







摘要
近年来,汉字lattice结构被证明是一种有效的中文命名实体识别方法。然而,由于网格结构的复杂性和动态性,现有的基于网格的模型难以充分利用gpu的并行计算能力,推理速度通常较低。在本文中,我们提出了FLAT: FLAT - lattice-Transformer将lattice结构转化为由跨度组成的平面结构。每个跨度对应一个字符或潜在单词及其在原始格中的位置。借助Transformer的强大功能和精心设计的位置编码,FLAT可以充分利用lattice信息,具有良好的并行化能力。在四个数据集上的实验表明,FLAT在性能和效率上都优于其他基于词汇的模型。
介绍
命名实体识别在许多下游自然语言处理任务中扮演着不可获取的角色。与英文的NER相比,中文NER更困难,因为它涉及到分词。
最近,lattice结构被证明是对利用此信息和避免分词错误传播有很大的好处。我们可以将一个句子和一个词典进行匹配以获得其中的潜在单词,然后得到一个如图1所示的lattice。lattice是一个有向无环图,其中每个节点是一个字符或一个潜在字。
lattice包括一系列字符和句子中潜在的单词。它们不是按顺序排列的,单词的第一个字符和最后一个字符决定了它的位置。lattice中的一些单词对NER很重要。如图,在图1中“人和药店”可用于区分地理实体“重庆”和“重庆人”。

有两种方法可以利用lattice。(1)一个方法是设计一个与lattice输入兼容的模型,例如lattice-LSTM和LR-CNN。在lattice-LSTM中,使用一个额外的字单元对潜在的字进行编码,并使用注意力机制在每个位置融合可变数量的节点。如图b.

LR-CNN使用CNN将对不同窗口大小的潜在单词进行编码。然而,RNN和CNN很难对长距离依赖性进行建模,这可能在NER中有用,例如共同引用。由于动态网络结构,这些方法不能充分利用GPU的并行计算。
(2)另一种方式是将lattice转换为图形,并使用图形神经网络(GNN)对其进行编码,例如lexicon-based Graph Network(LGN)和协作图形网络(CNN)。虽然序列结构对NER仍然很重要,而图是一般的对应物,他们之间的差距不可忽视。这些方法需要使用LSTM作为底部编码器来携带序列电感偏置,这使得模型变得复杂。
在这篇论文中,我们为中文命名实体识别提出了Flat Lattice Transformer。Transformer采用全连接的自注意力机制来模拟序列中的长距离依赖关系。为了保留位置信息,Transformer为序列中的每个标记引入位置表示。受位置表示思想的启发,我们为lattice结构设计了一种巧妙的位置编码,如©展示。

具体而言,我们为一个标记(字符或者单词)指定了两个位置索引:头部位置和尾部位置,通过这两个位置索引,我们可以从一组标记重建一个lattice。因此,我们直接使用Transformer对lattice输入进行完全建模。Transformer的自注意力机制使字符能直接与任何潜在单词交互,包括自匹配单词。对于字符,它的自匹配单词表示包含它的词。例如,在(a),药是“人和药店”和“药店”。实验结果表明,我们的模型在性能和推理速度上优于其他词典的方法。
2 背景
在本节中,我们简要介绍Transformer架构。针对于NER任务,我们只讨论Transformer编码。它由自注意力机制和前馈神经网络组成。每个子层之后是剩余连接和层规范化。FFN具有非线性变换的位置感知多层感知器。Transformer在注意头序列上单独执行自注意力机制,然后连接H头的结果。为了简单起见,我们在下面的公式中忽略了头指数。每个头的计算结果如下:
E是token嵌入查找表或最后一个transformer层的输出。Wq,Wk,Wv属于Rdmodeldhead是科学系的参数,dmodel=Hdhead,dhead是每个头部的维度。
vanilla Transformer还使用绝对位置编码来捕获序列信息。受Yan等人的启发,我们认为向量内点可交换性会导致自注意力方向性的丧失。因此,我们认为lattice的相对位置对NER也很重要。
3 Model
3.1 将lattice转换为Flat结构
在从具有词典的字符中获得一个lattice之后,我们可以将其展平为平面对应,平面格子(flat-lattice)可以定义为一组跨度,一个跨度对应一个标记、一个头部和一个尾部。如(C)所示。标记是一个字符或单词。头部和尾部表示原始序列标记中的第一个和最后一个字符的位置索引,它们表示标记在lattice中的位置。对于符号来说,他的头和尾巴是一样的。有一种简单的算法可以将flat-lattice恢复为其原始结构。首先,我们可以使用具有相同头部和尾部的标记来构造字符序列。然后,我们使用其他标记(单词)及其头部和尾部来构建跳过路径。由于我们的变换是可恢复的,我们假设flat-lattice可以保持lattice的原始结构。
3.2 跨度的相对位置编码
flat-lattice结构由不同长度的跨度组成。为了对跨度之间的相互作用进行编码,我们提出了跨度的相对位置编码。对于lattice中的两个跨度xi和xj,他们之间有三种关系:相交、包含和分离,有它们的头和尾决定。我们没有直接编码这三种关系,而是使用密集向量来建模他们之间的关系。它是通过头部和尾部信息的连续变换来计算的。因此,我们认为它不仅可以表示两个标记之间的关系,还可以表示更详细的信息,例如字符和单词之间的距离。让head[i]和tail[i]表示跨度xi的头部和尾部位置。四种相对距离可以用来表示xi和xj之间的关系。他们可以计算为:
dij(hh)表示xi的头部和xj的尾部之间的距离。其他dij(ht)有类似的含义。跨度的最终相对位置编码是四个距离的简单非线性变换:
Wr是一个学习参数,Pd的计算如下:
d是dij(hh),dij(ht),dij(th),dij(tt)或者k表示位置编码的维数索引。然后我们使用一种自注意力机制的变体来利用相对广度位置编码:
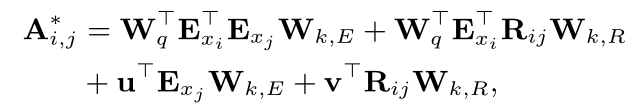
其中Wq,Wk,R,Wk,E属于Rmodeldhead,U,V属于Rdhead,这些都是学习参数。然后我们在第一个公式中用A 换成了A。接下来的计算和vanillaTransformer相同。
在Flat之后,我们只将字符表示带入输出层,然后是条件随机场(CRF)。
4 实验
4.1 实验设置
四个中文NER数据集用于评估我们的模型,包括(1)Notonotes 4.0(2)MSRA(3)Resume(4)Weibo。
在表1中显示了这些数据集的统计数据。

表1:四个数据集的统计数据。“Trani”是训练集的大小。Charavg,Wordavg,Entityavg是实例中按词典和实体匹配字符、单词的平均数量。
我们使用同一个训练接,验证集,测试集。我们采用BiLSTM-CRF和TENER作为基线模型。TENER是一种使用相对位置编码的Transformer,无需外部信息。我们还将Flat与其他基于词典的方法进行了比较。嵌入和词汇和Zhang和Yang相同。与CGN相比,我们使用的词汇与CGN相同。选择超参数的方法可以在补充材料中找到。特别是,我们的模型只使用了一层Transformer编码器。
4.2 整体表现
如表2所示,在四个中文NER数据集上,我们的模型优于基线模型和其他基于词典的模型。

表2:四个数据集结果(F1)。BiLSTM结果来自Zhang和Yang。PLT表示多孔lattice Transformer。‘YJ’表示Zhang和Yang发布的词典,“LS”表示Li等人发布的词典。其他模型的结果来自他们的原始论文。除了上标*表示原始文件中没有提供结果。我们通过运行公共源代码获得结果。下表“msm”和‘mld’分别表示带有自匹配单词和长距离(>10)掩码的FLAT。
我们的模型比TENER的性能好1倍。F1平均值为1.72.对于lattice LSTM,我们的模型的平均F!提升为1.51。当使用另一个词汇是,我们的模型F1平均值也比CGN好0.73。可能由于Transformer的特性,与其他基于词典的模型相比,FLAT在小数据及上的改进不如大数据集上那么显著。
4.3 全连接结构的特点
我们认为自注意力机制比LSTM有两个优点:1)所有字符都可以直接与其匹配的单词进行交互。2)长距离依赖可以完全建模。由于我们的模型只有一层,我们可以通过掩蔽相应的注意力来分开他们。具体来说,我们掩盖了符号对其自身匹配单词的注意,以及距离超过10的标记之间的注意。如表2所示,第一个掩模的性能显著下降至平坦,而第二个掩模的性能略有下降。因此,我们认为利用自匹配词的信息对汉语学习者很重要。
4.4 FLAT的性能
为了验证我们模型的计算效率,我们在Ontonotes上比较了不同基于词典的模型的推理速度。结果如图3所示。

图3:与lattice LSTM相比,不同的模型的推理速度。表示非批处理并行版本,以及表示模型以16批大小并行运行。对于LR-CNN幸好,我们没有得到他的批处理并行版本。
基于GNN的模型优于lattice LSTM和LR-CNN。但基于GNN的模型的RNN编码器也降低了它们的速度。由于我们的模型没有递归模块,并且可以充分利用GPU的并行计算,因此在运行效率方面优于其他方法。在利用批处理并行性方面,当batchsize=16,批处理并行性带来的加速比杜宇FLAT是4.97,对于Lattice LSTM来说是2.1,。由于我们模型的简单性,他可以更显著地受益于批处理并行性。
4.5 FLAT如何带来提升
与TENER相比,FLAT充分利用了词汇资源,并使用了一种新的位置编码。探讨这两个因素如何带来改善,我们设置了两个新指标,1)Span F:NER中使用的通用F值同时考虑了Span和实体类型的正确性,而Span F只考虑了前者。2)Acc类型:完全正确预测与范围正确预测的比例。表3显示了Ononotes和MSRA开发集上三个模型的两个指标。我们可以发现:1)FLAT在两个指标上显著优于TENER。2)FLAT对Span F的改善比Acc更为显著。3)与FLAT相比,Span F 上的FLAThead劣化比Acc更显著。这表明:1)新的位置编码有助于FLAT更准确地定义实体。2)预训练单词级嵌入使FLAT在实体分类中更强大。
4.6 与BERT的兼容性
我们还在四个数据集上比较了配备BERT的FLAT和普通BERT+CRF标记器,结果如表4所示。我们发现,对于Ontonotes和MSRA这样的大型数据集,FLAT BERT可以比BERT有显著的改进。但对于简历和微博这样的小数据集来说,FLAT+BERT相对于BERT的改善是微乎其微的。
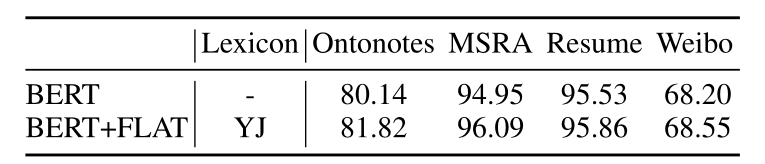
表4:BERT和BERT FLAT之间的比较。“BERT”指的是BERT+MLP+CRF架构。“FLAT BERT”指的是使用BERT嵌入的FLAT。在训练期间,我们对这两个模型进行了微调。实验中的BERT是Cui等人发布的‘BERT-wwn’,我们在fastNLP的BERTm嵌入中使用它。
5 相关工作
5.1 Lexicon-based NER
Zhang和Yang引入了一种lattice LSTM, 对于一个词汇在一个句子中识别的所有字符和潜在单词进行编码,在利用单词信息的同时避免了切分的错误传播。Gui等人利用CNN和反思机制的结合,对不同窗口大小的字符序列和潜在单词进行编码。上述两种模型的推理效率都很低,并且很难对长距离依赖进行建模。Gui等人和Sui等人利用词典和字符序列来构造图,将NER转换为结点分类任务。然而,由于NER的标签和输入的强对齐,他们的模型需要一个RNN模块进行编码。我们的模型和上述模型的主要区别在于,他们根据lattice修改模型结构,而我们使用精心设计的位置编码来知识latttice结构。
5.2 Lattice-based Transformer
对于lattice-based Transformer,它已经被用于语音翻译和中文源代码翻译。他们之间的主要区别在于表示lattice结构。在中文源代码翻译中,Xiao等人将节点第一个字符的绝对位置和每对节点之间的关系作为结构信息。在语音翻译中,Sperber等人使用到起始节点的最长距离来表示lattice结构,Zhang等人使用两个节点之间的最短距离。我们的跨度位置编码更自然,可以映射到所有三种方式,但反之亦然。由于NER比翻译对应位置更敏感,因此我们的模型更适合NER。最近,Porus lattice Transformer被提出用于中文NER。FLAT和Porus Lattice Transformer的主要区别在于位置信息的表示方式。我们使用“头”和“尾”来表示标记在lattice中的位置。他们使用“头”、标记的相对关系(不是距离)和额外的GRU。他们还使用“porouw”技术来限制注意力分布。在他们的模型中,位置信息是不可恢复的,因为“头部”和相对关系会导致位置信息丢失。简而言之,相对距离比相对关系承载更多信息。
6 结论和今后工作
在本文中,我们引入了一个flat-lattice Transformer来整合中文NER的lexicon信息。我们模型的核心是将lattice结构转换为一组跨度,并引入特定的位置编码。实验结果表明,我们的模型在性能和效率上优于其他基于词典的模型。我们把调整模型以适应不同种类的lattice或者图形作为我们未来的工作。
7 致谢
我们感谢匿名评论者的负责人态度和有益的评论。我们感谢孙天翔、邵永芬和李磊的帮助,例如绘画技巧分享,预习等。中国国家自然科学基金、上海市科技重大专项、中国国家重点研究开发计划资助。















 1138
1138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









