







1 Python私房菜【一】——(模块)
筑基篇已经了解了什么是模块,接下来就要深入学习常用的模块
如果未学习 筑基篇 可移步至 Python私房菜—— 筑基篇(已完结)
1.1 sys 模块
内置模块,可操作Python解释器相关的数据
【1】sys.argv
获取脚本命令python xxx a b 的参数,以列表形式返回
如 python xxx a b,则 sys.argv 会返回 [xxx,a,b]
【2】sys.path
返回的是一个列表,列表中每一元素是一个目录路径字符串
这个列表的作用是——
Python在导入模块时,默认会从该列表中的目录查找
其中——
python会自动将当前运行文件所在的目录添加到sys.path中
pycharm默认会将项目所在的目录添加到sys.path中
若后续想将其他路径添加到该目录列表,可通过——
sys.path.append(“路径”) 进行添加
1.2 os 模块
内置模块,提供了与操作系统交互的函数或属性
【1】os.name
返回当前具体操作系统
【2】os.environ[“环境变量名”]
返回具体文件的环境变量
【3】os.listdir(“路径”)
以列表形式列出路径下的文件名及文件夹名(只列出第一层)
【4】os.walk(“路径”)
返回的是一个指定路径下包含所有目录和文件的生成器,可通过for…in…遍历;
遍历的每一个元素是一个元组,
元组中包含3个元素,
第一个元素是遍历的当前目录路径 以字符串形式返回
第二个元素是当前目录下还包含哪些目录 以列表形式返回
第三个元素是当前目录下还包含哪些文件 以列表形式返回
【5】os.mkdir(“aa”)
当前运行模块的目录下创建aa文件夹,只能创建一级目录;
若参数是多级路径 如 “aa/bb”,则需保证aa目录需存在,否则报错
【6】os.makedirs(“aa\bb\cc”)
可以创建多级目录
【7】os.rmdir(“路径”)
删除指定文件夹【且是空文件夹】
【8】os.remove(“路径”)
删除指定文件
【9】os.rename(“旧文件路径”,“新文件路径”)
重命名
【10】os.getcwd()
返回当前执行文件所在的目录【绝对路径】
【11】os.path
① os.path.join(“路径1”, “路径2”, “路径3”)
将多个路径进行拼接
② os.path.abspath(“路径”)
- 若参数中的路径是绝对路径
返回该路径 - 若参数中的路径是相对路径
返回当前执行文件所在目录与参数路径拼接后的路径
③ os.path.basename(“路径A/路径B/路径C”)
返回路径C 即路径当中最后一个文件或文件夹名
④ os.path.split(“路径”)
以路径中最后一个/进行分割,
将分割后的路径字符串装进元组中
⑤ os.path.exists(“路径”)
- 绝对路径
系统中该路径存在返回True 不存在返回False - 相对路径
会与当前工作目录拼接后再判断存不存在
⑥ os.path.dirname(“路径”)
输出该路径的上一层路径
- 若参数为__file__
表示所在模块的路径【绝对路径 包含模块名 pycharm环境下】
和执行文件无关 - __file__
表示当前模块名
在pycharm环境下表示当前模块的完整路径
在命令行环境只表示模块名
实际上是Python命令后跟的脚本路径
⑦ os.path.isabs(“路径”)
判断该路径是否为绝对路径
⑧ os.path.isfile(“文件路径”)
判断该路径是否是一个文件
⑨ os.path.isdir(“文件夹路径”)
判断该路径是否是一个文件夹
【12】os.stat(“文件路径”).st_size
获取该文件大小
1.3 shutil模块
内置模块,用于操作文件/目录
【1】shutil.rmtree(“路径”)
删除目录(强制删除,不必权限)
【2】shutil.move(“旧文件名路径”, “新文件名路径”)
重命名
【3】shutil.make_archive(“压缩文件名”, “压缩格式”, “要压缩的文件路径”)
压缩文件;
压缩格式 :zip、tar、gztar、bztar、xztar
【4】shutil.unpack_archive(“要解压的文件名”, extract_dir=“要解压的路径”, format=“解压格式”)
解压缩;
若解压的路径不存在会自动创建(可创建多级目录)
1.4 random模块
内置模块,用于获取随机数
【1】random.randint(整数a, 整数b)
随机生成a到b的随机整数 闭区间
【2】random.choice(有序对象)
从有序对象(列表、元组、字符串)中随机取出一个元素
【3】random.random()
取0到1的随机浮点数
【4】random.uniform(数A, 数B)
取数A到数B的随机浮点数
【5】rand.randrange(整数a, 整数b)
随机生成a到b的随机整数 区间左闭右开
【6】random.sample(有序对象, 数值)
在有序对象中随机取出数值个元素并以列表返回
1.5 时间日期模块
内置模块,用于操作时间
1.5.1 time 模块
【1】time.time()
返回一个时间戳 秒数;
从1970年1月1日0时0分0秒开始到当前
【2】time.localtime()
返回【年 月 日 时 分 秒 星期几 一年中的第几天 是否夏令时】的类似元组的时间数据;
要获取对应的时间数据通过下标获取即可
【3】time.sleep(秒数)
延迟秒数后再往后执行下面的代码程序
【4】time.strftime(“格式化参数”, time.localtime())
格式化日期对象
格式化参数符号:
 示例 :time.strftime(“%Y - %m - %d”, time.localtime())
示例 :time.strftime(“%Y - %m - %d”, time.localtime())
1.5.2 datetime 模块
【1】datetime.datetime.now()
获取当前时间【年月日时分秒】;
以系统指定的格式输出;
返回一个日期对象
【2】strftime(“格式化参数”)
通过日期对象调用该方法;
会以自定义的格式对日期对象进行格式化输出
【3】其他方法

1.6 re 模块
内置模块,用于操作正则表达式
1.6.1 正则表达式
【1】规则
本身是哪一个字符,就匹配字符串中的哪一个字符
示例——
- 字符串 : abca
- 表达式 : a
- 输出 : a , a
会遍历字符串中的每个字符与表达式进行匹配
若字符与表达式匹配则会查找下一个字符是否与表达式匹配
【2】字符组
① [字符1字符2字符3…]
② [0-9]
③ [A-z] 范围要遵循ASCII码从小到大
作用 :匹配字符组中的字符,相当于 或 的含义
示例——
- 字符串 : acdebjc
- 表达式 : [abc]
- 输出 : a , c , b , c
注:
一个字符组每次匹配只能和字符串中的一个字符匹配——
字符串 : 12345
表达式 : [123]
输出 : 1 , 2 , 3
若要使输出结果是2位数——
字符串 : 12345
表达式 : [123][123]
输出 : 12
会先选取字符串中的前两个字符分别与两个表达式进行匹配;
若两个字符都匹配成功,则会选取第三四个字符分别与第一二个表达式进行匹配,以此类推;
若第二个字符与第二个表达式匹配不成功,则会选取第二三个字符分别与第一二个表达式进行匹配,以此类推
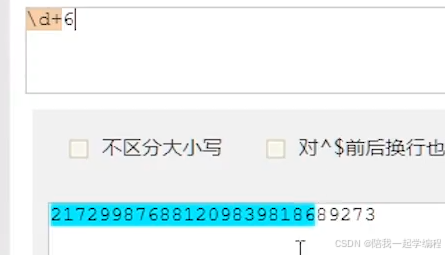
【3】元字符
① \d
表示任意个数字,等价于[0-9]
② \D
表示任意个非数字
③ \s
表示任意个空格、换行符、制表符
④ \S
表示任意个非空格、换行符、制表符
⑤\w
表示任意个数字字母下划线
⑥ \W
表示任意个非数字字母下划线
⑦ \t
表示匹配制表符
⑧ \n
表示匹配换行符
⑨ .
表示除了换行符之外的任意内容
⑩ ^
表示匹配字符串的开头(以xxx开头)
⑪ $
表示匹配字符串的结尾(以xxx结尾)
⑫ []
字符组,表示在 [] 内的所有字符都是 符合 规则的字符
⑬ [^]
非字符组,表示在 [] 内的所有字符都是 不符合 规则的字符
eg. [^abc] 表示匹配 非 a或b或c 的任一字符
eg. ^[abc] 表示匹配 以 a或b或c 某一字符作为开头
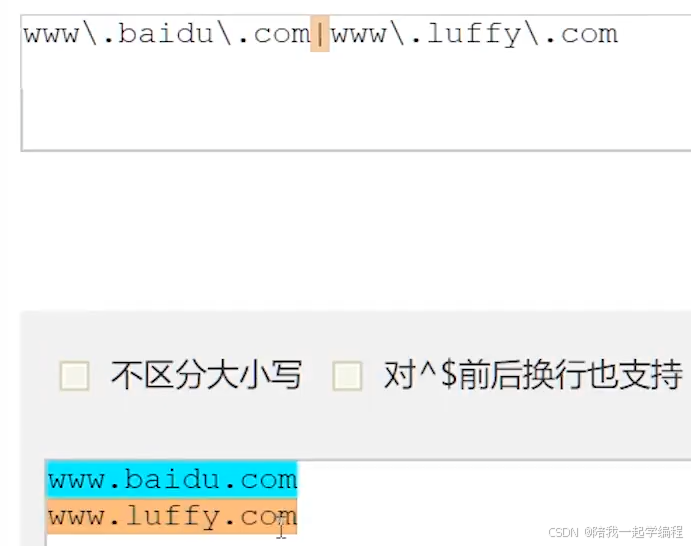
⑭ |
表示 或 ,匹配多个表达式
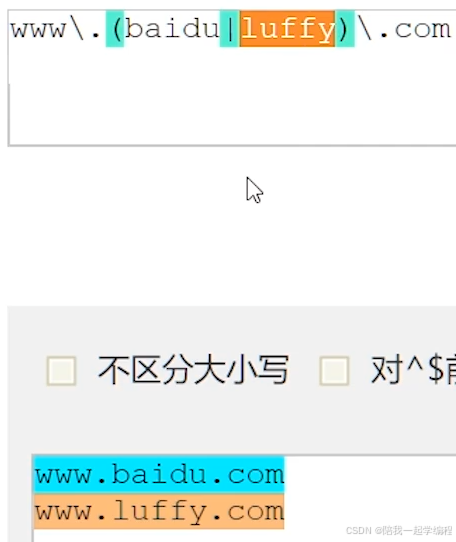
⑮ ()
表示 分组,给一部分正则规定为一组
【4】量词
① {n}
只能出现n次
② {n , }
至少出现n次
③ {n , m}
至少出现n次,至多出现m次
④ ?
表示匹配0或1次
⑤ +
表示匹配1次或多次
⑥ *
表示匹配0次或多次
贪婪模式(默认的匹配模式)
总是会在符合量词条件的范围内尽可能多的匹配
非贪婪模式
总是会在符合量词条件的范围内尽可能少的匹配
写法
元字符 量词 ? 任意字符
常见写法
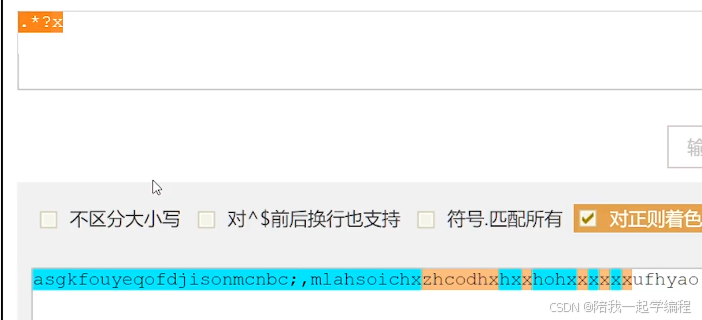
.*?x
x表示任意字符
下图是 贪婪模式 和 非贪婪模式 的匹配结果的区别
贪婪模式
非贪婪模式
1.6.2 re 模块中的方法
【1】re.findall(“表达式”, “要匹配的字符串”)
返回一个列表,每个元素是匹配到的每个项;
匹配不到返回空列表
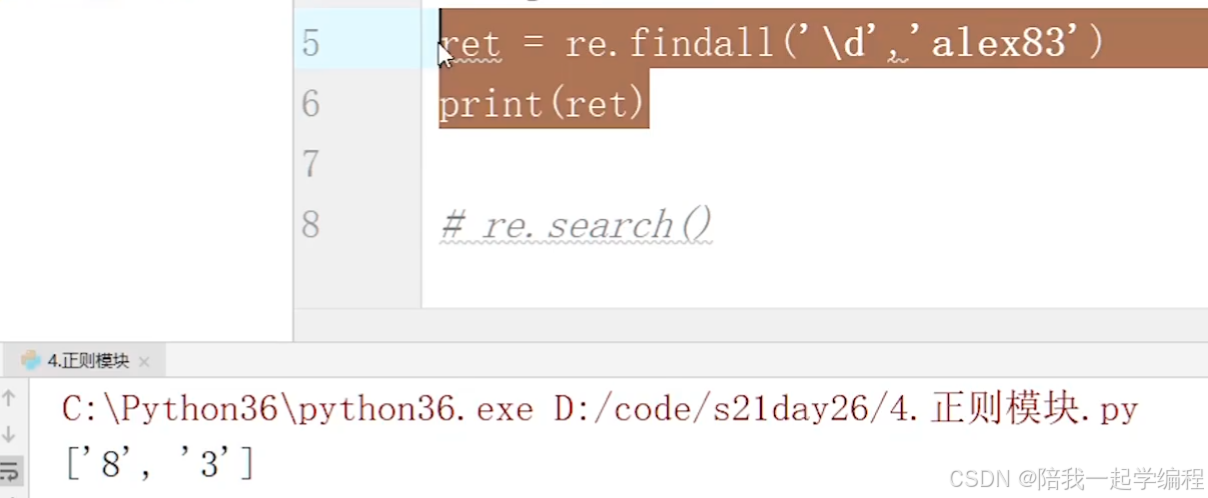
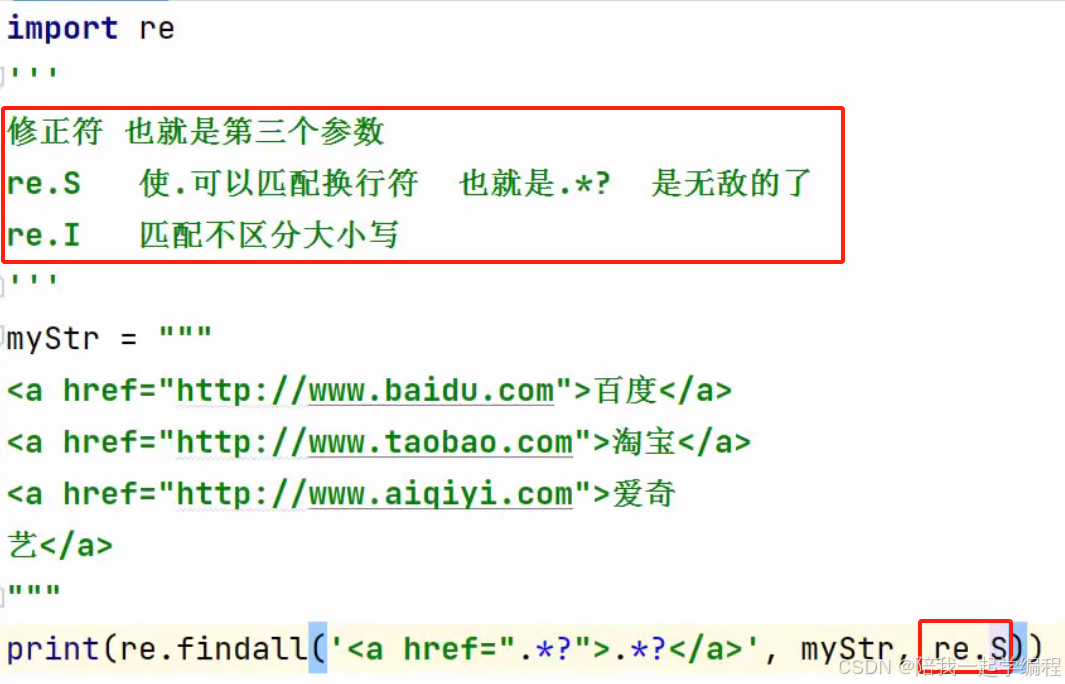
可选参数: re.S 使.可以匹配换行符; re.I 不区分大写小写
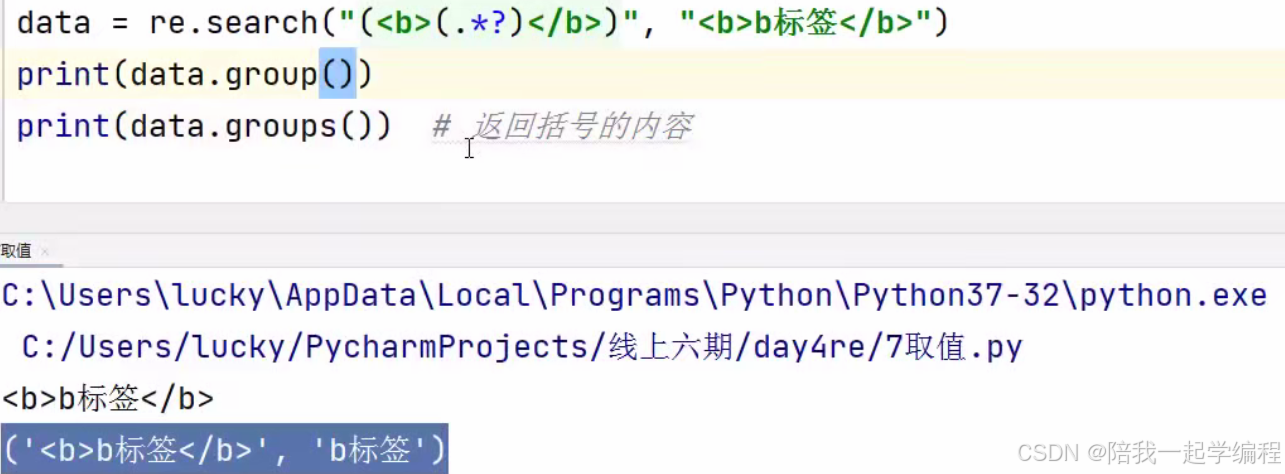
【2】re.search(“表达式”, “要匹配的字符串”)
只匹配一次,若匹配到符合的将不会再继续往后匹配,匹配到会返回一个对象,匹配不到返回None;
要获取 表达式 ( ) 中的值 需要调用group()或groups()
group() :
参数不传 或 参数为0 或 参数为1,返回的都是表达式中匹配到的第一个( )中的值,
若传入参数n, 代表要取值第n个( ) 中的结果;
groups():
以元组形式返回表达式中所有 ( ) 的值
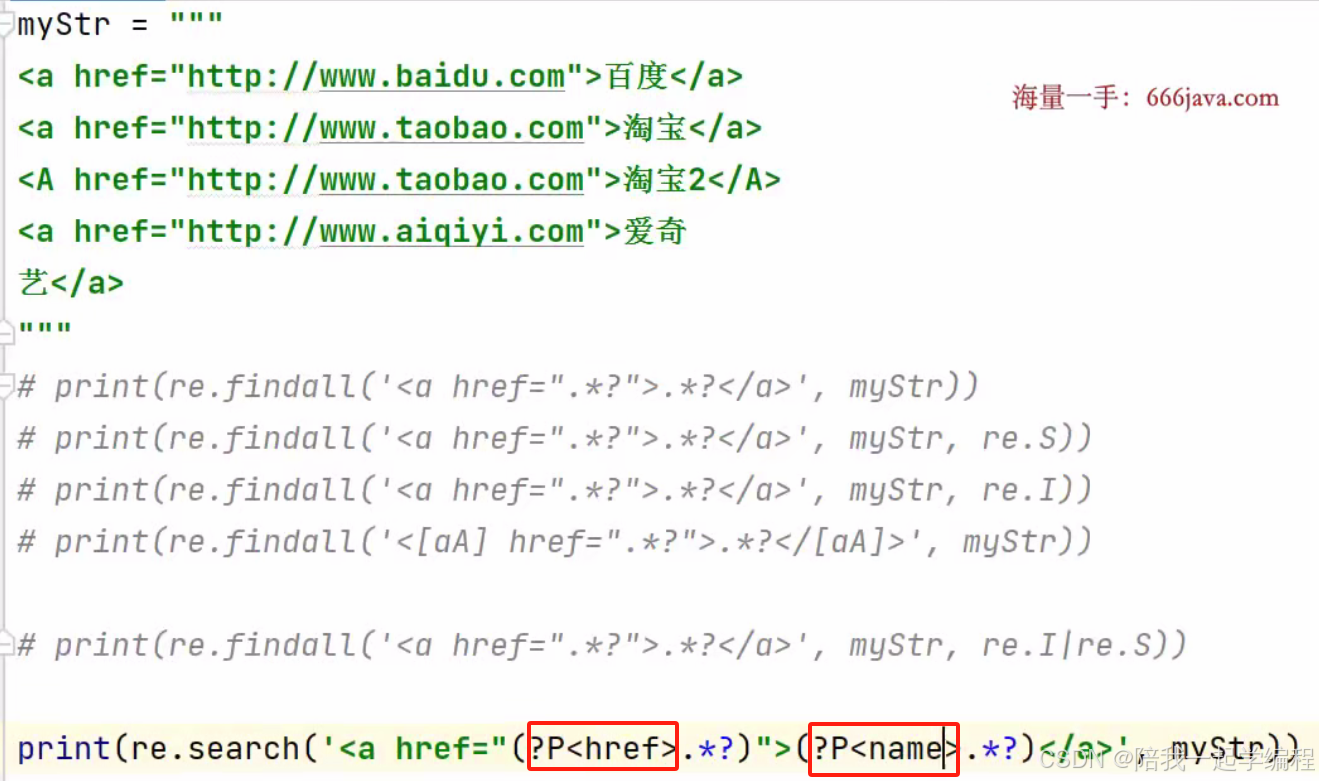
当然,也可以为( ) 取值的内容命名
【3】re.match(“表达式”, “要匹配的字符串”)
会自动在表达式前加上^, 表示以xxx开头进行匹配;
匹配到就返回一个对象,用group()取值;
匹配不到返回None
和re.search()同样也是匹配成功后就停止匹配,像“短路”
【4】re.finditer(“表达式”, “要匹配的字符串”)
返回一个迭代器,通过for循环调用group()取值;
常用于长字符串的匹配;
也常用于匹配到的项比较多

可降低内存占用率和空间复杂度,从而提高时间效率
【5】re.complie(“表达式”)
返回一个编译好的正则表达式对象;
当一个表达式较长且需要反复使用到,
可调用该方法,将其缓存到内存中,
再通过该对象调用匹配方法(findall、search、match、finditer)即可;
以此降低时间复杂度
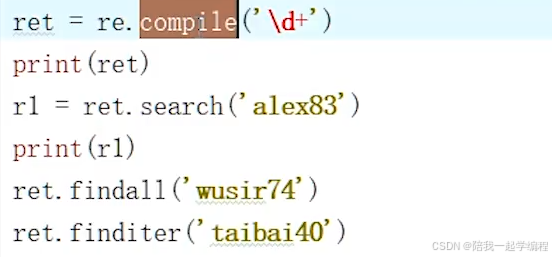
【6】re.split(“表达式”, “要匹配的字符串”)
根据正则表达式对匹配的字符串进行分割,
将分割好的每一项放进列表中;
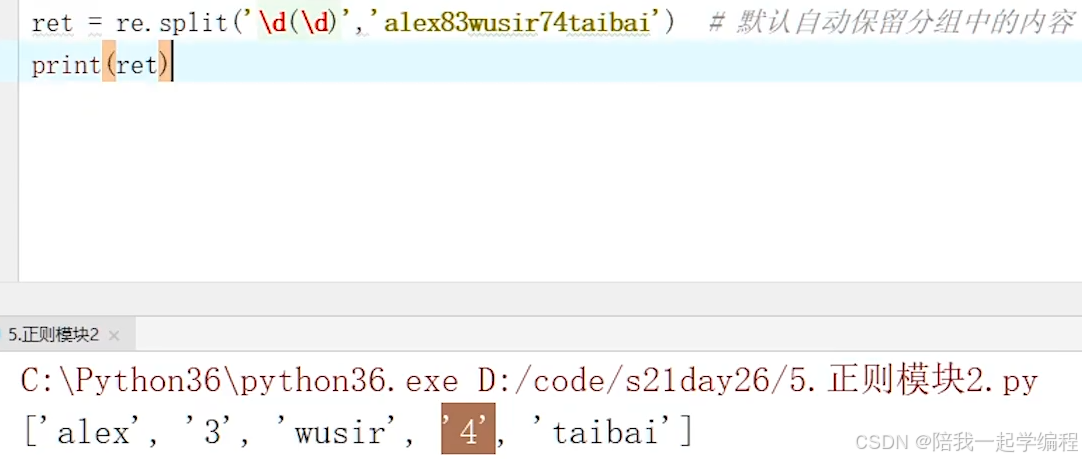
若要将表达式匹配到的字符串保留到列表中,可加上()
默认不会将表达式匹配到的字符串保留到列表中
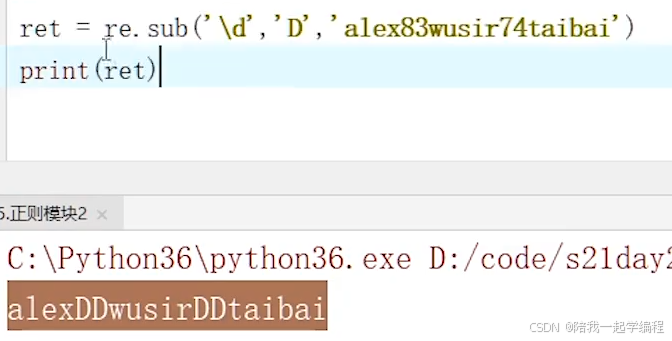
【7】re.sub(“表达式”, “要替换的值”, “要匹配的字符串”, 要替换前n个)
根据表达式字符串进行匹配,
对匹配到的内容替换为第二个参数的值
【8】re.subn(“表达式”, “要替换的值”, “要匹配的字符串”)
效果和sub()类似,
返回一个元组,
第一个元素是替换后的结果,第二个元素是替换了几个
1.6.3 分组
【1】分组命名

多个分组时可以该形式对不同分组命名
【2】引用分组
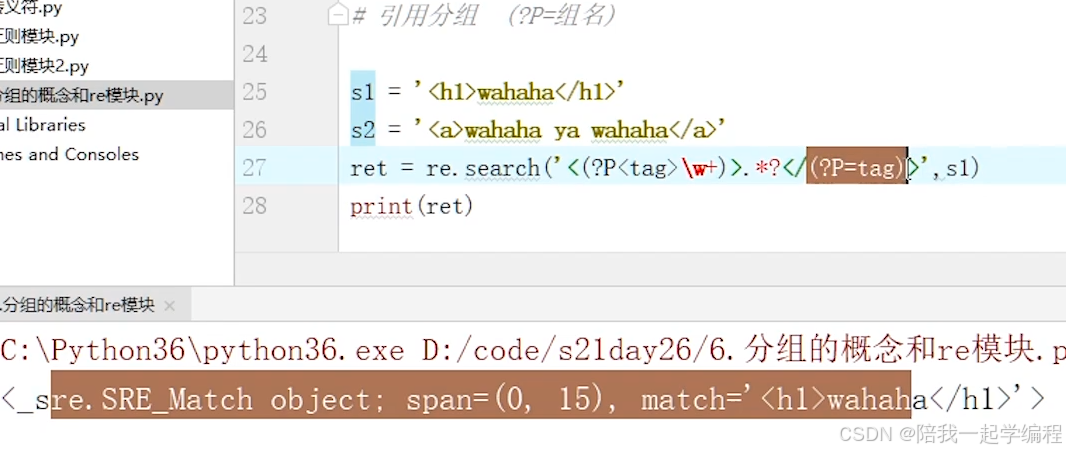
某分组中的表达式若和某分组相同,可对其引
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











