






Java 的基本数据类型以及占用的内存大小;
1、bit(电位):是计算机中存储数据的最小单元,指二进制表示的数中的一个位数,值要么是0要么是1; 2、byte(字节):字节是计算机存储容量的基本单位,一个字节由八位的二进制数组成,也就是1byte=8bit。1字节表示的二进制数转化为十进制数的大小范围是-127~128. 3、计算机基本存储容量关系 1B=8bit 1byte=8bit 1kb=1024Byte=8*1024bit 1MB=1024kb 1GB=1024MB 1TB=1024GB JAVA基本数据类型(8种) byte 1字节 整数 short 2字节 短整型 int 4字节 整型 long 8字节 长整型 float 4字节 单精度浮点小数 double 8字节 双精度浮点小数 char 2字节 字符或字符的整数编码 boolean 1字节 布尔型(值有两种:false,true)
Java 内存模型;
JVM内存模式指的是JVM的内存分区;而java内存模式是一种虚拟机规范。 Java虚拟机规范中定义了Java内存模型(JMM),用于屏蔽掉各种硬件和操作系统的内存和访问差异 ,以实现让java程序在各种平台对内存的访问都能保证效果一致的机制及规范。 JMM规范了Java虚拟机与计算机内存是如何协同工作的:规定了一个线程如何 何时可以看到由其他线程修改过后的共享变量的值,以及在必须时如何同步的访问共享变量。
线程间通信;
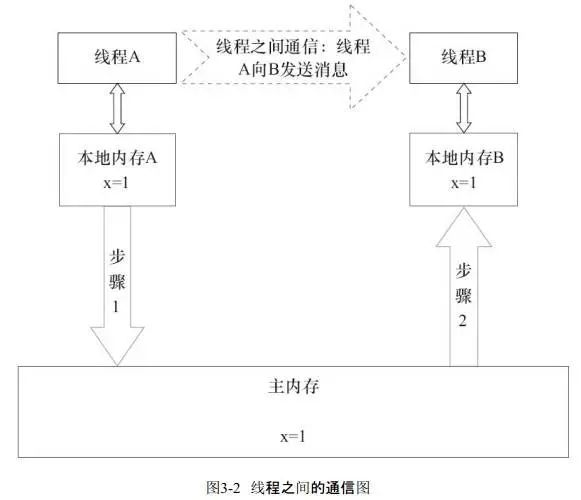
线程间通信必须要经过主内存。 如下,线程A与线程B之间要通信的话。必须要经历下面两个步骤; 1、线程A把本地内存中更新过的共享变量刷新到主内存中去。 2、线程B到主内存中去读取线程A之前已更新过的共享变量。
线程池参数以及意义;
一、四种线程池 Java通过Executors提供四种线程池,分别为 1、newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。 2、newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。 3、newScheduledThreadPool 创建一个可定期或者延时执行任务的定长线程池,支持定时及周期性任务执行。 4、newCachedThreadPool 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。 二、核心类 四种线程池本质都是创建ThreadPoolExecutor类,ThreadPoolExecutor构造参数如下 int corePoolSize, 核心线程大小 int maximumPoolSize,最大线程大小 long keepAliveTime, 超过corePoolSize的线程多久不活动被销毁时间 TimeUnit unit,时间单位 BlockingQueue<Runnable> workQueue 任务队列 ThreadFactory threadFactory 线程池工厂 RejectedExecutionHandler handler 拒绝策略 三、阻塞队列 ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列 LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列(常用) PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列 DelayQueue: 一个使用优先级队列实现的无界阻塞队列 SynchronousQueue: 一个不存储元素的阻塞队列(常用) LinkedTransferQueue: 一个由链表结构组成的无界阻塞队列 LinkedBlockingDeque: 一个由链表结构组成的双向阻塞队列
MySQL 的锁
LOCK tables orders read local,order_detail read local; SELECT SUM(total) FROM orders; SELECT SUM(subtotal) FROM order_detail; Unlock tables;
遇到并发问题该怎么办
处理高并发问题的一些方式: 1.拆表:大表拆小表(垂直拆,水平拆;分表,分区partition,分片sharding),可以在应用层实现,也可以在数据库层面实现一部分;提高系统性能。 2.分库:把表放到不同的数据库,这也是分布式数据库的基础;提高系统性能。 3.分布式:不同的数据库放到不同的服务器;提高系统性能。 4.集群:使用数据库复制等技术组建集群,实现读写分离、备份等;提高系统性能、可用性。 5.缓存:对常用的数据进行缓存。提高系统性能。 6.备份:主从库,快照,热备,异地备份等;提高系统可用性 优化的顺序是:业务、程序、部署。 业务上:要处理好应用超出负荷时的处理,比如:目前在线人过多请稍候访问之类的提示;减少图片、附件等上传的大小限制,甚至临时取消附件功能,减少带宽和存储空间的压力;分页只支持固定的分页。 程序上:包括应用的优化和数据库的优化。有可能的话尽量使用第三方的服务减少服务器自身的压力。首页等访问量大的页面静态化,减少数据库的压力,批量的实务代替时时的处理。数据库要对业务表的锁进行细化处理,读写分离。 部署上:要数据库一台,另外两台负载均衡。使用cdn(分布式网络)尽量把流量分离出去。增加防ddos(分布式拒绝服务)攻击,跳高防护的等级,减少网络攻击对普通用户的影响。 并发中的性能问题 1,有钱就堆设备 2,充分利用缓存(配合php的黑魔法fastcgi_finish_request非常好用) 并发中数据一致性问题 1,使用队列 2,必要的自动复查 3,数据库锁的合理利用 负载均衡 读写分离 缓存,分布式缓存 最基本的各种配置文件的优化是有必要的. 程序方面:数据文件缓存,内存缓存,静态缓存,opcode缓存等等 数据库方面:设计合适的表结构,表缓存优化,主从动静分离,集群,冷热数据分离等…
字符串常量池以及相关问题
String类中两种对象实例化的区别 直接赋值:只会开辟一块堆内存空间,并且该字符串对象可以自动保存在对象池(字符串常量池)中以供下次使用。 构造方法:会开辟两块堆内存空间,其中一块成为垃圾空间,不会自动保存在对象池中,可以使用 intern()方法手工入池。
网络通信协议
1,网络通信协议:是指两个(或多个)终端之间信息交换和资源共享所遵守的规则(多个客户端,手机,电脑,ipad,之间的通信需要大家都懂的语言,就相当于人与人之间的交流有中文,英文);
举例说明:
例如一个手机和一个电脑进行通信,由于这两个数据终端所用字符集不同,因此所输入的命令彼此不认识。为了能进行通信,规定每个终端都要将各自字符集中的字符先变换为标准字符集的字符后,才进入网络传送,到达目的终端之后,再变换为该终端字符集的字符。因此,网络通信协议也可以理解为网络上各台终端之间进行交流的一种语言;
2,常用的通信协议主要包括:
TCP/IP协议:
NETBEUI协议:
IPX/SPX协议:
3,我们普遍接受和使用的就是TCP/IP协议,所以我主要说说TCP/IP协议:
TCP/IP协议,共分为四层,由一组具有专业用途的多个子协议组合而成的,这些子协议包括TCP,UDP,IP,FTP,HTTP,SMTP等
网络接口层协议:Ethernet 802.3、Token Ring 802.5
网络层协议:
IP(Internet Protocol,英特网协议)
ICMP(Internet Control Message Protocol,控制报文协议)
ARP(Address Resolution Protocol,地址转换协议)
RARP(Reverse ARP,反向地址转换协议)
传输层协议:
TCP(Transmission Control Protocol,传输控制协议)
UDP(User Datagram protocol,用户数据报协议)
应用层协议:
FTP(File Transfer Protocol,文件传输协议)
HTTP(Hypertext Transfer Protocol,超文本传输协议)
SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)
TELNET(用户远程登录服务协议)
NFS(Network File System,网络文件系统)
DNS(Domain Name Service,是域名解析服务)
4,TCP 与 UDP 的区别:
(1)TCP是面向连接(如打电话要先拨号建立连接);
UDP是无连接的(即发送数据之前不需要建立连接);
(2)TCP提供可靠的传输(也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,如出现数据丢失,会进行重发);
UDP尽最大努力交付,不保证数据的完整,会出现局部数据的丢失;
(3)UDP具有较好的实时性,工作效率比TCP高,适用于高速传输和实时性要求较高的通信中;
(4)每一条TCP连接只能是点到点的;
UDP支持一对一,一对多,和多对多;
(5)TCP对系统资源要求较多;
UDP对系统资源要求较少;
我们举一个通过 IP 电话进行通话的例子。如果使用 TCP,数据在传送途中如果丢失会被重发,但这样无法流畅的传输通话人的声音,会导致无法进行正常交流。而采用 UDP,他不会进行重发处理。从而也就不会有声音大幅度延迟到达的问题。即使有部分数据丢失,也支持会影响某一小部分的通话。此外,在多播与广播通信中也是用 UDP 而不是 TCP
Spring 的 IoC; 让你写一个类似于 MyBatis 的 ORM 框架,你会怎么写;
数据库并发操作会带来哪些问题,以及如何解决(mysql)
(1)丢失更新 当两个或多个事物读入同一数据并修改,会发生丢失更新问题,即,后一个事物更新的结果被前一事物所更新覆盖 即当事务A和B同事进行时,事务A对数据已经改变但并未提交时B又对同一数据进行了修改(注意此时数据是A还未提交改变的数据),到时A做的数据改动丢失了 (2)不可重复读 当两个数据读取某个数据后,另一事务执行了对该数据的更新,当前一事务再次读取该数据(希望与第一次读取的是相同的值)时,得到的数据与前一次的不一样,这是由于第一次 读取数据后,事务B对其做了修改,导致再次读取数据时与第一次读取的数据不相同 (3)读‘脏数据’ 当一个事务修改某个数据后,另一事务对该数据进行了读取,由于某种原因前一事务撤销了对改数据的修改,即将修改过的数据恢复原值,那么后一事务读到的数据与数据可得不一致,称之为读脏数据 注意:还有一个叫“幽灵数据” 幽灵数据与脏数据类似,不过幽灵数据是指事务提交之后读到的数据,但是在读取之后又进行了对前一事务的恢复,而脏数据是指并未提交前读取的数据
MySQL 默认的隔离级别是什么
一、什么是事务 事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消。也就是事务具有原子性,一个事务中的一系列的操作要么全部成功,要么一个都不做。 事务是逻辑上的一组操作,要么都执行,要么都不执行。 事务的结束有两种,当事务中的所以步骤全部成功执行时,事务提交。如果其中一个步骤失败,将发生回滚操作,撤消撤消之前到事务开始时的所以操作。 二、事务的四个特性 (ACID)原子性,一致性,隔离性,持续性 1 、原子性。事务是数据库的逻辑工作单位,事务中包含的各操作要么都做,要么都不做 2 、一致性。事 务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。因此当数据库只包含成功事务提交的结果时,就说数据库处于一致性状态。如果数据库系统 运行中发生故障,有些事务尚未完成就被迫中断,这些未完成事务对数据库所做的修改有一部分已写入物理数据库,这时数据库就处于一种不正确的状态,或者说是 不一致的状态。 3 、隔离性。一个事务的执行不能其它事务干扰。即一个事务内部的操作及使用的数据对其它并发事务是隔离的,并发执行的各个事务之间不能互相干扰。 4 、持续性。也称永久性,指一个事务一旦提交,它对数据库中的数据的改变就应该是永久性的。接下来的其它操作或故障不应该对其执行结果有任何影响。 默认的隔离级别是什么-->可重复读(原因:保证主从复制不出问题!)
B树和B+树的区别
B树:可以将键和值存放在内部节点和叶子节点上;B+树内部节点都是键,没有值,叶子节点同时存放键和值。 B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。 使用B树的好处 B树可以在内部节点同时存储键和值,因此,把频繁访问的数据放在靠近根节点的地方将会大大提高热点数据的查询效率。这种特性使得B树在特定数据重复多次查询的场景中更加高效。 使用B+树的好处 由于B+树的内部节点只存放键,不存放值,因此,一次读取,可以在内存页中获取更多的键,有利于更快地缩小查找范围。 B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候,B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每一层进行遍历,这会需要更多的内存置换次数,因此也就需要花费更多的时间 数据库为什么使用B+树而不是B树 B树只适合随机检索,而B+树同时支持随机检索和顺序检索; B+树空间利用率更高,可减少I/O次数,磁盘读写代价更低。一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗。B+树的内部结点并没有指向关键字具体信息的指针,只是作为索引使用,其内部结点比B树小,盘块能容纳的结点中关键字数量更多,一次性读入内存中可以查找的关键字也就越多,相对的,IO读写次数也就降低了。而IO读写次数是影响索引检索效率的最大因素; B+树的查询效率更加稳定。B树搜索有可能会在非叶子结点结束,越靠近根节点的记录查找时间越短,只要找到关键字即可确定记录的存在,其性能等价于在关键字全集内做一次二分查找。而在B+树中,顺序检索比较明显,随机检索时,任何关键字的查找都必须走一条从根节点到叶节点的路,所有关键字的查找路径长度相同,导致每一个关键字的查询效率相当。 B-树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。B+树的叶子节点使用指针顺序连接在一起,只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作。 增删文件(节点)时,效率更高。因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。 什么是聚簇索引?何时使用聚簇索引与非聚簇索引 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据 非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因 澄清一个概念:innodb中,在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引,辅助索引叶子节点存储的不再是行的物理位置,而是主键值
数据库索引相关的知识点; JVM 的相关知识点;
了解过那些设计模式;单例模式口述一下
package com.yrworkspaces.text.javaBasics.thread;
/**
* 懒汉式,需要的时候才创建,典型的时间换空间
* 上面的懒汉式单例类实现里对静态工厂方法使用了同步化,以处理多线程环境。
*/
public class LazySingleton {
//TODO 静态属性用来缓存创建实例
private static LazySingleton lazySingleton;
//TODO 私有构造方法避免程序自由创建实例
public LazySingleton() {
}
//TODO 静态公共方法用于取得该类实例
private static synchronized LazySingleton getLazySingleton() {
if (null == lazySingleton) {
lazySingleton = new LazySingleton();
}
return lazySingleton;
}
}
package com.yrworkspaces.text.javaBasics.thread;
/**
* 双重检查加锁,既实现线程安全,又能够使性能不受很大的影响
*/
public class Singleton {
//TODO 被volatile修饰的变量的值,将不会被本地线程缓存,所有对该变量的读写都是直接操作共享内存,从而确保多个线程能正确的处理该变量。
private volatile static Singleton instance;
//TODO 私有构造方法
public Singleton() {
}
//TODO 公共静态方法获取实例
public static Singleton getSingleton() {
//TODO 先检查实例是否存在,不存在,在进行同步
if (null == instance) {
//TODO 同步块,线程安全的创建实例
synchronized (Singleton.class) {
//TODO 再次检查实例是否存在,如果不存在才真正的创建实例
if (null == instance) {
instance = new Singleton();
}
}
}
return instance;
}
}
HashMap: 小结 (1) 扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。 (2) 负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。 (3) HashMap是线程不安全的,不要在并发的环境中同时操作HashMap,建议使用ConcurrentHashMap。 (4) JDK1.8引入红黑树大程度优化了HashMap的性能。 (5) 还没升级JDK1.8的,现在开始升级吧。HashMap的性能提升仅仅是JDK1.8的冰山一角。
时间复杂度
三个求和算法,按顺序时间复杂度为O(n),O(1),O(n^2),分别称为线性阶,常数阶和平方阶。 O(1)常数阶:每条语句的频度都是1,算法的执行时间不随着问题规模n增大而增长,即使有上千条语句,其执行时间也不过是一个比较大的常数。 O(n)线性阶:有一个n次循环的循环语句。随着n增长执行时间线性增长。 O(n^2)平方阶:循环中嵌套一个循环的情况。
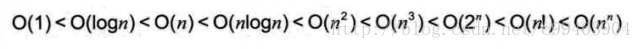
ArrayList和LinkedList有什么区别
ArrayList的实现用的是数组,LinkedList是基于链表的,数组适合查找,链表适合增删 LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
HashMap ,HashTable,LinkedHashMap,TreeMap
(1)HashMap:它根据键的HashCode值存储数据,大多数情况下可以直接定位它的值,因而具有很快的访问速度,但遍历顺序是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。 (2)Hashtable:Hashtable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。 (3) LinkedHashMap:LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。 (4) TreeMap:TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









