time.time()
print(end - start)
datetime模块
在后期我们处理时间的时候会经常使用datetime来处理。
必须掌握的内容:
now() 系统时间
datetime(year, month, day, hour, min, second)
strftime(“%Y-%m-%d %H:%M:%S”) 把时间格式化成字符串
strptime(str, “%Y-%m-%d %H:%M:%S”) 把字符串转化为时间
date.today() 今天的日期
from datetime import datetime
# 今天的日期时间
today = datetime.today()
print(today) # 2023-06-01 10:42:38.768463
当前系统时间
now = datetime.now()
print(now) # 2023-06-01 10:42:38.768463
# 格林尼治时间,和我们相差8小时
utc = datetime.utcnow()
print(utc) # 2023-06-01 02:42:38.768463
# 用指定的时间创建datetime
d = datetime(2023, 6, 1, 10, 40, 8, 3553)
print(d) # 2023-06-01 10:40:08.003553
# 时间格式化(datetime>>str)
dt = datetime.now()
print(type(dt))
str_date = dt.strftime('%Y-%m-%d %H:%M:%S')
print(str_date) # 2023-06-01 10:42:38
print(type(str_date)) # <class 'str'>
# 字符串转化为时间
str_date = '2023-06-01 10:46:00'
dt = datetime.strptime(str_date, '%Y-%m-%d %H:%M:%S') # p:parse
print(dt) # 2023-06-01 10:46:00
print(type(dt)) # <class 'datetime.datetime'>
# 计算时间差
d1 = datetime(2023, 6, 1, 12, 0, 0)
d2 = datetime(2023, 6, 8, 14, 0, 0)
diff = d2 - d1
print(diff.days) # 7
print(diff.seconds) # 7200(=2h) 单纯从时分秒来计算
print(diff.total_seconds()) # 612000.0 包括年月日计算
日期格式化的标准:
| 格式 | 含义 |
|---|---|
| %y | 两位数的年份表示(00-99) |
| %Y | 四位数的年份表示(000-9999) |
| %m | 月份(01-12) |
| %d | 月内中的一天(0-31) |
| %H | 24小时制小时数(0-23) |
| %I | 12小时制小时数(01-12) |
| %M | 分钟数(00-59) |
| %S | 秒(00-59) |
| %a | 本地简化星期名称 |
| %A | 本地完整星期名称 |
| %b | 本地简化的月份名称 |
| %B | 本地完整的月份名称 |
| %c | 本地相应的日期表示和时间表示 |
| %j | 年内的一天(001-366) |
| %p | 本地A.M.或P.M.的等价符 |
| %U | 一年中的星期数(00-53)星期天为星期的开始 |
| %w | 星期(0-6),星期天为星期的开始 |
| %W | 一年中的星期数(00-53) 星期一为星期的开始 |
| %x | 本地相应的日期表示 |
| %X | 本地相应的时间表示 |
random模块
python中专门用来产生随机数的一个模块。
import random
# 随机数[0, 1)
print(random.random()) # 0.7444044141423838
# 随机小数[10, 20)
print(random.uniform(10, 20)) # 18.843507890117074
# 随机整数[10, 20]
print(random.randint(10, 20)) # 16
lst = ['a', 'b', 'c', 'd', 'e']
# 从列表中随机选1个
print(random.choice(lst)) # e
# 从列表中随机选n个
print(random.sample(lst, 3)) # ['b', 'a', 'e']
# 打乱一个列表
random.shuffle(lst)
print(lst) # ['e', 'd', 'a', 'b', 'c']
练习题:随机生成四位验证码
import random
def rand_num():
return str(random.randint(0, 9))
def rand_upper():
return chr(random.randint(65, 90))
def rand_lower():
return chr(random.randint(97, 122))
def rand_verifyCode(n=4):
lst = []
for i in range(n):
type = random.randint(1, 3)
if type == 1: # 随机数字
s = rand_num()
elif type == 2:
s = rand_upper()
elif type == 3:
s = rand_lower()
lst.append(s)
return ''.join(lst)
print(rand_verifyCode()) # 1qz2
序列化-pickle模块
pickle把变量(对象)打散成字节,进行传输和存储
dumps():把对象处理成字节,序列化
loads():把字节还原回对象,反序列化
dump()/load():直接处理文件
pickle处理的都是字节。
import pickle
arr = [1, 2, 3]
bs = pickle.dumps(arr) # 序列化
print(bs) # b'\x80\x03]q\x00(K\x01K\x02K\x03e.'
with open('txts_dir/arr.dat', mode='wb') as f:
f.write(bs)
# 把数据还原回来
f = open('txts_dir/arr.dat', mode='rb')
content = f.read()
print(content) # b'\x80\x03]q\x00(K\x01K\x02K\x03e.'
# 反序列化,还原成正常的对象
r = pickle.loads(content)
print(r) # [1, 2, 3]
f.close()
# 以下内容直接操纵文件
# 写序列文件
f = open('txts_dir/abc.dat', mode='wb')
data = ['a', 'b', 'c']
pickle.dump(data, f) # 直接把对象序列化存储到文件中
f.close()
# 直接从文件中读取字节,反序列化成对象
f = open('txts_dir/abc.dat', mode='rb')
r = pickle.load(f)
print(r) # ['a', 'b', 'c']
f.close()
序列化-json模块
json把变量(对象)处理成json字符串,进行传输和存储。
json的概念是web前端的概念(javascript),它本质是一个字符串;
json模块 >> python提供的一个专门处理json字符串的一个模块。
json.dumps(对象):把python对象转化成json字符串,序列化
json.loads(字符串):把json字符串还原成python字典,反序列化
dump()/load():直接处理文件
import json
dict = {
'name': 'Bob',
'age': 36,
'married': True,
'child': None,
'retire': False,
'wife': {
'name': 'Lily',
'age': 32
}
}
s = json.dumps(dict, ensure_ascii=False) # 把python字典,序列化成json字符串(注意:true/false/null -- javascript语法,json统一的规则)
print(s)
print(type(s))
d = json.loads(s) # 把json字符串还原成python字典
print(d)
print(type(d))
结果如下:

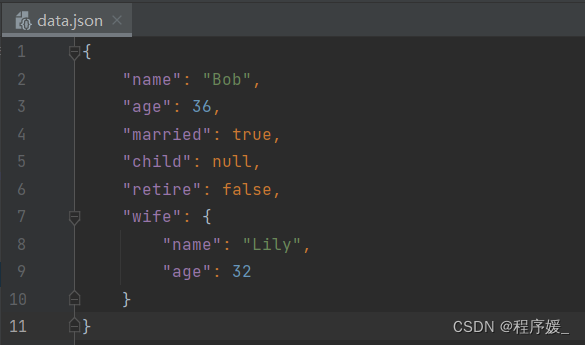
# 直接处理以上data.json文件
import json
r = json.load(open('./Data/data.json', mode='r', encoding='utf-8'))
print(r)
print(type(r))
结果如下:

hashlib模块
hashlib模块的功能
python的hashlib提供了常见的摘要算法,如MD5, SHA1等。(封装一些用于加密的类)
摘要算法:又称哈希算法、散列算法。它是通过一个函数,把任意长度的数据转换成一个长度固定的数据串(通常用16进制的字符串表示。)
摘要算法的本质:通过摘要函数对任意长度的data计算出固定长度的摘要digest。
摘要算法的目的:为了发现原始数据是否被人篡改过。
摘要算法的特点:
1. 摘要函数是一个单向函数,计算data的摘要digest很容易,但是通过digest反推data却非常难。(单向加密,理论不可逆)
2. 对原始数据做一个bite的修改,都会导致数据算出的digest完全不同。(原数据的一点小变化,将导致结果非常大的差异,“雪崩效应”)
使用hashlib模块
使用hashlib加密算法的4大步骤:
- 在python中引用hashlib模块;
- 创建一个hash对象(使用hash算命命名的构造函数/通用构造函数);
- 使用hash对象的update()方法进行加密,可以调用多次;
- 调用digest()或hexdigest()方法获取摘要(加密结果);
实例代码:
# 1 引用hashlib模块
import hashlib
# 2 创建一个hash对象
md5 = hashlib.md5()
# 3 使用hash对象的update()方法进行加密
s = '加密内容'
md5.update(s.encode('utf-8'))
# 4 调用digest()或hexdigest()方法获取加密结果
res = md5.digest() # 字节对象 digest: b'"\x0b\xe5[.=\x8e`\xf9!K\x04\xa7\xa22\x8f'
print('digest: ', res)
res2 = md5.hexdigest() # 字符串对象 hexdigest: 220be55b2e3d8e60f9214b04a7a2328f
print('hexdigest: ', res2)
hashlib的应用
- 密码验证
所有允许用户登录的网站都会将用户登录的用户名和密码存储在数据库中。如果以明文保存用户口令,如果数据库泄漏,所有用户的口令就落入黑客的手中。此外,网站运维人员是可以访问数据库的,也可以获取到所有用户的口令。保存口令的正确方式不是存储用户的明文密码,而是存储用户密码的摘要,比如md5。 - 文件校验
可以在文件传输时,验证文件是否被完整接收,这用到的是hashlib的“相同字符串的摘要一致”原理。如果摘要一致,说明文件传输完成,否则就是文件在传输过程中丢帧。 - 加盐
考虑到有这种情况,就是有些用户喜欢用“123456”、“888888”等一些简单的口令,于是,黑客可以事先计算出这些常见口令的md5值,得到一个反推表。这样,无需破解,只需要对比数据库的md5,黑客就获得了使用常用口令的用户帐号。对于用户来说,当然不要使用过于简单的口令。同时,我们在程序设计上对简单口令加强保护。由于常用口令的md5值很容易被计算出来,所以,要确保存储都的用户密码不是那些已经被计算出来的常用口令的md5。这一方法通过对原始口令加一个复杂字符串来实现,俗成“加盐”:hashlib.md5("salt".encode("utf-8"))
经过"salt"处理的md5口令,只要“salt"不被黑客知道,即使用户输入简单口令,也很难通过md5反推明文口令。
通过hashlib实现简单登录验证
import hashlib
def getMd5(username, password):
m = hashlib.md5()
m.update(username.encode('utf-8'))
m.update(password.encode('utf-8'))
return m.hexdigest()
def register(username, password):
res = getMd5(username, password)
with open('userInfo.txt', 'at', encoding='utf-8') as f:
f.write(res+'\n')
def login(username, password):
res = getMd5(username, password)
with open('userInfo.txt', 'rt', encoding='utf-8') as f:
for line in f:
if res == line.strip():
return True
else:
return False
while True:
print(''.center(50, '-'))
try:
op = int(input('1.注册\t2.登录\t3.退出\t\n请输入:'))
except ValueError:
print('输入有误')
continue
if op == 1:
username = input('请输入用户名:')
password = input('请输入密码:')
register(username, password)
elif op == 2:
username = input('请输入用户名:')
password = input('请输入密码:')
res = login(username, password)
if res:
print('登录成功')
else:
print('登录失败')
elif op == 3:
break
else:
print('输入有误')
continue
运行结果如下:
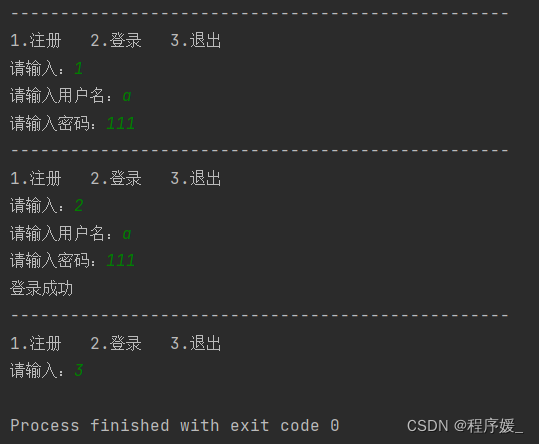
logging模块
logging模块,自动帮你划分了一些日志等级:
| 错误 | 备注 |
|---|---|
| logging.CRITICAL | 最高级别的错误 level=50 |
| logging.ERROR | 普通错误 level=40 |
| logging.WARNING | 警告 level=30 |
| logging.INFO | 信息 level=20 |
| logging.DEBUG | 最详细 level=10 |
import logging
# 基础配置
logging.basicConfig(filename='logging.txt',
format='%(asctime)s - %(name)s - %(levelname)s - %(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
level=40) # level多少分以上的错误信息会写入到日志当中。
logging.error('出error了!')
logging.warning('警告!') # 日志设置是40分以上,此时warning(30)级别不够
logging.log(41, '自行打log') # 不推荐
运行后的logging.txt如下:

常用于输出错误日志(错误仅显示在log文件中,控制台不再报错):
# 完整的错误处理逻辑
import logging
import traceback
logging.basicConfig(filename='logging.txt',
format='%(asctime)s - %(name)s - %(levelname)s - %(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
level=40) # level多少分以上的错误信息会写入到日志当中。
try:
print(1/0)
except Exception as e:
logging.error(traceback.format_exc()) # 记录错误信息
运行后的logging.txt如下:

异常处理
异常处理,处理的是程序运行时的一些意外情况。如果异常不处理,程序会中断。
try ... except 语句:
try:
xxx
except 类型 as e:
xxx
except 类型 as e:
xxx
finally:
xxx 不论是否会报错,最终要执行的代码
尝试运行一段代码,如果不出错,就正常结束;如果出错,自动运行except中的内容。
try:
a = int(input(">>>:"))
b = int(input(">>>:"))
print(a/b)
except ZeroDivisionError as e:
print('出小错误了!', e)
except ValueError as e:
print('出中错误了!!', e)
except Exception as e:
print('出大错误了!!!', e)
finally:
print('最终收尾。')
print('未完待续...')
运行结果如下:

def func():
try:
print(1/0)
except Exception as e:
return e
finally:
print('Done')
r = func()
print(r)
执行结果如下:

traceback模块
traceback.format_exc() :看到调调用栈(except中可以看到错误信息)
import traceback
try:
print(1/0)
except Exception as e:
print(traceback.format_exc()) # 代码调试期间用这个!
print(e)
运行结果如下:
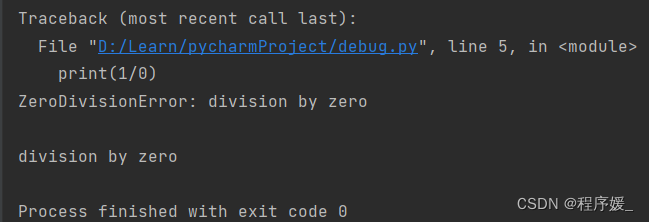
zipfile模块
ziplife是python用来做zip格式编码的压缩和解压,可以简单地把它理解为Python中的zip压缩软件。常用类:
ZipFile:用来创建和读取zip文件;
ZipInfo:存储zip文件的每个文件信息;
ZipFlie类的常用方法
-
创建ZipFile对象:
ZipFile(filename, [,mode[,compression[,allowZip64]]])
表示一个zip文件。后面要使用其它方法,前提都要在这个创建好的对象基础上操作。参数说明:
filename:文件对象。如:‘xxx.zip’
mode:可选r只读(默认)、w重写、a添加不同打开文件的方式。
compression:用什么压缩方法,默认是ZIP_SORTED,另一种是ZIP_DEFLATED.
allowZip64:是个bool型变量,当设置为True(默认值)时可以用来创建大小大于2G的文件。from zipfile import ZipFile path = 'd:/压缩文件.zip' file = ZipFile(path) file2 = ZipFile(path, 'w') file3 = ZipFile(path, 'a') print(file) # <zipfile.ZipFile filename='d:/压缩文件.zip' mode='r'> print(file2) # <zipfile.ZipFile filename='d:/压缩文件.zip' mode='w'> print(file3) # <zipfile.ZipFile filename='d:/压缩文件.zip' mode='a'> -
关闭文件:
ZipFile.close()结束时必须要有!from zipfile import ZipFile path = 'd:/压缩文件.zip' file = ZipFile(path) print(file) # <zipfile.ZipFile filename='d:/压缩文件.zip' mode='r'> file.close() print(file) # <zipfile.ZipFile [closed]> -
获取zip压缩文件内所有文件的名称列表:
ZipFile.namelist()from zipfile import ZipFile path = 'd:/压缩文件.zip' file = ZipFile(path) print(file.namelist()) # ['text1.txt', 'pic.jpeg'] -
获取zip文档内指定文件的信息,返回一个zipfile.ZipInfo对象,它包括文件的详细信息:
ZipFile.getinfo(name)from zipfile import ZipFile path = 'd:/压缩文件.zip' file = ZipFile(path) print(file.getinfo('text1.txt')) # <ZipInfo filename='text1.txt' external_attr=0x20 file_size=7> -
获取zip文档内所有文件的信息,返回一个zipfile.ZipInfo的列表:
ZipFile.infolist()from zipfile import ZipFile path = 'd:/压缩文件.zip' file = ZipFile(path) print(file.infolist()) # [<ZipInfo filename='text1.txt' external_attr=0x20 file_size=7>, <ZipInfo filename='pic.jpeg' compress_type=deflate external_attr=0x20 file_size=21494 compress_size=18710>] -
获取zip文档内指定文件解压到当前目录:
ZipFile.extract(member[, path[, pwd]])
member:指定要解压的文件名称或对应的ZipInfo对象;
path:指定解析文件保存的文件夹;
pwd:解压密码from zipfile import ZipFile path = 'd:/压缩文件.zip' file = ZipFile(path) # 将指定文件text1.txt解压到d:/目录下(运行代码之后可以看到成功解压出来了,这里没有用到pwd解压密码参数,因为压缩包没有加密。) file.extract('text1.txt', 'd:/') file.close() -
获取zip文档内所有文件解压到当前目录:
ZipFile.extractall(member[, path[, pwd]])
member:默认值为zip文档内所有文件名称列表,也可以自己设置,选择要解压的文件名称;
path:解压路径;
pwd:解压密码from zipfile import ZipFile path = 'd:/压缩文件.zip' file = ZipFile(path) # zip文档内所有文件全部解压到d:/ file.extractall( 'd:/') file.close()
re模块
参考文章:【Python】正则表达式re库
os模块
OS模块主要封装了关于操作系统文件系统的相关操作。比如。创建文件夹,删除文件夹等。
import os
os.makedirs('dirname1/dirname2') # 可生成多层递归目录。(目录已存在时无法创建)
os.removedirs('dirname1/dirname2') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依次类推。(目录非空不可删除)
os.mkdir('dirname') # 生成单级目录,相当于shell中的mkir dirname (目录已存在时无法创建)
os.rmdir('dirname') # 删除单级目录,若目录不为空则无法删除,报错;相当于shell中的rmdir dirname
dir_lst = os.listdir('Data') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
print(dir_lst)
open('dirname/filename.txt', mode='w') # 创建一个文件
os.remove('dirname/filename.txt') # 删除一个文件
os.rename('oldname', 'newname') # 重命名文件名/目录名
print(os.getcwd()) # 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir('direname') # 改变当前脚本工作目录:相当于shell下的cd
# 调用命令
os.system('dir') # 运行shell目录,直接显示(会乱码)
print(os.popen('dir').read()) # # 运行shell目录,获取执行结果(不乱码)
print(os.path.exists('path')) # 判断路径是否存在,存在返回True,否则返回False
print(os.path.isabs('path')) # 如果path是绝对路径,返回True
print(os.path.isdir('path')) # 判断是否是文件夹,是返回True,否则返回False
print(os.path.isfile('path')) # 判断是否是文件,是返回True,否则返回False
print(os.path.abspath('path')) # 返回path规范化的绝对路径
print(os.path.split('path')) # 将path分割成目录和文件名二元组返回
print(os.path.dirname('path')) # 返回path的目录。其实就是os.path.split('path')的第一个元素
print(os.path.basename('path')) # 返回path最后的文件名。如果path以/或\结尾,那么就会返回空值。即os.path.split('path')的第二个元素
print(os.path.join('C:/', 'path2', 'path3')) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略(自动使用文件系统分隔符来拼接)
print(os.path.getsize('path')) # 返回path大小
print(os.path.getatime('path')) # 返回path所指的文件/目录的最后访问时间
print(os.path.getmtime('path')) # 返回path所指的文件/目录的最后修改时间
拓展1:遍历文件夹中的内容
import os
def func(path, level):
for name in os.listdir(path):
# 拼接路径
new_path = os.path.join(path, name)
print(level * ' |---', name, sep='')
if os.path.isdir(new_path):
# 如果是文件夹,递归遍历
func(new_path, level + 1)
func('./', 1)
拓展2:创建文件的正确流程
import os
def create_file(path, cover):
# 先处理路径
dirname = os.path.dirname(path)
if not os.path.exists(dirname):
os.makedirs(dirname)
if os.path.exists(path):
if cover:
open(path, mode='w').close()
else:
return # 文件已存在,且用户选择不覆盖
else:
open(path, mode='w').close()
create_file('./txts_dir/2.txt', True)
sys模块
所有和python解释器相关的都在sys模块。
| 格式 | 含义 |
|---|---|
| sys.argv | 命令行参数List,第一个元素是程序本身路径 |
| sys.exit(n) | 退出程序,正常退出时exit(0), 错误退出sys.exit(1) |
| sys.version | 获取python解释程序的版本信息 |
| sys.path | 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 |
| sys.platform | 返回操作系统平台名称 |
sys.path:
- python在import模块的时候,解释器是根据sys.path中给出的路径进行查找的;
- 随动的…根据你运行的那个py文件进行动态变化;
- 一定要小心,你导入的模块的路径很有可能是pycharm帮你添加的,代码移动到linux中可能出现运行不通畅的情况,只需要把sys.path补全就可以了。
import sys
print(sys.version) # 3.7.9
print(sys.platform) # win32
print(sys.path) # python用来搜索模块的,会自动的去找sys.path,返回列表
'''
sys.path.append('C:/新建文件夹')
import xxx # 导入该模块的时候,会自动去找sys.path
xxx.func()
'''
while 1:
print('123')
sys.exit(1)
sys.argv:
可以接受到命令行参数 [文件名 参数1 参数2, …]
def total(a, b):
print(f'{a}+{b}=', int(a) + int(b), sep='')
if __name__ == '__main__':
import sys
total(sys.argv[1], sys.argv[2])
print(sys.argv) # 接收到的就是程序运行时的命令行参数
运行结果如下:
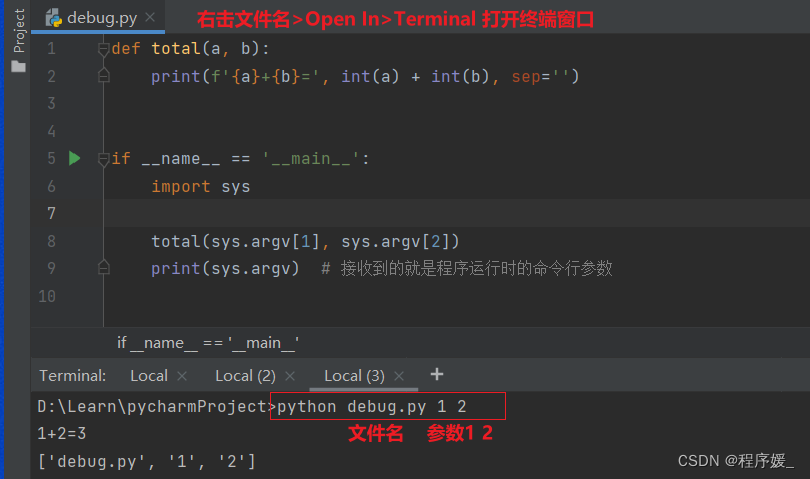















 2804
2804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









