









Zookeeper的介绍
Zookeeper是一款apache社区开源的基于内存的,能够完成分布式协调服务的一个应用,其目的就是让分布式的一些协调变的简单
特性
-
顺序一致性 - 客户端的更新将按发送顺序应用。
-
原子性 - 更新要么成功要么失败。没有部分结果。
-
全局数据一致性:在集群中每个节点都保存相同的数据,无论修改哪个节点,最终所有节点的数据都会一致
-
实时性 - 系统的客户视图保证在特定时间范围内是最新的。
-
极其高可用
如果我们的Zookeeper服务是单节点,那肯定会想到单点故障问题。事实上一个leader挂掉,在200ms内就能恢复,重新选举出一个新的leader,所以Zookeeper的可靠性来自于其快速恢复
Zookeeper的作用
统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。
统一配置管理
分布式环境下,配置文件同步非常常见,一般要求一个集群中,所有节点的配置信息是一致的,配置管理可交由ZooKeeper实现。
实现方式:通过Zookeeper监听机制,各个客户端服务器监听这个Znode。 一旦Znode中的数据被修改,ZooKeeper将通知各个客户端服务器,快速进行配置信息的同步
统一集群管理
分布式环境中,实时掌握每个节点的状态是必要的。 可根据节点实时状态做出一些调整。
ZooKeeper可以实现实时监控节点状态变化
- 将节点信息写入ZooKeeper上的一个ZNode。
- 监听这个ZNode可获取它的实时状态变化。
监听服务动态上下线
Zookeeper的使用
./zkServer.sh help # 查看通过zkServer.sh可以使用的命令
./zkServer.sh start # 启动Zookeeper
./zkServer.sh start-foreground # 后台启动zookeeper
./zkServer/sh status # 查看当前Zookeeper节点的状态,看是leader还是follower
# 添加数据
create 路径 "数据"
# 查询数据
ls / # 显示根目录
ls 路径 # 显示路径下的数据
get 路径 # 获取具体路径下的数据
节点类型
按持久和非持久类型可将节点分为:
- 持久节点:节点及数据实现了持久化保存
- 临时节点:只要客户端断开连接临时节点就会消失(基于session,后续介绍)
按照带序号和不带序号的类型可将节点分为:
-
不带序列号的节点
-
带序列号的节点
因此可以两两组合创建出四种类型的节点
create /xxoo "" # 创建不带序列号的持久节点
create -s /xxoo "" # 创建带序列号的持久节点
create -s -e /xxoo "" # 创建带序列号的临时节点
create -e /ooxx "" # 创建不带序列号的临时节点
创建完后查看节点

断开客户端,重新连接后再次查看节点
发现临时节点已经消失
注:
- 对于不带序列号的节点,不管是持久的还是临时的相同名字只能创建一个
- 对于带序列号的节点,不管是持久的还是临时的相同名字可以创建多个,且Zookeeper内部维护了节点的序列化,因此序列号为递增
节点参数
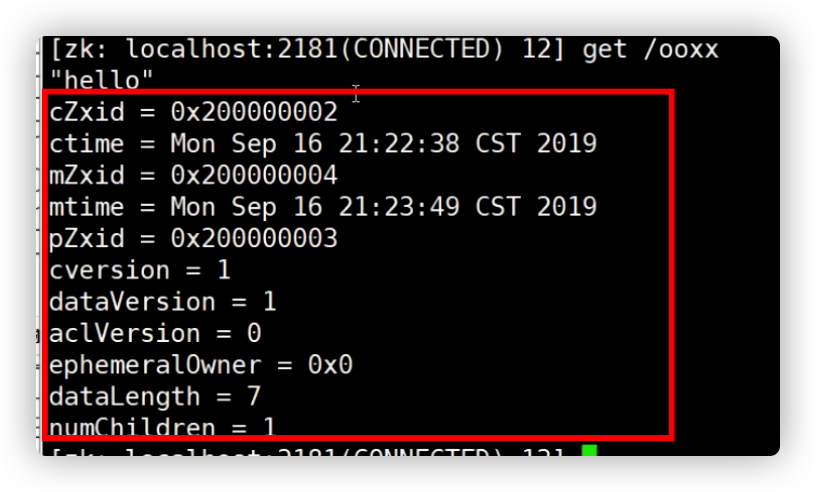
cZxid:创建节点的事务ID
如图,cZid是一个64位组成的事务id。一个数字代表十六进制,一个十六进制代表4位。00000002后32位代表事务递增的序列,前32 位(因为高位补零所以省略)代表leader的纪元(leader序号,如果leader更新,会自动增加leader的纪元号)
**cTime:**创建节点的时间
**mZid:**修改节点的事务id
**mTime:**修改节点的时间
**pZxid:**当前节点下创建的最后一个节点的事务id
cVersion:版本号
ephemeralOwner:如果是持久节点那么没有ephemeralOwner,如果是临时节点,则ephemeralOwner为sessionId的值,属于会话的
ZooKeeper集群中的机器,每台机器不能重
复,和myid一致。
Epoch:每个Leader任期的代号。没有
Leader时同一轮投票过程中的逻辑时钟值是
相同的。每投完一次票这个数据就会增加
配置文件
其中最重要的地方是以下:
server.1=192.168.31.132:2888:3888
server.2=192.168.31.180:2888:3888
server.3=192.168.31.94:2888:3888
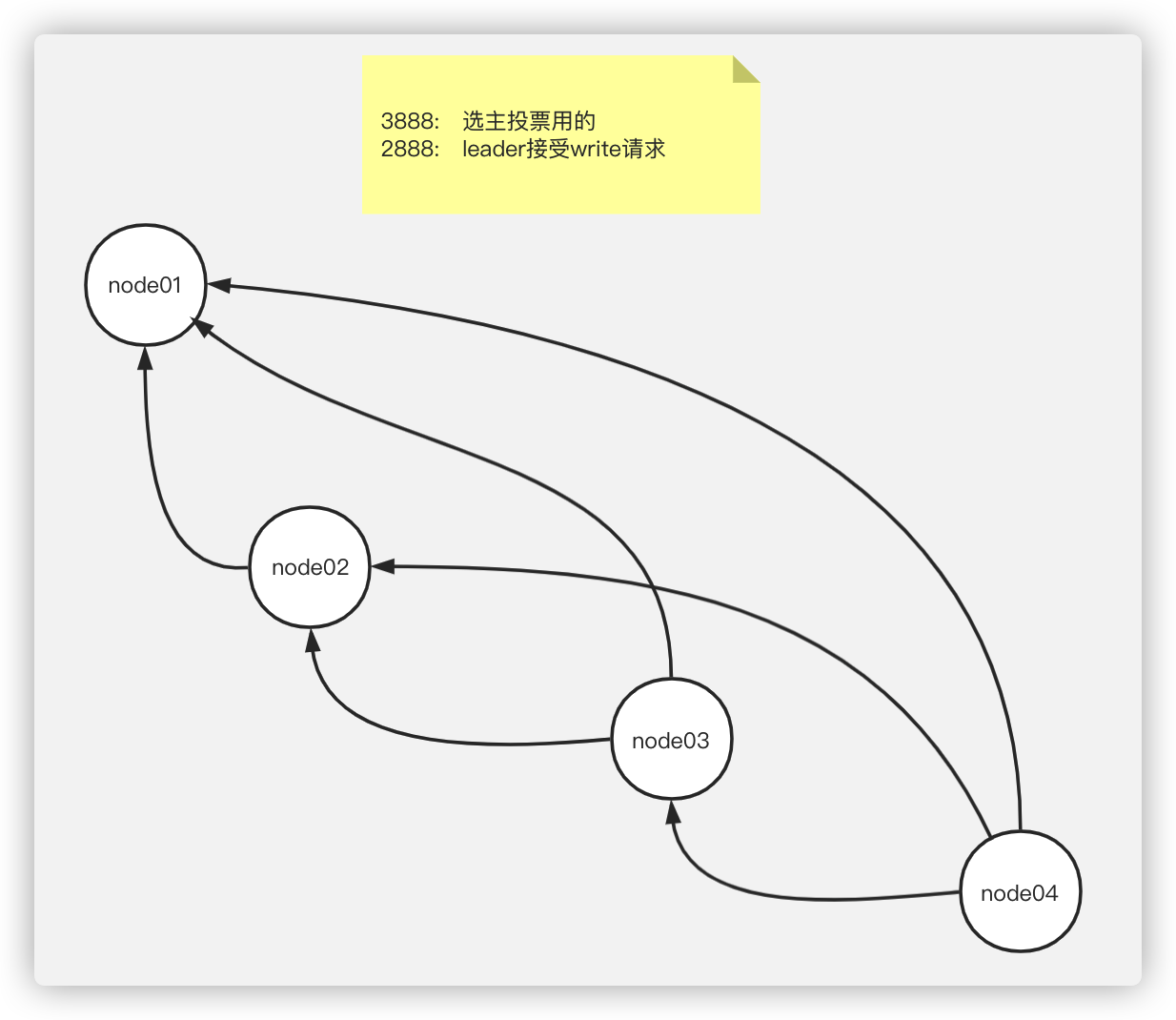
server后面的序号对应myid的序号,ip对应集群中机器的ip地址
端口号说明
- 3888:用来选主,在没有leader主机的时候,建立连接通信投票选出leader
- 2888:选完leader后启动2888,其他节点通过2888端口号和leader同步数据
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just example sakes.
dataDir=/var/zookeeperData
dataDir为快照保存地,不要使用默认,要自己手动创建文件夹,在文件夹里创建myid文件
zookeeper各节点中的通信连接关系图:
paxos和zab
paxos
某个周的议员通过开会决定电费价格,议会有一个目标:保证所有的议员对于提议都能达成一致的看法。
现在议会开始运作,所有议员开始记事本上面记录的编号都是0。有一个议员发了一个提议:将电费设定为1元/度。他首先看了一下记事本,当前提议编号是0,那么我的这个提议的编号就是1,于是他给所有议员发消息:1号提议,设定电费1元/度。其他议员收到消息以后查了一下记事本:当前提议编号是0,这个提议可接受,于是他记录下这个提议并回复:我接受你的1号提议,同时他在记事本上记录:当前提议编号为1。发起提议的议员收到了超过半数的回复,立即给所有人发通知:1号提议生效!收到的议员会修改他的记事本,将1号提议由记录改成正式的法令,当有人问他电费为多少时,他会查看法令并告诉对方:1元/度。
现在看冲突的解决:假设总共有三个议员S1-S3,S1和S2同时发起了一个提议:1号提议,设定电费。S1想设为1元/度,S2想设为2元/度。结果S3先收到了S1的提议,于是他做了和前面同样的操作。紧接着他又收到了S2的提议,结果他一查记事本,咦,这个提议的编号小于等于我的当前编号1,于是他拒绝了这个提议:对不起,这个提议先前提过了。于是S2的提议被拒绝,S1正式发布了提议:1号提议生效。S2向S1或者S3打听并更新了1号法令的内容,然后他可以选择继续发起2号提议。
zab协议
zab协议是基于paxos进行的简化
涉及到两阶段提交的过程
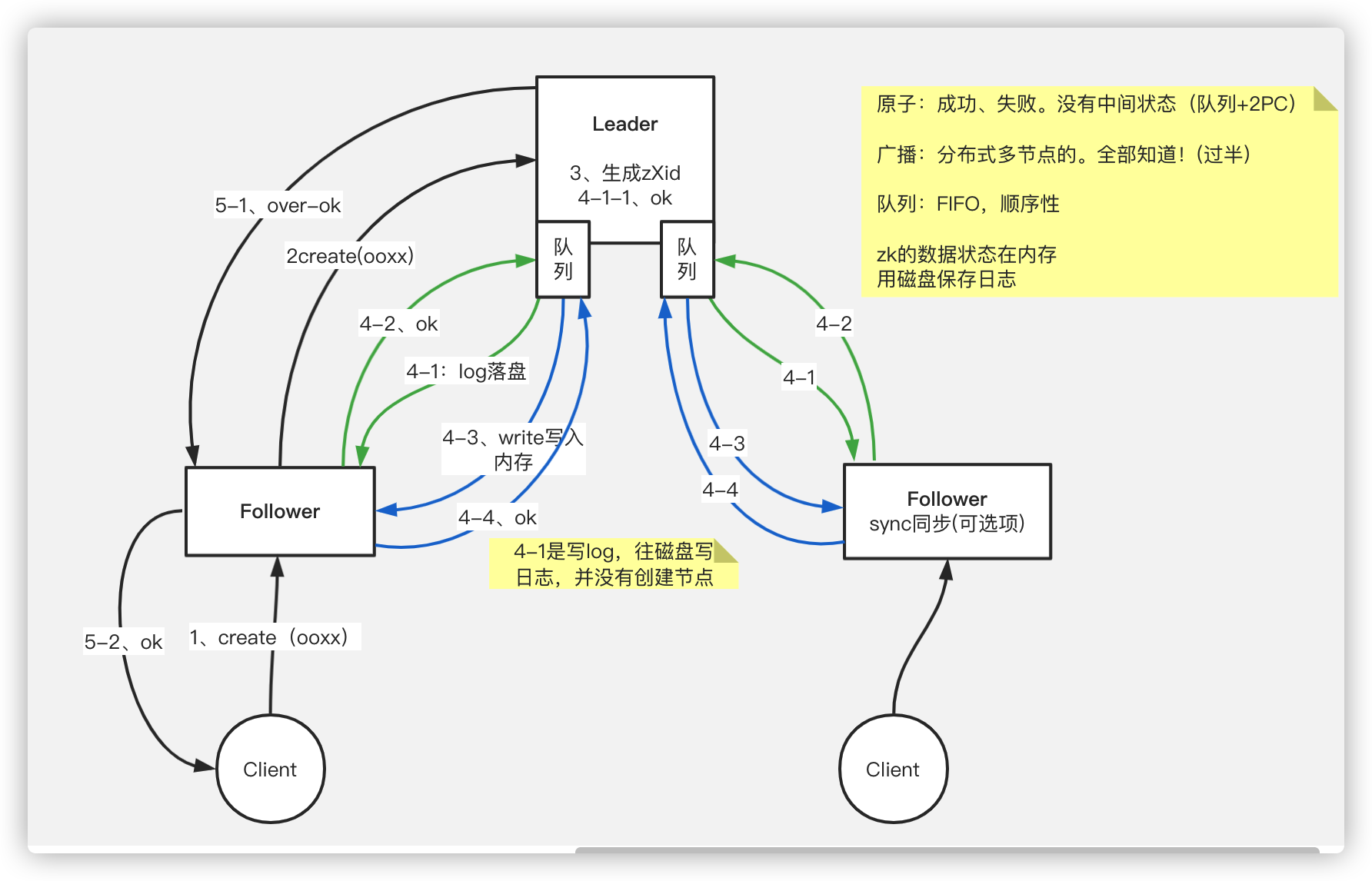
leader的选举过程
集群中每个节点都是通过如上图所示的网状连接,因此每个节点都会进行通信,往其他节点中的队列发送消息
- 选举过程通过3888端口进行两两通信
- 只要任何节点先开始发起投票,都会触发任何节点发起自己的投票,也会触发准leader发起自己的投票
- 推选制,先比较zXid,如果zXid相同再比较myid(其实大部分时间都是zXid相同,都是比较myid)
leader的选举场景分三类
第一次启动集群(此时无版本,无历史数据)
-
服务器1启 动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
-
服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1) 大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
-
服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
-
服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
首次启动集群的leader选举很好理解,即选择超过半数时myid最大的节点作为leader
注:有4个节点myid分别为1、2、3、4,最终的leader是谁?
可能是3、也可能是4,因为要4台节点过半,最大的要么是3,要么是4(2、3、4 ; 1、3、4 ; 1、2、4 ; 1、2、3 ; 1、2、3、4)
重启集群(曾经有过leader和一些数据)
场景举例:
假设四个节点组成的集群,曾经4号节点为leader,突然leader在数据没有同步到三号节点的时候挂掉了
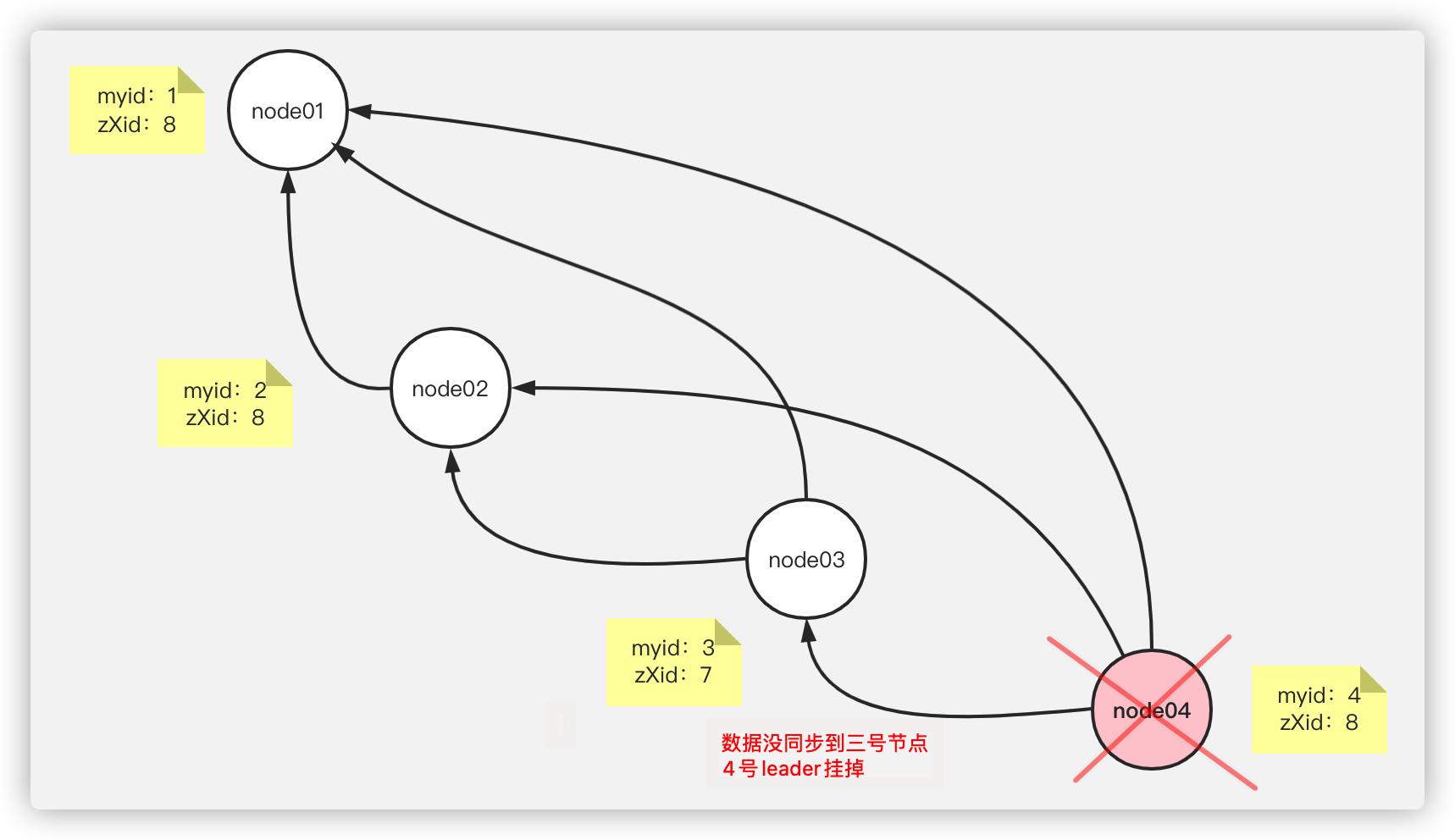
第二步:
node3先检测到leader挂了,那么node3会通过socket连接向node1和node2发送数据,携带自身的myid和zXid
node1和node2检测到node3发来的zXid比自身的小,将node3否决,并将自身的数据发给node3来进行纠正
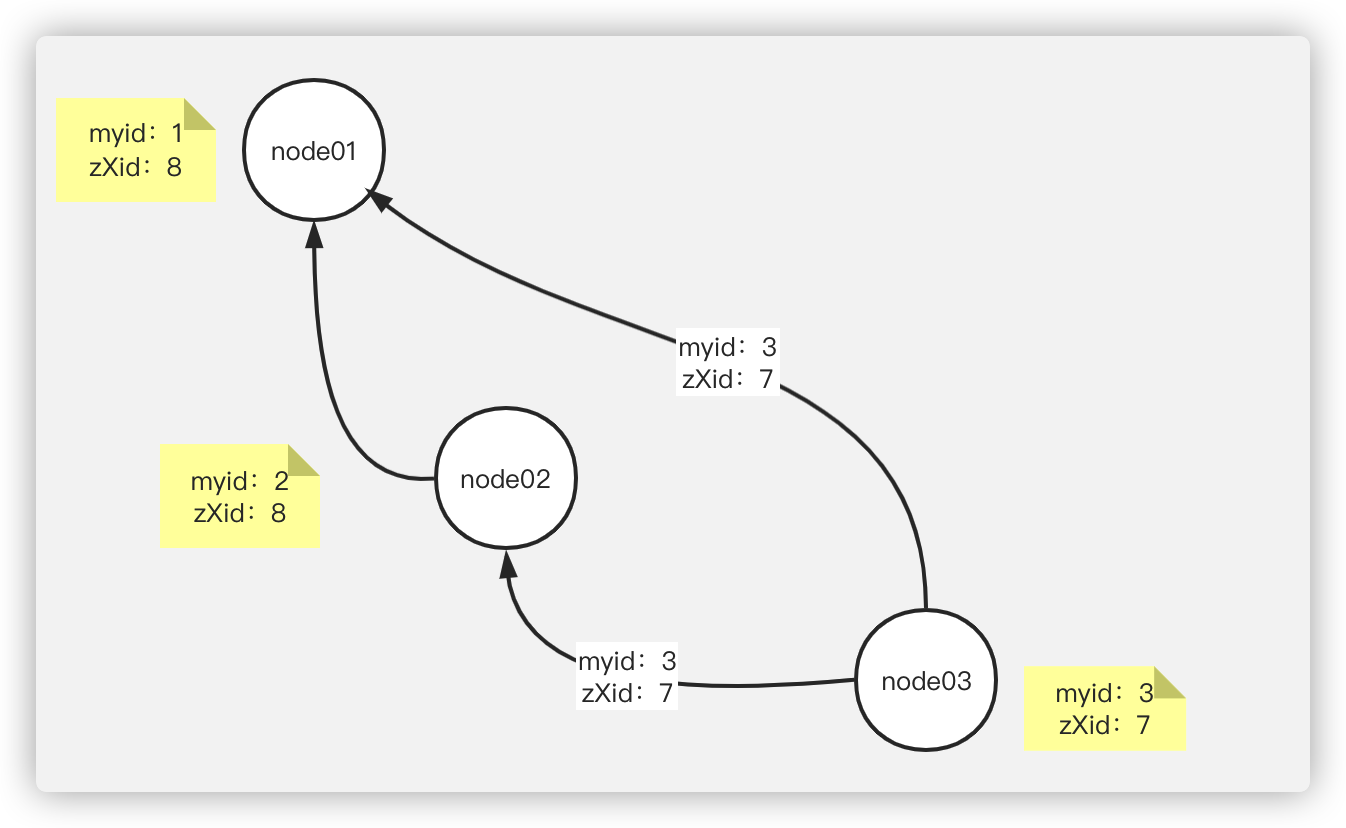
收到票的节点会被动触发自己给自己投票,且把自己的票传给与之相连的其他节点
具体投票过程如下:
-
node3:率先发起投票,node03给自己投了一票,然后将数据传给node1和node2,收到票的节点会被动触发自己给自己投票,且把自己的票传给与之相连的其他节点。
因此:
node2:给自己投一票,并将票传到node1和node3
node1:给自己投一票,并将票传到node2和node3
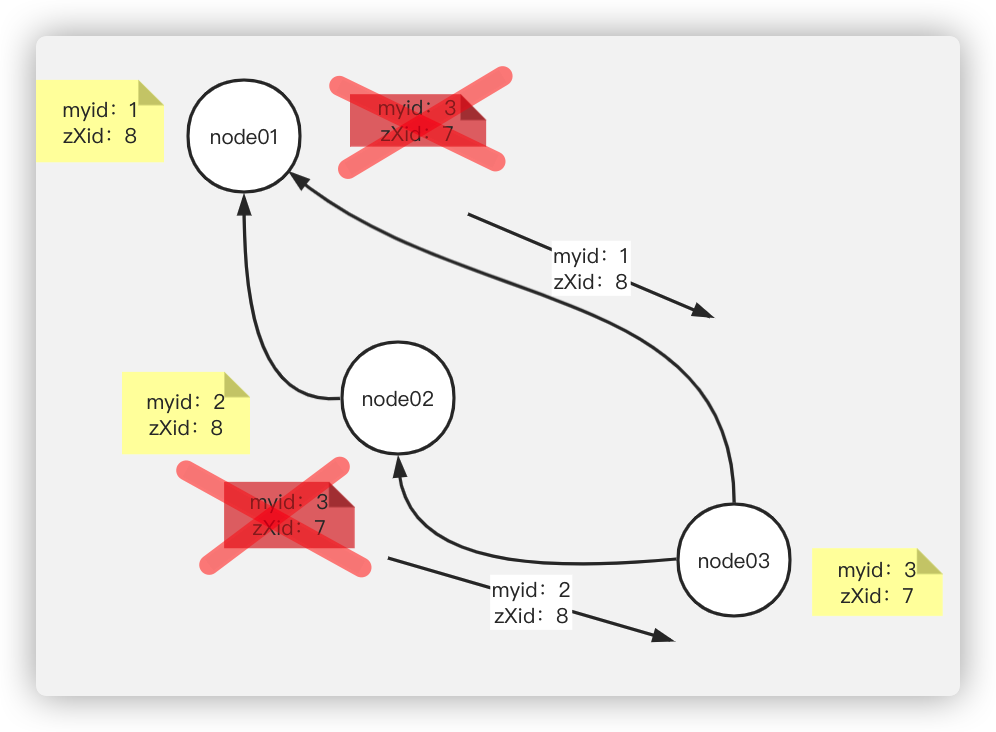
此时node1、node2、node3的票数为:
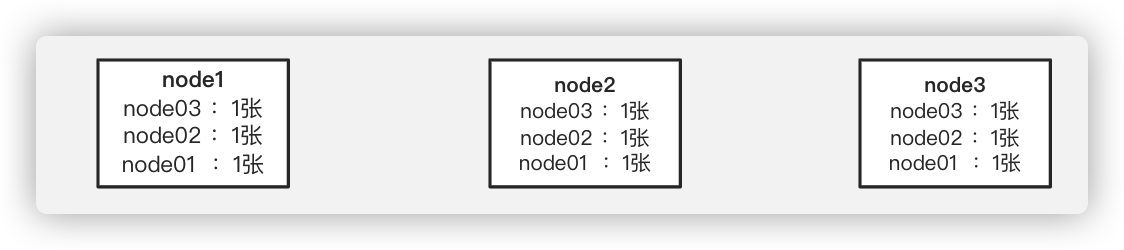
-
node1:发现node2传来的票的zXid和自己相同,myid比自己大,因此node1会给node2投票,将票传给node2和node3。
此时node1、node2、node3的票数为:
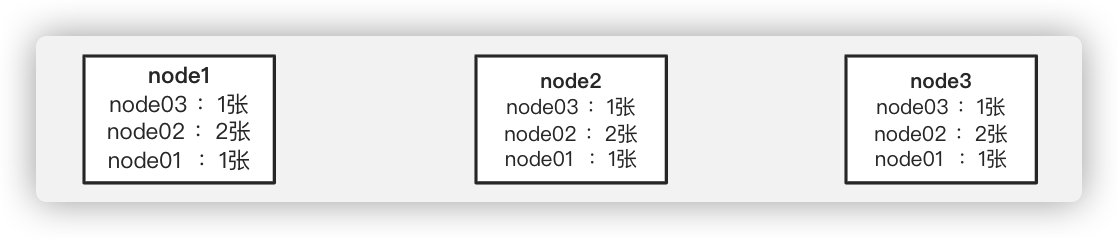
-
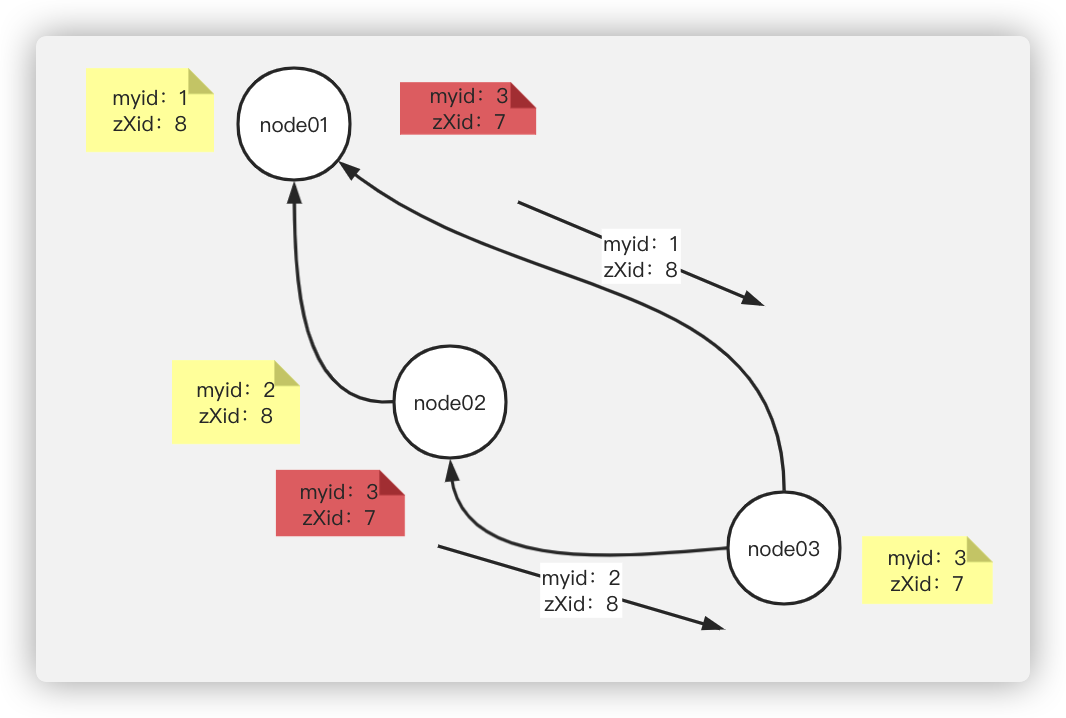
node3:发现传来的票的zXid比自己大,且node2的myid更大,因此node3再给node2投,并传给node1和node2
最终,node1、node2、node3的票数为:
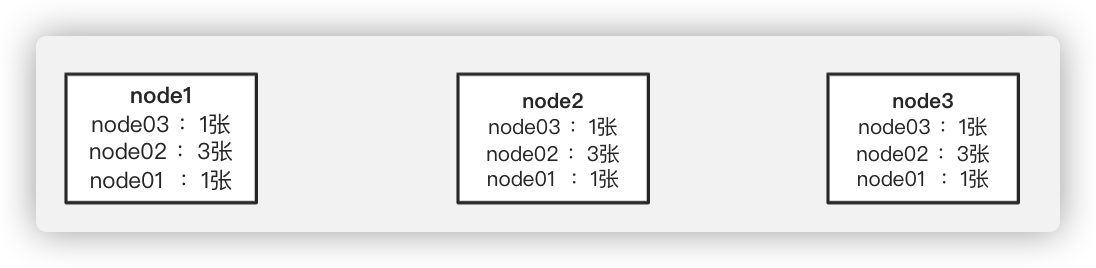
因此,最终认定leader为node2
leader挂了以后(曾经有过一些数据)
每个节点都有自己的myid和cZxid这两个重要的
leader挂掉什么样的节点才能当leader?
- zXid最高的(经验最丰富的)
- 过半通过的















 464
464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









