







文章目录
进程地址空间
- 概述
前面我们提到,其实内核除了管理本身的内存外,还必须管理用户空间中进程的内存。我们称这个内存为进程地址空间,也就是系统中每个用户空间进程所看到的内存。Linux操作系统采用虚拟内存技术,因此,系统中的所有进程之间以虚拟方式共享内存。对一个进程而言,它好像都可以访问整个系统的所有物理内存。更重要的是,即使单独一个进程,它拥有的地址空间也可以远远大于系统物理内存。
1.地址空间
- 平坦
术语“平坦”指的是地址空间范围是一个独立的连续区间(比如,地址从О扩展到4294967295的32位地址空间)。
- 概述
进程地址空间由进程可寻址的虚拟内存组成,而且更为重要的特点是内核允许进程使用这种虚拟内存中的地址。每个进程都有一个32位或64位的平坦((flat)地址空间,空间的具体大小取决于体系结构,
- 有些OS提供段地址空间,这种地址空间不是独立的线性区域,而是被分段的
- 有些OS都是用平坦地址空间
- 再谈线程
通常一个进程有唯一的平坦地址空间,两个进程即使使用相同的内存地址(要在地址空间范围内),实际上也互不干涉,称这样的进程为线程
- 内存区域
尽管进程的可寻虚拟地址范围很大,但并不代表有权访问全部虚拟地址,所以在地址空间内我们更关心虚拟地址的地址区间;例如08048000-0804c000,它们可被进程访问。这些可被访问的合法地址空间称为内存区域(memory areas)。通过内核,进程可以给自己的地址空间动态地添加或减少内存区域。
如果进程访问了不在有效范围内的内存区域,或以不正确的方式访问了有效地址,那么内核会终结该进程并返回
段错误信息
内存区域可以包含的内存对象
进程地址空间中的任何有效地址都只能位于唯一的区域,这些内存区域不能相互覆盖。可以看到,在执行的进程中,每个不同的内存片段都对应一个独立的内存区域:栈、对象代码、全局变量、被映射的文件等。
- 可执行文件代码的内存映射,称为代码段( text section).
- 可执行文件的已初始化全局变量的内存映射,称为数据段(data section)。
- 包含未初始化全局变量,也就是bss(block started by symbol)段的零页(页面中的信息全部为0值,所以可用于映射bss段等目的,所谓bbs未初始化的变量都会被赋予0,这样避免显示初始化而造成的空间浪费)的内存映射。
- 用于进程用户空间栈(不要和进程内核栈混淆,进程的内核栈独立存在并由内核维护)的零页的内存映射。
- 每一个诸如C库或动态连接程序等共享库的代码段、数据段和bss也会被载入进程的地址空间。
- 任何内存映射文件。·任何共享内存段。
- 任何匿名的内存映射,比如由malloc()分配的内存。
2.内存描述符
- 概述
内核使用内存描述符结构体表示进程的地址空间,该结构包含了和进程地址空间有关的全部信息。内存描述符由mm_struct结构体表示
- mm_users:记录正在使用该区域的进程数目,两个线程共享此空间,就是2
mm_count:结构体的引用数,前面的两个线程共享,那么mm_users就是2,count为1,如果前者为9,后者同样还是1;当前者为0时,后者也是0(会被撤销结构体);当内核在一个地址空间上操作,并需要使用与该地址相关联的引用计数时,内核便增加mm_count。- mmap和mm_rb:这两个不同数据结构体描述的对象是相同的:该地址空间中的全部内存区域。但是前者以链表形式存放而后者以红黑树的形式存放。红黑树是一种二叉树,与其他二叉树一样,搜索它的时间复杂度为O (log n)。前者简单高效的遍历所有元素,后者高效搜索制定元素
- 所有的mm_struct结构体都通过自身的mmlist域连接在一个双向链表中,该链表的首元素是init_mm内存描述符,它代表init进程的地址空间。另外要注意,操作该链表的时候需要使用mmlist_lock锁来防止并发访问


2.1 分配内存描述符
- 概述
在进程的进程描述符中,mm域存放着该进程使用的内存描述符,所以current-> mm便指向当前进程的内存描述符。fork()函数利用copy_mm()函数复制父进程的内存描述符,也就是current->mm域给其子进程,而子进程中的mm_struct结构体实际是通过文件kernel/fork.c中的allocate_mm()宏从mm_cachep slab缓存中分配得到的。通常,每个进程都有唯一的mm_struct结构体,即唯一的进程地址空间
如果父进程希望与子进程共享地址空间,在调用函数时设置一个标志位CLONE_VM,那么这个子进程也就是我们俗称的线程了。当CLONE_VM被指定后,内核就不再需要调用allocate_mm()函数了,而仅仅需要在调用copy_mm()函数中将mm域指向其父进程的内存描述符就可以了
2.2 撤销内存描述符
- 概述
进程退出时,一般会调用三个相关结束工作的函数,一个是执行常规撤销工作,更新一些统计变量,并且其中会调用第二个函数去减少mm_users的数量,如果该值减少到0,会调用第三个函数减少mm_count的值,如果mm_count也为0了,系统会将mm_struct加入到lab中
2.3 mm_struct与内核线程
- 再谈内核线程
内核线程没有进程地址空间,也没有相关的内存描述符。所以内核线程对应的进程描述符中mm域为空。事实上,这也正是内核线程的真实含义—它们没有用户上下文。
虽然内核线程不需要访问任何用户空间的内存也没有任何页在内存空间,即使这样线程访问内核内存也需要一些数据为了避免浪费内存和地址空间的切换消耗,所以索性就要线程使用了前一个进程的内存描述符
- 内核线程被调度
当一个进程被调度,该进程的mm结构体指向被装在到内存的地址空间,进程描述符记录地址空间地址也被更新;但是线程没有地址空间,所以mm结构为NULL,所以当一个内核线程被调度直接去检查mm结构的标识符是否为NULL就知道要把上一个进程的内存描述符和页表分配给这个内核线程,线程会访问用户空间所以也仅仅使用到这些信息的一部分
3.虚拟内存区域
- 概述
内存区域由vm_area_struct结构体描述,内存区域在Linux内核中也经常称作虚拟内存区域( virtual memoryAreas,VMAs)。
虚拟内存区域对应的结构体制定地址空间内连续区间上的一个独立内存范围,这个内存范围会被独立的当做一个内存对象进行管理,每个内存对象都有相同的属性(访问权限等)和相同的操作;那么VMA就可以代表不同的内存对象(区域),这种管理方式就类似于VFS层的面向对象方法
- VMA的结构
每个内存描述符都代表进程地址空间内唯一的区间,下面前两个属性之差就是区间内该内存区域的长度
- vm_start:代表区间的首地址(最低地址)
- vm_end:代表尾地址(最高地址)之后的第一个字节
- vm_mm:指向mm_struct结构体,注意指向的关系是惟一的(所以不同的进程映射相同的文件到自己的地址空间,每个进程都有唯一的VMA结构体;如果两个线程共享一个地址空间,那么相应的VMA结构体也是共享的)

3.1 VMA标志
- 概述
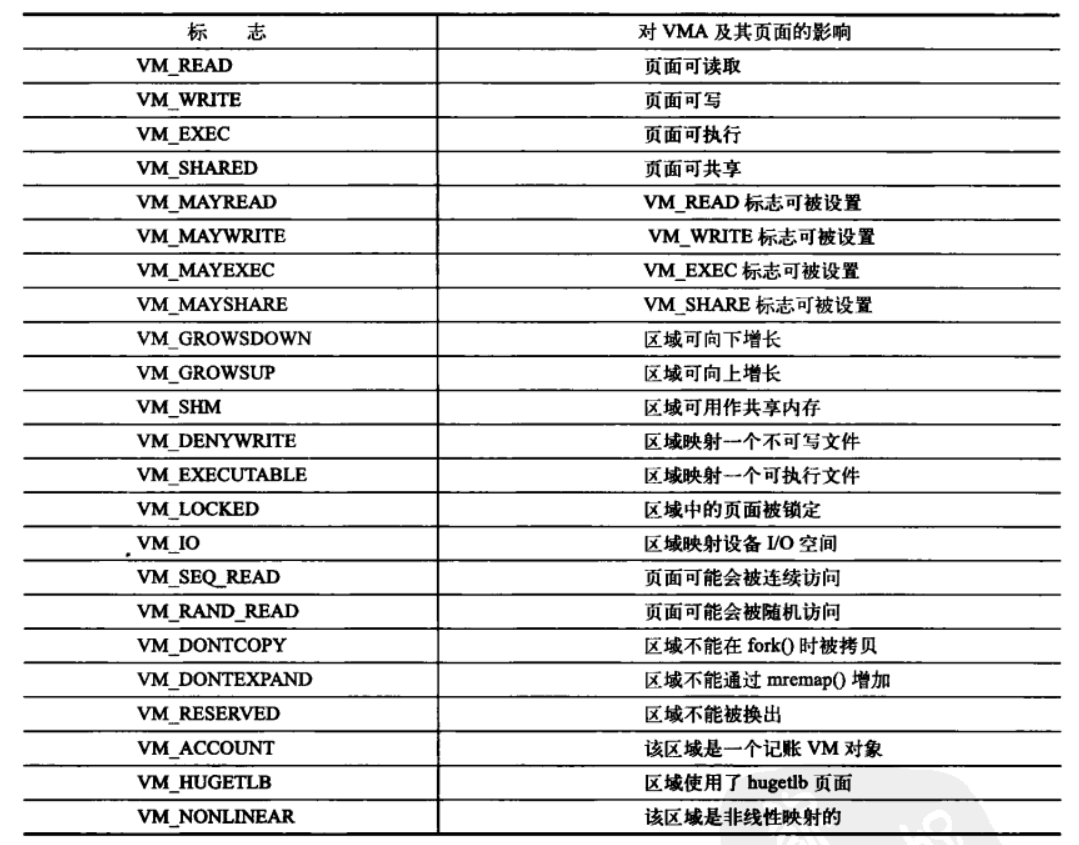
VMA标志是一种位标志,它包含在vm_flags域内,标志了内存区域所包含的页面的行为和信息。和物理页的访问权限不同,VMA标志反映了内核处理页面所需要遵守的行为准则,而不是硬件要求。而且,vm_flags同时也包含了内存区域中每个页面的信息,或内存区域的整体信息,而不是具体的独立页面。这也就是解释了我们上面说的VMA如何代表不同的内存区域
- 标志
3.2 VMA操作
- 概述
我们下面直接展示对应的函数
struct vm_operations_struct {
//当指定的内存区域被加入到一个地址空间时,该函数被调用。
void (*open) (struct vm_area_struct * ) ;
//当指定的内存区域从地址空间删除
void (*close) (struct vm_area_struct * ) ;
//当没有出现在物理内存的页面被访问,则调用故障处理
int (*fault)(struct vm_area_struct *, struct vm_fault *) ;
//当某个页面为只读页面时,调用故障处理
int (*page_mkwrite) (struct vm_area_struct *vma,struct vm_fault *vmf );
//当get_user_pages()函数调用失败时,该函数被access_process_vm)函数调用。
int ( *access) (struct vm_area_struct *, unsigned long ,
void * , int, int) ;
};
3.3 内存区域的树型结构和内存区域的链表结构
- 概述
前面我们介绍内存描述符的mmap和mm_rb这两个属性说到,内存区域可以通过这两者其一进行访问;这两个属性各自指向了与之相关的全体内存区域对象,其实两者包含完全相同的VMA结构体指针,只不过就是阻止形式不同
那mmap来说,每个VMA结构通过自身的vm_next来连接同处于一个内存描述符的下一个VMA结构,按照地址增长方向排列
而对于mm_rb来说是用红黑树连接所有VMA结构,该指针指向红黑树的根节点,每个VMA结构通过自身的vm_rb连接到树
- 这里简单的提一下红黑树以及相关性质
红黑树是一种二叉树,树中的每一个元素称为一个节点,最初的节点称为树根。红黑树的多数节点都由两个子节点:一个左子节点和一个右子节点,不过也有节点只有一个子节点的情况。树末端的节点称为叶子节点,它们没有子节点。
红黑树中的所有节点都遵从﹔左边节点值小于右边节点值﹔另外每个节点都被配以红色或黑色(要么红要么黑,所以叫做红一黑树)。
分配的规则为:红节点的子节点为黑色,并且树中的任何一条从节点到叶子的路径必须包含同样数目的黑色节点。记住根节点总为红色。.红一黑树的搜索、插入、删除等操作的复杂度都为O(log(⑴))
3.4 实际使用中的内存区域
- 概述
可以使用/proc文件系统和pmap(1)工具查看给定进程的内存空间和其中所含的内存区域。
- 例子
//先使用下面的命令查看运行中的进程的PID
ps aux | less
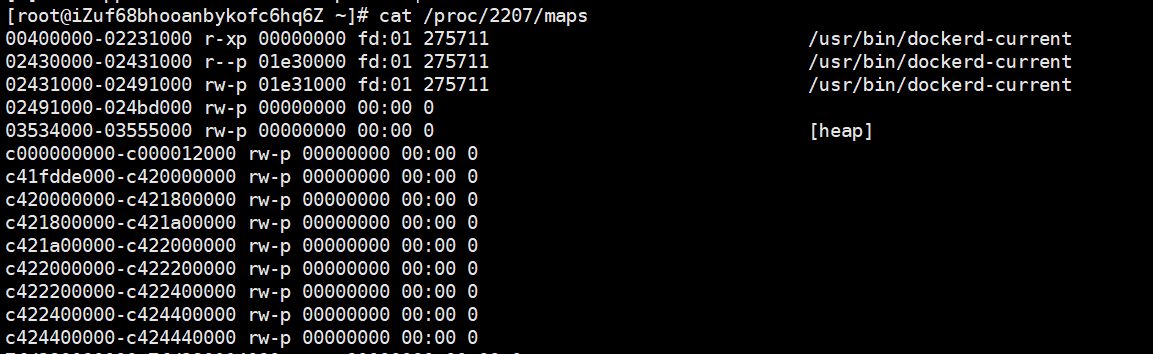
//然后可以使用/procl<pid>/maps 的输出显示了该进程地址空间中的全部内存区域,
//比如我们查下面的docker进程中的全部内存区域
cat /proc/2207/maps

- 结果及格式分析
| 开始-结束 | 访问权限 | 偏移 | 主设备号:次设备号 | i节点 | 文件 |
|---|
我们可以使用pmap工具进行可视化显示:
可以看到进程的全部地址空间大约为999948KB,我就不细致统计了,观察发现大概只有很少的一片区域是可写和私有的,如果一片内存范围是共享的或是不可写的,那么内核只需要在内存中为文件保留一份映射,当然为共享映射这样做很好理解(每个人都可以访问一份共享数据);但是对于私有的就有些匪夷所思了,考虑到不可写意味着不可被改变,也就是说读入一次是安全的
举个例子,C库在物理内存中仅仅用了1212KB,而不是需要给每个使用C库的进程在内存中都保存一个1212KB;所以上面访问进程如果访问999948KB的数据和代码空间但却消耗了一点点的物理内存,可见非常


- 零页
注意没有映射文件的内存区域的设备标志为00:00,索引接点标志也为0,这个区域就是零页——零页映射的内容全为零。如果将零页映射到可写的内存区域,那么该区域将全被初始化为0。这是零页的一个重要用处,而bss 段需要的就是全0的内存区域。由于内存未被共享,所以只要-有进程写该处数据,那么该处数据就将被拷贝出来(就是我们所说的写时拷贝),然后才被更新。
4.操作内存区域
- 概述
内核时常需要在某个内存区域上执行一些操作,比如某个指定地址是否包含在某个内存区域中
4.1 find_vma()
- 概述
为了找到一个给定的内存地址属于哪一个内存区域,内核提供了find_vma()函数。首先会寻找第一个包含addr或首地址大于addr的内存区域,没有返回NULL
//函数中先去检查缓存,然后检查addr的合法性,然后获取红黑树的根节点,开始遍历红黑树中符合addr的条件的节点,找到后缓存一份
struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addz);
- 注意
返回的可能是大于addr的内存区域,那么有可能指定的地址并不包含在返回的VMA中;操作后会有很大概率继续对该VMA进行操作,所以返回的结果会被缓存在内存描述符中的mmap_cache里面,如果不在缓存中才会去搜索相关内存区域,这个搜索就是用的红黑树结构
- find_vma_prev()
find_vma prev()函数和find_vma()工作方式相同,但是它返回第一个小于addr的VMA
struct vm_area_struct find_vma_prev(struct mm_struct *mm , unsigned long addr ,
struct vm area_struct *pprev)
- find_vma_intersection()
find_vma_intersection()函数返回第一个和指定地址区间相交的VMA。第一个参数mm是要搜索的地址空间,start_addr是区间的开始首位置,end_addr是区间的尾位置。
static inline struct vm_area_struct*
find_vma_intersection(struct mm_struct*m,
unsigned long start_addr,
unsigned long end_addr){
struct vmarea_struct *vma ;
vma = find_vma ( mm,start_addr) ;
if (vma && end_addr <= vma- >vm_start)
vma = NULL;
return vma;
}
5.mmap()和do_mmap():创建地址区间
- 概述
内核使用do_mmap()函数创建一个新的线性地址区间。但是说该函数创建了一个新VM并不非常准确,因为如果创建的地址区间和一个已经存在的地址区间相邻,并且它们具有相同的访问权限的话,两个区间将合并为一个。如果不能合并,就确实需要创建一个新的VMA了,然后加入区域链表和红黑树,随后还会更新该内存描述符的VMA总数。
但无论哪种情况,do_mmap()函数都会将一个地址区间加入到进程的地址空间中——无论是扩展已存在的内存区域还是创建一个新的区域。
- do_mmap()函数
- 我们具体说一下prot,这个参数是制定内存区域页面的访问权限
- flag参数制定了VMA标志,作用制定类型并改变映射行为



unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long offset)
- mmap系统调用
在用户空间可以通过mmap()系统调用获取内核函数do_mmap()的功能。mmap()系统调用定义如下:
由于下面系统调用是mmap()调用的第二种变种,所以起名为mmap2()。最原始的mmap()调用中最后一个参数是字节偏移量,而目前这个mmap2()使用页面偏移作最后一个参数。使用页面偏移量可以映射更大的文件和更大的偏移位置。
void mmap2 (void *start,
size_t length,
int prot,
int flags,
int fd,
off__t pgoff)
6.mummap()和do_mummap():删除地址区间
- 概述
do_mummap()函数从特定的进程地址空间中删除指定地址区间,第一个参数指定要删除区域所在的地址空间,删除从地址 start开始,长度为len字节的地垃区间。如果成功,返回零。否则,返回负的错误码。
int do_mummap(struct mm_struct *mm, unsigned long start, size_t len)
- 系统跳动mummap()
系统调用munmap()给用户空间程序提供了一种从自身地址空间中删除指定地址区间的方法,它和系统调用mmap()的作用相反:
int munmap (void *start, size_t length)
7.页表
- 概述
虽然应用程序操作的对象是映射到物理内存之上的虚拟内存,但是处理器直接操作的却是物理内存。所以当用程序访问一个虚拟地址时,首先必须将虚拟地址转化成物理地址,然后处理器才能解析到访问请求,地址的转换工作需要通过查询页表才能完成,
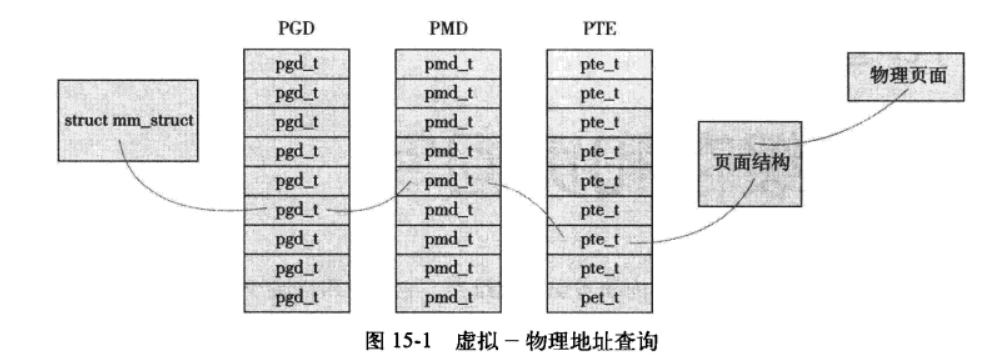
概括地讲,地址转换需要将虚拟地址分段,使每段虚拟地址都作为一个索引指向页表,而页表项则指向下一级别的页表或者指向最终的物理页面。
- Linux中的三级页表转换
Linux中使用三级页表完成地址转换。利用多级页表能够节约地址转换需占用的存放空间。如果利用三级页表转换地址,即使是64位才很省空间;但是使用静态数组的话无论是32还是64位都十分占用空间
Linux对所有体系结构,包括对那些不支持三级页表的体系结构(比如,有些体系结构只使用两级页表或者使用散列表完成地址转换)都使用三级页表管理,因为使用三级页表结构可以利用
“最大公约数”的思想
- 最大公约数思想
一种设计简单的体系结构,可以按照需要在编译时简化使用页表的三级结构,比如只使用两级。
- 三级页表
每个进程都有自己的页表(当然,线程会共享页表)。内存描述符的pgd域指向的就是进程的页全局目录。注意,操作和检索页表时必须使用
page_table_lock锁,该锁在相应的进程的内存描述符中,以防止竞争条件。
顶级页表是页全局目录(PGD):
它包含了一个pgd_t类型数组,多数体系结构中 pgd_t类型等同于无符号长整型类型。PGD中的表项指向二级页目录中的表项:PMD。
二级页表是中间页目录(PMD):
它是个pmd_t类型数组,其中的表项指向PTE中的表项
页表(PTE):
最后一级的页表简称页表,其中包含了pte_t类型的页表项,该页表项指向物理页面。
- 搜索过程
- 页表操作与性能——
快表TLB(translate lookaside buffer)
由于每次访问虚拟内存中的页面都要解析页表,从而得到真实的物理地址,所以性能非常关系;但是由于搜索物理内存的速度十分有限,为此我们加入了一个翻译后缓冲器(TLB)
TLB作为一个将虚拟地址映射到物理地址的硬件缓存,当请求访问一个虚拟地址时,处理器将首先检查TLB中是否缓存了该虚拟地址到物理地址的映射,如果在缓存中直接命中,物理地址立刻返回否则,就需要再通过页表搜索需要的物理地址。















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









