






目录
面向 Prometheus 的 Redis-exporter 监控
实习期间,了解到,企业级开发中多个项目使用Redis,运行Redis实例的有可能是同一台物理机器,那么,前一个项目的数据过期了,新的项目重新部署Redis,就要关注Redis的内存存储效率了,毕竟硬件资源成本高且有限。在使用 Redis 时,经常会遇到这样一个问题:做了数据删除,数据量已经不大了,使用 top 命令查看时,为什么 Redis 还是占用了很多内存呢?
实际上,这是因为,当数据删除后,Redis 释放的内存空间会由内存分配器管理,并不会立即返回给操作系统。所以,操作系统仍然会记录着给 Redis 分配了大量内存。但是,这往往会伴随一个潜在的风险点:Redis 释放的内存空间可能并不是连续的,那么,这些不连续的内存空间很有可能处于一种闲置的状态。这就会导致一个问题:虽然有空闲空间,Redis 却无法用来保存数据,不仅会减少 Redis 能够实际保存的数据量,还会降低 Redis 运行机器的成本回报率。这就是内存碎片化!
内存碎片是如何形成的?
内存碎片的形成有两个原因:一是操作系统的内存分配机制,二是 Redis 的负载特征。
内存分配器的分配策略
内存分配器一般是按固定大小来分配内存,而不是完全按照应用程序申请的内存空间大小给程序分配。Redis 可以使用 libc、jemalloc、tcmalloc 多种内存分配器来分配内存,默认使用 jemalloc。jemalloc 的分配策略之一,是按照一系列固定的大小划分内存空间,例如 8 字节、16 字节、32 字节、48 字节,…, 2KB、4KB、8KB 等。当程序申请的内存最接近某个固定值时,jemalloc 会给它分配相应大小的空间。这样的分配方式本身是为了减少分配次数。但是,如果 Redis 每次向分配器申请的内存空间大小不一样,这种分配方式就会有形成碎片的风险。
键值对大小不一样和删改操作
Redis 作为缓存系统或键值数据库对外提供服务时,不同业务的数据都可能保存在 Redis 中,会带来不同大小的键值对。这样,Redis 申请内存空间分配时,本身就会有大小不一的空间需求。其次,键值对会被修改和删除,这会导致空间的扩容和释放。一方面,如果修改后的键值对变大或变小了,就需要占用额外的空间或者释放不用的空间。另一方面,删除的键值对就不再需要内存空间了,此时,就会把空间释放出来,形成空闲空间。
大量内存碎片的存在,会造成 Redis 的内存实际利用率变低;解决问题前,要先判断 Redis 运行过程中是否存在内存碎片。
如何判断是否有内存碎片?
Redis 是内存数据库,内存利用率的高低直接关系到 Redis 运行效率的高低;Redis 提供了 INFO 命令,可以用来查询内存使用的详细信息:

mem_fragmentation_ratio:表示的就是 Redis 当前的内存碎片率。这个碎片率是上面命令中的两个指标 used_memory_rss 和 used_memory 相除的结果。
mem_fragmentation_ratio = used_memory_rss/ used_memoryused_memory_rss 是操作系统实际分配给 Redis 的物理内存空间,里面就包含了碎片;而 used_memory 是 Redis 为了保存数据实际申请使用的空间。
如何根据以上指标判断是否内存碎片化严重呢?提供一些经验阈值:
mem_fragmentation_ratio 大于 1 但小于 1.5。这种情况是合理的。因为,上面介绍的那些因素是难以避免的。毕竟,内因的内存分配器是一定要使用的,分配策略都是通用的,不会轻易修改;而外因由 Redis 负载决定,也无法限制。所以,存在内存碎片也是正常的。mem_fragmentation_ratio 大于 1.5 。表明内存碎片率已经超过了 50%。这时就需要采取一些措施来降低内存碎片率。
通过上面我的Redis截图发现,此时内存碎片率已经比较高了,需要清理内存碎片了!
如何清理内存碎片?
Redis 自身提供了一种内存碎片自动清理的方法,简单来说,就是“搬家让位,合并空间”。当有数据把一块连续的内存空间分割成好几块不连续的空间时,操作系统就会把数据拷贝到别处。此时,数据拷贝需要能把这些数据原来占用的空间都空出来,把原本不连续的内存空间变成连续的空间。否则,如果数据拷贝后,并没有形成连续的内存空间,这就不能算是清理了。
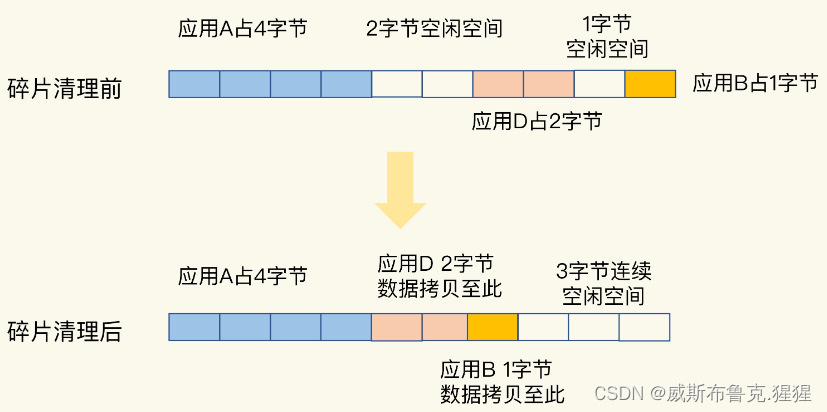
注意:碎片清理是有代价的,操作系统需要把多份数据拷贝到新位置,把原有空间释放出来,这会带来时间开销。因为 Redis 是单线程,在数据拷贝时,Redis 只能等着,这就导致 Redis 无法及时处理请求,性能就会降低。
Redis 专门为自动内存碎片清理功机制设置参数了,可以通过设置参数,来控制碎片清理的开始和结束时机,以及占用的 CPU 比例,从而减少碎片清理对 Redis 本身请求处理的性能影响。
把 activedefrag 配置项设置为 yes,命令如下:
config set activedefrag yes这个命令只是启用了自动清理功能,但是,具体什么时候清理,会受到下面这两个参数的控制。这两个参数分别设置了触发内存清理的一个条件,如果同时满足这两个条件,就开始清理。在清理的过程中,只要有一个条件不满足了,就停止自动清理。
1)active-defrag-ignore-bytes 100mb:表示内存碎片的字节数达到 100MB 时,开始清理;
2)active-defrag-threshold-lower 10:表示内存碎片空间占操作系统分配给 Redis 的总空间比例达到 10% 时,开始清理。
为了尽可能减少碎片清理对 Redis 正常请求处理的影响,自动内存碎片清理功能在执行时,还会监控清理操作占用的 CPU 时间,而且还设置了两个参数,分别用于控制清理操作占用的 CPU 时间比例的上、下限,既保证清理工作能正常进行,又避免了降低 Redis 性能。如下:
1)active-defrag-cycle-min 25: 表示自动清理过程所用 CPU 时间的比例不低于 25%,保证清理能正常开展;
2)active-defrag-cycle-max 75:表示自动清理过程所用 CPU 时间的比例不高于 75%,一旦超过,就停止清理,从而避免在清理时,大量的内存拷贝阻塞 Redis,导致响应延迟升高。
小结
-
info memory 命令是一个好工具,可以帮助查看碎片率的情况;
-
碎片率阈值是一个好经验,可以帮忙有效地判断是否要进行碎片清理了;
-
内存碎片自动清理是一个好方法,可以避免因为碎片导致 Redis 的内存实际利用率降低,提升成本收益率。
建议: 内存碎片自动清理涉及内存拷贝,这对 Redis 而言,是个潜在的风险。如果在实践过程中遇到 Redis 性能变慢,记得通过日志看下是否正在进行碎片清理。如果 Redis 的确正在清理碎片,那么,建议调小 active-defrag-cycle-max 的值,以减轻对正常请求处理的影响。
最后,INFO命令中的返回参数有很多,也很有用,值得总结下!
INFO命令
Redis 本身提供的 INFO 命令会返回丰富的实例运行监控信息,这个命令是 Redis 监控工具的基础。通过给定可选的参数 section ,可以让命令只返回某一部分的信息:
redis 127.0.0.1:6379> INFO [section]
section可选项:
1. Server 服务器运行的环境参数
2. Clients 客户端相关信息
3. Memory 服务器运行内存统计数据
4. Persistence 持久化信息
5. Stats 通用统计数据
6. Replication 主从复制相关信息
7. CPU CPU 使用情况
8. Cluster 集群信息
9. KeySpace 键值对统计数量信息
默认显示所有的信息,通过指定section,可以只显示想看的内容。
把 INFO 命令的返回信息分成 5 大类,其中,有的类别当中又包含了不同的监控内容,如下表所示:
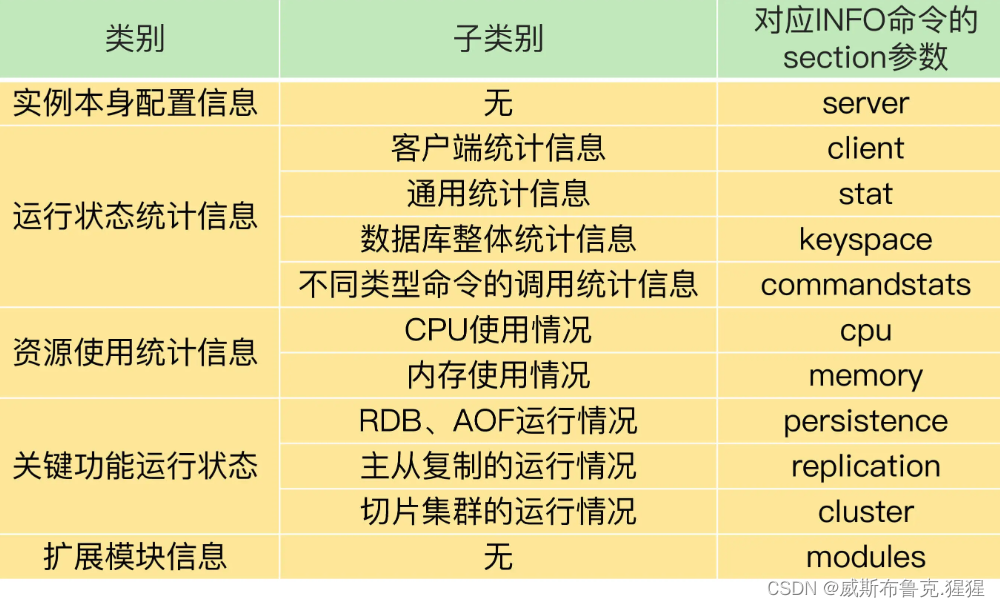
在监控 Redis 运行状态时,INFO 命令返回的结果非常有用。无论是运行单实例或是集群,建议重点关注一下 stat、commandstat、cpu 和 memory 这四个参数的返回结果,这些里面包含了命令的执行情况(比如命令的执行次数和执行时间、命令使用的 CPU 资源),内存资源的使用情况(比如内存已使用量、内存碎片率),CPU 资源使用情况等,可以帮助程序员判断实例的运行状态和资源消耗情况。
不过,INFO 命令只是提供了文本形式的监控结果,并没有可视化,所以,在实际应用中,还可以使用一些第三方开源工具,将 INFO 命令的返回结果可视化。当前最流行应该就是Prometheus + Grafana工具的使用了。
Linux监控命令
Redis需要运行在Linux上,所以也会用到Linux的监控命令。top命令是Linux中常用的分析性能的工具,能够实时监控系统中各个进程资源占用的情况;包括 CPU 使用率、内存使用量、磁盘 I/O 等。
Linux系统中top命令详解_linux top_码农联盟的博客-CSDN博客
面向 Prometheus 的 Redis-exporter 监控
Prometheus是一套开源的系统监控报警框架。它的核心功能是从被监控系统中拉取监控数据,结合Grafana工具,进行可视化展示。而且,监控数据可以保存到时序数据库中,以便程序员进行历史查询。同时,Prometheus 会检测系统的监控指标是否超过了预设的阈值,一旦超过阈值,Prometheus 就会触发报警。根据下图更好理解这些工具组件之间的关系:
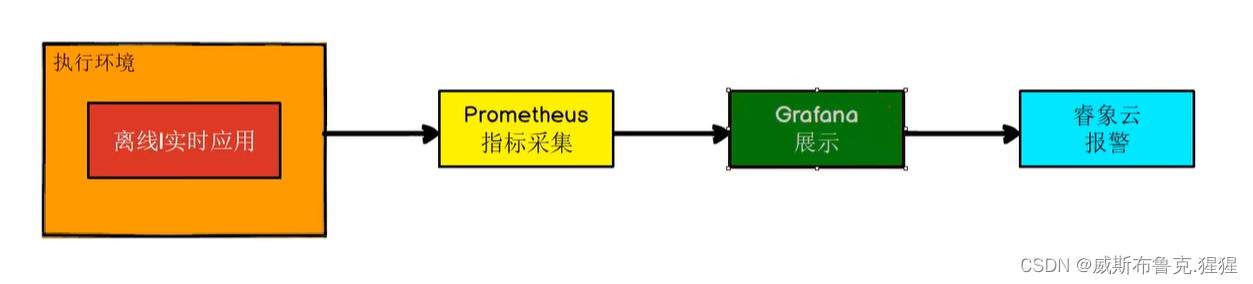
prometheus采集数据,Grafana进行数据展示
grafana是一款采用go语言编写的开源应用,主要用于大规模指标数据的可视化展示,是网络架构和应用分析中最流行的时序数据展示工具,目前已经支持大部分常用的时序数据库。
Prometheus 提供插件功能来实现对一个系统的监控,把插件称为 exporter,每一个 exporter 实际是一个采集监控数据的组件。Redis-exporter就是用来监控 Redis 的,它将 INFO 命令监控到的运行状态和各种统计信息提供给 Prometheus,从而进行可视化展示和报警设置。当然了,除了监控Redis的插件,还有别的,从官网(Download | Prometheus)上截取部分:

下面是我学习prometheus时参考的文章,帮助更高效使用这个工具:
Prometheus监控Redis集群+Grafana实现可视化(图文详解!)
其它linux常见的性能监控命令,看这篇文章:















 1053
1053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









