






行式存储结构: TEXTFILE , SEQUENCEFILE 行式存储磁盘占用比较高
列式存储结构:ORC ,PARQUETFILE 列式存储磁盘占用比较低,
orc的压缩率最高 , parquet 压缩率最低
ZLIB SNAPPY
连接jdbc的hive命令:
beeline -u jdbc:hive2://hadoop161:10000 -n root
set hive.server2.logging.opereation.level=none;
create table log_seqencefile(
uuid1 string, uuid2 string , uuid3 string , uuid4 string ,uuid5 string ,
uuid6 string
) row format delimited fields terminated by ',' stored as sequencefile : 行式存储(不压缩)
create table log_orc(
uuid1 string, uuid2 string , uuid3 string , uuid4 string ,uuid5 string ,
uuid6 string
) row format delimited fields terminated by ',' stored as orc
tblproperites ("orc.compress"="none") ; 列式存储 (不压缩)
数据插入情况
在插入数据的时候,需要先用textfile格式。
sequencefile 格式和ORC 格式
不能用 load data local inpath ‘/tmp/hive/log_uuid.csv’ into table log_orc; 导入 , 导入失败。
parquet 能导入,无法查询。只能用insert into table xxxx select * from log_textfile;(之前能成功导入和查询格式的表)
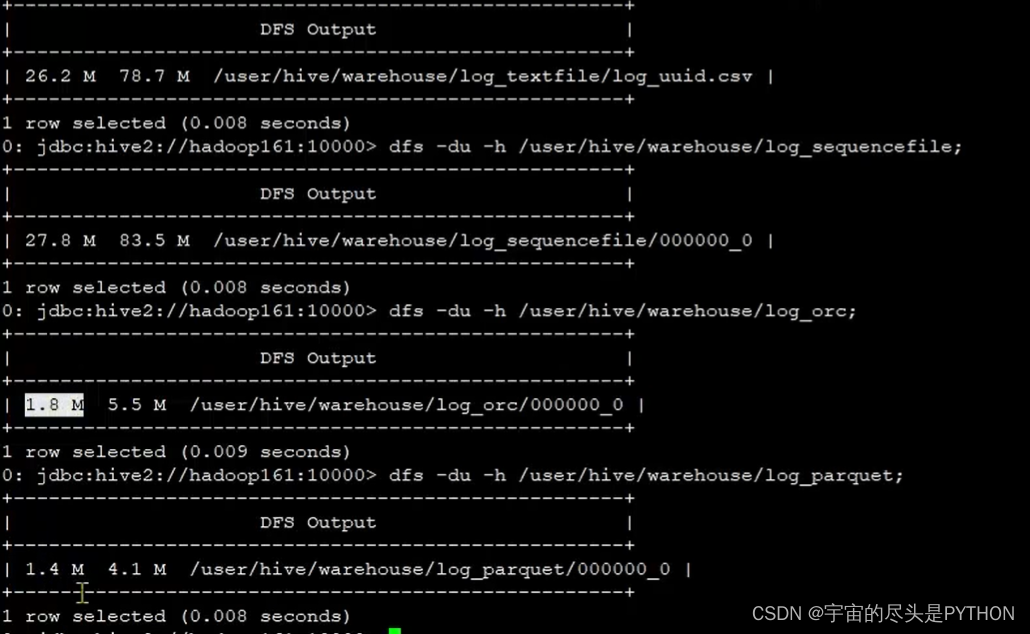
查看数据文件所占的大小的命令 :
dfs -du -h /user/hive/warehouse/log_textfile;
dfs output
26.2M 78.7M /user/hive/warehouse/log_textfile/log_uuid.csv |
可以看到 列式存储占的空间是1.4 到1.8兆。而行式存储占的空间为 26.2兆和27.8兆。
对列存储进行压缩是比较常见的。
两种压缩格式 ZLIB SNAPPY
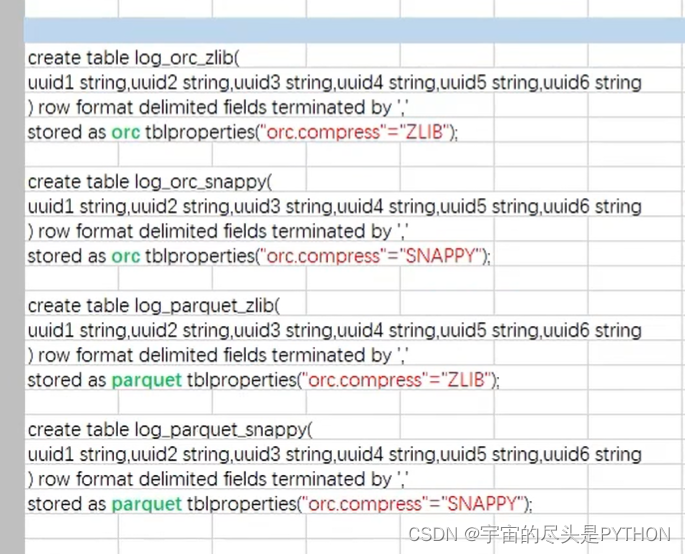
stored as orc tblproperties(''orc.compress'='ZLIB');
stored as orc tblproperties(''orc.compress'='SNAPPY');
stored as parquet tblproperties(''orc.compress'='ZLIB');
stored as parquet tblproperties(''orc.compress'='SNAPPY');
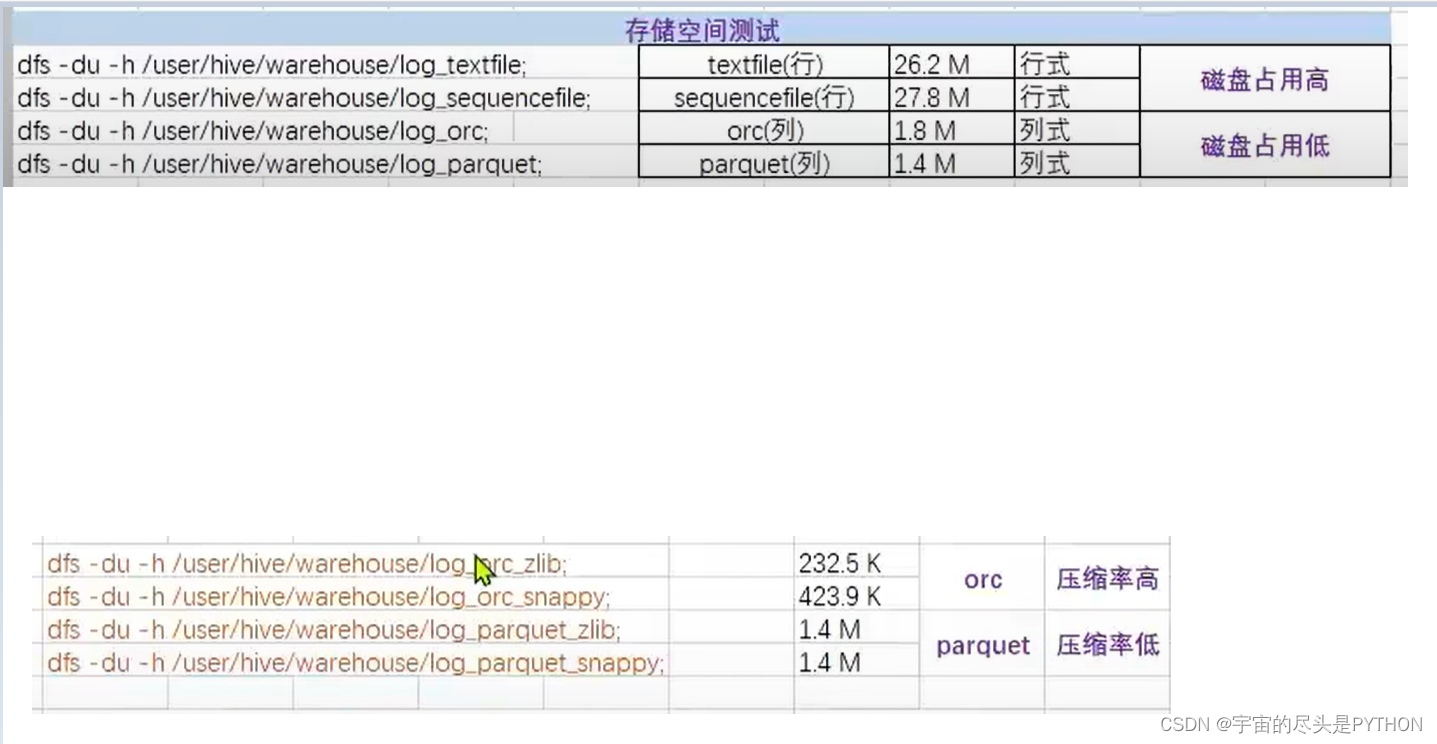
发现orc中的ZLIB 压缩格式可以把数据从 1.8M 压缩到 232.5 KB 压缩率为 12.6%; (232.5/1.8*1024 )
压缩前后 查询速度其实差别不大;
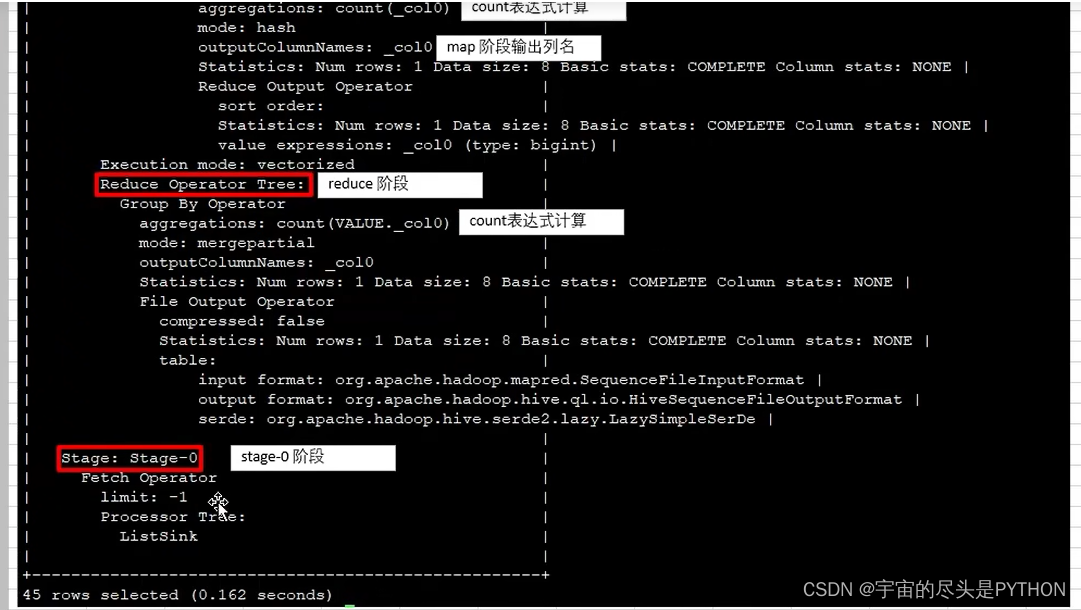
hive的执行计划
















 1797
1797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









