







摘要
迭代最近点(ICP)算法通过两个步骤迭代地解决刚性点云配准问题:(1)进行空间上最近点对应的硬分配,然后(2)找到最小二乘刚性变换。基于空间距离的最近点对应的硬分配对初始刚性变换和噪声/离群点非常敏感,这通常会导致ICP收敛到错误的局部最小值。在本文中,我们提出了RPM-Net——一种对初始化不敏感且更稳健的基于深度学习的刚性点云配准方法。为此,我们的网络使用可微分的Sinkhorn层和退火来从空间坐标和局部几何形状中学习的混合特征中获得点对应的软分配。为了进一步提高配准性能,我们引入了一个次级网络来预测最优退火参数。与一些现有方法不同,我们的RPM-Net能够处理缺失的对应关系和部分可见的点云。实验结果表明,与现有的非深度学习方法和最近的深度学习方法相比,我们的RPM-Net达到了最先进的性能。我们的源代码可在项目网站上获得。
1.引言
刚性点云配准指的是在未知点对应关系的情况下,找到刚性变换来对齐两个给定的点云。这在计算机视觉和机器人学的许多领域都有应用,例如机器人和物体姿态估计、基于点云的里程计和地图构建等。刚性点云配准是一个“鸡和蛋”问题,需要同时解决未知点对应关系和刚性变换,以对齐点云,因此通常被称为同时姿态和对应关系问题。掌握点对应关系或刚性变换中的任何一个都可以使问题变得简单。
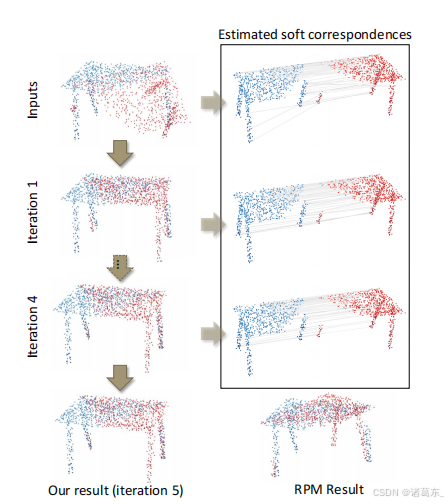
图1. 我们的RPM-Net从点的空间坐标和局部几何形状中学习的混合特征中估计软对应关系,并在5次迭代后收敛到正确的解决方案。相比之下,RPM [12]陷入了局部最小值。
ICP [3] 被广泛认为是解决刚性点云配准问题的事实标准算法。它通过交替进行两个步骤来解决点对应关系和刚性变换:(1) 将参考点云中的每个点分配给源点云中空间上最近的点,(2) 计算这些对应点之间的最小二乘刚性变换。不幸的是,ICP 对初始化非常敏感,常常收敛到错误的局部最小值。在存在噪声/离群点的情况下,它也可能会失败。这限制了ICP只能在噪声较低、无离群点且具有良好初始刚性变换的场景中使用,无法用于例如噪声扫描的配准和全局配准等应用。最近的一种基于深度学习的ICP——Deep Closest Point (DCP) [35] 从深度特征中计算点对应关系,以降低对初始化的敏感性,但它仍然对离群点不够稳健,并且在部分可见的点云上表现不佳。
许多工作 [6, 12, 33] 被提出以减轻ICP的问题,其中一个突出的工作是Robust Point Matching (RPM) [12]。它以点对应关系的软分配开始,通过确定性退火逐渐强化分配。正如我们在实验中所展示的,尽管RPM比ICP更稳健,但由于点对应关系仍然仅仅基于空间距离,因此它仍对初始化和局部最小值敏感。另一方面,基于特征的方法 [26, 28, 32] 通过检测独特的关键点并使用特征描述符描述关键点的局部几何形状,避免了初始化和局部最小值问题。然后,一个点云中的特征描述符可以与另一个点云中的特征描述符匹配,并使用RANSAC方案稳健地解决刚性变换。然而,这些方法仅对具有独特几何结构的点云有效 [30]。
在本文中,我们提出了一种基于深度学习的RPM,即RPM-Net:一个端到端可微的深度网络,它保持了RPM对噪声/离群点的鲁棒性,同时通过从学习的特征距离而非空间距离中获得点对应关系来降低对初始化的敏感性。为此,我们设计了一个特征提取网络,从每个点的空间坐标和几何属性中计算混合特征,然后使用Sinkhorn [31]层和退火从这些混合特征中获得点对应关系的软分配。空间坐标和几何属性的融合以及从数据中学习改进了点对应关系,从而降低了初始化的敏感性,并增强了配准缺失对应关系和部分可见点云的能力。与ICP及其大多数变种类似,我们的RPM-Net通过迭代精细化刚性点云配准。此外,我们引入了一个次级网络,根据当前对齐状态预测最佳退火参数,即我们的退火不遵循固定的计划。结合混合特征的使用,我们的算法可以在少数几次迭代中收敛,如图1所示的例子所示。实验表明,与现有的非深度学习和最近的深度学习方法相比,我们的RPM-Net达到了最先进的性能。我们的主要贡献是:
- 通过特征提取网络、Sinkhorn层和退火来学习混合特征,从而降低初始化的敏感性并增强刚性点云配准的鲁棒性。
- 引入次级网络以预测最佳退火参数。
- 提出了一种改进的Chamfer距离度量,以在存在对称性或部分可见性的情况下改进配准质量的测量。
- 在干净、噪声和部分可见的数据集上进行实验评估,显示出与其他现有工作相比的最先进性能。
2.相关工作
基于特征的方法。 基于特征的方法通常采用两步策略来解决配准问题:(1) 建立两个点云之间的点对应关系,和 (2) 从这些对应关系中计算最优的变换。第一步非常复杂,需要精心设计的描述符来描述特征点,以便在点云之间进行匹配。已经提出了多种手工设计的3D特征描述符,详细的综述可以参见 [13]。通常,这些描述符根据它们的空间坐标 [9, 14, 32] 或者它们的几何属性如曲率 [4] 或法向量 [28],将测量值(通常是点的数量)积累到直方图中。为了定向空间箱子,大多数方法需要一个本地参考框架(LRF),但这通常难以明确获取,因此其他工作如PFH [27] 和FPFH [26] 设计了旋转不变的描述符,以避免对LRF的需求。更近期的工作将深度学习应用于学习这些描述符。最早的工作之一,3DMatch [42],对每个关键点周围的区域进行体素化,并使用训练过对比损失的3DCNN计算描述符。体素化会导致质量损失,因此后续的工作如PPFNet [7] 使用PointNet [23, 24] 架构直接从原始点云中学习特征。除了预测特征描述符外,3DFeat-Net [41] 和USIP [18] 还学习检测显著的关键点。基于特征的方法的主要问题在于,它们要求点云具有显著的几何结构。此外,由于生成的对应关系可能含有噪声,因此需要进行后续的稳健配准步骤(例如RANSAC),这与典型的学习框架不太匹配。
手工设计的配准方法。 最初的ICP算法 [3, 5] 通过交替估计点对应关系和找到最小化点对点 [3] 或点对面 [5] 误差的刚性变换,避免了需要特征点匹配的需求。随后的工作试图改进ICP的收敛性,例如通过选择合适的点 [10, 25] 或加权点对应关系 [11]。ICP变种的概述可以在 [25] 中找到。然而,大多数ICP变种仍然需要相对良好的初始化,以避免收敛到不良的局部最小值。一个显著的例外是Go-ICP [40],它使用分支定界方案来搜索全局最优的配准,但计算时间要长得多。另一种方法是使用软分配策略来扩大ICP的收敛区域 [6, 12, 33]。特别地,RPM [12] 使用一个软分配方案,并通过确定性退火调度逐渐“加强”每次迭代中的分配。IGSP [21] 使用一种不同的方法,在混合度量空间中测量点的相似性,该空间结合了点的空间坐标和手工设计的BSC [8] 特征。然而,作者没有学习这些特征,并且必须手工设计空间距离和特征距离之间的加权方案。我们的工作建立在RPM的迭代框架之上。然而,在其软分配阶段,我们考虑了学习到的混合特征之间的距离。此外,我们不使用预定义的退火调度,而是让网络在每次迭代中决定最佳的设置。
学习型配准方法。 近年来的研究利用深度学习改进了现有的配准方法。PointNetLK [1] 使用PointNet [23] 计算每个点云的全局表示,然后优化变换,以迭代方式最小化全局描述符之间的距离,类似于Lucas-Kanade算法 [20, 2]。后来,PCRNet [30] 通过用深度网络替换Lucas-Kanade步骤来提高抗噪声能力。Deep Closest Point [35] 提出了一种不同的方法。它为每个点提取特征,在点云之间计算软匹配,然后使用可微分的SVD模块提取刚性变换。他们还利用变换器网络 [34] 在计算特征表示时融合全局和点间信息。尽管这些方法显示出比传统方法更强大的稳健性,但上述工作无法处理部分对部分的点云配准。另一项同时进行的工作,PR-Net [36] 结合关键点检测来处理部分可见性。我们的工作采用了一种更简单的方法,与Deep Closest Point 更为相似,但不同于 [35],我们的网络通过RPM中的Sinkhorn归一化 [31] 处理离群点和部分可见性,并使用迭代推断流程实现高精度配准。
3.问题表述
给定两个点云: X = { x j ∈ R 3 ∣ j = 1 , . . . , J } X = \{ x_j \in \mathbb{R}^3 \ | \ j = 1, ..., J \} X={ xj∈R3 ∣ j=1,...,J}和 Y = { y k ∈ R 3 ∣ k = 1 , . . . , K } Y = \{ y_k \in \mathbb{R}^3 \ | \ k = 1, ..., K \} Y={ yk∈R3 ∣ k=1,...,K},我们将它们分别标记为源点云和参考点云。我们的目标是恢复未知的刚性变换 { R , t } \{ R, t \} { R,t},其中 R ∈ S O ( 3 ) R ∈ SO(3) R∈SO(3) 是一个旋转矩阵, t ∈ R 3 t ∈ R^3 t∈R3 是一个平移向量,用于将这两个点云对齐。我们假设可以轻松地从点计算出法向量。与最近的基于深度学习的相关工作 [35] 不同,我们不假设点之间有一一对应关系。两个点云可以具有不同数量的点,即 J ≠ K J ≠ K J=K,或者覆盖不同的区域范围。
4.背景:Robust Point Matching
如前所述,我们的工作基于 RPM [ 12 12 12] 的框架。本节我们简要描述算法,详细内容请参阅 [ 12 12 12]。我们定义一个匹配矩阵 M ∈ { 0 , 1 } J × K M \in \{0, 1\}^{J \times K} M∈{ 0,1}J×K 来表示点对应关系的分配,其中每个元素 m j k m_{jk} mjk 定义如下:
m j k = { 1 , 如果点 x j 对应于点 y k 0 , 否则 ( 1 ) m_{jk} = \begin{cases} 1, & \text{如果点 } x_j \text{ 对应于点 } y_k \\ 0, & \text{否则} \end{cases} \quad (1) mjk={ 1,0,如果点 xj 对应于点 yk否则(1)
首先考虑点之间存在一对一对应的情况。在这种情况下, M M M 是一个方阵。注册问题可以表述为找到最佳的刚性变换 { R , t } \{R, t\} { R,t} 和对应矩阵 M M M,使得点集 X X X 最佳地映射到点集 Y Y Y,即:
arg min M , R , t ∑ j = 1 J ∑ k = 1 K m j k ( ∥ R x j + t − y k ∥ 2 2 − α ) , ( 2 ) \arg \min_{M, R, t} \sum_{j=1}^{J} \sum_{k=1}^{K} m_{jk} \left( \|Rx_j + t - y_k\|_2^2 - \alpha \right), \quad (2) argM,R,tminj=1∑Jk=1∑Kmjk(∥Rxj+t−yk∥22−α),(2)
满足约束条件 ∑ k = 1 K m j k = 1 , ∀ j \sum_{k=1}^{K} m_{jk} = 1, \forall j ∑k=1Kmjk=1,∀j, ∑ j = 1 J m j k = 1 , ∀ k \sum_{j=1}^{J} m_{jk} = 1, \forall k ∑j=1Jmjk=1,∀k,以及 m j k ∈ { 0 , 1 } , ∀ j k m_{jk} \in \{0, 1\}, \forall jk mjk∈{ 0,1},∀jk。这些约束条件确保 M M M 是一个排列矩阵。 α \alpha α 是一个参数,用于控制拒绝为异常值的对应数量:任何距离 ∥ R x j + t − y k ∥ 2 2 < α \|Rx_j + t - y_k\|_2^2 < \alpha ∥Rxj+t−yk∥22<α 的点对 ( x j , y k ) (x_j, y_k) (xj,yk) 被视为内点,因为设置 m j k = 1 m_{jk} = 1 mjk=1 会降低方程 (2) 的成本。
在 RPM 中,排列矩阵的约束被放松为双随机约束,即每个 m j k ∈ [ 0 , 1 ] m_{jk} \in [0, 1] mjk∈[0,1]。通过确定性退火算法来最小化方程 (2),该算法在两个步骤之间迭代:(1) 软分配,和 (2) 刚性变换的估计。匹配矩阵 M M M 在软分配步骤中进行估计。为此,每个元素 m j k ∈ M m_{jk} \in M mjk∈M 首先按如下方式初始化:
m j k ← e − β ( ∥ R x j + t − y k ∥ 2 2 − α ) , ( 3 ) m_{jk} \leftarrow e^{-\beta (\|Rx_j + t - y_k\|_2^2 - \alpha)}, \quad (3) mjk←e−β(∥Rxj
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5271
5271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











