






金融风控训练营 Task4 建模与调参 学习笔记
本学习笔记为阿里云天池龙珠计划金融风控训练营的学习内容,学习链接为:https://tianchi.aliyun.com/specials/activity/promotion/aicampfr
一、学习知识点概要
文章目录
二、学习内容
1. 内容介绍
推荐教材:
《机器学习》《面向机器学习的特征工程》《信用评分模型技术与应用》《数据化风控》
- 逻辑回归模型:
- 理解逻辑回归模型
- 逻辑回归模型的应用
- 逻辑回归的优缺点
- 树模型:
- 理解树模型
- 树模型的应用
- 树模型的优缺点
- 集成模型
- 基于bagging思想的集成模型
- 随机森林模型
- 基于boosting思想的集成模型
- XGBoost模型
- LightGBM模型
- CatBoost模型
- 基于bagging思想的集成模型
- 模型对比与性能评估:
- 回归模型/树模型/集成模型
- 模型评估方法
- 模型评价结果
- 模型调参:
- 贪心调参方法
- 网格调参方法
- 贝叶斯调参方法
2. 逻辑回归

-
优点
-
训练速度较快
分类的时候,计算量只和特征的数目相关
-
简单易理解
从特征的权重可以看到不同的特征对最后结果的影响
-
适合二分类问题,不需要缩放输入特征
-
内存资源占用小,只需要存储各个维度的特征值
-
-
缺点
-
需预先处理缺失值和异常值
-
不能用Logistic回归去解决非线性问题(因为Logistic的决策面是线性的)
-
对多重共线性数据较为敏感
很难处理数据不平衡的问题
-
准确率不高
形式非常简单,很难去拟合数据的真实分布
-
3. 决策树模型

递归创建决策树时,有两个终止条件:
-
所有的类标签完全相同 → 直接返回该类标签
-
使用完了所有特征,仍然不能将数据划分仅包含唯一类别的分组,即决策树构建失败,特征不够用。此时说明数据纬度不够。
→ 挑选出现数量最多的类别作为返回值
-
优点
-
易于理解和解释,简单直观,可视化展示
-
数据不需要预处理
不需要归一化,不需要处理缺失数据
-
可以处理多值输出变量问题
-
可以同时处理数值变量和分类变量
-
时间成本低,使用树的花费是训练数据点数量的对数
-
-
缺点
-
容易过拟合,导致泛化能力不强
(需要适当的剪枝)
-
采用的是贪心算法,容易得到局部最优解
-
可能是不稳定的
-
4. 梯度提升树GBDT
GBDT是一个集成模型,可以看做是很多个基模型的线性相加,其中的基模型就是CART回归树
回归树生成 => 回归树剪枝 => GBDT模型
5. XGBoost模型
与GBDT类似,区别于目标函数的定义
在策略上是类似的,都是聚焦残差(xgboost是gbdt算法在工程上的一种实现方式)
在进行最优分裂点的选择上是先进行预排序,然后对所有特征的所有分裂点计算按照这些分裂点位分裂后的全部样本的目标函数增益
遍历所有的样本后求每个样本的损失函数,但样本最终会落在叶子节点上,所以也可以遍历叶子节点,然后获取叶子节点上的样本集合
xgboost相比于GBDT 优点:
-
GBDT是机器学习算法, XGBOOST是GBDT的工程实现
-
精度更高
-
灵活性更强:GBDT以CART作为基分类器,而Xgboost支持CART、支持线性分类器、支持自定义损失函数(只要损失函数有一二阶导数)
-
正则化:控制模型的复杂度;有助于降低模型方差,防止过拟合
XGBOOST在构建树的过程中,进行树复杂度的控制,不像GBDT, 等树构建好了之后再进行剪枝
-
Shrinkage(缩减):削弱每棵树的影响,让后面有更大的学习空间,学习过程更加的平缓
-
列抽样:在建树时,不遍历特征,进行抽样
简化计算,助于降低过拟合
-
缺失值处理:加快了节点分裂的速度
传统的GBDT没有设计对缺失值的处理, 而XBOOST能自动学习出缺失值的处理策略
-
支持对数据进行采样:传统的GBDT在每轮迭代时使用全部的数据, XGBOOST则采用了与随机森林相似的策略
-
并行化操作:块结构可以很好的支持并行计算
6. LightGBM模型
训练速度快
采用Histogram算法会起到正则化的效果,有效地防止模型的过拟合
Lightgbm的参数非常多,有核心参数,学习控制参数,IO参数,目标函数参数,度量参数等很多(我们调参时只需要一些常用的关键的参数)
基本流程:
- 选择较高的学习率,大概0.1附近,这加快收敛的速度
- 对决策树基本参数调参
- 正则化参数调参
- 降低学习率,为了最后提高准确率
缺点: 直方图较为粗糙, 会损失一定的精度
7. Catboost模型
CatBoost由Categorical和Boosting组成
基于对称决策树为基学习器实现的参数较少、支持类别型变量和高准确性的GBDT框架
主要解决的痛点:高效合理地处理类别型特征
CatBoost解决了梯度偏差(Gradient Bias)以及预测偏移(Prediction shift)的问题,从而减少过拟合的发生,进而提高算法的准确性和泛化能力
-
创新点:
-
嵌入了自动将类别型特征处理为数值型特征的创新算法
对categorical features做一些统计,计算某个类别特征出现的频率,加上超参数,生成新的数值型特征
-
使用组合类别特征,利用到特征之间的联系,极大的丰富了特征维度
-
采用排序提升的方法对抗训练集中的噪声点,避免梯度估计的偏差,进而解决预测偏移的问题
-
采用了完全对称树作为基模型
-
-
评分
CatBoost使用对称树(oblivious trees)作为基预测器。在这类树中,相同的分割准则在树的整个一层上使用。这种树是平衡的,不太容易过拟合。
梯度提升对称树被成功地用于各种学习任务中。在对称树中,每个叶子节点的索引可以被编码为长度等于树深度的二进制向量。
应用:将所有浮点特征、统计信息和独热编码特征进行二值化,然后使用二进制特征来计算模型预测值。
-
优缺点
-
优点
- 性能卓越
- 鲁棒性/强健性: 减少对很多超参数调优的需求,降低过度拟合的机会,使得模型变得更加具有通用性
- 易于使用
- 实用: 可以处理类别型、数值型特征
- 可扩展: 支持自定义损失函数
-
缺点
- 对于类别型特征的处理需要大量的内存和时间
- 不同随机数的设定对于模型预测结果有一定的影响
-
CatBoost和XGBoost、LightGBM并称为GBDT的三大主流神器!!!
8. 时间序列模型
神经网络
-
KNN
-
时间长
使用长序列训练RNN时会在多个时间节点上进行运算,导致展开的RNN是一个非常深的网络
RNN会面临梯度消失或爆炸问题,使训练时间变得很慢:良好的参数初始化,非饱和激活函数(如ReLU),Batch Normalization,梯度裁剪,更快的优化器
(如果需要处理比较长的序列,那么训练仍然很慢)
-
最简单常用的方法是在训练时,只针对部分时间节点展开RNN => 截断式时序反向传播(truncated backpropagation through time)
在TensorFlow中通过截断输入序列即可实现截断式时序反向传播
例如,在时序预测任务中,训练RNN时减少n_steps即可
很明显,该方法会导致模型无法学习长期模式(long-term patterns)
-
使缩短后的序列包含旧信息和当前信息,这样模型就可以学习新旧信息了
例如,序列包含最近五个月的月度数据、最近五周的周度数据、最近五日的日度数据
-
-
最初输入的记忆在运算中逐渐消失
当数据穿过RNN时,数据会被转换,在每个时间节点都会丢失一些信息。一段时间后,RNN的状态将完全没有任何最初输入的信息
例如,对一个长的评论做语义分析,评论开始是“我喜欢这个电影”,但是余下部分列出了电影的改进点。如果RNN完全忘记了最开始的几个字,将会误解这个影评
-
-
一种特殊的RNN 长短时记忆神经网络


9. 集成模型集成方法(ensemble method)
通过组合多个学习器来完成学习任务,通过集成方法,可以将多个弱学习器组合成一个强分类器
集成方法主要包括Bagging和Boosting => 将已有的分类或回归算法通过一定方式组合起来,形成一个更加强大的分类
把若干个分类器整合为一个分类器,但整合的方式不一样,最终得到不一样的效果
常见的基于Baggin思想的集成模型有:随机森林、基于Boosting思想的集成模型有:Adaboost、GBDT、XgBoost、LightGBM等
Baggin vs Boosting:
-
样本选择上:
Bagging训练集 从原始集中有放回的选取,各轮训练集是独立的
Boosting每一轮训练集不变,权重发生变化 (权值: 根据上一轮的分类结果进行调整)
-
样例权重上:
Bagging使用均匀取样,每个样本的权重相等
Boosting根据错误率不断调整样本的权值,错误率越大则权重越大
-
预测函数上:
Bagging所有预测函数的权重相等
Boosting中每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重
-
并行计算上:
Bagging各个预测函数可以并行生成
Boosting各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果
10. 模型评估方法
对于模型,在训练集上的误差 => 训练误差或者经验误差,在测试集上的误差 => 测试误差。
训练集用来训练模型,测试集则是用来评估模型对于新样本的判别能力
- 数据集划分条件:
- 训练集和测试集的分布要与样本真实分布一致(训练集和测试集都要保证是从样本真实分布中独立同分布采样而得)
- 训练集和测试集要互斥
- 数据集的划分方法:
-
①留出法
直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T
! 要尽可能保证数据分布的一致性 => 避免因数据划分过程引入额外的偏差而对最终结果产生影响
为了保证数据分布的一致性 => 分层采样
大约2/3~4/5的样本作为训练集,其余的作为测试集
-
②交叉验证法
将数据集D分为k份,其中k-1份作为训练集,剩余的一份作为测试集
获得k组训练/测试集,进行k次训练与测试,最终返回的是k个测试结果的均值
分层采样
k值的选取决定了评估结果的稳定性和保真性,通常k值选取10
当k=1的时候 => 留一法
-
③自助法
取一个样本作为训练集中的元素,然后把该样本放回,重复该行为m次
得到大小为m的训练集
有的样本重复出现,有的样本没有出现过 => 把没有出现过的样本作为测试集
在D中约有36.8%的数据没有在训练集中出现过
留出法与交叉验证法都是使用分层采样的方式进行数据采样与划分,而自助法则是使用有放回重复采样的方式进行数据采样
11. 调参及步骤
老规矩,前面先进行导库,读取数据,对数据进行一些简单的调整,例如:调整数据类型(减少数据在内存中占用的空间)
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum()
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum()
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
建模步骤:
预操作(分离数据集、交叉验证) → 根据数据选择合适的模型进行建模 → 对验证集进行预测 → 使用5折交叉验证进行模型性能评估
模型调参:
-
贪心调参
- 先使用当前对模型影响最大的参数进行调优,达到当前参数下的模型最优化,再使用对模型影响次之的参数进行调优
- 可能会调到局部最优而不是全局最优
-
网络搜索
- 使用sklearn 提供GridSearchCV,只需把模型的参数输进去,就能给出最优化的结果和参数
- 适合于小数据集
-
贝叶斯调参
-
给定优化的目标函数(广义的函数,只需指定输入和输出,无需知道内部结构以及数学性质)
通过不断地添加样本点来更新目标函数的后验分布(高斯过程,直到后验分布基本贴合于真实分布)
考虑了上一次参数的信息,从而更好的调整当前的参数
-
步骤
- 定义优化函数(rf_cv)
- 建立模型
- 定义待优化的参数
- 得到优化结果,并返回要优化的分数指标
-
三、学习问题与解答
Q: 在实际中,如何才能更快地找到合适的模型?
A: ①需要掌握一定的基础知识,例如:监督学习、半监督学习、无监督学习等等
②学习一些常见的算法知识,在学习过程中需要多关注整个运行过程,从浅到深,需要关注算法的使用条件及优缺点,到一定时期时重点比对不同算法之间的好与坏
③有了上述的铺垫,可以进行一定的实践,将拿到的问题进行分类,找到合适的算法进行机器学习 ↓
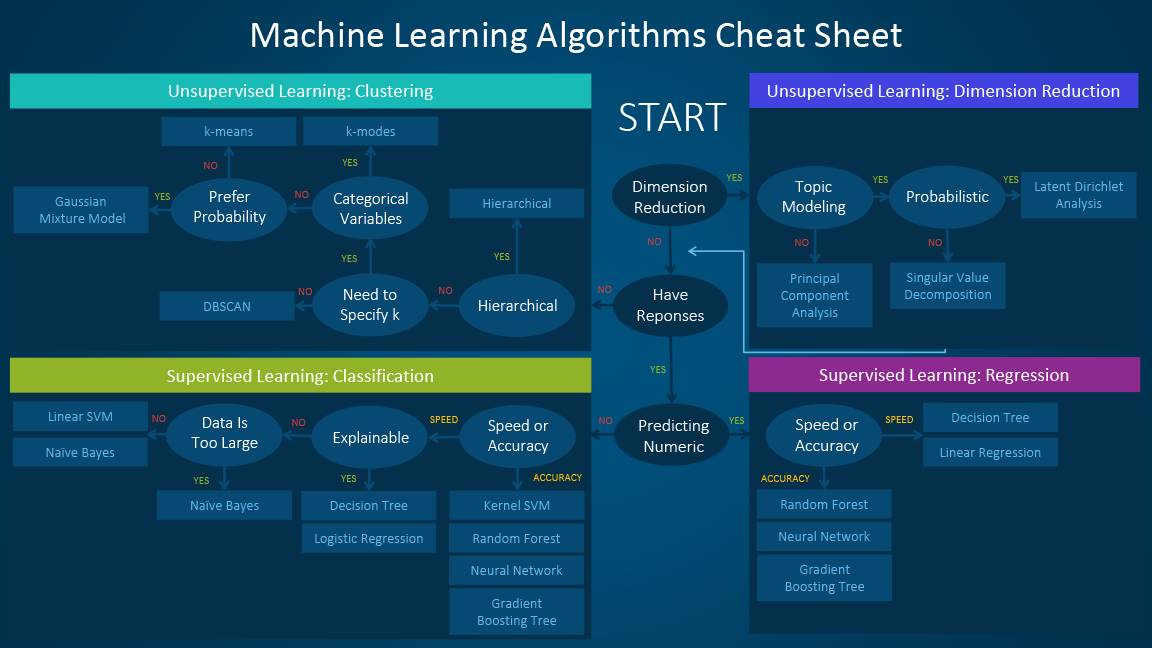
在我们实际的项目中,我们需要做到对自己所熟悉的个别算法灵活使用
四、学习思考与总结
-
模型评估总结
-
数据量充足 => 留出法 or k折交叉验证法
-
数据集小且难以有效划分 => 自助法
-
数据集小且可有效划分 => 留一法
-
-
模型调参总结:
-
集成模型内置的cv函数可以较快的进行单一参数的调节
一般可以用来优先确定树模型的迭代次数
-
数据量较大的时候,网格搜索调参会特别特别慢,不建议尝试
-
集成模型中原生库和sklearn下的库部分参数不一致,需要具体参看官方API
-
-
其他总结
需要掌握一定的数学相关知识后,对各类模型进行系统性学习,根据不同模型的特点及适用条件,对该数据进行建模。目前掌握的数学知识较少,大部分模型的推导过程或者数学公式不能理解,只能看懂模型的特点及如何对代码进行修改进行简单的建模。调参部分,对数据的敏感程度不高,仍需好好努力!















 104
104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









