







Apache Atlas为组织提供开放式元数据管理和治理功能,用以构建其数据资产目录,对这些资产进行分类和管理,并为数据分析师和数据治理团队,提供围绕这些数据资产的协作功能。本文就介绍Atlas在Apache Hadoop环境下的安装。
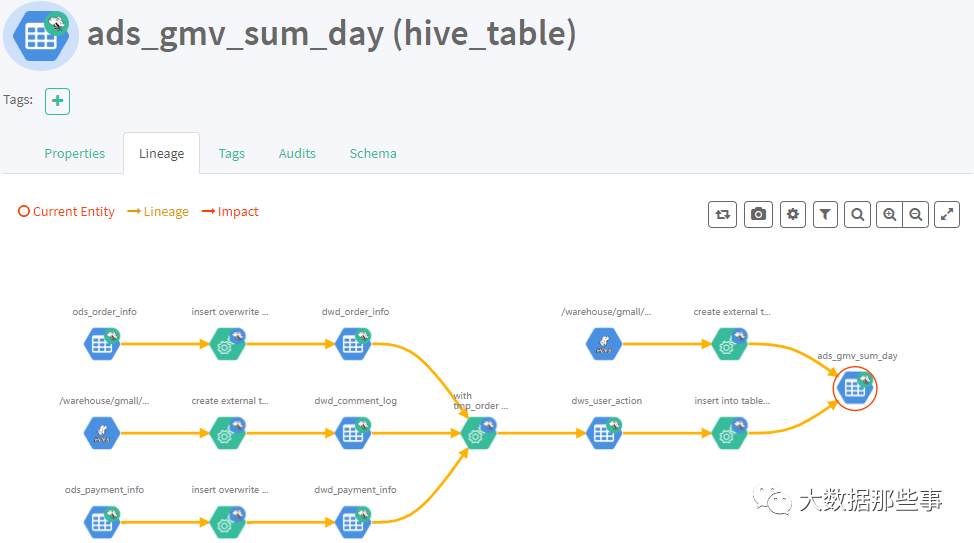
1)表与表之间的血缘依赖
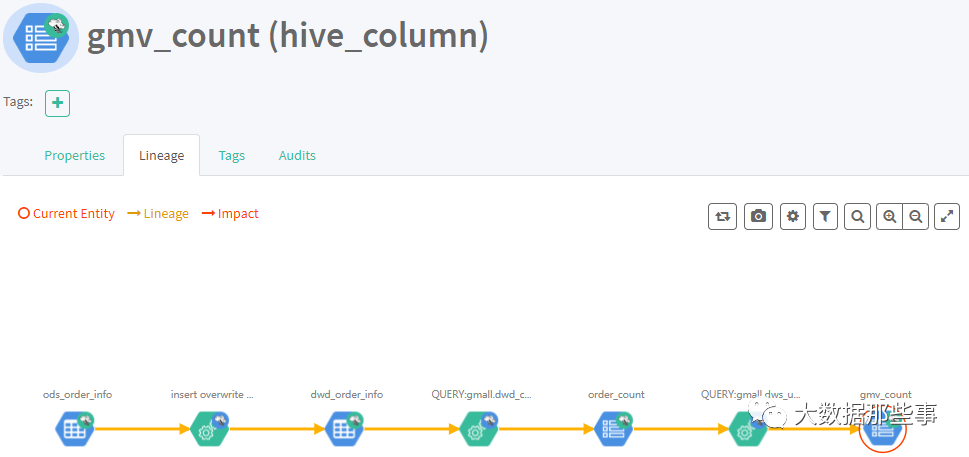
2)字段与字段之间的血缘依赖
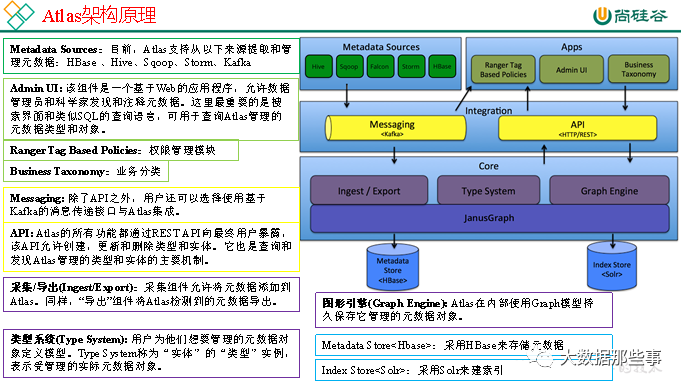
02
PART
特性与环境准备
Atlas2.0特性
(1)更新了组件可以使用
Hadoop3.1,Hive3.1,Hive3.0,Hbase2.0,Solr7.5和Kafka2.0
(2)将JanusGraph版本更新为0.3.1
(3)更新了身份验证支持可信代理
(4)更新了指标模块收集通知
(5)支持Atlas增量导出元数据
准备3台主机,hadoop101,hadoop102,hadoop103。
Atlas安装分为:集成自带的HBase + Solr;集成外部的HBase + Solr。
这里安装采用集成外部Hase+Solr。环境准备如下图
| 服务名称 |
子服务 |
服务器 hadoop101 |
服务器 hadoop102 |
服务器 hadoop103 |
| HDFS |
NameNode |
√ |
||
| DataNode |
√ |
√ |
√ |
|
| SecondaryNameNode |
√ |
|||
| Yarn |
NodeManager |
√ |
√ |
√ |
| Resourcemanager |
√ |
|||
| Zookeeper |
QuorumPeerMain |
√ |
√ |
√ |
| Kafka |
Kafka |
√ |
√ |
√ |
| HBase |
HMaster |
√ |
||
| HRegionServer |
√ |
< |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









