







为什么需要消息队列
1、削峰
高并发情况下,服务器通过集群模式(即多机部署),可以抗住几万的并发,但数据库能承受的并发量是有限的,若服务器将所有请求直接打向数据库,会直接把数据库打垮。如图所示:
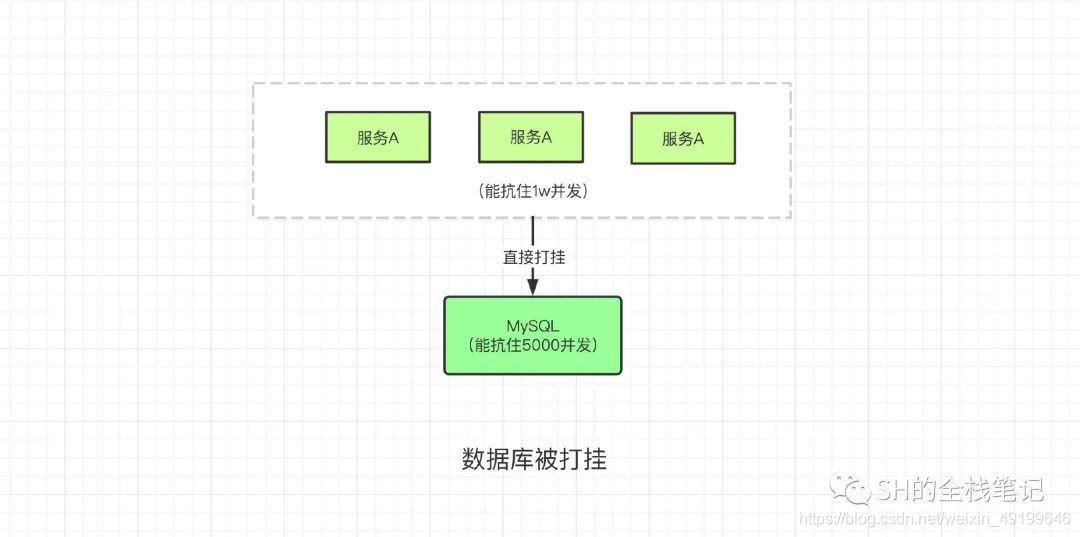
2、异步
对于实时性不是很高的业务,例如给用户发送短信、邮件通知,以及下单后的创建订单、削减库存等操作都可以放到消息队列里去。因为相对于核心订单流程来说,短信、邮件晚一些发送,对用户来说影响不是很大。同时还可以提升整个链路的响应时间。
1、解耦
多个服务通过消息队列关联在一起,相互之间不会产生耦合,一个服务挂了不影响其他服务。后续的可维护性、扩展性都大大提升。如:订单系统在创建了订单之后需要通知其他的所有系统,若通过rpc调用就把订单系统和其余的系统强耦合在了一起。若采用消息队列,就可以将所有服务关联在一起,订单服务只用往消息队列中发送消息,而其他服务则根据自己的消费能力依次消费消息即可。
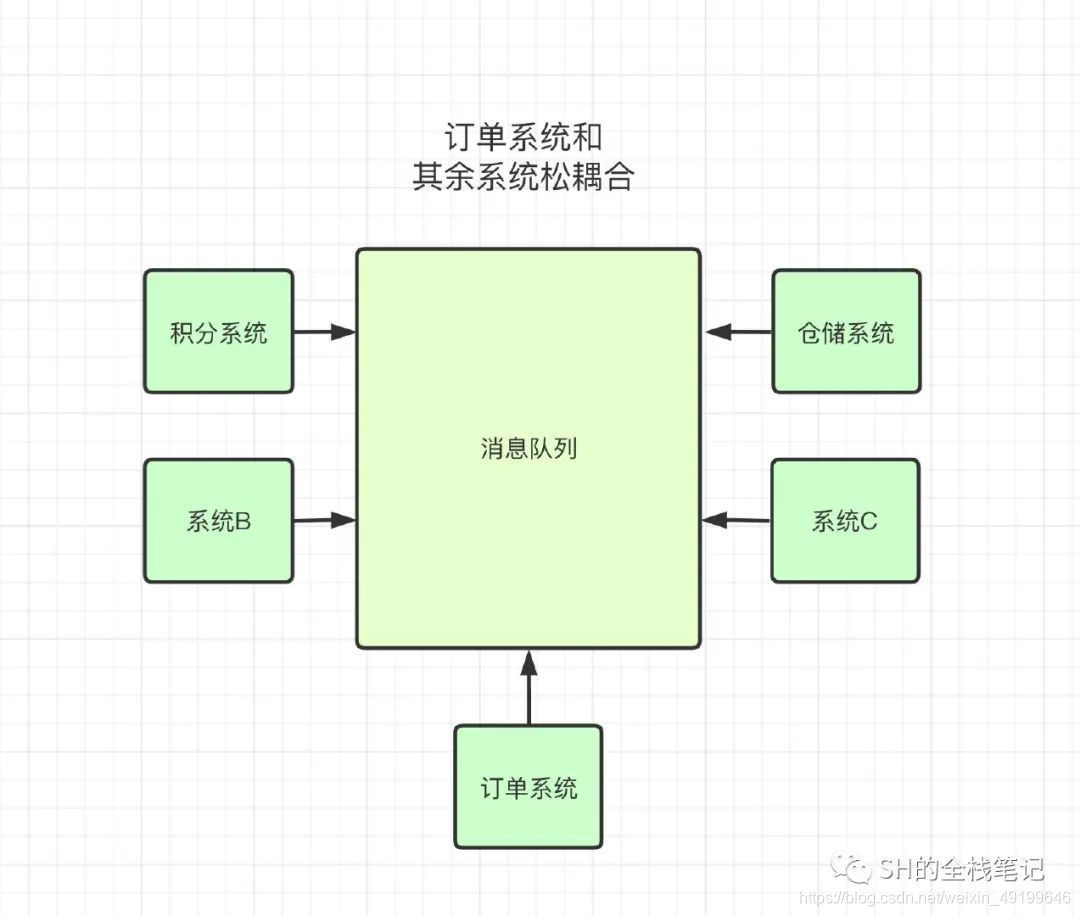
主流的消息队列选型
1、Kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,属于apache的开源项目,基于pull模式来消费消息。
优点:拥有很高的吞吐量,单机能够抗下十几w的并发,而且写入的性能也很高,能够达到毫秒级别。
缺点:高并发情况下可能会出现消息的丢失。
应用场景:用于大量数据的日志消息的收集,允许丢失一两条消息。
2、RabbitMQ
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。
优点:保证消息不丢失,可靠性高,且写入延迟可达到微秒级;
缺点:吞吐量只能达到几万;
应用场景:不允许消息丢失,且不会出现高并发的业务需求。
3、RocketMQ
RocketMQ是一个纯Java、分布式、队列模型的开源消息中间件,前身是MetaQ,是阿里参考Kaf
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2240
2240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









