









文章目录
一、MongoDB概述
1.MongoDB简介
-
MongoDB是一种高性能、支持海量存储的NoSQL数据库
-
MongoDB的数据以类似于JSON格式的二进制文档存储
-
文档型的数据存储方式有几个重要好处:
- 文档的数据类型可以对应到语言的数据类型,如数组类型(Array)和对象类型(Object)
- 文档可以嵌套,有时关系型数据库涉及几个表的操作,在MongoDB中一次就能完成,可以减少昂贵的连接开销
- 文档不对数据结构加以限制,不同的数据结构可以存储在同一张表。
-
MongoDB的适用场景:
- 网站数据:MongoDB非常适合实时的插入、更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
- 缓存:由于性能很高,MongoDB也适合作为信息基础设施的缓存层。在系统重启之后,由MongoDB搭建的持久化缓存层可以避免下层的数据源过载。
- 大尺寸、低价值的数据:使用传统的关系型数据库存储一些大尺寸、低价值的数据会比较浪费,在此之前,很多时候会选择传统的文件进行存储。
- 高伸缩性的场景:MongoDB非常适合由数十台或数百台服务器组成的数据库,MongoDB的路线图中已经包含对MapReduce引擎的内置支持以及集群高可用的解决方案。
- 用于对象及JSON数据的存储:MongoDB的BSON数据格式非常适合文档化格式的存储及查询。
-
MongoDB的具体应用
- 游戏场景,使用MongoDB存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新。
- 物流场景,使用MongoDB存储订单信息,订单状态在运输过程中会不断更新,以MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
- 社交场景,使用MongoDB存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能。
- 物联网场景,使用MongoDB存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析。
- 直播,使用MongoDB存储用户信息、礼物信息等。
2.选择使用MongoDB
- 应用不需要复杂事务及复杂join支持,必要条件。
- 新应用,需求会变,数据模型无法确定,想快速迭代开发。
- 应用需要2000-3000以上的读写QPS(更高也可以)。
- 应用需要TB甚至PB级别的数据存储。
- 应用发展迅速,需要能快速水平扩展。
- 应用需要大量的地理位置查询、文本查询。
- 应用需要99.999的高可用
有一个符合就可以选择MongoDB,两个以上符合,选MongoDB绝对不后悔。
3.MongoDB与关系型DB比较
-
RDBMS(关系型DB):table(表),row(行),column(列),index(唯一索引、主键索引),join(主外键关联),primary key(指定1到N个列做主键)
-
MongoDB:collection(集合),document(文档),field(字段),index(支持地理位置索引、全文索引、哈希索引),embedded Document(嵌套文档),primary key(指定_id field做主键)
-
BSON是一种类似于JSON的二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型。BSON有三个特点:轻量性、可遍历性、高效性。
-
MondoDB中Document可以出现的数据类型有:String、Integer、Boolean、Double、ObjectId(对象id,用于创建文档的id)、Array、Timestamp(时间戳)、object(内嵌文档)、null、Date或者ISOdate、Code。
二、下载安装MongoDB
1.独立安装MongoDB
-
进入到/etc/yum.repos.d目录下,创建文件mongodb-org-5.0.repo并输入如下yum源地址:
[mongodb-org] name=MongoDB Repository baseurl=http://mirrors.aliyun.com/mongodb/yum/redhat/7Server/mongodb-org/5.0/x86_64/ gpgcheck=0 enabled=1 -
安装之前先更新yum:
yum -y update -
下载安装MongoDB:
yum -y install mongodb-org -
查看mongo的安装位置:
whereis mongod -
修改mongod.conf配置文件,修改如下:
bindIp: 0.0.0.0即表示所有ip地址都可以进行连接
-
mongodb服务命令
- 启动mongo服务:
systemctl start mongod.service - 停止mongo服务:
systemctl stop mongod.service - 重启mongo服务:
systemctl restart mongod.service - 查看mongo服务:
systemctl status mongod.service - 设置开机自启动:
systemctl enable mongod.service
- 启动mongo服务:
-
启动mongo服务:
systemctl start mongod.service -
进入到/usr/bin目录下,启动mongod 客户端:./mongo
-
查看mongodb默认的数据库:
show dbs
2.docker安装MongoDB
- 通过yum命令下载docker:
yum -y install docker - 启动docker:
systemctl start docker - 通过访问
https://hub.docker.com/,搜索mongodb:

进入后,选择第一个mongodb,然后再点tags,选择mongo:5.0.11-focal,复制docker命令。 - 通过docker拉取mongodb的镜像:
docker pull mongo:5.0.11-focal - 查看下载镜像:
docker images - 创建mongodb的挂载目录(保存数据目录):
mkdir -p /mnt/mongodb/data - 关闭独立安装的mongodb服务(端口占用):
systemctl stop mongod.service - 创建并运行mongo容器:
docker run -itd --privileged=true --name mongo5 -p 27017:27017 -v /mnt/mongodb/data:/data/db mongo:5.0.11-focal
参数:- -itd,即创建以交互的方式(it)且后台运行(d)
- –privileged=true,即有root权限
- -p 27017:27017,即将后面的27017映射到前面的27017(宿主机的端口)
- -v /mnt/mongodb/data:/data/db,即将容器里的/data/db挂载到宿主机的/mnt/mongodb/data目录下
- mongo:5.0.11-focal,即通过docker下载的镜像名
- 查看docker启动的容器:
docker ps -a - NoSQLBooster下载网址:
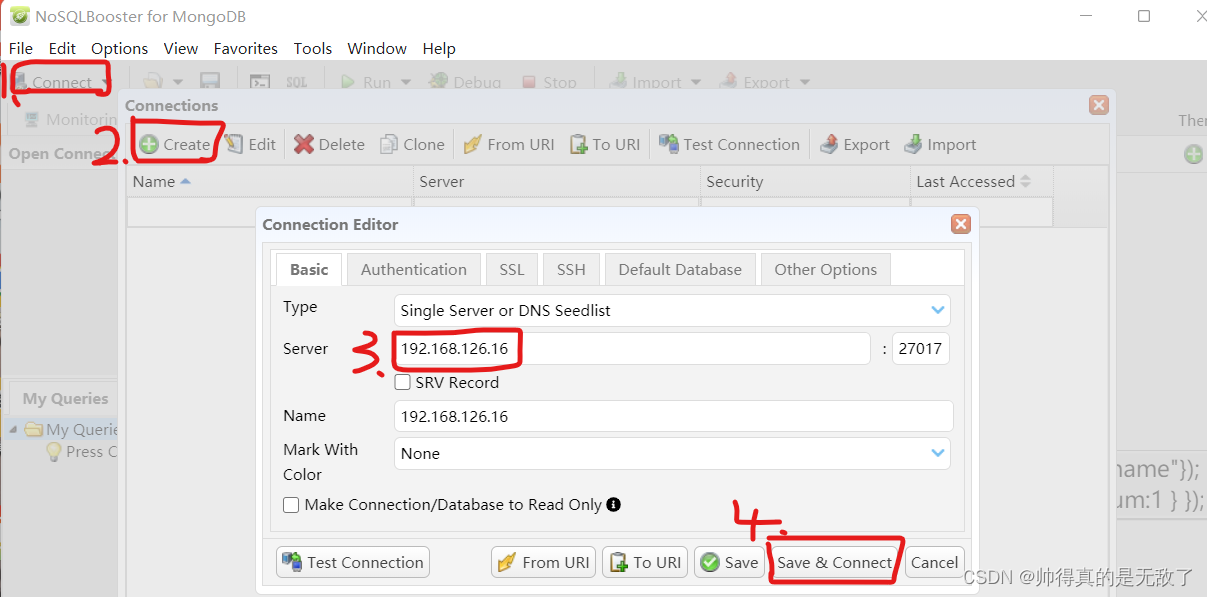
https://www.mongobooster.com/downloads - 连接MongoDB,打开NoSQLBooster,进行如下顺序操作(无密码):
三、MongoDB的逻辑结构
1.mongodb的逻辑结构
- MongoDB与MySQL中的架构相差不多,底层都使用了可插拔的存储引擎以满足用户的不同需要。用户可以根据程序的数据特征选择不同的存储引擎,在3.2版本以后的MongoDB中使用了WiredTiger作为默认的存储引擎,WiredTiger提供了不同粒度的并发控制和压缩机制,能够为不同种类的应用提供最好的性能和存储率。
- 在存储引擎上层的就是MongoDB的数据模型和查询语言了,由于MongoDB对数据的存储与RDBMS有较大的差异,所以它创建了一套不同的数据模型和查询语言。
2.mongodb数据模型
-
与SQL数据库不同,在SQL数据库中,在插入数据之前必须确定和声明表的架构,默认情况下,MongoDB的集合不要求其文档具有相同的架构。
-
结构灵活
单个集合中的文档不需要具有相同的字段集合,并且集合中的文档之间的字段数据类型可以不同。
相当于RDB表的行数据中,每行的字段名都可以不相同;然后字段数据类型也都可以不相同。
可灵活更改集合中文档的结构,如添加新字段、删除现有字段或将字段值更改为新类型,将文档更新为新结构。 -
文档结构
- 内嵌的方式指的是把相关联的数据保存在同一个文档结构之中。MongoDB的文档结构允许一个字段或一个数组内的值作为嵌套的文档。
- 引用方式通过存储数据的引用信息来实现两个不同文档之间的关联,应用程序可以通过解析这些数据引用来访问相关数据。
-
选择数据模型
- 内嵌
数据对象之间有包含关系,一般是数据对象有一对多或一对一的关系。需要经常一起读取的数据。
有map-reduce/aggregation需求的数据放在一起,这些操作都只能操作单个collection。 - 引用
当内嵌数据会导致很多数据的重复,并且读性能的优势又不足以覆盖数据重复的弊端。
需要表达比较复杂的多对多关系的时候。
大型层次结果数据集,嵌套不要太深。
- 内嵌
3.WiredTiger存储引擎(默认)
- 存储引擎负责管理数据如何在磁盘和内存中存储,MongoDB支持多种存储引擎,不同的存储引擎都有其在特定工作环境下的特点,选择适合的存储引擎能够有效提高应用程序的性能。
- WiredTiger存储引擎(默认)
- WiredTiger适合大多数工作场景,从MongoDB 3.2开始默认的存储引擎是WiredTiger,3.2版本以前的默认存储引擎是MMAPv1,MongoDB 4.0以后的版本不再支持MMAPv1存储引擎。
- 支持document级别并发操作
WiredTiger对写入操作使用document级别并发控制。因此,多个客户端可以同时修改集合的不同文档。对于大多数读写操作,WiredTiger使用乐观并发控制。WiredTiger仅在全局、数据库和集合级别使用意向锁。当存储引擎检测到两个操作之间的冲突时,其中一个操作将引发写入冲突,MongDB会对用户透明地尝试该操作。
意向锁(Intent Lock),简单来说就是给更大一级别的空间示意里面是否已经上过锁。如果我们给某一行数据加上了排它锁,数据库会自动给更大一级的空间,比如数据页或数据表加上意向锁,告诉其他人这个数据页或数据表已经有人上过排它锁了,这样当其他人想要获取数据表排它锁的时候,只需要了解是否有人已经获取了这个数据表的意向排他锁即可。
意向锁,即通知其他线程该数据的上一级已经加过排它锁。
排它锁,即只有一个线程能获取该资源。
乐观锁(Optimistic Locking)认为对同一数据的并发操作不会总发生,属于小概率事件,不用每次都对数据上锁,也就是不采用数据库自身的锁机制,而是通过程序来实现。在程序上,我们可以采用版本号机制或者时间戳机制实现。
-
Snapshots and Checkpoints(快照和检查点)
WiredTiger使用多版本并发控制(MVCC)。在操作开始时,WiredTiger会向操作提供数据的point-in-time快照,快照显示了数据在内存中的一致性视图。
从3.6版本开始,MongoDB将WiredTiger配置为每隔60s创建检查点(将快照数据写入磁盘)。在早期版本中,MongoDB将检查点设置为在WiredTiger中每隔60s或写入2GB日志数据时(以先发生的为准)对用户数据进行检查。 -
journal(日志)
WiredTiger将日志和检查点结合使用,以确保数据的持久性。WiredTiger日志将保留检查点之间的所有数据修改。如果MongoDB在两个检查点之间退出,它将使用日志重播自上一个检查点以来修改的所有数据。 -
compression(压缩)
使用WiredTiger存储引擎,MongoDB会对所有集合和索引进行压缩,压缩以牺牲额外的cpu作为代价,最大限度的减少了磁盘的使用。默认情况下,WiredTiger对所有集合使用block compression(块压缩),并对索引使用prefix compression(前缀压缩)。 -
内存使用
对于WiredTiger,MongoDB利用WiredTiger内部缓存和文件系统缓存。从MongoDB 3.4开始,默认WiredTiger内存缓存大小为以下两者中的较大值:
50% of(RAM(主机物理内存)- 1GB)
256MB
4.In-memory存储引擎
-
从MongoDB企业版3.2.6开始,In-Memory存储引擎是64位版本中广泛使用(general availability GA)的一部分。除某些元数据和诊断数据外,In-Memory存储引擎不维护任何磁盘上的数据,包括配置数据,索引,用户凭据等。
-
In-Memory存储引擎设置
配置–storageEngine选项值为inMemory;如果使用配置文件,则配置storage.engine
配置–dbpath,如果使用配置文件则配置storage.dbPath。尽管In-Memory存储引擎不会将数据写入文件系统,但它会在–dbpath中维护小型元数据文件和诊断数据以及用于构建大型索引的临时文件。 -
并发(concurrency)
In-Memory存储引擎对于写入操作使用了document级别的并发控制。多个客户端可以同时修改集合的不同文档。即同时对同一个文档进行修改时时,才会进行阻塞。 -
内存使用
默认情况下,In-Memory存储引擎使用50%的物理RAM减去1GB。如果写操作的数据超过了指定的内存大小,则MongoDB返回内存溢出错误。
要指定新的内存大小,可使用YAML格式配置文件storage.inMemeory.engineConfig.inMemorySizeGB: < newSize> -
事务
从MongoDB 4.2开始,在复制集和分片集群上支持事务,也就是支持集群事务,其中:主成员节点WiredTiger存储引擎,同时,辅助成员使用WiredTiger存储引擎或In-Memory存储引擎。
在MongoDB 4.0中,只有使用WiredTiger存储引擎的复制集才支持事务。
四、MongoDB的命令行操作
1.基本操作(数据库与集合)
- 通过docker命令进入到容器:
docker exec -it mongo5 bash - 在容器中进入到mongoDB命令行客户端:
mongo - 查看数据库:
show dbs - 切换数据库,如果不存在则创建:
use database - 创建集合:
db.createCollection("集合名") - 查看集合:
show tables,show collections - 删除集合:
db.集合名.drop() - 删除当前数据库:
db.dropDatabase()
2.CRUD操作
1.添加文档
- 添加单个文档,如果集合不存在,会创建一个集合。语法:
db.collection.insertOne()
如果不指定id,MongoDB会使用ObjectId的value作为id,示例如下:db.inventory.insertOne({ item: "canvas", qty: 100, tags: ["cotton"],size: { h: 28, w: 35.5,uom: "cm" } }) - 添加多个文档。语法:
db.collection.insertMany()
示例如下:db.inventory.insertMany([ { item: "journal", qty: 25, tags: ["blank","red"], size: { h: 14, w: 21, uom: "cm" } }, { item: "mat", qty: 85, tags: ["gray"],size: { h: 27.9, w: 35.5, uom: "cm" } }, { item: "mousepad", qty: 25, tags: ["gel","blue"], size: { h: 19, w: 22.85, uom: "cm"}} ])
2.查询文档
语法:db.collection.find()
- 查询集合的所有文档:
db.inventory.find({}) - 匹配指定内容的文档:
db.inventory.find({size:{h: 14, w: 21, uom: "cm"}})
如果h: 14在w: 21后,也就是交换位置,则查询不到 - 匹配指定数组中某个元素的文档:
db.inventory.find({"size.h": 14}) - 匹配某个属性值小于具体数值的文档:
db.inventory.find({"size.h": {$lt:15}})
如果需要匹配多个条件则用逗号隔开
3.更新文档
- 更新单个文档
语法:db.inventory.updateOne()
$currentDate: { lastModified: true },即将lastModified字段更新为当前时间,不存在则生成一个db.inventory.updateOne( { item: "journal" }, {$set: { "size.uom": "dm", qty: 30 }, $currentDate: { lastModified: true }} ) - 更新多个文档
语法:db.inventory.updateMany()
即将集合inventory中qty小于50的文档进行更新。db.inventory.updateMany( { "qty":{$lt: 50} }, {$set: { "size.uom": "in" }, $currentDate: { lastModified: true }} ) - 替换文档:
语法:db.collection.replaceOne()db.inventory.replaceOne( { item: "journal" }, { item: "journal", instock:[ { warehouse: "A", qty: 60 }, { warehouse:"B", qty: 40 } ] } )
即第一个{}是条件,第二个{}是更新的内容。
4.删除文档
- 删除集合的所有文档:
db.inventory.deleteMany({}) - 删除指定条件的文档:
db.inventory.deleteMany({"qty":{$lt: 70}}) - 最多删除一个指定条件的文档:
db.inventory.deleteOne({"qty":{$lt: 101}})
3.聚合操作
-
通过聚合操作可以处理多个文档,并返回计算后的结果。
- 对多个文档进行分组
- 对分组的文档执行操作并返回单个结果
- 分析数据变化
-
聚合管道,即分别由多个阶段来处理文档,每个阶段的输出是下个阶段的输入,返回的是一组文档的处理结果,例如,total、average、maxmium、minmium。
插入用来聚合操作的数据:db.orders.insertMany( [ { _id: 0, name: "Pepperoni", size: "small", price: 19, quantity: 10,date: ISODate( "2030-03-13T08:14:30Z" ) }, { _id: 1, name: "Pepperoni", size: "medium", price: 20,quantity: 20, date : ISODate( "2030-03-13T09:13:24Z" ) }, { _id: 2, name: "Pepperoni", size: "large", price: 21,quantity: 30, date : ISODate( "2030-03-17T09:22:12Z" ) }, { _id: 3, name: "Cheese", size: "small", price: 12,quantity: 15, date : ISODate( "2030-03-13T11:21:39.736Z" ) }, { _id: 4, name: "Cheese",size: "medium", price: 13,quantity:50, date : ISODate( "2031-01-12T21:23:13.331Z" ) }, { _id: 5, name:"Cheese", size: "large", price: 14,quantity: 10, date : ISODate( "2031-01-12T05:08:13Z" ) }, { _id: 6, name: "Vegan", size: "small", price: 17, quantity: 10, date : ISODate( "2030-01-13T05:08:13Z" ) }, { _id: 7, name: "Vegan", size: "medium", price: 18,quantity: 10, date : ISODate( "2030-01-13T05:10:13Z" ) } ] ) -
计算尺寸为medium的订单中,每种类型的订单数量
db.orders.aggregate([ { $match:{size: "medium"} }, { $group:{_id:"$name",totalQuantity: {$sum: "$quantity"}} } ])下面一段,即根据name统计过滤后的文档,并把"quantity"值相加。
-
根据日期范围过滤,从2030-01-01到2030-01-30之间;对过滤后的文档以日期为条件进行分组并计算;按照订单价值倒序排列文档
db.orders.aggregate( [ { $match: { "date": { $gte: new ISODate( "2030-01-01" ), $lt: new ISODate( "2030-01-30" ) } } }, { $group: { _id: { $dateToString: { format: "%Y-%m-%d", date: "$date" } }, totalOrderValue: { $sum: { $multiply:[ "$price", "$quantity" ] } }, averageOrderQuantity: { $avg:"$quantity" } } }, { $sort: { totalOrderValue: -1 } } ] ) -
统计集合中的文档数量:
db.orders.count() -
根据指定字段进行过滤,去掉重复的文档:
db.orders.distinct("name")
即拿到集合中所有name的值,并将重复的name去掉。 -
聚合管道顺序优化,即聚合管道在执行过程中有一个优化的阶段,以提高性能。
即先过滤再处理。 -
聚合操作的限制事项:
- 返回的结果集不能超过16m字节
- 单个管道中的stage不能超过1000个(MongoDB 5.0)
-
聚合操作的命令有:$sum、 $avg、 $min、 $max、 $push、 $first、 $last、 $group、 $project、 $match、 $limit
4.索引
1.单键索引
-
索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引目标是提高数据库的查询效率,没有索引的话,查询会进行全盘扫描(scan every document in a collection),数据量大时严重降低查询效率。默认情况下,MongoDB在一个集合(collection)创建时,自动地对集合的_id创建了唯一索引。
-
单键索引,即一个索引结构指向一个字段且非数组类型。
MongoDB默认所有集合在_id字段上有一个索引。即集合对文档的_id存储一个索引。 -
创建集合records并插入数据:
db.records.insertOne({ "score": 356, "location": { province: "Hebei", city:"Tangshan" } }) -
创建索引,1代表升序,-1代表降序
-
创建索引score:
db.records.createIndex({score: 1}) -
在内嵌字段上建立索引province:
db.records.createIndex({"location.province": 1}) -
在内嵌文档上建立索引:
db.records.createIndex({location: 1})
2.复合索引
- 复合索引是指单个索引结构指向多个字段。
- 创建集合products并插入数据:
db.products.insertOne({ "item": "Banana", "category": ["food", "produce", "grocery"], "location": "4th Street Store", "stock": 4, "type": "cases" }) - 建立复合索引,在item和stock字段上建立升序索引:
db.products.createIndex({"item": 1, "stock": 1})
3.多键索引
- 多键索引用于为数组中的元素创建索引
- 创建集合inventory并插入数据:
db.inventory.insertMany([ { _id: 5, type: "food", item: "aaa", ratings:[5, 8, 9 ] }, { _id: 6, type: "food", item: "bbb", ratings: [5, 9 ] }, { _id: 7, type: "food", item: "ccc", ratings: [9, 5, 8 ] }, { _id: 8, type: "food", item: "ddd", ratings: [9, 5 ] }, { _id: 9, type: "food", item: "eee", ratings: [5, 9, 5 ] } ]) - 建立多建索引,在ratings字段数组上建立索引:
db.inventory.createIndex({ratings: 1}) - 使用多键索引查找ratings数组中有5,9的文档:
db.inventory.find({ratings: [5,9]})
4.地理坐标索引
- 针对地理空间坐标数据创建索引。
2dsphere索引用于存储和查找球面上的点,2d索引用于存储和查找平面上的点。 - 创建集合company并插入数据:
db.company.insert([ { loc : { type: "Point", coordinates: [116.502451, 40.014176 ] }, name: "军博地铁", category : "Parks" }, { loc : { type: "Point", coordinates: [116.492451, 39.924176 ] }, name: "苹果园地铁", category : "Parks" } ]) - 建立2dsphere球面索引,在loc字段坐标上建立索引:
db.company.createIndex({loc: "2dsphere"}) - 查询以坐标[116.482451,39.914176]为中心,附近大概5km的坐标
db.company.find({ "loc" : { "$geoWithin" : { "$center":[[116.482451,39.914176],0.05] } } }) - 创建集合places并插入数据:
db.places.insert({"name":"aa","addr":[32,32]})
db.places.insert({"name":"bb","addr":[30,22]})
db.places.insert({"name":"cc","addr":[28,21]})
db.places.insert({"name":"dd","addr":[34,26]})
db.places.insert({"name":"ee","addr":[34,27]})
db.places.insert({"name":"ff","addr":[39,28]})
- 建立2d平面索引,在addr字段上建立索引:
db.places.createIndex({"addr": "2d"}) - 查找从[0,0]到[30,30]区间的平面坐标,即从左边的0到左边的30是x的区间,从右边的0到右边的30是y的区间
db.places.find({
"addr": {$within:
{"$box": [[0,0],[30,30]]}
}
})
5.全文索引
-
MongoDB提供了针对string内容的文本查询,Text Index支持任意属性值为string或string数组元素的索引查询。
一个集合仅支持最多一个Text Index,中文分词不理想,推荐ES(Elasticsearch) -
创建集合fullText并插入数据:
db.fullText.insert({name:"aa",description:"no pains,no gains"}) db.fullText.insert({name:"ab",description:"pay pains,get gains"}) db.fullText.insert( {name:"ac",description:"a friend in need,a friend in deed"}) -
建立全文索引,在description字段上建立全文索引,并指定语言
db.fullText.createIndex( {description: "text"}, {default_language: "english"} ) -
通过全文索引text查找pains:
db.fullText.find({"$text": {"$search": "pains"}}) -
创建多个字段的全文索引,并指定全文索引名称:
db.newText.createIndex( { content: "text", "users.comments": "text", "users.profiles": "text" }, { name: "MyTextIndex" } ) -
根据集合名查看全文索引名称:
db.newText.getIndexes() -
根据全文索引名称删除全文索引:
db.newText.dropIndex("MyTextIndex")
6.hash索引和索引管理
-
hash索引,针对属性的hash值进行索引查询,当要使用Hashed Index时,MongoDB能够自动的计算hash值,无需程序计算hash值。
hash index仅支持等于查询,不支持范围查询。 -
创建hash索引:
db.collection.createIndex({"field": "hashed"}) -
创建复合hash索引(4.4以后的版本):
db.collection.createIndex({"fieldA": 1,"fieldB": "hashed"}) -
索引管理
-
获取针对某个集合的索引:
db.collection.getIndexes() -
获取索引的大小:
db.collection.totalIndexSize() -
索引的重建:
db.collection.reIndex() -
索引的删除(根据索引名):
db.collection.dropIndex("索引名") -
删除全部索引:
db.collection.dropIndexes()
但是无法删除_id对应的索引。
总结:
- MongoDB是一种高性能、支持海量存储的NoSQL数据库。用来存储一些大尺寸、低价值的数据,它的BSON数据格式非常适合文档化格式的存储和查询。MongoDB采用文档形式存储数据;而关系型数据库采用二维表形式存储数据。
- MongoDB的默认端口是27017,通过NoSQLBooster可视化工具连接MongoDB。
- MongoDB底层采用了可插拔的存储引擎(默认WiredTiger),存储引擎上面是数据模型和查询语言。文档结构有内嵌和引用的方式。
- 从MongoDB 3.2开始默认的存储引擎是WiredTiger;支持document级别并发操作;从3.6版本开始,MongoDB将WiredTiger配置为每隔60s创建检查点(将快照数据写入磁盘);WiredTiger日志将保留检查点之间的所有数据修改。
默认情况下,WiredTiger对所有集合使用block compression(块压缩),并对索引使用prefix compression(前缀压缩)。 - MongoDB与MySQL对应的结构属性,Database与Database,Collection与Table,文档与行数据,字段与列数据。跟MYSQL数据库一样,都有增删改查。
- 聚合管道,即分别由多个阶段来处理文档,每个阶段的输出是下个阶段的输入,返回的是一组文档的处理结果。一般分为2个阶段,从对数据进行过滤,再到对过滤后的数据进行分组。最后还可以添加排序阶段。
- 索引是一种单独的、物理的对数据库表中的一列或多列值进行排序的一种存储结构。
单键索引是一对一的关系,复合索引是一对多的关系,多键索引是多对多的关系。
2d sphere索引用于存储和查找球面上的点(经纬度),2d索引用于存储和查找平面上的点(平面[x,y]的坐标)。 - 全文索引是针对string内容的文本查询,全文索引的关键字为"text";但是中文缺不理想,中文推荐ES(Elasticsearch)。全文索引可以由一个或多个string内容的字段组成。
针对属性的hash值进行索引查询,当要使用Hashed Index时,MongoDB能够自动的计算hash值,无需程序计算hash值。hash index仅支持等于查询,不支持范围查询。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









