







现有如下图所示的学生信息,请根据图中的信息完成以下操作。(10分)
| 年级 | 姓名 | 年龄 | 性别 | 身高(cm) | 体重(kg) | |
| 1 | 大一 | 李思珍 | 18 | 男 | 175 | 65 |
| 2 | 大二 | 李红卓 | 19 | 女 | 165 | 60 |
| 3 | 大三 | 张市政 | 20 | 男 | 178 | 70 |
| 4 | 大四 | 赵鸿飞 | 21 | 男 | 175 | 75 |
| 5 | 大二 | 白荣 | 19 | 女 | 160 | 55 |
| 6 | 大三 | 马腾飞 | 20 | 男 | 180 | 70 |
| 7 | 大一 | 张晓峰 | 18 | 女 | 167 | 52 |
| 8 | 大三 | 张林海 | 20 | 女 | 170 | 53 |
| 9 | 大四 | 王一浩 | 21 | 男 | 185 | 73 |
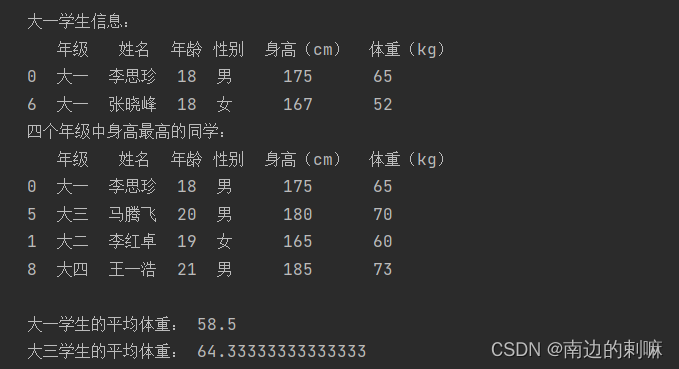
(1)以年级信息为分组键,对学生信息进行分组,并输出大一学生信息。
(2)分别计算出四个年级中身高最高的同学。
(3)计算大一学生与大三学生的平均体重。
import pandas as pd
# 创建DataFrame对象
data = {'年级': ['大一', '大二', '大三', '大四', '大二', '大三', '大一', '大三', '大四'],
'姓名': ['李思珍', '李红卓', '张市政', '赵鸿飞', '白荣', '马腾飞', '张晓峰', '张林海', '王一浩'],
'年龄': [18, 19, 20, 21, 19, 20, 18, 20, 21],
'性别': ['男', '女', '男', '男', '女', '男', '女', '女', '男'],
'身高(cm)': [175, 165, 178, 175, 160, 180, 167, 170, 185],
'体重(kg)': [65, 60, 70, 75, 55, 70, 52, 53, 73]}
df = pd.DataFrame(data)
# (1) 以年级信息为分组键,输出大一学生信息
df1 = df[df['年级'] == '大一']
print("大一学生信息:")
print(df1)
# (2) 分别计算出四个年级中身高最高的同学
heightmax = df.loc[df.groupby('年级')['身高(cm)'].idxmax()]
print("四个年级中身高最高的同学:")
print(heightmax)
# (3) 计算大一学生与大三学生的平均体重
df2 = df[df['年级'] == '大一']['体重(kg)'].mean()
df3= df[df['年级'] == '大三']['体重(kg)'].mean()
print("\n大一学生的平均体重:", df2)
print("大三学生的平均体重:", df3)
结果:


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









