







本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
以下文章来源于腾讯云 作者:Python进击者
( 想要学习Python?Python学习交流群:1039649593,满足你的需求,资料都已经上传群文件流,可以自行下载!还有海量最新2020python学习资料。 )

1
说在前面的话
在上一篇文章中我们介绍了scrapy的一些指令和框架的体系,今天咱们就来实战一下,用scrapy爬取当当网(网站其实大家可以随意找,原理都是一样)的数据。废话不多说,看下面↓
2
思路分析
当当网:

上图就是所谓的当当网,一个电商网站,我们随意找一个类别来进行爬取吧
就拿手机的界面来说事!

我们来抓取下图中红框的数据:
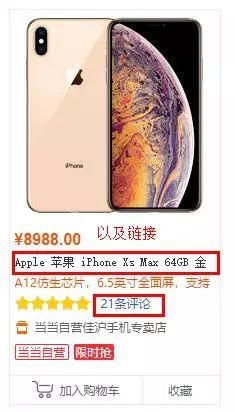
其实就三个数据,一个手机的名称以及相关的链接和评论的数量

大家可以从上图中可以看到这几个数据的标签位置,我们就可以直接通过xpath来进行简单的提取,xpath很简单,不会的朋友百度一下就明白了。
我们爬取完这些数据后就把这些数据存储到数据库当中。
3
正式操作啦
首先,因为我们要抓取网页中的标题、链接和评论数,所以我们首先得写items.py(具体的作用,我上篇文章有讲,大家可以去看一下):
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
comment = scrapy.Field()
我们需要抓取什么数据就调用scrapy.Field()这个方法在上面的注释中官方有给出。
我们在这里添加完我们需要爬取的哪些数据后,我们在转向我们的爬虫文件,我们通过 scrapy genspider dd dangdang.com 创建了一个爬虫文件dd.py:
# -*- coding: utf-8 -*-
import scrapy
# 我们需要导入这个项目里的items.py中的类
from dangdang.items import DangdangItem
# 导入scrapy中的Request
from scrapy.http import Request
'''
爬取当当网上的链接等信息
'''
class DdSpider(scrapy.Spider):
# 这里是爬虫的名称
name = 'dd'
# 这里是域名
allowed_domains = ['dangdang.com']
# 这里是我们要爬取的界面
start_urls = ['http://category.dangdang.com/pg1-cid4004279.html']
def parse(self, response):
# 实例化对象
item = DangdangItem()
# 通过分析标签,我们可以依次得到相关的数据,并将它们赋值给item类中
item["title"] = response.xpath("//a[@name='itemlist-title']/@title").extract()
item["link"] = response.xpath("//a[@name='itemlist-title']/@href").extract()
item["comment"] = response.xpath("//a[@name='itemlist-review']/text()").extract()
# 提交数据,把数据传送给item类
yield item
我把每一句话的解释都写在注解里了,其实这个爬虫文件才是真正的进行了爬取工作,它把爬取的数据全部传送给我们之前写的item.py里的类中,然后我们最后如果需要对数据进行处理,我们就需要进入pipelines.py进行数据的处理(比如添加到数据库或者写入txt中等等操作),接下来我们需要把我们所需要的数据存放至数据库。
在这之前我们需要进行两个操作!首先进入settings.py中,我们知道这里是我们整个项目的管理文件,我们找到如下代码:
# ITEM_PIPELINES = {
# 'dangdang.pipelines.DangdangPipeline': 300,
# }
我们要把这里的注释给去掉,因为我们要去使用pipelines文件进行数据的处理,去掉之后:
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300,
}
第二个也是在settings.py文件中:
ROBOTSTXT_OBEY = True
我们需要把它修改成False,因为大部分网站都是存在robots文件的,如果为true代表着我们遵循robots规则,这样会导致我们很多页面无法爬取,所以需要把它设置成False。
上面这两步处理之后,我们就可以正式写pipelines.py文件了(也就是可以正式操作数据了)
# -*- coding: utf-8 -*-
# 导入 pymysql库,这是python用于连接mysql数据库的专用库
import pymysql
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class DangdangPipeline(object):
def process_item(self, item, spider):
#连接数据库操作
conn = pymysql.connect("localhost", "root", "LS985548459", "dangdang", charset='utf8')
# 循环
for i in range(0, len(item["title"])):
# 获取每个标题
title = item["title"][i]
# 获取每个链接
link = item["link"][i]
# 获取每个评论
comment = item["comment"][i]
# 使用mysql语句进行插入数据表
sql = "insert into goods(title,link,comment) values ('"+title+"','"+link+"','"+comment+"');"
try:
#执行sql语句
conn.query(sql)
#提交语句,这句话必须写,否则无法成功!
conn.commit()
except Exception as e:
print(e)
# 关闭连接
conn.close()
return item
同样我把每一行的解释都写在了注释里面,如仍有疑问的,可以私聊我~
最后我们通过 scrapy crawl dd --nolog 运行一下我们的爬虫,运行完后,打开我们的数据库,发现已经完成添加了!

4
结尾
其实整个项目下来,我们会发现我们的思路很清晰,因为scrapy框架它把每一个步骤分解到不同的文件中解决,这样更有利于我们去写好整个项目,所以这里也要为scrapy框架的开发人员致谢!















 1055
1055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









