






1、前言
VGG16 是由牛津大学视觉几何组(Visual Geometry Group, VGG)在2014年提出的一种深度卷积神经网络架构。其网络结构非常规整,主要包括以下部分:
输入层:接收大小为 224x224x3 的彩色图像。
卷积层:包含多个卷积层,每个卷积层都使用 3x3 的小卷积核进行特征提取。每个卷积层后面都跟着一个 ReLU 激活函数,用于增加网络的非线性。通过重复堆叠卷积层,VGG16 实现了更强的特征学习能力。
池化层:VGG16 使用 2x2 的最大池化层进行空间降采样,减少特征图尺寸,提高计算效率。最大池化层可以提取特征图中的局部最大值,对图像的平移、旋转等变换具有一定的不变性,从而增强特征的鲁棒性。
全连接层:在卷积层和池化层之后,VGG16 连接了三个全连接层。最后一个全连接层用于输出分类结果
此外,VGG16 的小卷积核还具有减少参数数量、降低模型复杂度、增加网络深度、提高非线性能力、降低特征维度和减少计算量等优势。
VGG16 是一种具有简洁设计、出色性能和广泛应用场景的深度卷积神经网络架构。它在图像分类、目标检测、图像分割和人脸识别等计算机视觉任务中发挥着重要作用。
2、网络结构图
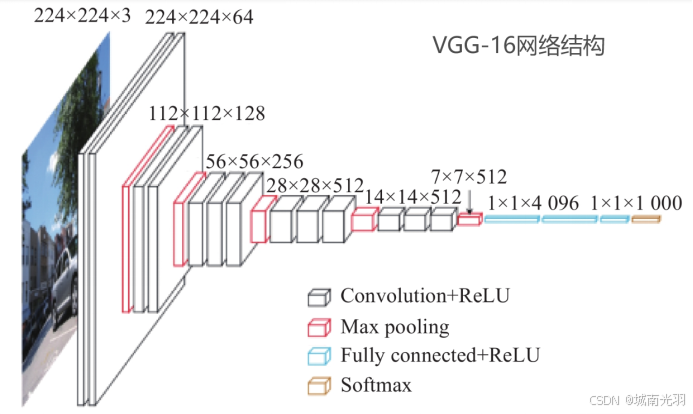
对于VGG16这个经典模型,其设计是基于224x224大小的输入图像的,输入图像维度是224*224*3,图片大小是224*224,通道数是3
3、图像大小的计算
padding(填充)是指在输入图像周围添加额外的像素,以便在进行卷积操作时可以保持输入和输出的尺寸相同或者更接近。padding='same' 是一种常见的填充方式,它的含义是将输入的每一侧都填充足够的零值,以使输出与输入的尺寸相同
通常图像大小的计算公式是:(假设输入图像的大小为NxN,卷积核的大小为FxF)
- 若无填充(padding=‘valid’),则输出图像大小为(N-F+1)x(N-F+1)。
- 若有填充(padding=‘same’),则在输入图像的周围填充了P个像素,使得输出图像的大小变为N+2P。
通常选择填充的数量 P,使得输出图像的大小与输入图像的大小相同。这样做有助于在卷积操作中保持输入输出尺寸的一致性,同时有助于减少信息丢失。
例如:在第一层的224*224图像中,卷积核为3*3,padding=1,则在224*224图像外围添加1个单位的行和列(2P),图片就变成了226*226,最终输出图像大小就是(226-3+1)*(226-3+1)=224*224,和原始图片大小一样,保证了图像大小的一致性。
因此 VGG16 第一层代码如下:
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.relu1 = nn.ReLU(inplace=True)
【注:激活函数不会改变数据的维度。】
数据维度变化:224*224*3-->224*224*64
(卷积步长stride为1,所以还是224*224,而由于代码中通道数64,所以由3变成了64,最终224*224*64)
4、最大池化
最大池化层中通过在每个池化窗口(将输入特征图划分为不重叠的矩形区域)选择最大值来减小特征图的尺寸,从而于减少特征图的空间维度,降低模型的计算量,保留重要的特征
在VGG16中,最大池化层的池化窗口大小是2,步长也是2
self.max_pooling1 = nn.MaxPool2d(kernel_size=2, stride=2)
数据维度变化:224*224*64->112*112*64
(步长stride为2,每次移动2格子,刚好使得图像大小减半)
5、全连接
到了全连接层,数据维度已经变成 7*7*512 了。如果需要连接全连接层,就需要将数据展平: x = x.view(-1, 512*7*7)
-1表示:根据总的数据量和第二个占有的数据量大小,计算一个合适的值
在 PyTorch中.view()函数对张量进行形状变换时,可以用-1来表示一个特殊的值,它表示该维度的大小由函数自动推断而来,以保证张量的总元素数不变
例:假设输入张量 x 的形状是 (B, C, H, W),其中 B 表示批量大小,C 表示通道数,H 表示高度,W 表示宽度。假设在这之前的处理中,已经得到了一个形状为 ( B, 512, 7, 7 ) 的张量 x。如果使用 x.view(-1, 512*7*7),PyTorch 将会自动计算出第一个维度的大小,以确保总元素数不变,也就是保证张量的批量大小 B 不变。
这样就将数据维度变成 1*(512*7*7)=1*25088,当然这里的1,说的不太准确,准确来说应该是批数,因为卷积层的第一个参数是批数
# 全连接层部分 #数据维度变化
self.fc1 = nn.Linear(512 * 7 * 7, 4096)
self.relu14 = nn.ReLU(inplace=True) 1*(512*7*7)=1*25088->1*4096
self.fc2 = nn.Linear(4096, 4096)
self.relu15 = nn.ReLU(inplace=True) 1*4096->1*4096
self.dropout = nn.Dropout(),
self.fc3 = nn.Linear(4096, 1000) 1*4096->1*1000
nn.Dropout()是正则化,用来防止过拟合的
如果输入数据是1*3*224*224,经过VGG16 网络,输出就是1*1000;
如果输入数据是2*3*224*224,经过VGG16 网络,输出就是2*1000。这就是批数变化。
nn.Sequential() 是 PyTorch 中的一个容器,用于按顺序地将多个神经网络层组合在一起,构建一个神经网络模型。通过 nn.Sequential(),你可以方便地定义一个神经网络模型,按照你指定的顺序依次添加神经网络层。
torch.flatten(x, 1)的作用和.view()一样,也是用来展平操作的。
这里的 1,表示的就是 [ batch , 通道数 , 高 , 宽 ] 中的通道数所在的维度。
例:假设输入张量 x 的形状为 (B, C, H, W),其中 B 表示批量大小,C 表示通道数,H 表示高度,W 表示宽度。如果使用 torch.flatten(x, 1),则函数会将输入张量在通道维度上(维度索引从0开始,因此通道维度索引为1)进行展平,结果将是一个形状为 (B, CHW) 的一维张量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









