







目录
1. 项目背景
网购已经成为人们生活不可或缺的一部分,本次项目基于淘宝app平台数据,通过相关指标对用户行为进行分析,从而探索用户相关行为模式。
提出问题
1.日PV有多少
2.日UV有多少
3.付费率情况如何
4.复购率是多少
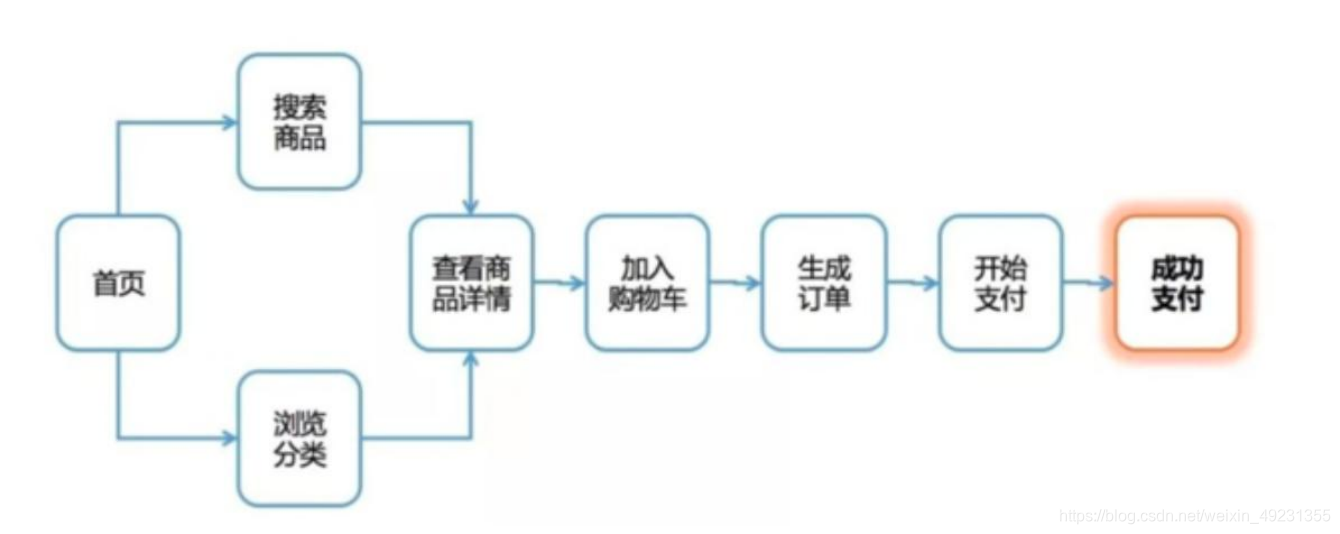
5.漏斗流失情况如何
6.用户价值情况
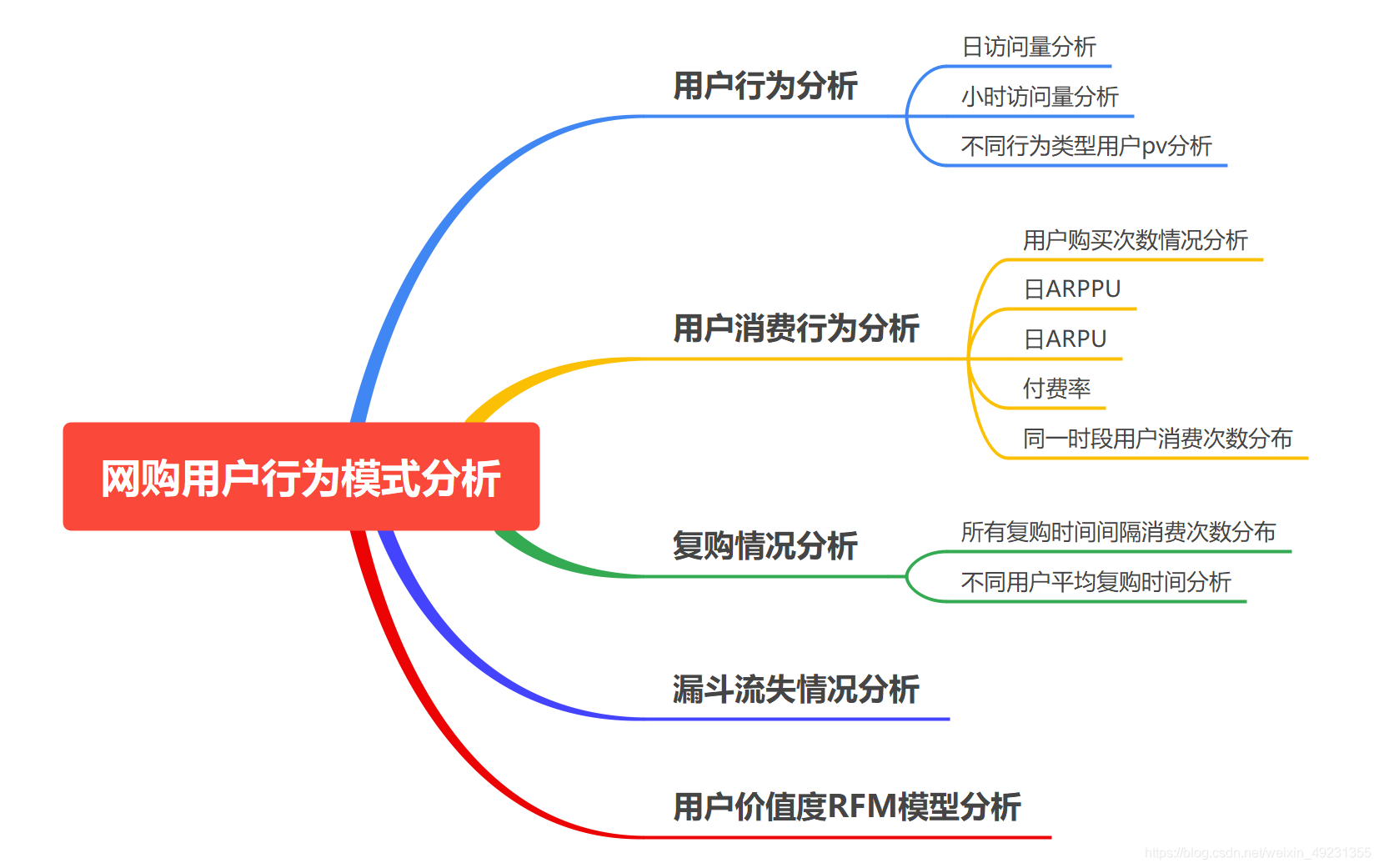
漏斗流失分析
漏斗分析是一套流程式数据分析,它能够科学反映用户行为状态以及从起点到终点 各阶段用户转化率情况的重要分析模型
RFM模型
用户分类(RFM模型),对比分析不同用户群体在时间、地区等维度下交易量, 交易金额指标,并根据分析结果提出优化建议
- R: 最近一次消费时间(最近一次消费到参考时间的长度)
- F: 消费的频次(单位时间内消费了多少次)
- M:消费的金额(单位时间内总消费金额)
| R | F | M | 用户分类 | 相应策略 |
|---|---|---|---|---|
| 高 | 高 | 高 | 重要价值用户 | RFM得分都高于平均值,属于优质客户,需要保持 |
| 低 | 高 | 高 | 重点保持用户 | 交易金额和交易次数都很大,但最近交易很少,需要唤回 |
| 高 | 低 | 高 | 重点发展用户 | 交易金额大贡献度高,且最近有交易,需要重点识别 |
| 高 | 高 | 低 | 重点挽留用户 | 交易次数多且最近有交易,但交易金额较小,需要挖掘客户需求 |
| 低 | 低 | 高 | 一般价值用户 | 交易金额大,但最近交易很少,且交易次数少,需要挽留 |
| 低 | 高 | 低 | 一般保持用户 | 交易次数多,但贡献不大,一般保持 |
| 高 | 低 | 低 | 一般发展用户 | 最近有交易,属于新客户,有推广价值 |
| 低 | 低 | 低 | 一般挽留用户 | RFM得分都低于平均值,最近再没有交易,属于流失 |
2. 理解数据
2.1 导入相关库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import plotly as py
import plotly.graph_objs as go
py.offline.init_notebook_mode()
pyplot=py.offline.iplot
import seaborn as sns
sns.set(style='darkgrid',context='notebook',font_scale=1.5)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
import warnings
warnings.filterwarnings('ignore')
2.2 导入数据
data_user=pd.read_csv('tianchi_mobile_recommend_train_user.csv',dtype=str)
data_user.head()
user_id item_id behavior_type user_geohash item_category time
0 98047837 232431562 1 NaN 4245 2014-12-06 02
1 97726136 383583590 1 NaN 5894 2014-12-09 20
2 98607707 64749712 1 NaN 2883 2014-12-18 11
3 98662432 320593836 1 96nn52n 6562 2014-12-06 10
4 98145908 290208520 1 NaN 13926 2014-12-16 21
查看数据,列字段分别是:
- user_id:用户身份,脱敏
- item_id:商品ID,脱敏
- behavior_type:用户行为类型(包含点击、收藏、加购物车、支付四种行为,分别用数字1、2、3、4表示)
- user_geohash:地理位置
- item_category:品类ID(商品所属的品类)
- time:用户行为发生的时间
data_user.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12256906 entries, 0 to 12256905
Data columns (total 6 columns):
# Column Dtype
--- ------ -----
0 user_id object
1 item_id object
2 behavior_type object
3 user_geohash object
4 item_category object
5 time object
dtypes: object(6)
memory usage: 561.1+ MB
3. 数据预处理
3.1 缺失值处理
#统计缺失值
data_user.apply(lambda x:sum(x.isnull()),axis=0)
user_id 0
item_id 0
behavior_type 0
user_geohash 8334824
item_category 0
time 0
dtype: int64
data_user.apply(lambda x:sum(x.isnull())/len(x),axis=0)
user_id 0.00000
item_id 0.00000
behavior_type 0.00000
user_geohash 0.68001
item_category 0.00000
time 0.00000
dtype: float64
- 存在缺失值的是User_geohash,有8334824条,缺失率0.68,不能删除缺失值,因为地理信息在数据集收集过程中做过加密转换,因此对数据集不做处理。
3.2 一致化处理
用户行为发生的时间由日期和小时构成,需要将该列进行拆分
#拆分数据集
data_user['date']=data_user['time'].str[0:10].str.strip()
data_user['hour']=data_user['time'].str[11:].str.strip()
data_user.head()
user_id item_id behavior_type user_geohash item_category time date hour
0 98047837 232431562 1 NaN 4245 2014-12-06 02 2014-12-06 02
1 97726136 383583590 1 NaN 5894 2014-12-09 20 2014-12-09 20
2 98607707 64749712 1 NaN 2883 2014-12-18 11 2014-12-18 11
3 98662432 320593836 1 96nn52n 6562 2014-12-06 10 2014-12-06 10
4 98145908 290208520 1 NaN 13926 2014-12-16 21 2014-12-16 21
# 查看data_user数据集数据类型:
data_user.dtypes
user_id object
item_id object
behavior_type object
user_geohash object
item_category object
time object
date object
hour object
dtype: object
#数据类型转换:time,date应该为日期格式,hour应该为整数型
data_user['time']=pd.to_datetime(data_user['time'])
data_user['date']=pd.to_datetime(data_user['date'])
data_user['hour']=data_user['hour'].astype('int64')
#检查数据类型转换结果
data_user.dtypes
user_id object
item_id object
behavior_type object
user_geohash object
item_category object
time datetime64[ns]
date datetime64[ns]
hour int64
dtype: object
3.3 异常值处理
#对数据按照time字段进行排序处理
data_user.sort_values(by='time',ascending=True,inplace=True)
#重建索引
data_user.reset_index(drop=True,inplace=True)
data_user.head()
user_id item_id behavior_type user_geohash item_category time date hour
0 73462715 378485233 1 NaN 9130 2014-11-18 2014-11-18 0
1 36090137 236748115 1 NaN 10523 2014-11-18 2014-11-18 0
2 40459733 155218177 1 Na 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3425
3425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









