






 本文介绍了如何利用长短期记忆网络(LSTM)解决文本情感分类问题,特别是在电影评论数据集IMDB上的应用。文章详细阐述了LSTM相较于传统RNN的优势,包括解决梯度消失和记忆不足的问题,并展示了实验的具体过程及结果。
本文介绍了如何利用长短期记忆网络(LSTM)解决文本情感分类问题,特别是在电影评论数据集IMDB上的应用。文章详细阐述了LSTM相较于传统RNN的优势,包括解决梯度消失和记忆不足的问题,并展示了实验的具体过程及结果。
高级实训 任务三
文本情感分类
实验任务描述
将循环任务(RNN)应用在图像分割任务上,我们需要对网络结构进行设计。
这里选择的网络结构:LSTM。
数据集为:imdb。
深度学习框架:tensorflow。
实验环境配置
Anaconda获取
可直接从官网得到anaconda的最新版本
https://www.anaconda.com/products/individual
并且可以直接使用附带的spyder对代码进行编辑
tensorflow配置
在之前的项目中已经配置好tensorflow,这里不再赘述
数据集获取
该数据集可从其官网获取
https://www.kaggle.com/c/sentiment-analysis-on-movie-reviews
实验原理简介
RNN与LSTM介绍:
RNN主要用于处理NLP类的问题,如词向量表达、语句合法性检查、词性标注等。在RNN中,目前使用最广泛最成功的模型便是LSTM(Long Short-Term Memory,长短时记忆模型)模型,该模型通常比vanilla RNN能够更好地对长短时依赖进行表达,该模型相对于一般的RNN,只是在隐藏层做了手脚。
传统RNN存在的问题:
1)容易出现梯度爆炸和梯度弥散。虽然在某些情况下,其参数比卷积神经网络要少很多。但是,RNN并没有我们想象中的那么完美,随着循环次数的叠加,其梯度很容易出现梯度爆炸或者梯度弥散,而导致这个缺陷产生的主要原因是,传统RNN在计算梯度时,其公式中存在一个whh的k次方。
由于其梯度求解公式中有的k次方的存在,所以会出现下面的极限情况:

2)memory记忆不足
虽然我们使用了一个全局的memory去记录全局的语境信息,但实际上,memory只能记住很短的全局信息,随着迭代次数的增加,memory会渐渐遗忘前面的语境信息。
LSTM网络结构:
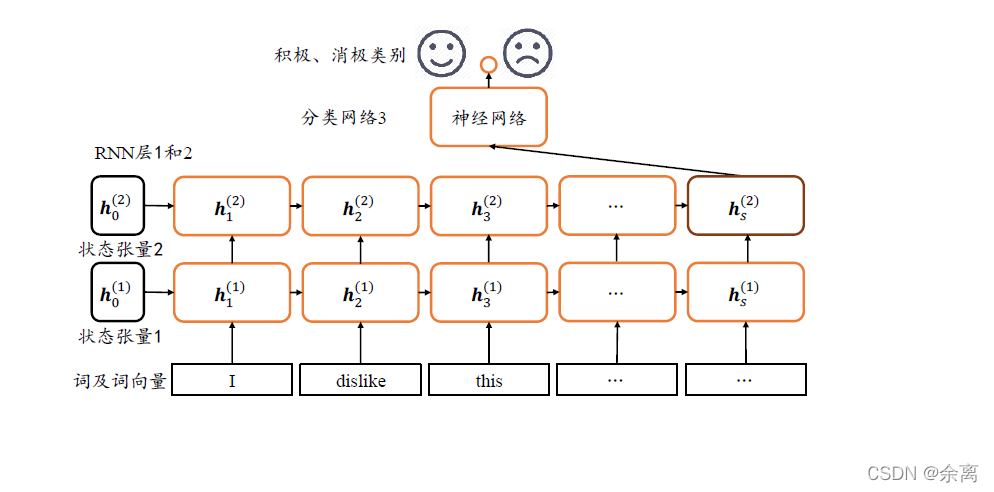
网络特征分析:
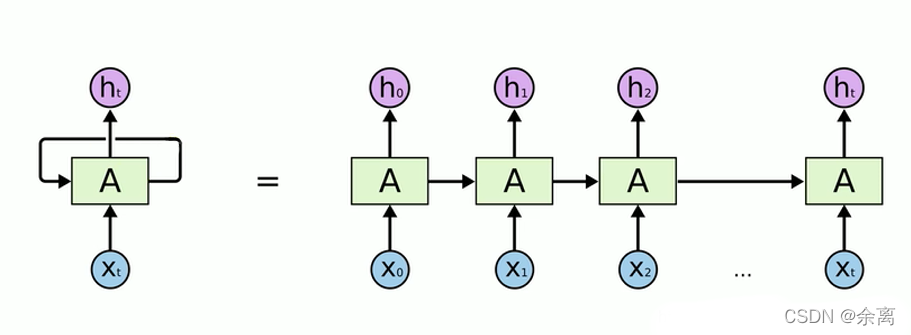
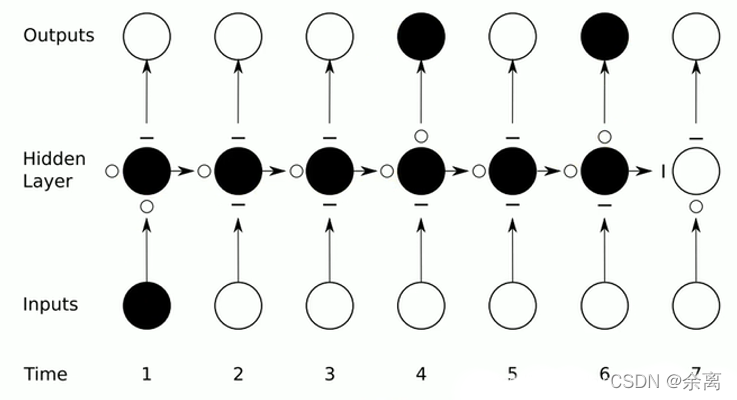
我们在处理文字等问题的时候,我们的输入会把上一个时间输出的数据作为下一个时间的输入数据进行处理。
例如:我们有一段话,我们将其分词,得到t个数据,我们分别将每一个词传入到x0,x1…xt里面,当x0传入后,会得到一个结果h0,同时我们会将处理后的数据传入到下个时间,到下个时间的时候,我们会再传入一个数据x1,同时还有上一个时间处理后的数据,将这两个数据进行整合计算,然后再向下传输,一直到结束。
rnn本质来说还是一个bp回路,不过他只是比bp网络多一个环节,即它可以反馈上一时间点处理后的数据。上图细化如下:
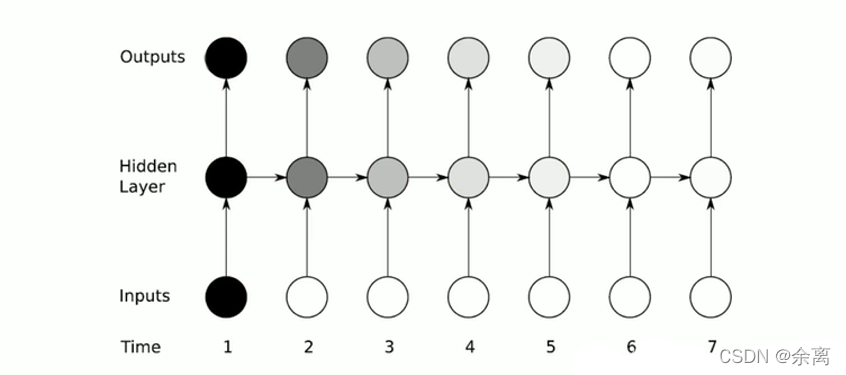
rnn实际上还是存在梯度消失的问题,因此如上图所示,当我们在第一个时间输入的数据,可能在很久之后他就已经梯度消失了(影响很小),因此我们使用lstm(long short trem memory)
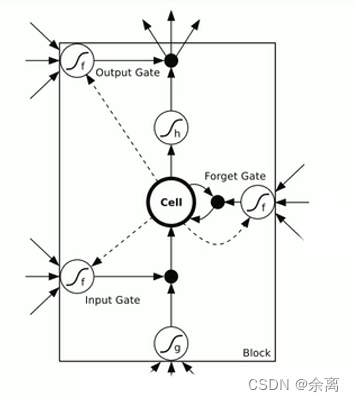
上图有三个门:输入门 忘记门 输出门
1.输入门:通过input * g 来判断是否输入,如果不输入就为0,输入就是0,以此判断信号是否输入
2.忘记门:这个信号是否需要衰减多少,可能为50%,衰减是根据信号来判断。
3.输入门:通过判断是否输出,或者输出多少,例如输出50%。
因此上述图可化为:
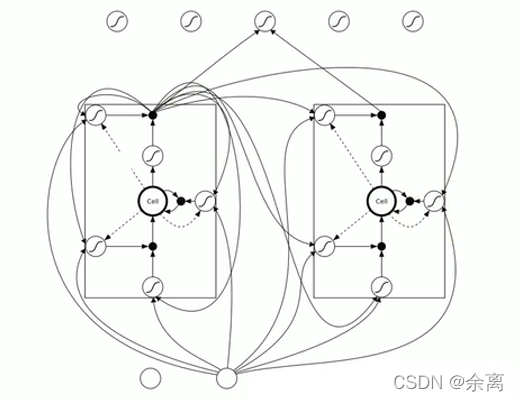
可以看出,这三个门,所有得影响都是关于输入和上一个数据得输出来进行计算的。可以看下图:
我们使用lstm的话,通过三个门决定信号是否向下传输,传输多少都可以控制,是否传入信号,输出信息都进行控制。
实验过程与结果
数据集的特殊性:
IMDB影评数据集中含有来自IMDB的25,000条影评,被标记为正面/负面两种评价。影评已被预处理为词下标构成的序列。方便起见,单词的下标基于它在数据集中出现的频率标定,例如整数3所编码的词为数据集中第3常出现的词。这样的组织方法使得用户可以快速完成诸如“只考虑最常出现的10,000个词,但不考虑最常出现的20个词”这样的操作,按照惯例,0不代表任何特定的词,而用来编码任何未知单词。
数据集已经过预处理:每个样本都是一个整数数组,表示影评中的字词。每个标签都是整数值0或1,其中0表示负面影评,1表示正面影评。影评文本已转换为整数,其中每个整数都表示字典中的一个特定字词。
将数据集中的整数转换回单词:
了解如何将整数转换回文本很有用。在以下代码中,我们创建一个辅助函数word_index来查询包含整数到字符串映射的字典对象:
# 查看编码
# 数字编码表
word_index = keras.datasets.imdb.get_word_index()
# 打印出编码表的单词和对应的数字
# for k,v in word_index.items():
# print(k,v)
# 前面4 个ID 是特殊位
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index["<PAD>"] = 0 # 填充标志
word_index["<START>"] = 1 # 起始标志
word_index["<UNK>"] = 2 # 未知单词的标志
word_index["<UNUSED>"] = 3
# 翻转编码表
reverse_word_index = dict([(value, key) for (key, value) in
word_index.items()])
# 对于一个数字编码的句子,通过如下函数转换为字符串数据:
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
print(decode_review(x_train[0]))
现在,我们可以使用 decode_review 函数显示第一条影评的文本:
decode_review(train_data[0])
输出如下:
" this film was just brilliant casting location scenery story direction everyone’s really suited the part they played and you could just imagine being there robert is an amazing actor and now the same being director father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also to the two little boy’s that played the of norman and paul they were just brilliant children are often left out of the list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don’t you think the whole story was so lovely because it was true and was someone’s life after all that was shared with us all"
测试例:
BLACK WATER is a thriller that manages to completely transcend it’s limitations (it’s an indie flick) by continually subverting expectations to emerge as an intense experience.In the tradition of all good animal centered thrillers ie Jaws, The Edge, the original Cat People, the directors know that restraint and what isn’t shown are the best ways to pack a punch. The performances are real and gripping, the crocdodile is extremely well done, indeed if the Black Water website is to be believed that’s because they used real crocs and the swamp location is fabulous.If you are after a B-grade gore fest croc romp forget Black Water but if you want a clever, suspenseful ride that will have you fearing the water and wondering what the hell would I do if i was up that tree then it’s a must see.
label: 正面的
预测结果: 正面的
测试的误差和准确率:
Final test loss and accuracy : [1.3201157276447002, 0.80188304]
实验结论
长短期记忆网络(LSTM)是一种时间循环神经网络,是RNN的一个优秀的变种模型,它继承了大部分RNN模型的特性,同时解决了梯度反向传播过程中产生的梯度消失问题。它非常适合于长时间序列的特征,能分析输入信息之间的整体逻辑序列。针对梯度弥散和memory记忆不足的缺陷,我们可以使用长短期记忆网络(LSTM)。
针对梯度爆炸,最简单有效的方法就是对每次求得的梯度,都进行缩放。即保持其梯度方向不变,梯度模长度缩放到某一范围。这样做能使得当前梯度前进的距离控制在某一个较小范围。
一个句子中,并不是所有单词都是有用的,也不是所有单词之间的语义是需要记住的,所以,LSTM网络在传统RNN网络中设置了三道闸门用于控制不同对象的输出量,达到选择性记忆的目的。
参考资料
https://www.samyzaf.com/ML/imdb/imdb.html
https://tensorflow.google.cn/tutorials/keras/basic_text_classification#download_the_imdb_dataset
https://github.com/jiajunhua/dragen1860-Deep-Learning-with-TensorFlow-book


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









