







目标
本节将继续讲解 Scrapy 框架的使用。具体包括 Scrapy 爬虫框架以及内部每个组件的使用(Selector 选择器、Spider 爬虫类、Downloader 和 Spider 中间件、ItemPipeline 管道类等)。
本例目标是爬取当当图书网站中所有关于 “python” 关键字的图片信息,网址http://search.dangdang.com/?key=python&act=input,要求将图书图片下载存储到指定目录,而图书信息写入到数据库中。
通过本例练习,要掌握 Scrapy 框架结构、运行原理、以及框架内部各个组件的使用。通过 Scrapy 框架的深入学习,学会自定义 Spider类爬取处理信息。
操作
运行爬虫之前,请导入 pythonbook.sql 到 MySQL。
- 第1步,创建工程
新建文件夹,用于存放项目。然后在命令行窗口中使用cd命令切换到当前目录,再输入下面命令创建Scrapy项目。
scrapy startproject dangdang
- 第2步,创建爬虫程序
使用cd命令切换到dangdang目录,再输入下面命令创建Scrapy程序。
cd dangdang
scrapy genspider pythonbook search.dangdang.com
- 第3步,自动创建目录及文件
完成前面2步操作,Scrapy会自动在指定文件夹中创建一个项目,并初始化爬虫程序文件的模板,如下图所示。
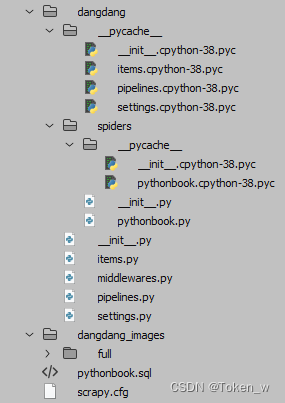
注意,一般创建爬虫文件时,以网站域名命名。
- 第4步,设置数据存储模板
打开items.py文件,然后输入下面代码,设置数据存储的模板。
import scrapy
class DangdangItem(scrapy.Item):
'''
当当图书的Item 类,包含所有要爬取的信息
'''
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() # 书名
price = scrapy.Field() # 价格
pic = scrapy.Field() # 图片链接
author = scrapy.Field() # 作者
publisher = scrapy.Field() # 出版商
comments = scrapy.Field() # 评论数量
pubdate = scrapy.Field() # 发行日期
description = scrapy.Field() # 描述
- 第5步,编写爬虫程序
在spiders子目录中打开pythonbook.py文件,然后输入下面代码,设置下载器开始下载的页面URL。以及爬虫要爬取的HTML结构片段。最后,使用for循环和迭代器,把每一个项目结构片段传递给items.py定义的字段模板。
完成本步操作之前,读者应该先熟悉目标页面的结构,以及要抓取的HTML片段,同时熟悉XPath基本语法,可以先使用浏览器访问该页面,使用F12键,查看一下HTML结构。
import scrapy, re
from dangdang.items import DangdangItem
class PythonbookPySpider(scrapy.Spider):
name = 'pythonbook'
allowed_domains = ['search.dangdang.com']
start_urls = ['http://search.dangdang.com/?key=python&act=input']
p = 1 # 爬取页数变量
def parse(self, response):
'''
递归解析响应数据
'''
print('*'*64)
dlist = response.selector.xpath(".//ul[@class='bigimg']/li")
for dd in dlist:
item = DangdangItem()
item['name'] = dd.xpath("./a/@title").extract_first() #good
price = dd.xpath(".//span[@class='search_now_price']").extract_first()
price = re.findall(".*?([0-9]*\.[0-9]*)",price)
if(price[0]):
item['price'] = price[0]
else:
item['price'] = None
item['pic'] = dd.xpath(".//img/@data-original|.//img/@src").extract_first()
item['author'] = dd.xpath(".//a[@name='itemlist-author']/@title").extract_first()
item['publisher'] = dd.xpath(".//a[@name='P_cbs']/text()").extract_first() #good
item['comments'] = dd.xpath(".//a[@class='search_comment_num']/text()").extract_first() #wrong
item['pubdate'] = dd.re_first("(([0-9]{4})-([0-9]{2})-([0-9]{2}))") #good
item['description'] = dd.xpath(".//p[@class='detail']/text()").extract_first() # good
yield item
self.p += 1
# 想爬取多少页?
if(self.p<=10):
next_url = "http://search.dangdang.com/?key=python&act=input&page_index=" + str(self.p)
url = response.urljoin(next_url)
yield scrapy.Request(url=url, callback=self.parse)
- 第6步,设置配置文件
打开settings.py文件,然后添加下面代码。
BOT_NAME = 'dangdang'
SPIDER_MODULES = ['dangdang.spiders']
NEWSPIDER_MODULE = 'dangdang.spiders'
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300, # 处理item的类
'dangdang.pipelines.MysqlPipeline' : 301, # 把item写入数据库的类
'dangdang.pipelines.ImagePipeline' : 302, # 下载图片的类
}
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'dangdang'
MYSQL_USER = 'root'
MYSQL_PASS = '11111111'
MYSQL_PORT = 3306
IMAGES_STORE = "./dangdang_images" # 存储图片的文件夹
- 第7步,编写数据处理脚本
打开pipelines.py文件,输入代码。设计图片下载和数据库存储。
import pymysql
from scrapy.exceptions import DropItem
from scrapy import Request
from scrapy.pipelines.images import ImagesPipeline
class DangdangPipeline(object):
'''处理item的类'''
def process_item(self, item, spider):
'''
处理爬取数据,如果爬取的书名没有,就把这条记录剔除。
:param item: 爬虫item类
:param spider: 爬虫超类
:return: 剔除条目或者item
'''
if item['name'] == None:
raise DropItem("Drop item found: %s" % item)
else:
return item
class MysqlPipeline(object):
'''处理item写入数据库的类'''
def __init__(self, host, database, user, password, port):
'''
构造类,创建全局变量
:param host: 数据库主机路径
:param database: 数据库名称
:param user: 数据库用户名
:param password: 数据库密码
:param port: 数据库端口
'''
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
self.db = None
self.cursor = None
@classmethod
def from_crawler(cls, crawler):
'''
类方法,用此方法获取数据库相应信息来连接数据库
:param crawler: crawler类
:return: 带有数据库信息的类。在这里调用类构造方法
'''
return cls(
host=crawler.settings.get("MYSQL_HOST"),
database=crawler.settings.get("MYSQL_DATABASE"),
user=crawler.settings.get("MYSQL_USER"),
password=crawler.settings.get("MYSQL_PASS"),
port=crawler.settings.get("MYSQL_PORT")
)
def open_spider(self, spider):
'''
通过设置文件里的信息链接到数据库,并准备好游标以便后面使用
:param spider:
:return:
'''
self.db = pymysql.connect(self.host, self.user, self.password, self.database, charset='utf8', port=self.port)
self.cursor = self.db.cursor()
def process_item(self, item, spider):
'''
执行插入操作,将item相应信息插入数据库并保存
:param item: 爬虫item类
:param spider: spider超类
:return: 爬虫item类
'''
sql = "insert into pythonbook(name,price,pic,author,publisher,comments, pubdate, description) values('%s','%s','%s','%s','%s','%s', '%s', '%s')"%(item['name'],item['price'],item['pic'],item['author'],item['publisher'],item['comments'], item['pubdate'],item['description'])
self.cursor.execute(sql)
self.db.commit()
return item
def close_spider(self, spider):
'''
关闭数据库连接
'''
self.db.close()
class ImagePipeline(ImagesPipeline):
'''处理图像的类'''
def get_media_requests(self, item, info):
'''
从item内拿到图片url信息,创建Request等待调度执行
:param item: 爬虫item类
:param info: 消息
:return: None, yield一个带图片URL的Request
'''
yield Request(item['pic'])
def item_completed(self, results, item, info):
'''
下载完成后,如果url不是有效的,就筛选掉这个数据。
:param results:
:param item:
:param info:
:return: 爬虫item类
'''
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
return item
- 第8步,执行爬虫
到上面一步,已经完成了爬虫程序的全部设计,下面就可以测试爬虫的工作状态了,在命令行窗口,使用cd命令进入dangdang目录,然后使用scrapy crawl命令进行测试。
scrapy crawl pythonbook
执行结果如下图:
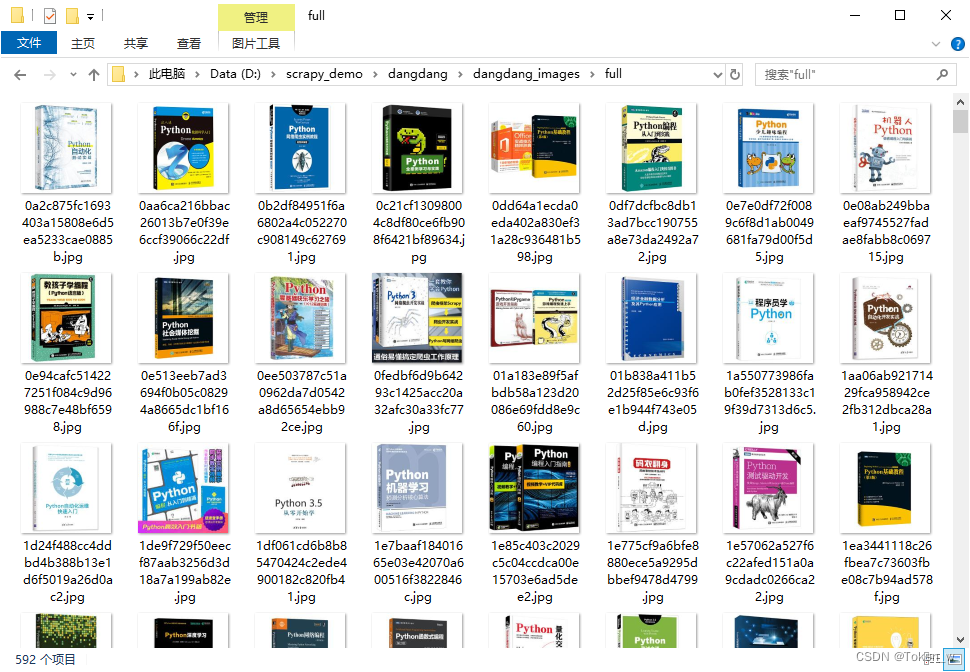
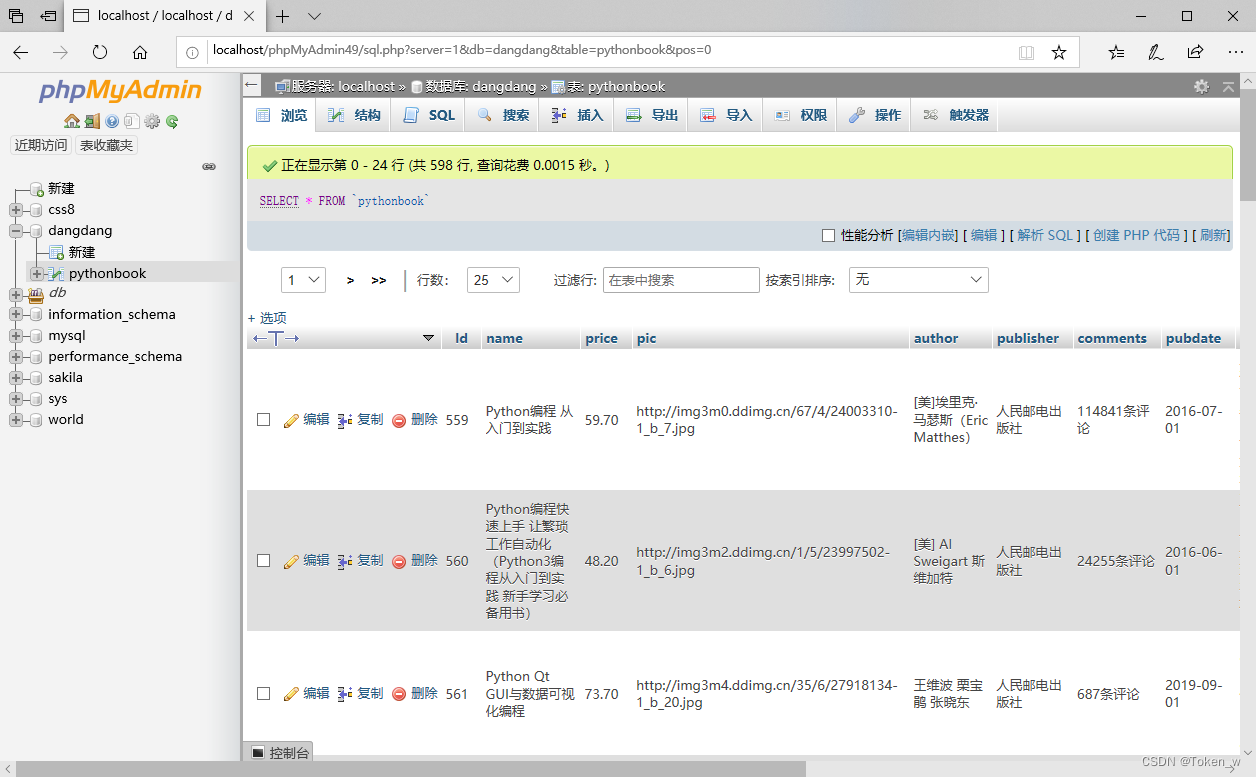

















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











