






用一分钟的语音,就能让AI模仿我的声音,一键翻唱任意歌曲,你敢信?
上周的小和尚语录制作教程,很多友友都表示对AI克隆声音非常感兴趣,还发来了一段大合唱视频:
四郎和诸葛亮在线合唱
用AI克隆声音,仿佛真的是四郎和诸葛亮在线合唱,竟然毫无违和感,看着挺有意思的,难怪在互联网上一直热度不减。
很多人好奇,这样的翻唱视频是怎么制作的?
其实只需要AI克隆声音翻唱+对口型。GitHub上也有了比较成熟的SVC(歌声转换)技术,但本地部署对电脑配置要求高,还需要大量的语音素材去训练,我觉得很麻烦。
今天给大家分享两个超级简单的工具,上传一分钟的原声素材,点点点就行了,0基础小白,也能快速生成翻唱作品。
如果你电脑配置不高,直接用网页版,云端有大量的语音模型可以用于翻唱,不用花时间训练,效果还杠杠好,重点是完全免费!用起来简直不要太香。
01
Weights三步生成翻唱
选择模型、上传音频、微调设置
进入Weights官网(建议打开网页翻译功能),第一个板块就是超级多训练好的语音模型,直接免费用!点击查看全部,我们可以看到从虚拟角色到明星大佬,像海绵宝宝、迈克•杰克逊、霉霉、初音未来...挑起来真的是眼花缭乱。
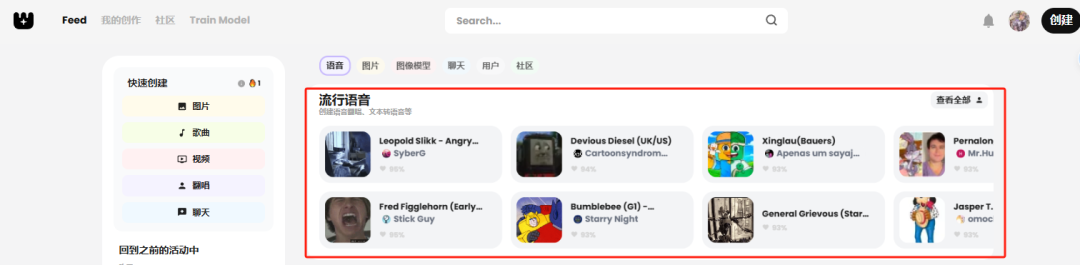
尝试搜了一下我的偶像,没想到他的语音模型居然有好几个,我选择了排名最靠前的这一个,点击右上角的创建,新建一个翻唱任务。
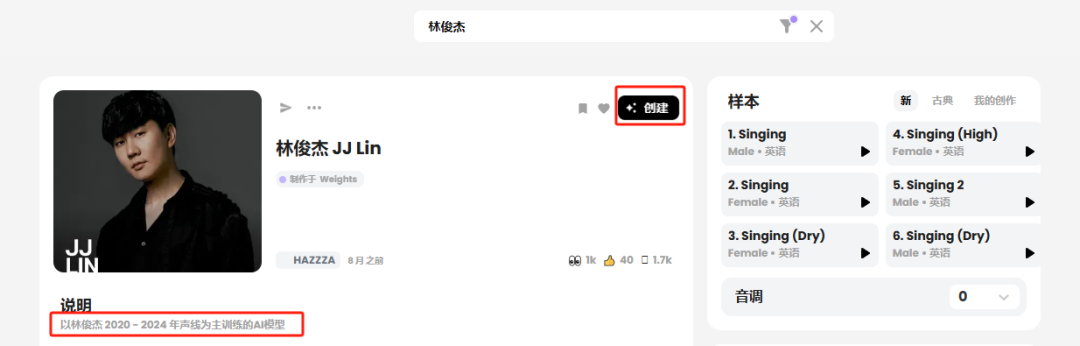
点击下一步。
翻唱的音频,我们可以直接复制YouTube链接上传,也可以直接将歌曲文件拖放进来。
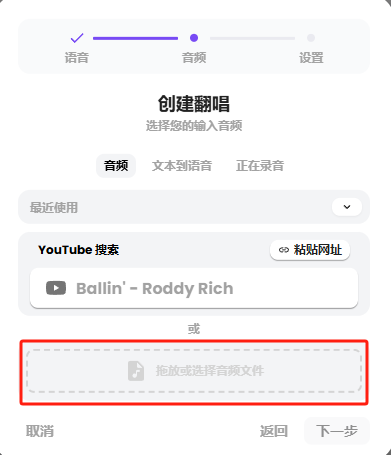
它不仅支持歌声翻唱,还可以输入文本转语音,或者直接用麦克风输入语音翻唱,这也太全面了~
和声、混响对翻唱效果都会有一些影响,所以这里我选择了一段单人清唱的音频。
上传音频后,点下一步。
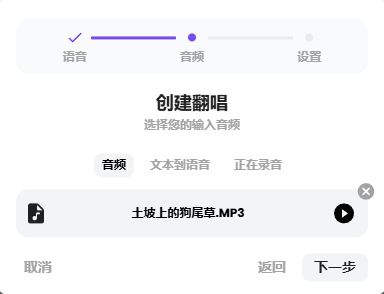
我上传的是仅人声的清唱,勾选上预混。音调方面,如果男声模型翻唱女声歌曲,可以适当调低一些音调,反之则调高;这里我们用默认即可。
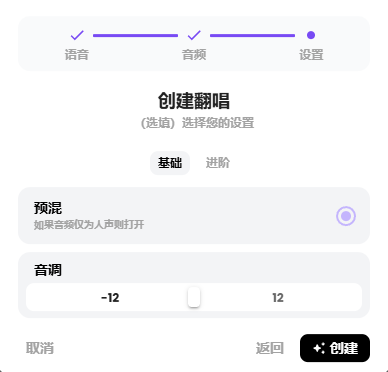
进阶的选项可以做一些更细致的调整,建议先用默认,如果生成的效果不满意,再进行微调。点击右下角的创建。
进入左上角我的创作,就可以看到翻唱歌曲正在排队生成啦,一般只需要等待几分钟。

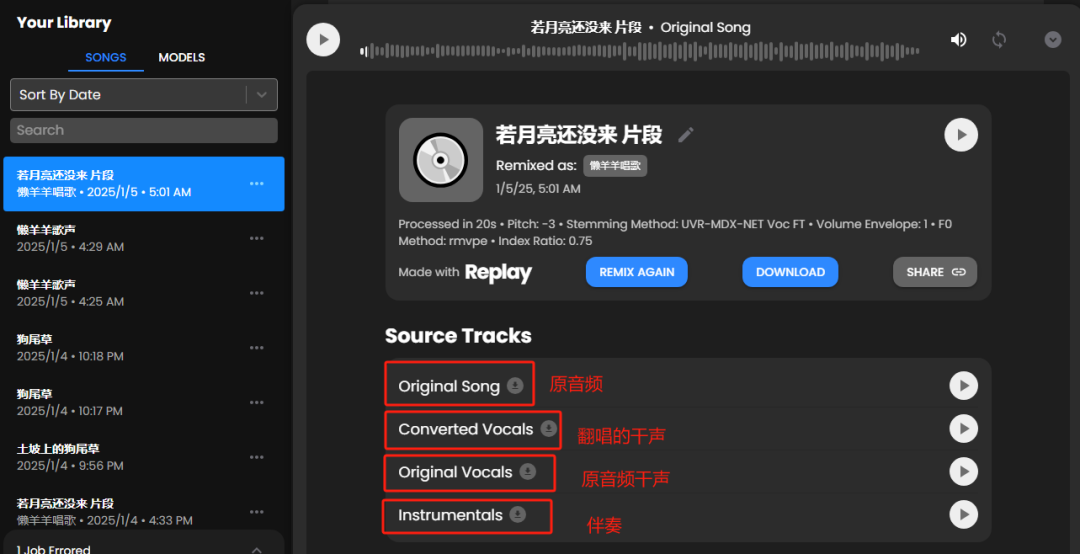
等列表里跳出成功的提示后,可以试听和下载。
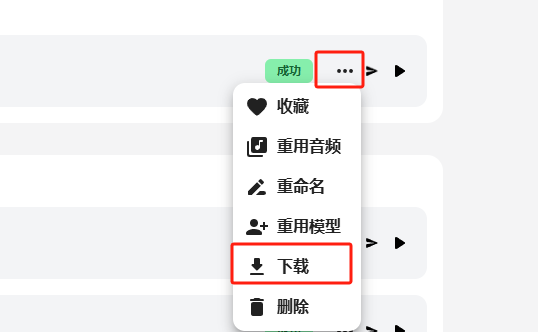
下载界面里的音频,依次是:翻唱后的人声+伴奏(如有)、翻唱后的干声、原始音频、原始音频中的干声、原始音频中的伴奏。

我们一起来听一下,翻唱后的音频。
声音很有特色,演唱的连贯自然,很有节奏感,转音、重音、高音表现都还不错。
而这整套操作下来,几分钟就完事了,可以说是有手就会。
同样的方法,我用周杰伦和邓紫棋的模型,也翻唱了一遍,一起来听一下。
我们将音频按照合唱的节奏切成几段,每一小段搭配一张Q版的人像,上传到即梦,生成对口型视频。
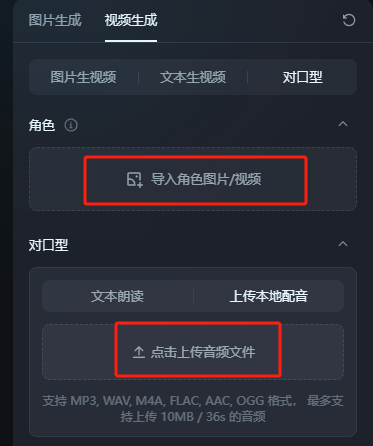
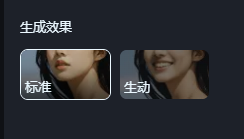
用图片对口型,生成效果一定要选择生动,不然标准的只动嘴不动头,看起来会很僵硬。
生成好的片段,用剪映组合,(如果有伴奏的话,加上伴奏),一个AI合唱视频就做完啦,我们来看看效果。
AI合唱视频
如果我想要自己创建语音模型来做翻唱,要怎么操作呢?
02
Replay一键分离人声
训练自己的语音模型
我们一起尝试做一个懒羊羊的声音模型和翻唱吧!
首先,需要进去Replay的官网,下载最新的软件。
要注意,安装软件之后,首次打开会弹出两个提示框,先别急着去点!!!先去左上角App-Show Settings修改一下文件保存位置。
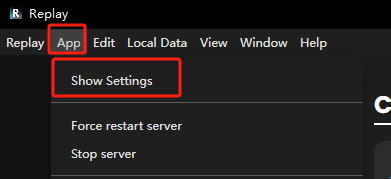
第一个文件夹是导出音频的位置。第二个文件夹是一些应用数据,语音模型、生成音频的数据等等都会保存在这里。总之,别放C盘,其它随意~
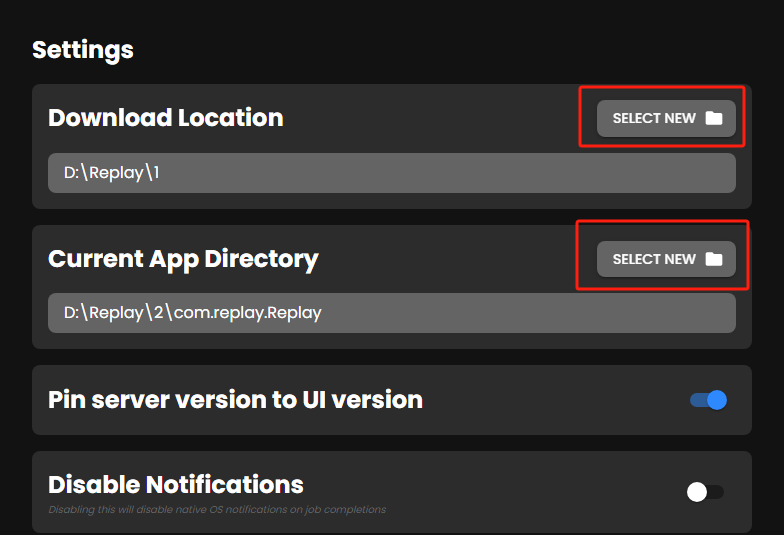
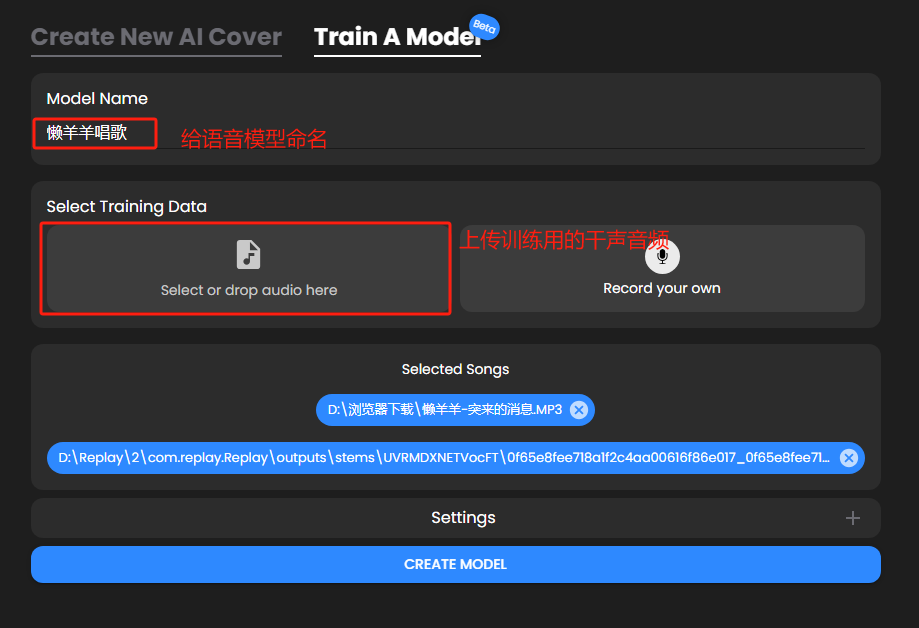
我们先从B站扒一段懒羊羊唱歌的视频,用剪映做一下前置处理,只保留懒羊羊声音的片段,导出为mp3/wav格式。将音频上传(如图所示位置)。
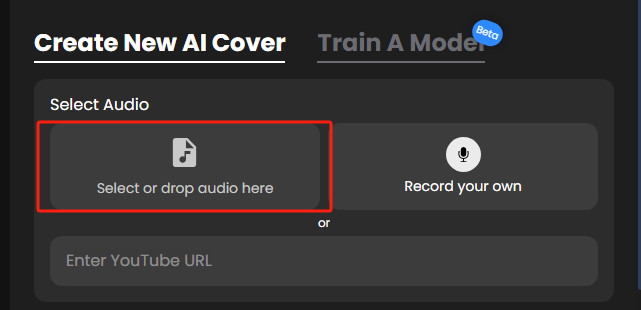
选择仅干声。
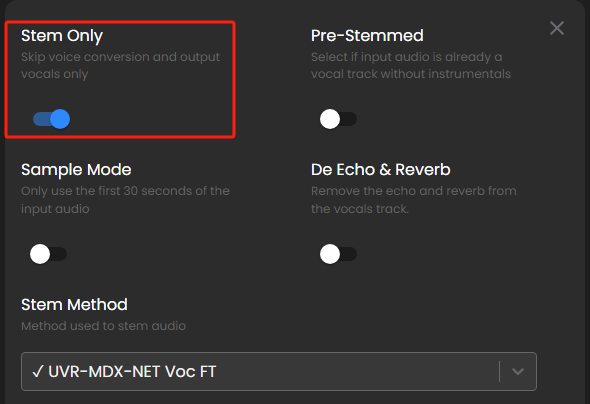
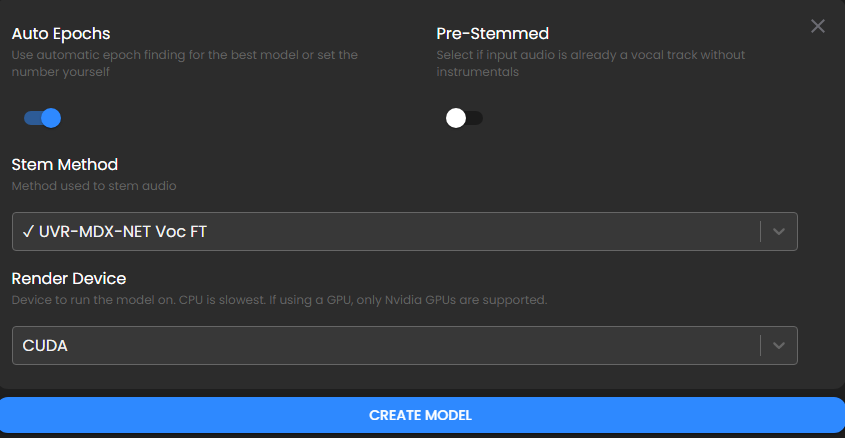
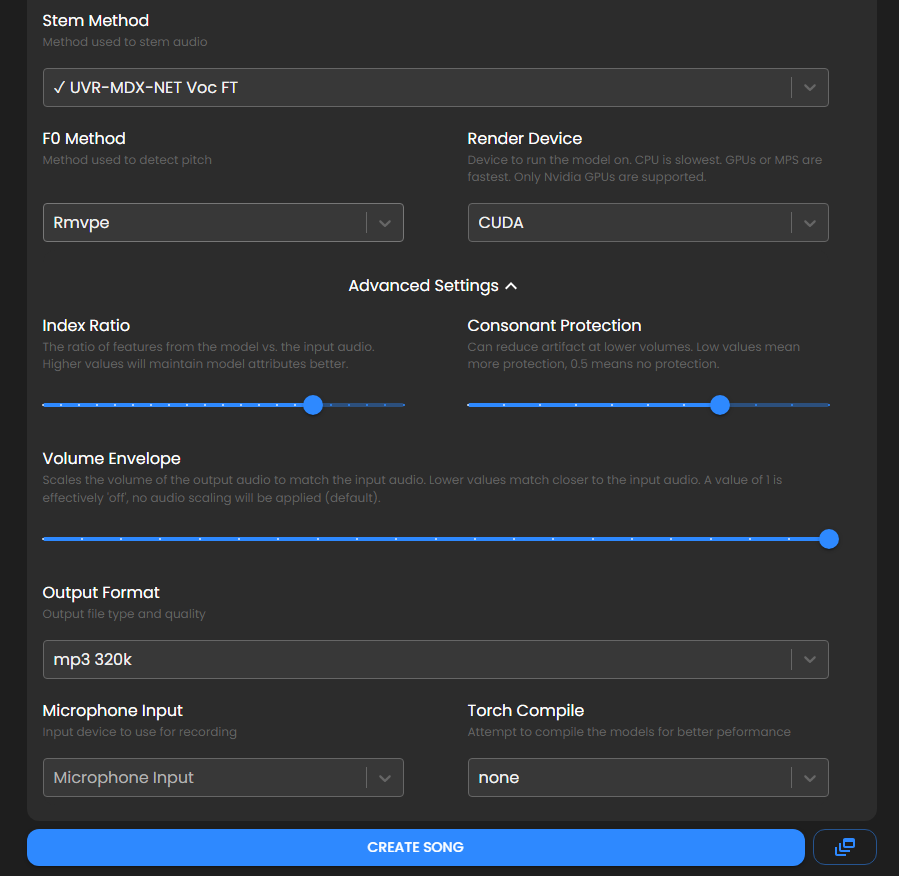
渲染设备这里,电脑有核显就选CUDA,会生成的稍微快一些,没有核显需要调成CPU。其它设置保持默认即可,点击生成。
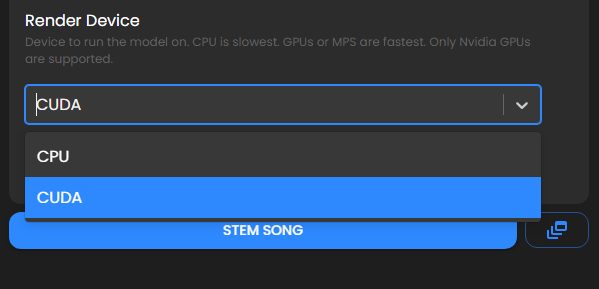
生成的音频会出现在左侧列表中,单击一下就可以看到分离出来的干声和伴奏声,可以分别试听和下载。
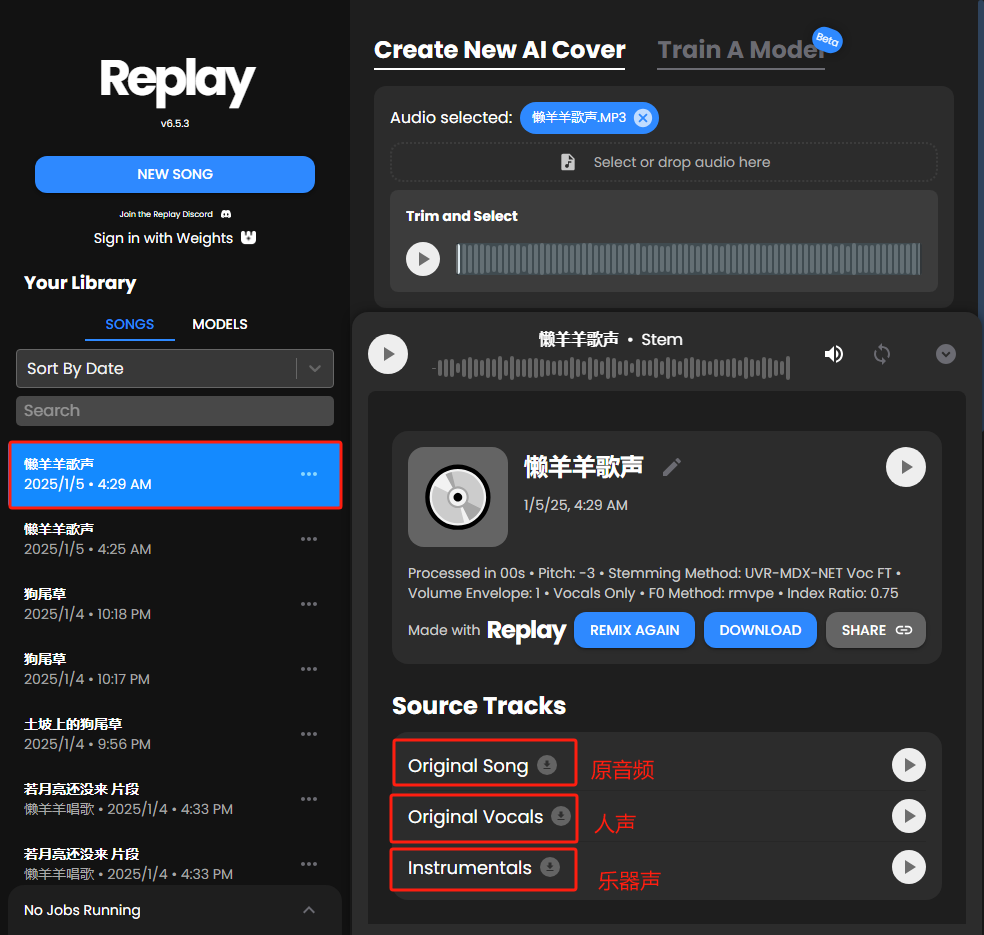
我们下载分离出的干声,将文件上传到训练模型的版块。这里可以上传多个文件,要尽可能多地覆盖各种声线,翻唱的效果就会更理想。
没有经过高音训练的语音模型,翻唱高音会容易失真甚至破音哈哈哈!
下面的设置,除了渲染设备这里,其它保持默认即可,点击创建模型。这个过程比较久,大概需要几个小时。
训练好的模型会在这里显示。
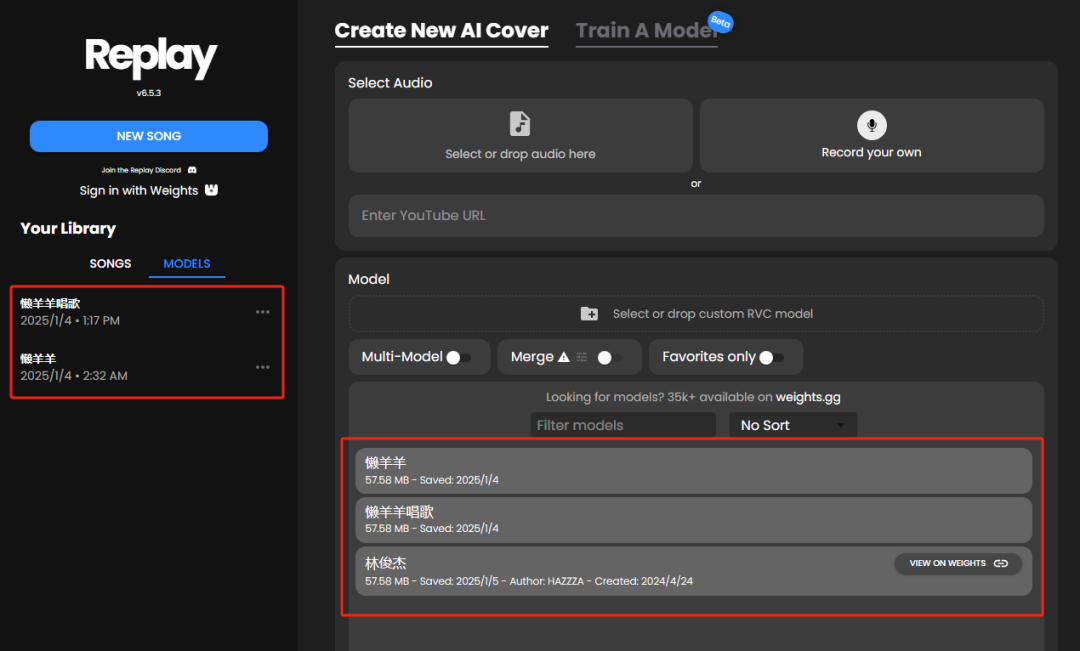
我们试一下用刚生成的懒羊羊模型翻唱,上传想要翻唱的歌曲。
点击选择懒羊羊的语音模型。
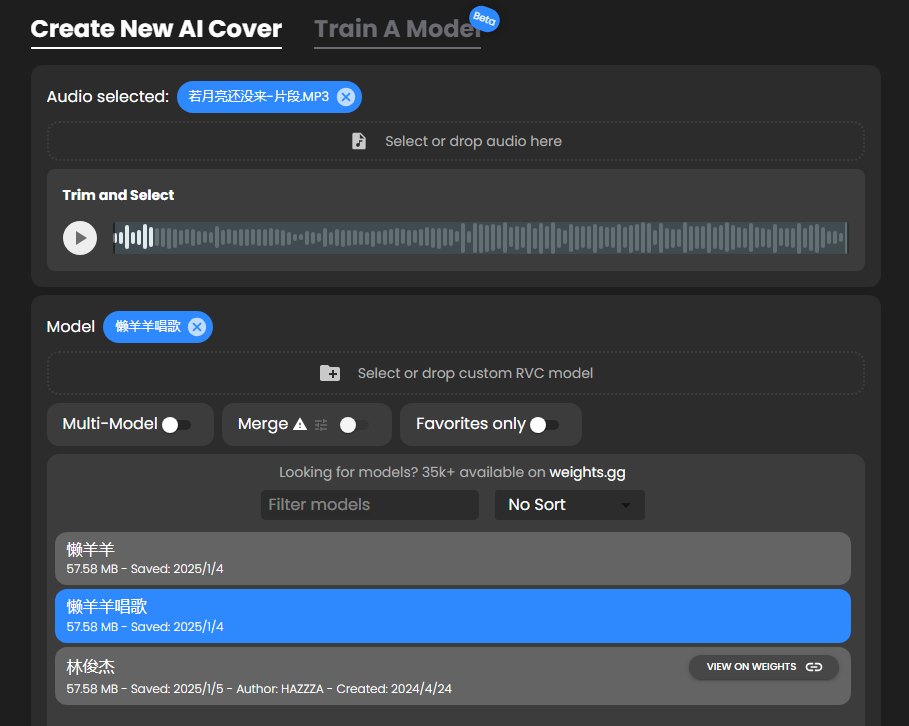
下方的设置保持默认就行,和在线翻唱的时候差不多,可以适当调整人声和乐器的音高,点击生成。
不到一分钟,就翻唱好啦。我们分别保存翻唱后的干声和伴奏。
一起来听听看:
下载Weights上的语音模型,解压后放入应用程序目录文件夹(软件开始设置的第二个位置)下的models文件里中,就可以在Replay中直接使用。
做合唱视频,只需要将同一段音频用不同的模型分别翻唱,最后用剪映拼接起来就可以啦。是不是非常简单方便。来听听懒羊羊和蜡笔小新的合唱。
懒羊羊和蜡笔小新的合唱
只用一分钟的声音素材,就能达到不错的翻唱效果,使用下来,除了生成模型有点慢(是我的缺点...),整体体验都很不错。特别是人声分离这个功能,基本上在其它平台都是要开会员才能用的,而Replay和Weights,都可以免费、无限次使用,效果还很赞,很难不爱呀。
翻唱音乐如果有和声、混响之类的,会影响翻唱的效果。如果我们想要做合唱类型的歌曲,可以先分别用单人版翻唱,再去剪映中合成。
用自己的声音训练模型,就能让AI翻唱各种热门歌曲,再也不用担心跑调,喊麦、说唱、流行音乐,分分钟拿捏,那些好听又难唱的歌,我用另一种方式学会啦。
AI翻唱虽然不能100%复刻声音和唱功,但已经可以听出七八分歌手的音色了,让赛博idol每天为我唱歌,想想还有点小激动呢~
⭐本文涉及的所有工具:
[1]Weights:Weights![]() https://ai-bot.cn/weights/
https://ai-bot.cn/weights/
[2]Replay:Replay![]() https://ai-bot.cn/replay/
https://ai-bot.cn/replay/


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











