




我自己的原文哦~ https://blog.51cto.com/whaosoft/12128822
#2024评审结果公布
AI大佬晒出成绩单,又是被吐槽最严重的一届
NeurIPS 2024评审结果公布!AI大佬晒出成绩单,又是被吐槽最严重的一届.
NeurIPS 2024评审结果已经公布了!
收到邮件的小伙伴们,就像在开盲盒一样,纷纷在社交媒体上晒出了自己的成绩单。
俄亥俄州立大学助理教授晒图,明明评审员给的评价是「论文接收」,却没想到最终决定是「拒收」。
应该给这位审稿人颁发一个NeurIPS 2024最佳AC奖
顺便提一句,今年是NeurIPS第38届年会,将于12月9日-15日在加拿大温哥华举办。
AI大佬晒出成绩单
一些网友们早已晒出了自己的录用结果,好像一件大事。
来自洛桑联邦理工学院(EPFL)的博士Maksym Andriushchenko称,自己有3篇论文被NeurIPS 2024接收。
它们分别是:
论文一:Why Do We Need Weight Decay in Modern Deep Learning?
论文地址:https://arxiv.org/pdf/2310.04415
权重衰减(weight decay),比如在AdamW中传统上被视为一种正则化的方法,但效果非常微妙,即使在过度参数化的情况下也是如此。
而对大模型而言,权重衰减则扮演者完全不同的角色。与最初一版arXiv论文相比,研究人员对其进行了很多更新。
Andriushchenko表示,自己非常喜欢这项新实验,并且匹配了AdamW有效学习率,得到了完全相同的损失曲线,而没有使用权重衰减。
论文二:JailbreakBench(Datasets and Benchmarks Track)
论文地址:https://arxiv.org/pdf/2404.01318
JailbreakBench是全新评估大模型越狱能力的基准。上个月,该数据集在HuggingFace上,被下载了2500次。
而且,多家媒体还使用了这个越狱神器,Gemini 1.5技术报告中也将其用于模型稳健性的评估。
论文三:Improving Alignment and Robustness with Circuit Breakers
论文地址:https://arxiv.org/pdf/2406.04313
这篇论文发布之初,已经掀起了不少的讨论。
其中最重要的一点是,它有助于训练Cygnet模型,其在越狱竞技场上表现出惊人的性能,而这正是对防御是否有用的测试。
来自UT Austin的副教授Qixing Huang也有三篇论文被NeurIPS录用。
它们分别是:
局部几何感知神经曲面表示法CoFie。
以及另外两篇,一个是参数化分段线性网络PPLN,另一个是关于时空联合建模的运动生成。
谷歌DeepMind团队Self-Discover算法被NeurIPS 2024录用。
中国有句古话:千人千面。正如每个人都是独一无二的,每个问题也是独一无二的。如何让LLM通过推理解决复杂的看不见的问题?
Self-Discover最新论文证明了,模型可以从一般问题解决技术的集合中,组成特定用于任务的推理策略。
最新算法在GPT-4和PaLm 2-L上的性能比CoT高32%,而推理计算量比Self-Consistency少10-40倍。
论文地址:https://arxiv.org/pdf/2402.03620
又是被吐槽的一届
不论是哪个顶会,吐槽是必不可少的。
这不,网友们对NeurIPS 2024审稿结果,吵成一锅了。
纽约大学工学院的助理教授称,一篇在NeurIPS提交中得分相当高的论文被拒绝。原因竟是:「模拟器是用C++编写的,而人们不懂C++」。
他表示,论文被拒的现象太正常了,但是对这个被拒理由,实在是令人震惊。
还有一位大佬表示,团队的两篇关于数据集追踪的NeurIPS论文被拒了,尽管评审结果有积极的反馈。
这显然是,组委会试图人为地标尺较低的录取率。
「根据录取率而不是成绩来排挤研究,这一点其实我不太确定」。
无独有偶,UMass Amherst的教员也表达出了这种担忧:
我看到很多人抱怨 NeurIPS的AC,推翻了最初收到积极评审论文的决定。
作为一名作者和评审员,我能理解这种做法有多令人沮丧。作为一名区域主席,我也经历过管理那些勉强达到录用分数的论文的压力,特别是当项目委员会要求更严格的录用率时。
有趣的是,NeurIPS已经变得像「arXiv精选」——突出展示前一年的最佳论文。
一位UCSC教授Xin Eric Wang表示,一篇平均得分为6.75的NeurIPS投稿被拒绝了。
他表示,这是自己收到第二荒谬的元评审,最荒谬的那次,是因为结果中没有加「%」就否决了论文。
无论论文质量如何,似乎总会有无数理由可以否决一篇论文。
元评审中提到的关键问题,在原始评审中只是小问题,而且他们团队已经在回复中明确解决。Xin Eric Wang怀疑AC是否真正阅读了他们的回复:
(1) AC提出了一个重大问题,这是基于一个得分为8分的评审者的小建议,引用了「大部分数据」,但实际数字小于10%(如回复中所述)。
(2) AC指出缺少统计数据,这些数据评审者从未提及,而且在论文正文中已经清楚地呈现。
LLM参与评审
而且AI火了之后,大模型也被用来论文评审。
这次,NeurIPS 2024也不例外。
Reddit网友评论道,自己用一个月的时间审核6篇论文,当看到自己得到的是LLM的评价,真的很受伤。
还有人指出,在自己审阅的论文中,至少发现了3篇由大模型生成的评审意见,很可能还有更多,其中3篇明显是直接复制粘贴了ChatGPT输出,完全没有阅读论文。
这些评审都给了6分,Confidence为4,与其他所有人的评价完全不一致。
更有网友评价道,「论文评论的质量很低」。
一个评审者混淆了我们方法的基线,另一个评审者混淆了基线的派生(正如我们的工作所批评的那样)和我们方法的派生。我怀疑一些评论是由LLM产生的。
参考资料:
https://x.com/AlbertQJiang/status/1839048302794518806
https://x.com/PiotrRMilos/status/1839221714674229579
#DDPM
diffusion原理
本文以易于理解的方式介绍了DDPM的基本原理,包括其前向加噪和反向去噪过程,以及如何通过最小化两个高斯分布之间的KL散度来训练模型。同时,文章还简要提及了DDIM作为DDPM的加速方法,以及如何将条件信息融入diffusion模型进行生成控制。
现在大火的stable diffusion系列,Sora,stable video diffusion等视频生成模型都是基于了diffusion模型。而diffusion模型的基石就是DDPM算法(之后有一些diffusion的加速方法,但是原理上还是DDPM),所以需要我们对DDPM有一定的了解,了解了DDPM可以帮助我们更好的理解diffusion模型。
DDPM全称是Denoising Diffusion Probabilistic Models,最开始提出是用于去噪领域。原始论文中数学公式比较多,需要一定的数理基础。
https://arxiv.org/pdf/2006.11239.pdf
实际上,DDPM也没那么复杂,我们两个层面上理解下DDPM的过程,分别是基于vae和基于傅立叶变换。 下文中diffusion默认指代的是DDPM文中的diffusion model。
首先,我们可以简单对比下vae和diffusion的推理过程
- vae 把图像可学习的方式压缩到一个latent space
- diffusion 把图像通过n step 压缩成噪声,噪声再通过n step 去噪成图像
不同于vae encoder/decoder的叫法,diffusion 的两个过程称为前向过程(加噪)和反向过程(去噪),这两个过程的中间态是一个和输入图像相同尺寸的高斯噪声。 而vae是通过数据驱动的方式压缩到一个一维隐空间,这个隐空间也是一个高斯分布,并且不需要n step,而是只需要 1 step。
那其实主观上,可能我们觉得vae多直接啊,而且非常优雅!为啥不用vae?确实,生成模型用了很长时间vae,最后gan变成主流,现在是diffusion。生成模型越来越复杂了。 为什么越来越复杂大家还要用?最简单的解释就是,diffusion虽然很麻烦,但是效果好啊,架不住可以新发(水)几篇paper啊 ️。了解光流的同学一定听过RAFT等一个网络不够,我就cascade(级联)多个网络去学习的范式,diffusion也是类似的想法,但是这里并不是简单的把级联,diffusion建模的是信号本身的restoration,意味着diffusion这套建模可以用到1维分布、2维分布、一直到N维分布都可以。 这非常重要,接下来我们从第二个点进一步了解。
第二,我们可以通过傅立叶变换的思路去理解diffuison。不了解傅立叶变化的我简单说下,就是用一系列不同频率的余弦函数我们可以逼近任意的时域分布。
我们看最右边蓝色时域分布是一个非常奇怪的分布,实际上可以在频域拆解成若干 不同频率的余弦去表达。那么理论上,余弦可以表达任意分布!
我们学过中心极限定理:无论原始数据的分布如何,只要样本量足够大,这些样本均值的分布将近似为正态分布。我们再回过头看看,为什么我们能从一个高斯分布,通过diffusion model 还原出clear image,甚至是segmentation mask,depth等等表达,都是因为我们的源头是一个包含了所有可能分布的总和啊!
DDPM
我会通过尽可能简单的语言,带大家一起理解
- diffsuion 前向过程 和 反向过程的基本数学表达
- 为什么diffusion 的loss是那么设计的
- diffusion 训练/推理的时候是如何运作的
基本符号
diffusion原文中用 表示clear image, 表示高斯噪声, T一般都很大, 比如1000。 表示中间的图像和噪声混合的中间态, t越大, 混杂的噪声越大。
表示去噪过程中给定 的分布。
表示加噪过程中给定 的分布。
前向过程(加噪)
加噪过程为前向过程

编辑
忽略化简过程,整个马尔可夫链可以表示为

编辑
首先需要理解的是。
这里的 可以表示为 , 很明显, 这个正态分布的均值方差如下:
- 表示均值, 均值是
- 方差是 的正态分布,
那么根据正态分布的性质,我们可以得到如下转换:

编辑
所以最后 , 看起来就非常清晰了。 就是 和一个高斯噪声加权 得到的。这里的权重 和噪声水平相关。当噪声比较大的时候, 信号的权重比较小, 相反, 当噪声比较小的时候, 图像权重比较大。一般来说 都比较小, 且小于1。
根据上面的式子, 我们可以直接递推出,给定 的情况下, 的分布 。这对后面损失函数 的化简有帮助。不要惧怕新的符号, 这里的 并且 只是为了美观引入了新的变量, 让表达式更加简洁。也就是说在diffusion 加噪过程中, 只要知道了 clean image 和 , 就能推导出任意时刻的 。
所以我们也需要理解
文中称 为 variance schedule。我们需要保证足够大的T的时候, 最后的分布是一个isotropic Gaussian (各向同性的高斯分布)。 值一般在正向过程 中增加(和时间 相关)比如 。
反向过程(去噪)
diffusion的目标是学习reverse process(或者叫 diffusion process),即训练一个,从噪声还原回干净的图像。
我们可以写出最开始纯高斯分布的表达式

编辑
是已知的,我们还可以写出马尔可夫链单步的递推表达式:

编辑
安装上节的写法可以写成
注意,均值 就是DDPM要训练的单元,方差在DDPM中是固定的,后续DDPM的优化工作也做成可训练的了。
目标函数
众所周知,生成式网络都是为了让估计出来的分布更加接近真实的分布。由于分布这个东西很抽象,一般都是使用一个dataset,然后都是要最大化网络估计出来的后验分布似然,也就是上图中右下角的公式。实践中,这个公式不能直接优化,需要转化,VAE中优化ELBO也是同理。这里省略推导。
对于扩散模型,扩散模型是通过寻找使训练数据的可能性最大化反向马尔可夫转移来训练的。在实践中,训练等同于最小化负对数似然的变分上界。
了解KL 散度的同学应该知道,这个问题就是要 优化 KL 散度,使得预测的分布更加接近真实分布。更直观的可以看下图,红色表示真实分布,蓝色表示预测分布。
DDPM 把负对数的上界叫vlb,其实就是 负的ELBO。最终要优化的目标是

编辑
其中

编辑
上式中, target distribution predicted distribution)表示KL 散度。接下来,我们分别解释下
中 . 没有可学习的参数, 所以在训练的时候 是一个常量, 可以直接忽略! 的取值范围是 , q (.) 没有可学习的参数, target 分布是 的原因是化简的过程中用到了贝叶斯公式。我们可以写出预测的分布 的表达式:

编辑
在DDPM中,假设多元变量高斯分布是具有相同方差的独立高斯分布的乘积,这个方差值可以随时间t变化。在前向过程中,我们将这些方差设置为相同的大小。t比较小的时候,方差比较小,t比较大的时候,方差比较大。最终方差值没有采用学习策略,而是经验设置了常数,如下:

编辑
所以预测的分布 变成了
注意! 中另外一项 和 都是通过配方法配的权重, 具体参数见论文下式

编辑
注意:上面的 在推理过程中是不知道的!!!所以需要利用网络进行预测!!!
这里是为了美观,设置了两个变量 并且
所以,有趣的来了,我们不难看出,对于两个高斯分布求KL散度,变量还只有均值项,所以可以直接写成MSE的形式,因为它们肯定是正相关的。
, 而作者实验发现在预测 的时候给定timestep t会取得更好的效果。
还记得前向过程中, 我们推导得到给定 的情况下, 的分布 吗? 我们可以简单的表达 。
作者为了清晰起见定义了一个 是噪声, 符合 0 均值, 1 方差的正态分布。 变成了 是因为对于一个正态分布, 乘一个系数, 方差会变成系数的平方哦。
我们再把因变量放进去就可以得到 , 带入这个式子到
可以得到最终需要预测的表达式是:

编辑
所以简化为 必须预测 , 因为我们输入中已经包含了 了,,所以我们就必须要预测噪声!

编辑
是可学习参数,就是一个可学习的噪声预测器。带入到最终损失函数表达式,我们可以得到
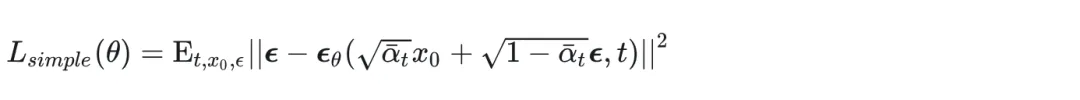
编辑
我们可以简单理解下 这个损失函数,这个损失函数有两个参数,一个是,我们可以理解为带有噪声的图像(clean image 和 noise 以一定的权重相加),另一个就是t,也就是到了中间哪个timestep。
网络结构
理论上,对网络结构的要求只有输入和输出维度一致。 作者最后选择了U-Net也不足为奇。
总结
对于training
repeat 表示 重复2-5行直到收敛
第二行表示从数据集中采样一张clean image,q 表示一个真实的数据分布
第三行表示从1-T(T很大,比如1000),采样一个t
第四行表示是噪声,从零均值,1方差的正态分布采样
最终的损失函数如 ,是在restore noise 而不是图像!最后计算的是restored noise 和 real noise 之间的MSE。
对于Sampling
也就是推理过程,实际上就是要递推
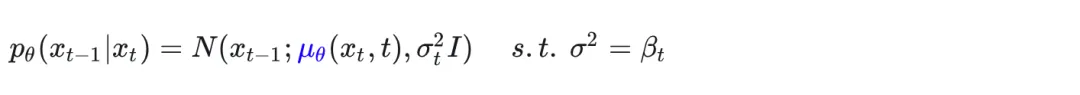
编辑
而我们网络学习到的,代入即可得到 算法2中第四行的式子
剩余细节
的处理我们还没有讲, ,简单提一下。在反向过程结束时,回想一下我们正在尝试生成一个由整数像素值组成的图像。因此,我们必须设计一种方法来获取所有像素上每个可能像素值的离散(对数)似然。详细的推导就不介绍了。
DDIM加速
DDIM(Denoising Diffusion Implicit Models)是后来提出的一种加速DDPM的方法,现在diffusion大多用的这个方法,一般可以加速差不多20倍,DDIM和DDPM有相同的训练目标,但是它不再限制扩散过程必须是一个马尔卡夫链,这使得DDIM可以采用更小的采样步数来加速生成过程,DDIM的另外是一个特点是从一个随机噪音生成样本的过程是一个确定的过程(中间没有加入随机噪音)。
如何加入condition
在最开始的时候,我买了一个坑说DDPM是从噪声还原出任意分布的一种建模方式,那么如何加入有效的引导,使这个生成变得可控呢?不妨看看google 的 Imagen,基于text 引导的 图像生成网络
https://www.assemblyai.com/blog/how-imagen-actually-works/#how-imagen-works-a-deep-dive
Imagen的流程如下
首先,将 caption 输入到一个 text encoder 中。这个 encoder 将文本形式的 caption 转换成一个数值表示,它封装了文本中的语义信息。
接下来,一个 image-generation model 通过从噪声,或者说 "TV static" 开始,逐渐将其转化为一个输出图像。为了引导这个过程,image-generation model 接收 text encoding 作为输入,这起到通知模型 caption 中包含了什么内容的作用,以便它能创建一个相应的图像。输出结果是一个小尺寸图像,它视觉上反映了我们输入到 text encoder 的 caption。
这个小尺寸图像随后被传递到一个 super-resolution model 中,这个模型将图像的分辨率提高。该模型同样将 text encoding 作为输入,这帮助模型决定在增加我们图像大小四倍时,如何填补由此产生的信息缺失。最终结果是我们所期望的中等大小的图像。
最后,这个中等大小的图像再被传递到另一个 super-resolution model 中,这个模型的运作方式与之前的几乎完全相同,只是这次它接收我们的中等大小图像,并将其扩大成一个高分辨率图像。成品是一个 1024 x 1024 像素的图像,它视觉上反映了我们 caption 中的语义。
在训练过程中,text-encoder 是冻结的,这意味着它不会学习或改变它创建 encodings 的方式。它只用于生成输入到模型其他部分的 encodings,而模型的这些部分是被训练的。
文本条件的引入
我们可以看下面这张图,实际上就是diffusion的反向过程中,他的条件加入了一个由文本编码得到的embedding。
总结与展望
diffusion 的讲解就到这里,diffusion model建模的是高斯分布restore到任意分布的过程。我个人并不认为这是图像生成式工作的终点,这个建模方式应用的非常广泛,其实没有利用图像的特点,比如二维信号特有的空间信息,像素关系等。未来如果根据图像本身的特点,或许能直接找到一条short cut,就类似DDIM等加速策略一样,优化贝叶斯公式,那应该会更加优雅高效。
参考
- https://www.assemblyai.com/blog/diffusion-models-for-machine-learning-introduction/
- 李宏毅老师https://www.youtube.com/watch?v=73qwu77ZsTM前向过程(加噪)
#WTConv
小参数大感受野,基于小波变换的新型卷积
这篇文章介绍了一种新型卷积层WTConv,它利用小波变换有效地扩大了卷积神经网络的感受野而不显著增加参数量,从而提升了网络性能。WTConv层可以作为现有CNN架构的直接替代,并在图像分类、语义分割和物体检测等多个计算机视觉任务中展示了其有效性。
近年来,人们尝试增加卷积神经网络(CNN)的卷积核大小,以模拟视觉Transformer(ViTs)自注意力模块的全局感受野。然而,这种方法很快就遇到了上限,并在实现全局感受野之前就达到了饱和。论文证明通过利用小波变换(WT),实际上可以获得非常大的感受野,而不会出现过参数化的情况。例如,对于一个

编辑
的感受野,所提出方法中的可训练参数数量仅以

编辑
进行对数增长。所提出的层命名为WTConv,可以作为现有架构中的替换,产生有效的多频响应,且能够优雅地随着感受野大小的变化而扩展。论文在ConvNeXt和MobileNetV2架构中展示了WTConv层在图像分类中的有效性,以及作为下游任务的主干网络,并且展示其具有其它属性,如对图像损坏的鲁棒性以及对形状相较于纹理的增强响应。
论文地址:https://arxiv.org/abs/2407.05848v2
论文代码:https://github.com/BGU-CS-VIL/WTConv
Introduction
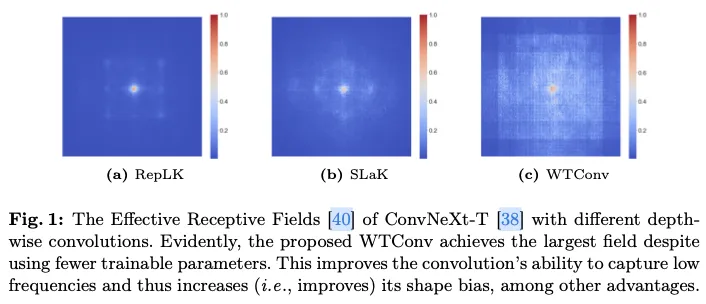
在过去十年中,卷积神经网络(CNN)在许多计算机视觉领域占主导地位。尽管如此,随着视觉Transformer(ViTs)的出现(这是一种用于自然语言处理的Transformer架构的适应),CNN面临着激烈的竞争。具体而言,ViTs目前被认为相较于CNN具有优势的原因,主要归功于其多头自注意力层。该层促进了特征的全局混合,而卷积在结构上仅局限于特征的局部混合。因此,最近几项工作尝试弥补CNN和ViTs之间的性能差距。有研究重构了ResNet架构和其训练过程,以跟上Swin Transformer。“增强”的一个重要改进是增加卷积核的大小。然而,实证研究表明,这种方法在的卷积核大小处就饱和了,这意味着进一步增加卷积核并没有帮助,甚至在某个时候开始出现性能恶化。虽然简单地将大小增加到超过并没有用,但RepLKNet的研究已经表明,通过更好的构建可以从更大的卷积核中获益。然而,即便如此,卷积核最终仍然会变得过参数化,性能在达到全局感受野之前就会饱和。
在RepLKNet分析中,一个引人入胜的特性是,使用更大的卷积核使得卷积神经网络(CNN)对形状的偏向性更强,这意味着它们捕捉图像中低频信息的能力得到了增强。这个发现有些令人惊讶,因为卷积层通常倾向于对输入中的高频部分作出响应。这与注意力头不同,后者已知对低频更加敏感,这在其他研究中得到了证实。
上述讨论引发了一个自然的问题:能否利用信号处理工具有效地增加卷积的感受野,而不至于遭受过参数化的困扰?换句话说,能否使用非常大的滤波器(例如具有全局感受野的滤波器),同时提升性能?论文提出的方法利用了小波变换(WT),这是来自时频分析的一个成熟工具,旨在有效扩大卷积的感受野,并通过级联的方式引导CNN更好地响应低频信息。论文将解决方案基于小波变换(与例如傅里叶变换不同),因为小波变换保留了一定的空间分辨率。这使得小波域中的空间操作(例如卷积)更加具有意义。
编辑
更具体地说,论文提出了WTConv,这是一个使用级联小波分解的层,并执行一组小卷积核的卷积,每个卷积专注于输入的不同频率带,并具有越来越大的感受野。这个过程能够在输入中对低频信息给予更多重视,同时仅增加少量可训练参数。实际上,对于一个的感受野,可训练参数数量只随着的增长而呈对数增长。而WTConv与常规方法的参数平方增长形成对比,能够获得有效的卷积神经网络(CNN),其有效感受野(ERF)大小前所未有,如图1所示。
WTConv作为深度可分离卷积的直接替代品,可以在任何给定的卷积神经网络(CNN)架构中直接使用,无需额外修改。通过将WTConv嵌入到ConvNeXt中进行图像分类,验证了WTConv的有效性,展示了其在基本视觉任务中的实用性。在此基础上,进一步利用ConvNeXt作为骨干网络,扩展评估到更复杂的应用中:在UperNet中进行语义分割,以及在Cascade Mask R-CNN中进行物体检测。此外,还分析了WTConv为CNN提供的额外好处。
论文的贡献总结如下:
- 一个新的层WTConv,利用小波变换(WT)有效地增加卷积的感受野。
- WTConv被设计为在给定的卷积神经网络(CNN)中作为深度可分离卷积的直接替代。
- 广泛的实证评估表明,WTConv在多个关键计算机视觉任务中提升了卷积神经网络(CNN)的结果。
- 对WTConv在卷积神经网络(CNN)的可扩展性、鲁棒性、形状偏向和有效感受野(ERF)方面贡献的分析。
Method
Preliminaries: The Wavelet Transform as Convolutions
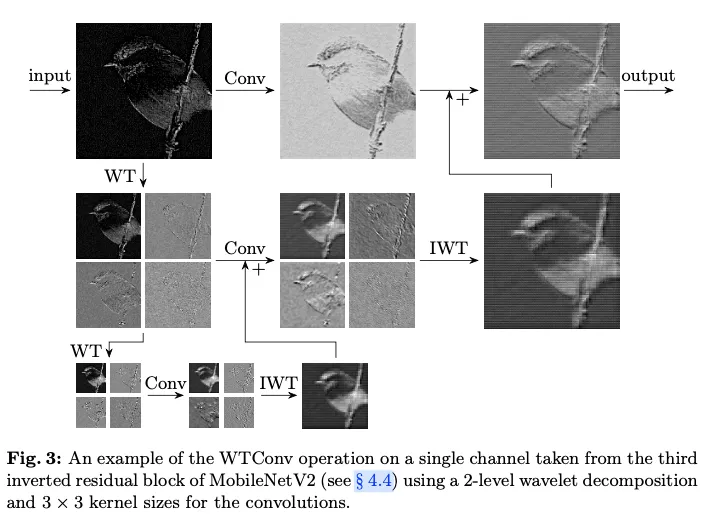
在这项工作中,采用Haar小波变换,因为它高效且简单。其他小波基底也可以使用,尽管计算成本会有所增加。
给定一个图像 , 在一个空间维度(宽度或高度)上的一层 Haar 小波变换由核为 和 的深度卷积组成, 之后是一个缩放因子为 2 的标准下采样操作。要执行 2D Haa r 小波变换, 在两个维度上组合该操作, 即使用以下四组滤波器进行深度卷积, 步距为 2:
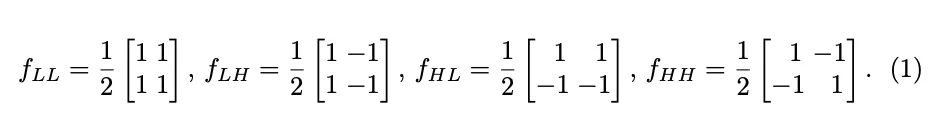
编辑
注意, 是一个低通滤波器, 而 是一组高通滤波器。对于每个输入通道, 卷积的输出为
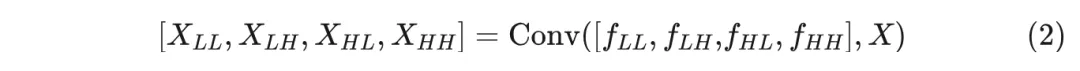
编辑
输出具有四个通道, 每个通道在每个空间维度上的分辨率为 的一半。 是 的低频分量, 而 分别是其水平、垂直和对角线的高频分量。
由于公式 1 中的核形成了一个标准正交基, 逆小波变换(IWT)可以通过转置卷积实现:
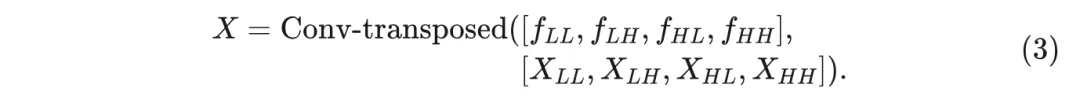
编辑
级联小波分解是通过递归地分解低频分量来实现的。每一层的分解由以下方式给出:
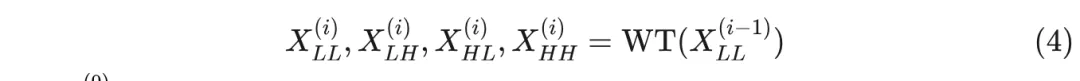
编辑
其中 , 而 是当前的层级。这导致较低频率的频率分辨率提高, 以及空间分辨率降低。
Convolution in the Wavelet Domain
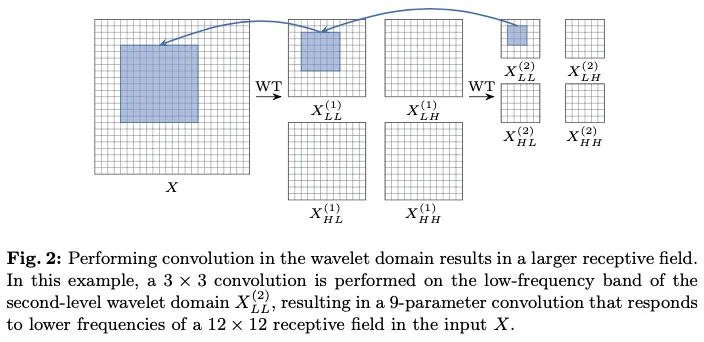
增加卷积层的核大小会使参数数量呈平方级增加,为了解决这个问题,论文提出以下方法。
编辑
首先,使用小波变换(WT)对输入的低频和高频内容进行过滤和下采样。然后,在不同的频率图上执行小核深度卷积,最后使用逆小波变换(IWT)来构建输出。换句话说,过程由以下给出:
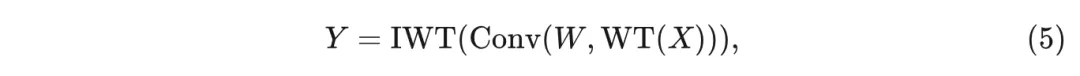
编辑
其中 是输入张量, 是一个 深度卷积核的权重张量, 其输入通道数量是 的四倍。此操作不仅在频率分量之间分离了卷积, 还允许较小的卷积核在原始输入的更大区域内操作, 即增加了相对于输入的感受野。
编辑
采用这种1级组合操作,并通过使用公式4中相同的级联原理进一步增加它。该过程如下所示:
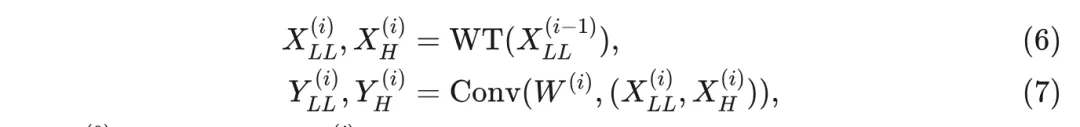
编辑
其中 是该层的输入, 表示第 级的所有三个高频图。
为了结合不同频率的输出, 利用小波变换 (WT ) 及其逆变换是线性操作的事实, 这意味着 。因此, 进行以下操作:
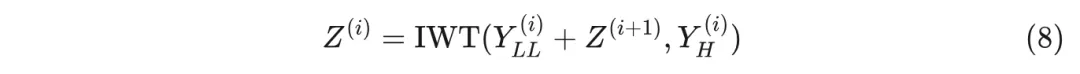
编辑
这将导致不同级别卷积的求和, 其中 是从第 级及之后的聚合输出。这与 RepLKNet 一致, 其中两个不同尺寸卷积的输出被相加作为最终输出。
与 RepLKNet 不同, 不能对每个 进行单独归一化, 因为这些的单独归一化并不对应于原始域中的归一化。相反, 论文发现仅进行通道级缩放以权衡每个频率分量的贡献就足够了。
The Benefits of Using WTConv
在给定的卷积神经网络(CNN)中结合小波卷积(WTConv)有两个主要的技术优势。
- 小波变换的每一级都会增加层的感受野大小, 同时仅小幅增加可训练参数的数量。也就是说, WT 的 级级联频率分解, 加上每个级别的固定大小卷积核 , 使得参数的数量在级别数量上呈线性增长 , 而感受野则呈指数级增长 。
- 小波卷积(WTConv)层的构建旨在比标准卷积更好地捕捉低频。这是因为对输入的低频进行重复的小波分解能够强调它们并增加层的相应响应。通过对多频率输入使用紧凑的卷积核,WTConv层将额外的参数放置在最需要的地方。
除了在标准基准上取得更好的结果,这些技术优势还转化为网络在以下方面的改进:与大卷积核方法相比的可扩展性、对于损坏和分布变化的鲁棒性,以及对形状的响应比对纹理的响应更强。
Computational Cost
深度卷积在浮点运算(FLOPs)方面的计算成本为:
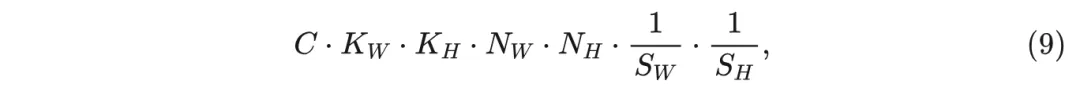
编辑
其中 为输入通道数, 为输入的空间维度, 为卷积核大小, 为每个维度的步幅。例如,考虑一个空间维度为 的单通道输入。使用大小为 的卷积核进行卷积运算会产生 FLOPs,而使用大小为 的卷积核则会产生 FLOPs 。考虑 WTConv 的卷积集, 尽管通道数是原始输入的四倍, 每个小波域卷积在空间维度上减少了一个因子 2, FLOP 计数为:
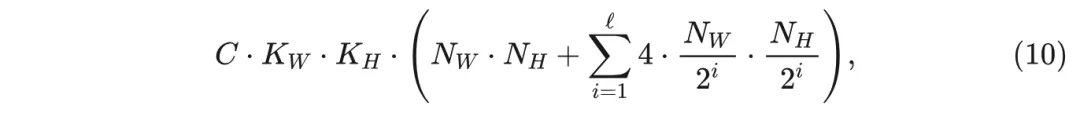
编辑
其中 是 WT 层级的数量。继续之前输入大小为 的例子, 对一个 3 层 WTConv 使用大小为 的多频卷积(其感受野为 )会产生 FLOP 。当然, 还需要添加 WT 计算本身的成本。当使用 Haar 基底时, WT 可以以非常高效的方式实现。也就是说, 如果使用标准卷积操作的简单实现, WT 的 FLOP 计数为:
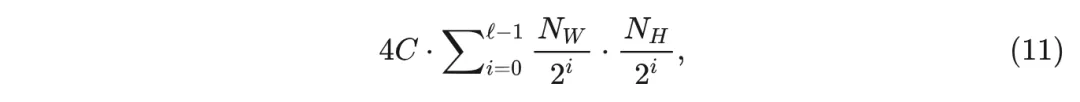
编辑
因为这四个卷积核的大小为 , 在每个空间维度上的步幅为 2 , 并且作用于每个输入通道。同样, 类似的分析表明, IWT 的 FLOP 计数与 WT 相同。继续这个例子, 3 层 WT 和 IWT 的额外成本为 FLOPs, 总计为 FLOPs, 这仍然在相似感受野的标准深度卷积中有显著的节省。
Results

编辑
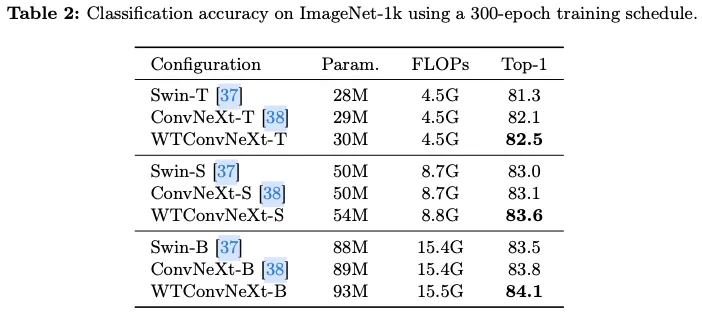
编辑
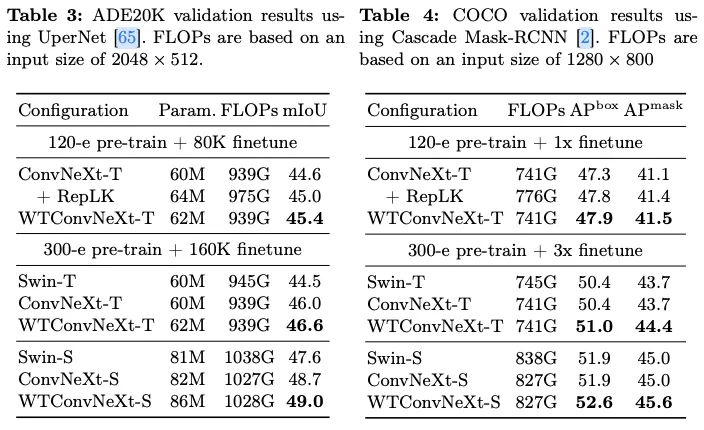
编辑
#多模态模型(VLM)部署方法
去年年初LLM刚起步的时候,大模型的部署方案还不是很成熟,如今仅仅过了一年多,LLM部署方案已经遍地都是了。
而多模态模型相比大语言模型来说,发展的还没有很“特别”成熟,不过由于两者结构很相似,LLMs的经验还是可以很好地利用到VLMs中。
本篇文章中提到的多模态指的是视觉多模态,即VLM(Vision Language Models)。
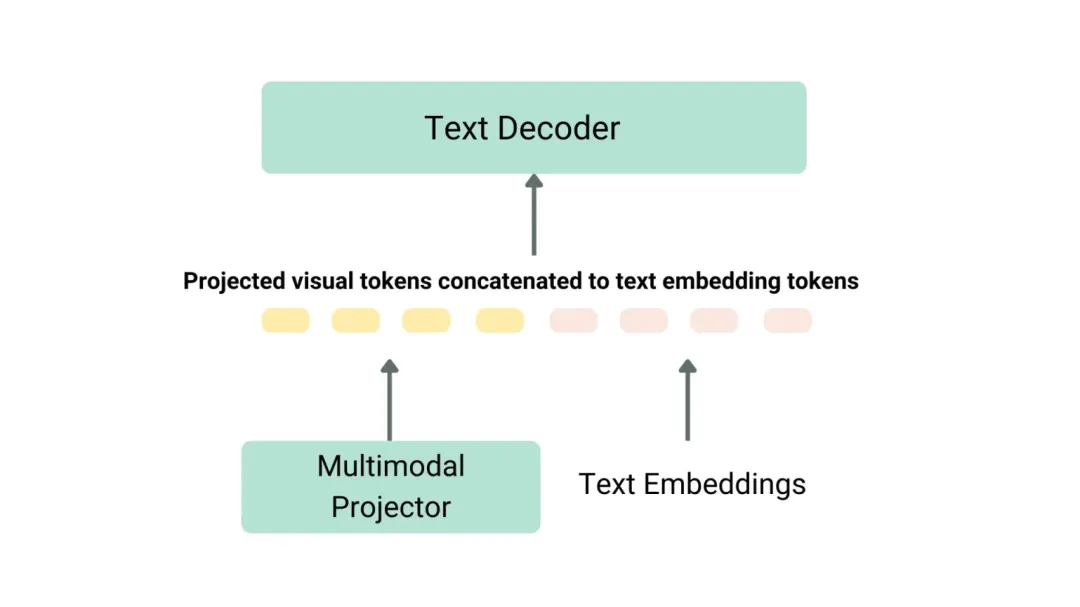
以下用一张图展示下简单多模态模型的运行流程:
- Text Embeddings即文本输入,就是常见LLM中的输入;
- 而Multomode projector则是多模态模型额外一个模态的输入,这里指的是视觉输入信息,当然是转换维度之后的;
将这个转换维度之后的视觉特征和Text Embeddings执行concat操作合并起来,输入decoder中(例如llama)就完成推理流程了;
Multomode projector负责将原始的图像特征转换下维度,输出转换后的图像特征;所以有个中文叫投射层,这个名字有点抽象,理解就行,其实就是个mlp层,转换下视觉特征的维度
编辑
多模态运作流程 from https://huggingface.co/blog/zh/vlms
引入VLM
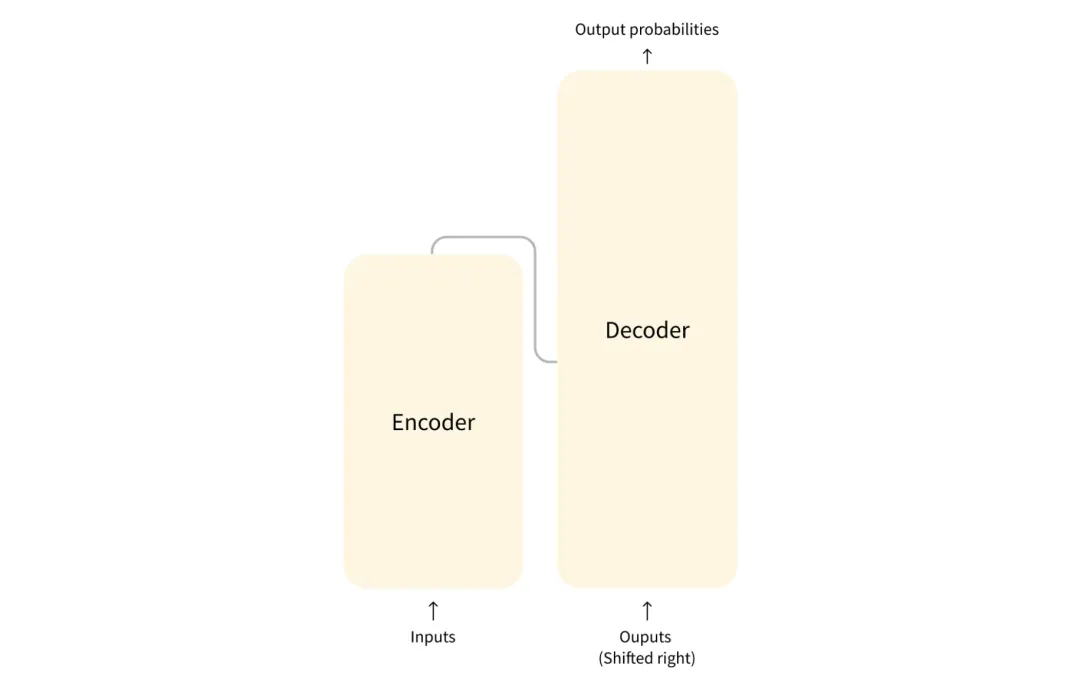
VLM就是视觉encoder加上语言decoder,这么说可能有点抽象,我们先简单回顾下transformer的基本结构:
编辑
from huggingface
由编码器和解码器组成,最开始的transformer主要是处理机器翻译任务,结构是encoder+decoder。除了这个结构,还有一些其他结构适用于各种任务,比如
- Encoder-only models:适用于需要理解输入的任务,例如句子分类和命名实体识别。
- Decoder-only models:适用于生成性任务,如文本生成。
- Encoder-decoder models or sequence-to-sequence models:适用于需要输入的生成性任务,例如翻译或摘要。
我们常见的llama属于Decoder-only models,只有decoder层;bert属于encoder-only;T5属于encoder-decoder。llama不多说了,BERT 是一种仅包含编码器的模型,它通过学习双向的上下文来更好地理解语言的深层含义。
BERT 通常用于理解任务,如情感分析、命名实体识别、问题回答等。T5 模型包括编码器和解码器,适用于同时需要理解和生成语言的任务。T5 被设计来处理各种“文本到文本”的任务,比如机器翻译、文摘生成、文本分类等。这种结构允许模型首先通过编码器理解输入文本,然后通过解码器生成相应的输出文本。基础知识就过到这里,我们先说enc-dec结构。
Encoder-Decoder (Enc-Dec)
注意,Enc-Dec模型需要区别于多模态模型,目前TensorRT-LLM官方支持的enc-dec模型如下:
- T5[1]
- T5v1.1[2] and Flan-T5[3]
- mT5[4]
- BART[5]
- mBART[6]
- FairSeq NMT[7]
- ByT5[8]
第一个就是T5也就是上述提到的编码器+解码器结构。需要注意这些模型都是基于Transformer架构的自然语言处理(NLP)模型,区别于多模态模型,这些模型主要是处理文本,算是单模态。
VLM or multimodal
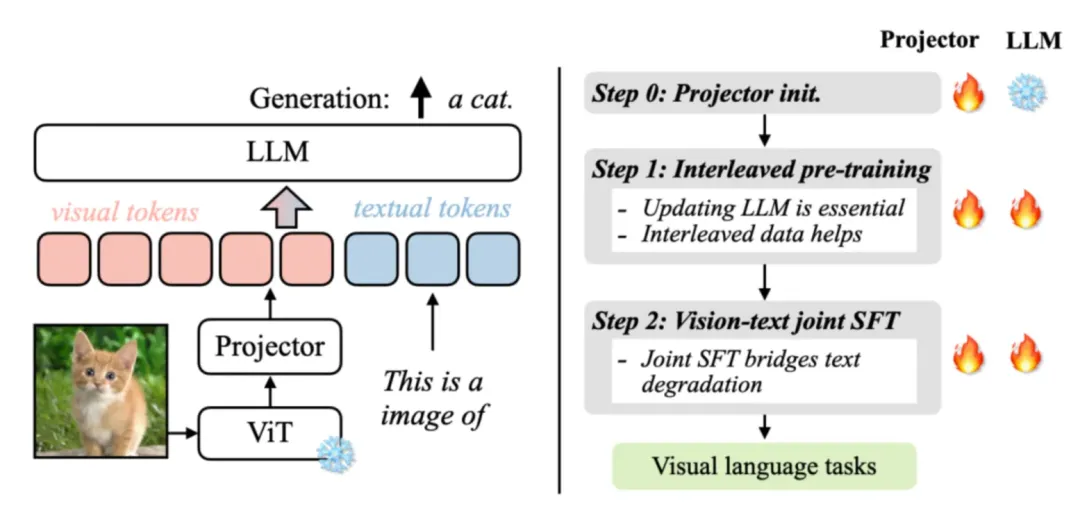
而多模态除了本文,就带上了图像:
编辑
VILA架构和训练流程
VILA[9]是nvidia推出的一个视觉语言模型,上图很清楚地介绍了其推理和训练流程。我知道的一些多模态模型有(这些模型来自lmdeploy官方github介绍):
- LLaVA(1.5,1.6) (7B-34B)
- InternLM-XComposer2 (7B, 4khd-7B)
- QWen-VL (7B)
- DeepSeek-VL (7B)
- InternVL-Chat (v1.1-v1.5)
- MiniGeminiLlama (7B)
- CogVLM-Chat (17B)
- CogVLM2-Chat (19B)
- MiniCPM-Llama3-V-2_5
这里我只简单介绍下llava,毕竟llava是较早的做多模态的模型,之后很多多模态的架构和llava基本都差不多。剩下的多模态模型大家可以自行查阅,结构基本都类似。
LLAVA
LLaVA(2304)[10]作为VLMs的代表性工作,号称只需要几个小时的训练,即可让一个LLM转变为VLM:
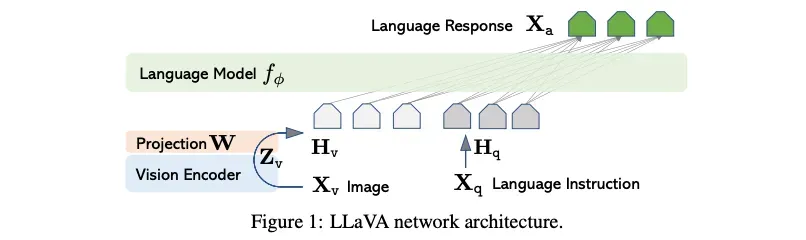
编辑
image
训练方式比较简单,主要操作是将视觉图像视作一种“外语”(相比于之前纯nlp,图像可以当做额外输入的外语),利用vision-encoder和projection[11]将“图像翻译成文本信号”,并微调LLM从而可以适应图像任务,我们简单看下其推理代码:
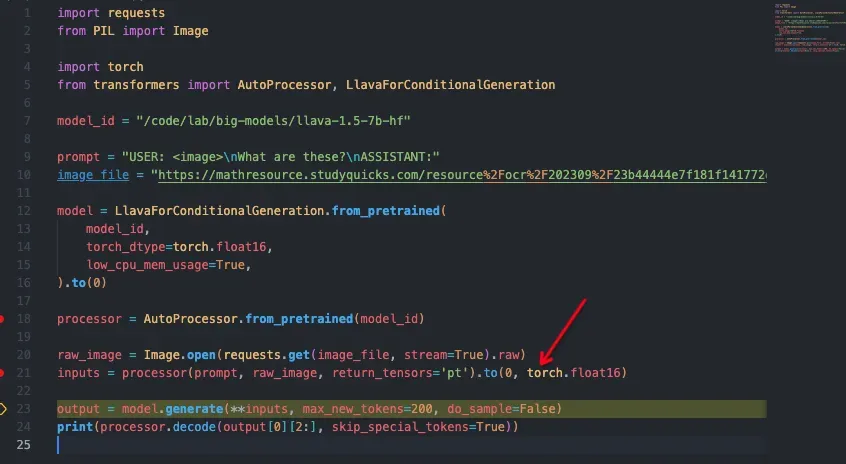
编辑
llava的整体运行过程
其中processor就是图像预处理,处理后得到的input为:inputs.pixel_values,其shape是torch.Size([1, 3, 336, 336])。然后进入generate阶段:
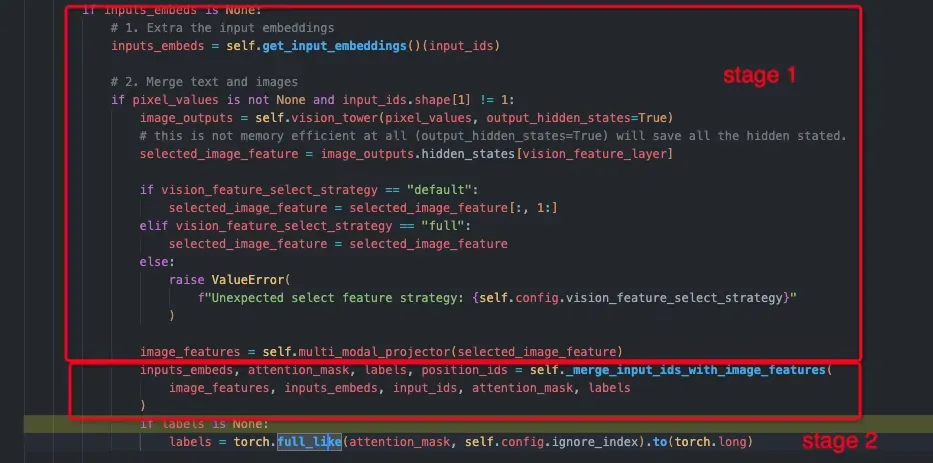
编辑
image
第一步(stage-1)是执行encoder部分:
- input_ids(torch.Size([1, 17])) -> input_embeds(torch.Size([1, 17, 4096]))
- pixel_values(torch.Size([1, 3, 336, 336]))经过视觉模型 输出视觉特征(torch.Size([1, 576, 1024]))
- 视觉特征经过投影层(mlp)输出最终的图像特征(torch.Size([1, 576, 4096]))
第二步(stage-2)是执行文字embed和图像embed合并过程,也就是合并inputs_embeds + image_features,最终得到的inputs_embeds维度为torch.Size([1, 592, 4096]),具体在llava中是pre_prompt + image + post_prompt一起输入进来,其中image的特征替换prompt中的标记,对应的token id为32000。
而这个_merge_input_ids_with_image_features函数的作用主要是将image_features和inputs_embeds合并起来:在合并完两者之后,其余部分就和普通的decoder基本一致了。整体运行流程如下:
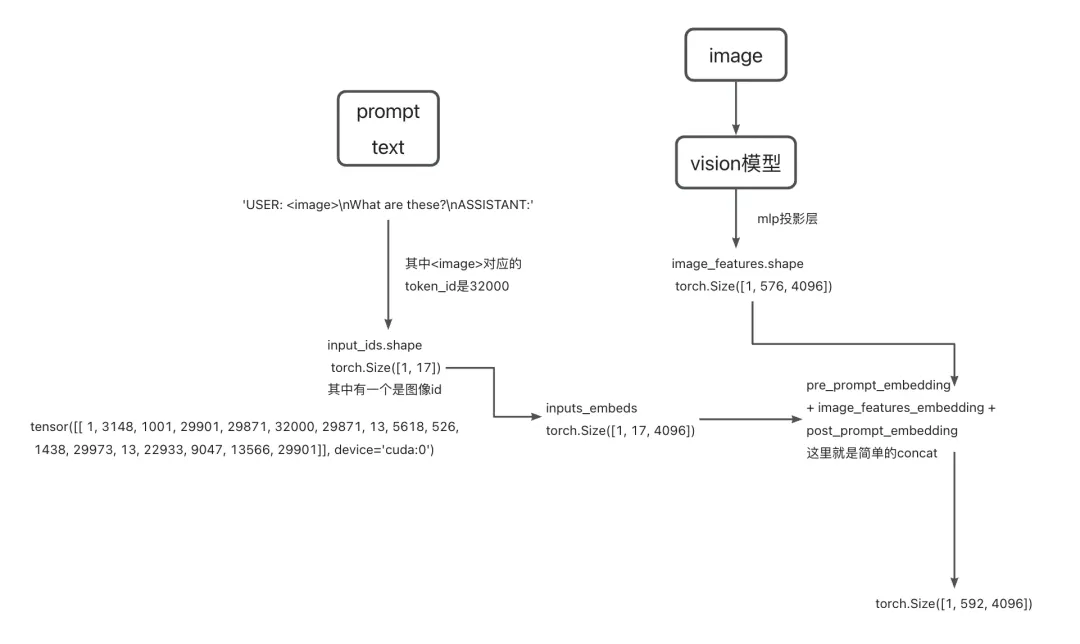
编辑
其他多模态模型拼输入的方式和llava类似,比如InternVLChat[12],输入的prompt是这样的:
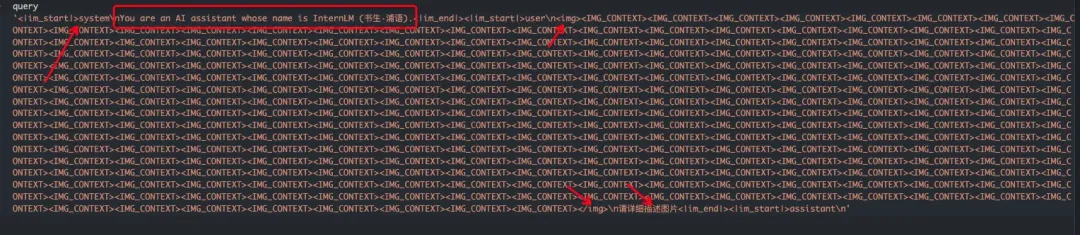
编辑
image
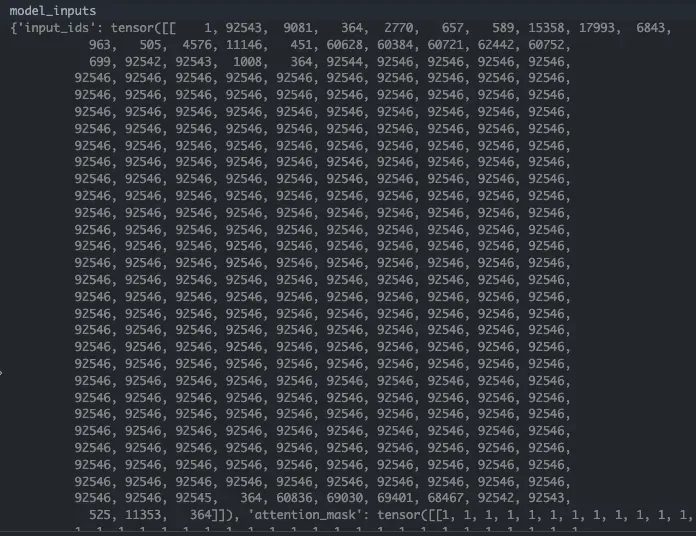
转换为token_ids如下,其图像特征占位,img_context_token_id是92546:
编辑
image
上述prompt中的<IMG_CONTEXT>之后会被实际的图像特征填上,目前只是占个位子。运行过程中的维度变化:
- pixel_values.shape torch.Size([1, 3, 224, 224]) -> vision model -> torch.Size([1, 64, 2048])
- input_ids torch.Size([1, 293]) -> language model embed -> torch.Size([1, 293, 2048])
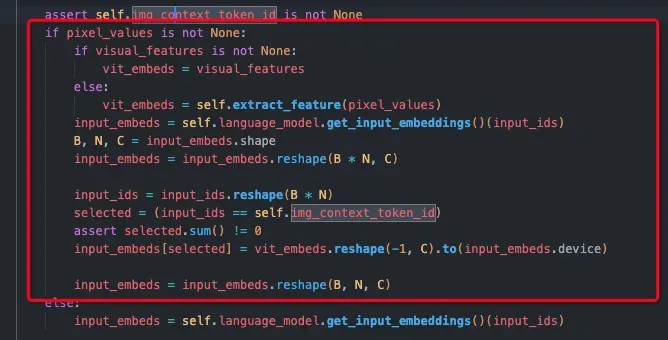
核心代码如下,需要注意这里是先占位再填(input_embeds[selected]=...)的形式,不是llava中concat的形式,最终实现效果是一样的。
编辑
image
最终也是将合并后的embeds送入language-decoder中。
包含cross-attention的多模态
上述介绍的多模态模型都是文本输入和图像输入转换为embeds合并后,输入language decoder中,这个decoder可以是常见的decoder-only models,比如llama。
还有些特殊的多模态模型的decoder部分会有cross-attention结构,比如meta推出的nougat[13]。其视觉特征不会和input_ids合并,而是单独输入decoder,在decoder中和文本特征进行cross attention:
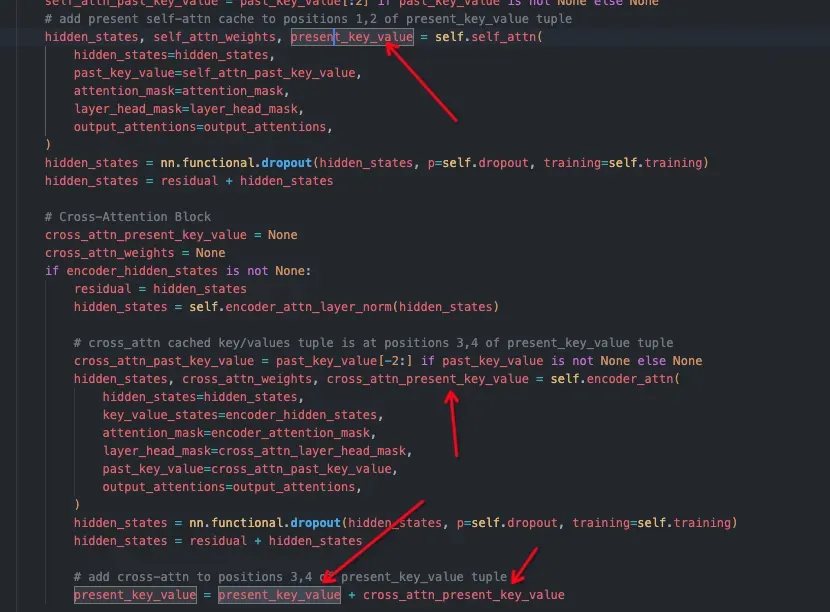
编辑
这种结构相对稍微复杂一些。
部署方案
部署方案的话,我们参考主流开源(TensorRT-LLM不完全开源)框架来窥探下。虽然一些大厂有自己的LLM部署方案,不过技术其实也多是“借鉴”,大同小异。这几个LLM框架应该是用的比较多的:
- TensorRT-LLM
- vLLM
- lmdeploy
目前这三个框架都支持VLM模型,只不过支持程度不同,我们先看trt-llm。
TensorRT-LLM
trt-llm中多模态部分在Multimodal示例中,如果是跑demo或者实际中使用trt-llm的python session跑的话,直接看官方的example即可:
编辑
如果我们更进一步,想要部署在生产环境,也是可以搞的。如果我们想要使用triton inference server部署的话,TensorRT-LLM对多模态模型的支持限于将cv-encoder和decoder分离开,搞成两个模型服务。
即通过ensemble或者tensorrt_llm_bls(python backend)的方式串起来,整体运行流程和在普通模型中是一致的(先输入image和text,然后两者经过tokenizer转换为token id,最终拼接和encoder输出特征图一并传入decoder中)。
视觉端
视觉端模型转换和普通CV模型一致,可以通过onnx的方式或者直接通过trt-python-api搭建。
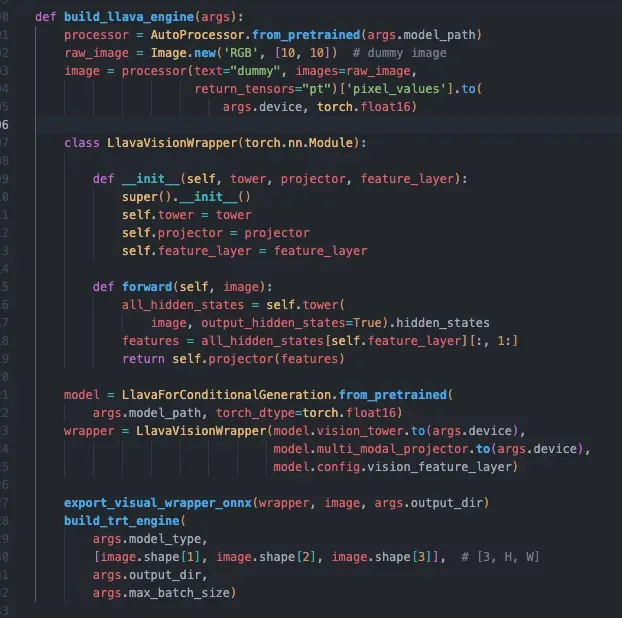
以llava举例子,在TensorRT-LLM中,首先把视觉模型(encoder)使用Wrapper类套一层,其中:
-
self.vision_tower是视觉模型, -
multi_modal_projector是投影层,将特征维度转换为和input_embeds相匹配的维度:
编辑
转换好之后,模型信息如下:
[I] ==== TensorRT Engine ====
Name: Unnamed Network 0 | Explicit Batch Engine
---- 1 Engine Input(s) ----
{input [dtype=float16, shape=(-1, 3, 336, 336)]}
---- 1 Engine Output(s) ----
{output [dtype=float16, shape=(-1, 576, 4096)]}
---- Memory ----
Device Memory: 56644608 bytes
---- 1 Profile(s) (2 Tensor(s) Each) ----
- Profile: 0
Tensor: input (Input), Index: 0 | Shapes: min=(1, 3, 336, 336), opt=(2, 3, 336, 336), max=(4, 3, 336, 336)
Tensor: output (Output), Index: 1 | Shape: (-1, 576, 4096)
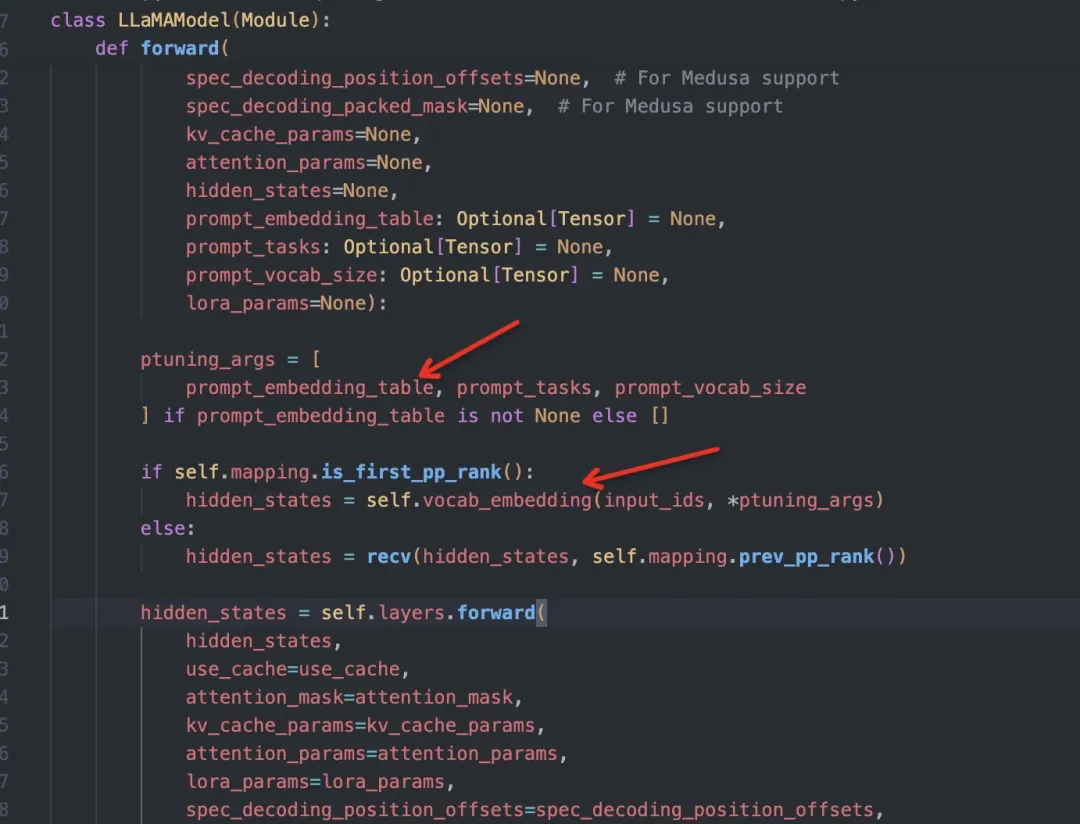
---- 398 Layer(s) ----语言端
decoder端需要额外加入一个合并input_ids 和prompt_table_data的embedding层(这里称为PromptTuningEmbedding),其余的和普通llama一致:
编辑
image
通过设置 use_prompt_tuning来确定该decoder是否需要额外的 prompt_tuning 输入:
class LLaMAModel(Module):
def __init__(self,
num_layers,
num_heads,
...# 省略参数
use_prompt_tuning: bool = False, # !!!
enable_pos_shift=False,
dense_context_fmha=False,
max_lora_rank=None):
super().__init__()
self.mapping = mapping
self.use_prompt_tuning = use_prompt_tuning
EmbeddingCls = PromptTuningEmbedding if use_prompt_tuning else Embedding其中PromptTuningEmbedding的forward代码如下,这个使用trt-python-api搭出来的layer主要作用就是将input_ids和视觉特征prompt_embedding_table进行embed并且concat,和上述一开始提到的concat流程大差不差:
# PromptTuningEmbedding
def forward(self, tokens, prompt_embedding_table, tasks, task_vocab_size):
# do not use '>=' because internally the layer works with floating points
prompt_tokens_mask = tokens > (self.vocab_size - 1)
# clip tokens in the [0, vocab_size) range
normal_tokens = where(prompt_tokens_mask, self.vocab_size - 1, tokens)
normal_embeddings = embedding(normal_tokens, self.weight.value,
self.tp_size, self.tp_group,
self.sharding_dim, self.tp_rank)
# put virtual tokens in the [0, max_prompt_vocab_size) range
prompt_tokens = where(prompt_tokens_mask, tokens - self.vocab_size, 0)
# add offsets to match the concatenated embedding tables
tasks = tasks * task_vocab_size
# tasks: [batch_size, seq_len]
# prompt_tokens: [batch_size, seq_len]
prompt_tokens = prompt_tokens + tasks
prompt_embeddings = embedding(prompt_tokens, prompt_embedding_table)
# prompt_tokens_mask: [batch_size, seq_len] -> [batch_size, seq_len, 1]
# combine the correct sources of embedding: normal/prompt
return where(unsqueeze(prompt_tokens_mask, -1), prompt_embeddings,
normal_embeddings)服务整合
服务整合其实很容易,只不过官方一开始并没有给出示例,只有在最近才在tutorial中给出实际例子:
其实我们可以很早发现tensorrt_llm/config.pbtxt中已经包含了这两个输入:
- prompt_embedding_table
- prompt_vocab_size
意味着在trt-llm的executor中包装着decoder-engine,可以接受这两个输入。而trt-llm提供的executor,在triton-trt-llm-backend去通过调用这个API实现inflight batching:

编辑
image
# inflight_batcher_llm/tensorrt_llm/config.pbtxt
{
name: 'prompt_embedding_table'
data_type: TYPE_FP16
dims: [ -1, -1 ]
optional: true
allow_ragged_batch: true
},
{
name: 'prompt_vocab_size'
data_type: TYPE_INT32
dims: [ 1 ]
reshape: { shape: [ ] }
optional: true
},而之前介绍的llava的decoder结构,则可以看到有prompt_embedding_table和prompt_vocab_size这两个输入:
[03/04/2024-03:23:39] [TRT-LLM] [I] Engine:name=Unnamed Network 0, refittable=False, num_layers=495, device_memory_size=1291851264, nb_profiles=1
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=input_ids, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=position_ids, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=prompt_embedding_table, mode=TensorIOMode.INPUT, shape=(-1, 4096), dtype=DataType.HALF, tformat=Row major linear FP16 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=tasks, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=prompt_vocab_size, mode=TensorIOMode.INPUT, shape=(1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=last_token_ids, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=kv_cache_block_offsets, mode=TensorIOMode.INPUT, shape=(-1, 2, -1), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_kv_cache_block_offsets, mode=TensorIOMode.INPUT, shape=(-1, 2, -1), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_kv_cache_pool_pointers, mode=TensorIOMode.INPUT, shape=(2,), dtype=DataType.INT64, tformat=Row major linear INT8 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=sequence_length, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_request_types, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_past_key_value_lengths, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=context_lengths, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_context_lengths, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_max_attention_window_sizes, mode=TensorIOMode.INPUT, shape=(32,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_sink_token_length, mode=TensorIOMode.INPUT, shape=(1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=cache_indirection, mode=TensorIOMode.INPUT, shape=(-1, 1, -1), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=logits, mode=TensorIOMode.OUTPUT, shape=(-1, 32064), dtype=DataType.FLOAT, tformat=Row major linear FP32 format (kLINEAR)这是普通decoder-only server中的服务文件组织:
编辑
而最终整体的目录文件,我们再多一个encoder文件夹就行,具体我们可以在preprocessing中调用encoder,然后去处理prompt合并,最终通过prompt_embedding_table和prompt_vocab_size送入tensorrt_llm中即可。
不过需要注意,trt-llm不支持cross attention这种多模态的inflight batching,因为在config.pbtxt没有暴露出相关的接口,cross attention这种多模态不需要prompt_embedding_table和prompt_vocab_size,而是需要类似于encoder_output这种原始的图像特征输入,以下是官方nougat模型decoder部分转为trt的结构:
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=input_ids, mode=TensorIOMode.INPUT, shape=(-1, 1), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=position_ids, mode=TensorIOMode.INPUT, shape=(-1, 1), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=encoder_input_lengths, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=encoder_max_input_length, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=encoder_output, mode=TensorIOMode.INPUT, shape=(-1, -1, 1024), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=host_past_key_value_lengths, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=sequence_length, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=context_lengths, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=host_request_types, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=last_token_ids, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cache_indirection, mode=TensorIOMode.INPUT, shape=(-1, 1, -1), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=host_max_attention_window_sizes, mode=TensorIOMode.INPUT, shape=(10,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=host_sink_token_length, mode=TensorIOMode.INPUT, shape=(1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_0, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_0, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_1, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_1, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_2, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_2, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_3, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_3, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_4, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_4, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_5, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_5, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_6, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_6, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_7, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_7, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_8, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_8, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_9, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_9, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_kv_cache_gen, mode=TensorIOMode.INPUT, shape=(1,), dtype=DataType.BOOL, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_0, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_0, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_1, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_1, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_2, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_2, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_3, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_3, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_4, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_4, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_5, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_5, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_6, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_6, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_7, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_7, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_8, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_8, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_9, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_9, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=logits, mode=TensorIOMode.OUTPUT, shape=(-1, 50000), dtype=DataType.FLOAT, tformat=Row major linear FP32 format (kLINEAR)lmdeploy
lmdeploy对多模态的支持方式也在预料之中,decoder使用自家的turbomind或者pytorch engine去跑,然后cv-encoder端复用原始transformers库中的代码去跑,整理流程和trt-llm中的相似。
vLLM
vllm对多模态模型的支持尚可,官方展示的不是很多,但实际上支持了不少(https://github.com/vllm-project/vllm/issues/4194[15]);而且鉴于vllm的易接入性,自己增加模型还是比较简单的:

编辑
image
另外,vLLM近期也在修改相关VLM的架构,正在进行重构[16],以及vllm对vlm的一些后续优化:
- Make VLMs work with chunked prefill
- Unify tokenizer & multi-modal processor (so that we can leverage AutoProcessor from transformers)
- Prefix caching for images
- Streaming inputs of multi-modal data
简单测试了llava,测试性能在同样fp16的情况下性能不如trt-llm,原因表现可以参考在llama上的对比。
优化点TODO
优化点其实有很多,不过占大头的就是量化[17]。
量化
因为多模态的decoder部分就是普通的decode模型,我们可以复用现有的成熟的量化技术量化decoder部分就可以拿到很大的收益。整个pipeline当中视觉encoder部分的耗时占比一般都很小5%左右,
encoder部分可以按照我们平常的小模型的方式去优化即可,量化也可以上。需要注意的就是量化方法,大模型量化方法很多,需要选对。
The AWQ quantization algorithm is suitable for multi-modal applications since AWQ does not require backpropagation or reconstruction, while GPTQ does. Thus, it has better generalization ability to new modalities and does not overfit to a specific calibration set. We only quantized the language part of the model as it dominates the model size and inference latency. The visual part takes less than 4% of the latency. AWQ outperforms existing methods (RTN, GPTQ) under zero-shot and various few-shot settings, demonstrating the generality of different modalities and in-context learning workloads.
Runtime
还有cv-encoder需要和decoder最好放到一个runtime当中,要不然会有一些冗余的显存拷贝,不过这部分对吞吐影响不大,主要是latency。trt-llm中对enc-dec结构已经做了这样的优化,在trt-llm-0607版本中将这俩放到了同一个runtime中,这里指的是Executor,可以看到多出了一个encoder的model path:
编辑
可以看到triton-llm-backend中多了一个encoder_model_path的输入,这里将encoder和decoder放到同一个runtime中了:

编辑
还有一些其他的优化空间,这里暂时不谈了,后续有新的结论了再补充。
这里的讨论还不是很全很细,算是抛砖引玉,之后有更新也会再发篇文章单独介绍。各位读者如果有比较好的方法或者建议也欢迎留言,我们一起讨论。
参考
- https://github.com/triton-inference-server/tutorials/pull/100[18]
- https://huggingface.co/blog/vlms[19]
- https://github.com/InternLM/lmdeploy/issues/1309[20]
- https://developer.nvidia.com/blog/visual-language-intelligence-and-edge-ai-2-0/[21]
参考资料
[1]
T5: https://huggingface.co/docs/transformers/main/en/model_doc/t5
[2]T5v1.1: https://huggingface.co/docs/transformers/model_doc/t5v1.1
[3]Flan-T5: https://huggingface.co/docs/transformers/model_doc/flan-t5
[4]mT5: https://huggingface.co/docs/transformers/model_doc/mt5
[5]BART: https://huggingface.co/docs/transformers/model_doc/bart
[6]mBART: https://huggingface.co/docs/transformers/model_doc/mbart
[7]FairSeq NMT: https://pytorch.org/hub/pytorch_fairseq_translation/
[8]ByT5: https://huggingface.co/docs/transformers/main/en/model_doc/byt5
[9]VILA: https://developer.nvidia.com/blog/visual-language-models-on-nvidia-hardware-with-vila/
[10]LLaVA(2304): https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2304.08485
[12]InternVLChat: https://huggingface.co/OpenGVLab/InternVL-Chat-V1-5
[13]nougat: https://github.com/facebookresearch/nougat
[14]https://github.com/triton-inference-server/tutorials/blob/main/Popular_Models_Guide/Llava1.5/llava_trtllm_guide.md: https://github.com/triton-inference-server/tutorials/blob/main/Popular_Models_Guide/Llava1.5/llava_trtllm_guide.md
[15]https://github.com/vllm-project/vllm/issues/4194: https://github.com/vllm-project/vllm/issues/4194
[16]重构: https://github.com/vllm-project/vllm/issues/4194
[17]量化: https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/reference/precision.md
[18]https://github.com/triton-inference-server/tutorials/pull/100: https://github.com/triton-inference-server/tutorials/pull/100
[19]https://huggingface.co/blog/vlms: https://huggingface.co/blog/vlms
[20]https://github.com/InternLM/lmdeploy/issues/1309: https://github.com/InternLM/lmdeploy/issues/1309
#从图形计算到世界模型
近日,北京大学陈宝权教授在第九届计算机图形学与混合现实研讨会(GAMES 2024)上,发表了题为《从图形计算到世界模型》的主旨报告,分享了他从图形仿真角度对世界模型的思考。本文是对陈教授报告的完整整理,以供大家学习。
世界模型是当前的热点话题。我这里分享的题目是 “图形计算到世界模型”,作为抛砖引玉,试图挖掘和展示图形计算和世界模型两者之间可能建立的紧密内在联系。
GAMES 这个平台上的报告,主要是为了交流,鼓励大胆提出想法,引发讨论,而不是单纯的宣读一些既有成果。所以,我为此做了一些调研和思考,期待通过这个报告,能激发更多关于图形计算如何助力构建更精准世界模型的深入讨论。

编辑
近年来,AIGC 领域的大模型技术取得了迅猛的发展,引发了广泛的关注与讨论。当观察到仅通过简单的文字输入,这些模型便能生成连贯且有逻辑的场景时,一个自然而然的问题浮现:这些模型背后是否隐藏着一个世界模型?这一疑问直指 AI 技术的核心,激发了业界对于模型内部机制与能力的深入探索。
编辑
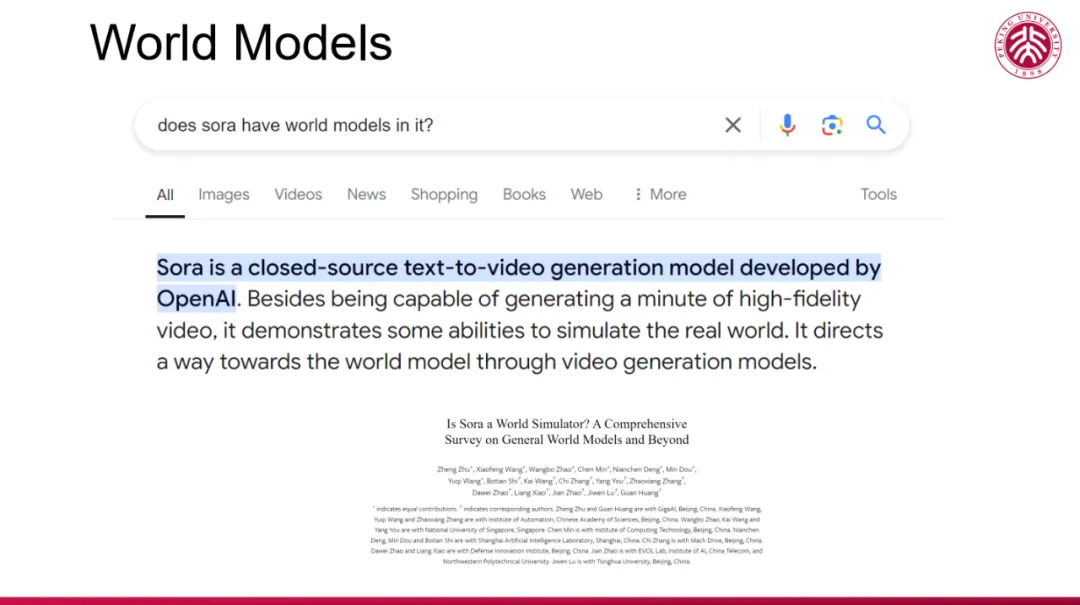
首先,我通过 Google 进行了搜索,“Sora 是否具有世界模型”。搜索结果显示,Sora 具备了一定的模拟真实世界的能力,通过视频生成模型来体现。该搜索还关联到一篇相关文章,文章作者中有坐在台下的 Jiwen 老师。这篇文章通过对一系列生成模型的综述和分析,展示了 Sora 等模型内部融入了视觉模型的元素,支持了该类模型包含世界模型特征的观点。

编辑
退回一步,何谓 “世界模型”?其实,当前学术届和产业界对于世界模型缺乏一个统一且严格的界定。回顾过往,LSTM 的先驱 Schmidhuber 及其学生曾在其论文中探讨过世界模型,他们并未直接给出世界模型的明确结构,而是从功能角度进行了阐述。他们认为,世界模型的核心在于其预测(prediction)与规划决策(planning)的能力。换言之,若一模型能够基于当前信息预测未来状态,并据此做出合理规划与决策,那么它便被视为具备世界模型的特征。这一定义虽非严谨的结构性描述,却从实用功能角度出发,为我们理解世界模型提供了有益视角。

编辑
Yann LeCun 作为人工智能领域内的重要人物,也曾从现象层面深入剖析世界模型的概念。尽管这一阐述也未提供严格定义,但他认为世界模型所涵盖的关键能力,如预测、推理、决策及规划等,与我们先前讨论的内容高度契合。值得瞩目的是,LeCun 的论述将世界模型的功能同人类大脑类比,通过图示形象地展示了这一理念。
从 GPT-4o 的回答中,我们也可以看到类似的观点:世界模型被描述为一种能够进行模拟、预测、规划和决策的系统。这种系统通过学习和理解大量的数据,构建出对现实世界的内部表示,从而能够模拟不同情境下的可能结果,并据此做出最优的决策。
编辑
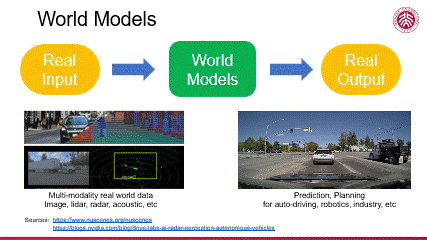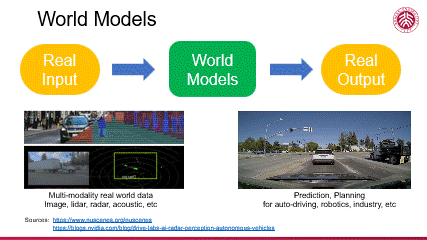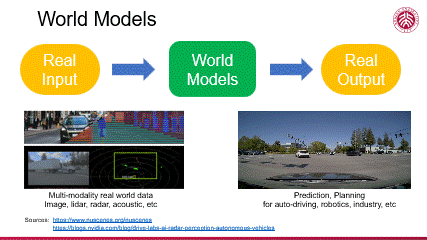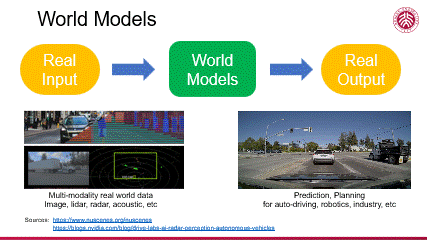
综上所述,我们可以通过构建一个最简单的示意图来直观理解世界模型。我们以真实场景作为输入,通过一个有理解、分析、模拟、评价等能力的世界模型,最终实现在该输入条件下符合真实场景的未来预测及决策推理。这样的世界模型体现了人工智能技术在处理复杂信息方面的能力,也预示了其在多个应用场景中的巨大潜力。
当前,众多大型 AI 模型已展现出在复杂场景应用中的卓越能力,特别是在无人驾驶领域,其成熟度尤为显著。底下左边,一个面向无人驾驶的高逼真仿真系统通过模拟多种传感器(如激光雷达、摄像头、声音传感器等)产生丰富的多模态数据,由此构建出一个庞大的数据集用于大模型训练。底下右边,该模型在新的场景下实现了对环境的精准感知,并由此做场景的动态预测,进行判断决策,完成自动驾驶任务。在这方面有许多著名的尝试,比如 nuScenes 这样的项目,它在数据丰富性和多模态性方面超越了传统的 KITTI 数据集,为模型提供了更为全面的学习素材。同时,英伟达等科技巨头也在无人驾驶场景的仿真模拟(simulation)方面投入了大量资源,推动了该技术的快速发展与应用。
可见在自动驾驶等领域,人工智能技术已展现出从真实场景输入到符合真实场景输出的从感知到决策的全链条能力,标志着这一技术正逐步迈向成熟,在现实中的应用会快速推广开来。
编辑
接下来,我想针对如何构建更加完备的世界模型这一宏大命题,探讨一下可能的实现路径。尽管语言、图片和视频大模型已展现出强大的能力,但这仅是建立世界模型征途的起点。大模型依托 scaling law,通过海量数据 “喂养” 取得了显著成效,但我们能产生的数据的边界远未被触及,可能的训练模式也远不止当前这些。
我将从几个核心维度展开阐述:数据丰富性、训练模式、监督机制的增强,以及这些要素最终有机融合,共同推动世界模型的构建。在这一过程中有一个中心词就是 simulation,它占据了举足轻重的地位。图形计算的核心目标就是模拟一个真实的世界,所以我将把它等同于 simulation。这样的 simulation 在模拟真实世界、更有效地训练模型,加速模型迭代与验证方面展现出非凡的价值。

编辑
首先,我们看看现有大模型训练的基本规律和其局限。
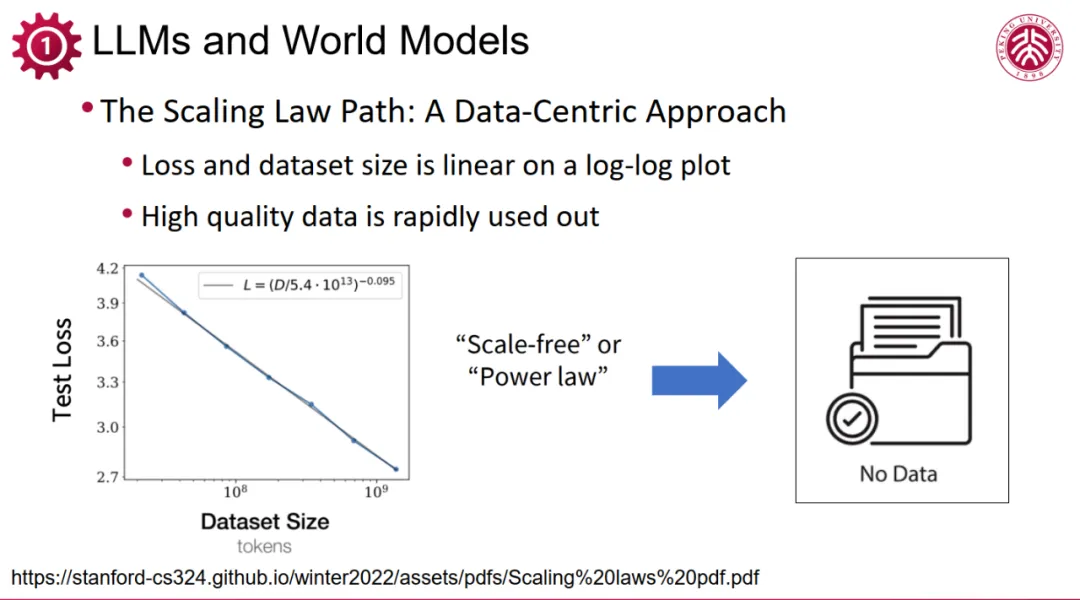
编辑
在大模型训练的过程中,一个关键观察是数据量与模型损失(loss)降低之间的关系。尽管常有人以线性关系简化描述,但实际上,这种关系更接近对数 (Log) 关系,这暗示了模型对数据需求的指数级增长特性。事实是,随着模型训练深入,对数据量的要求急剧增加,以至于数据资源在迅速耗尽。这一现象在涉及更高维度(如三维及以上)的数据处理时尤为显著,进一步凸显了高效数据利用与扩展数据源的紧迫性。

编辑
在二维领域,对数据的需求已展现出庞大的规模,如德国开源项目 LAION 所展现的 5PB 数据量,尽管其后续版本 Re-LAION 经过清洗后重新发布,但数据量依然可观。然而,当我们转向三维数据领域时,情况则大为窘迫。从早期的 ShapeNet 到近期的 ObjectVerse 及其扩展版 ObjectVerse-XL,三维数据集的量级仅为数十兆,与二维数据相比,显然不在一个数量级上。这凸显了三维数据的极度稀缺性,是当前人工智能与计算机视觉领域面临的一大挑战。

编辑
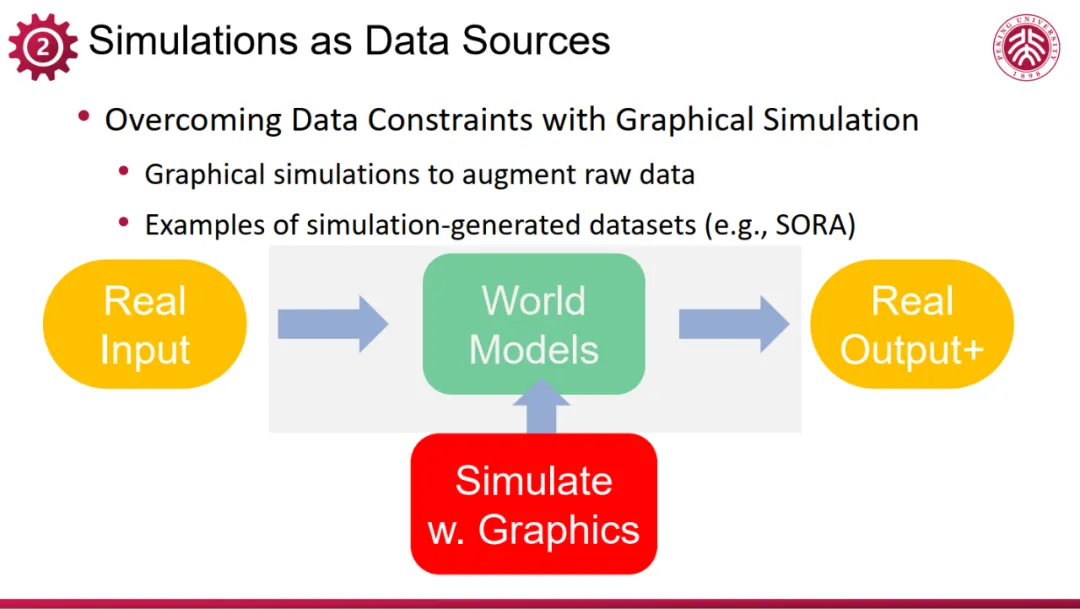
在这一背景下,simulation(模拟)的重要性日益凸显。鉴于数据的有限性,如何系统性地生成更多高质量、带标签的数据成为关键。simulation 正是这一需求的强大解决方案。如今,计算机图形技术已远非仅限于特效制作和图像编辑,其核心实力在于模拟现实世界,构建的 simulation 系统可以生成海量数据,这不仅能够扩展数据集规模,还能提供丰富的标签和可控性,确保数据的多样性、合规性、约束其符合伦理道德标准,这样的数据增广为大模型的训练提供有力支持。

编辑
编辑
利用 simulaiton 来生成数据已经有许多成功的初步探索,如 UCSD 苏昊团队早期的针对图像姿态估计等任务的研究。这一工作的基础是采用有 pose 信息标注的图像作为训练数据的卷积神经网络(CNN),而真实世界中的图像中,有 pose 标注的是非常有限的,远不足以训练一个有效的模型。苏昊团队就利用了 ShapeNet 等三维数据集,通过三维渲染生成了大量包含姿态信息的图象数据,为 CNN 的学习提供了丰富的训练样本,而训练得到的模型,应用在真实世界无标注的图片上,也能够良好的泛化,得出有效的 pose 估计。这种数据生成方法有效弥补了现实世界数据标注稀缺的问题。
随后,基于这些三维数据,苏昊团队以及其他研究者们还开发了更为复杂的场景交互功能(interaction),如柜门开启、物体抓取等,旨在模拟真实世界中的物体交互,为机器人训练等应用提供更为贴近实际的数据支持。由此可见,图形计算提供的 simulation 能力已成为产生高质量、带标签、有功能的多样化训练数据不可或缺的重要手段。
编辑
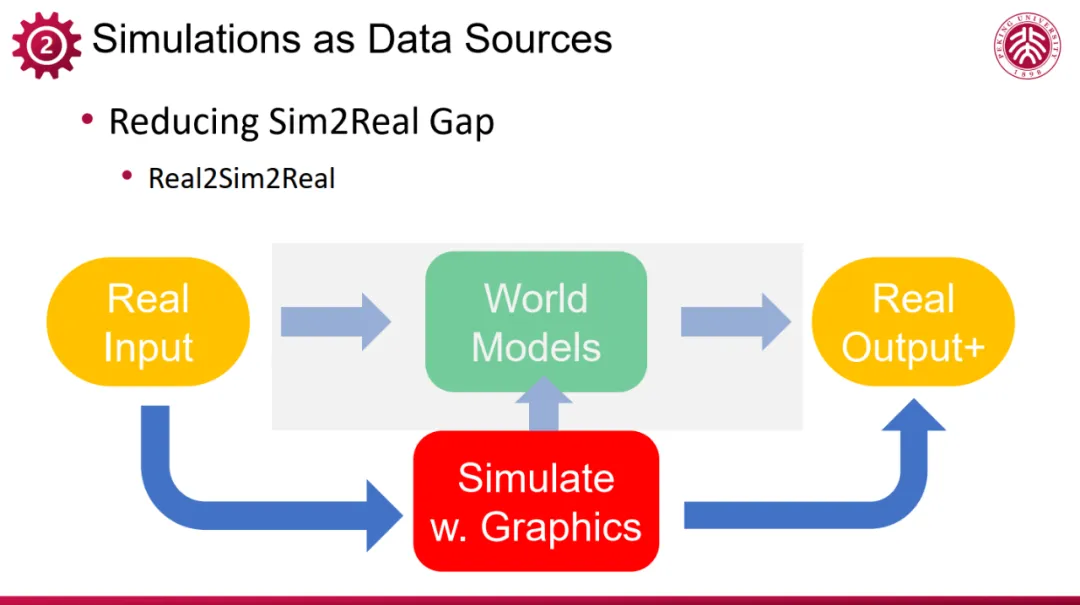
但我们也都知道,模拟仿真(Sim)与真实现象(Real )之间还存在差距,这是由数据的生成方式所决定的。那么为了生成更贴近现实世界的数据,在具身智能等智能应用中,我们需要采用 “real to sim” 与 “sim to real” 的策略。前者指从真实世界获取原始传感数据,用于构建相对应的仿真环境,比如说我们以香港科技大学广州校区(港科广)的校区作为目标对象,那么可以基于港科广的真实传感器数据重建其数字化表达,如果有动态场景,就建立与之对应的动态仿真,这就是 real to sim;一旦从 real 建立 sim,我们就可以通过改变模拟参数,来模拟出更丰富的场景,比如说新视点观察,场景重构和功能组合等。Simulation 是基于真实世界原理的,它具备很强的真实感,不只是在表象上(appearance),还包括它的动态(dynamics)和交互(interaction)等等,因此,基于图形计算的仿真能做到尽可能真实(as-real-as-possible),实现 “sim to real”。
但是,尽管 “sim to real” 努力使模拟接近真实,但完全消除两者之间的差距仍是一个挑战。因此,在部署阶段,往往还需进行 “real to real” 的微调,即在真实环境中采集输入输出数据来训练大模型,进一步调整和优化系统性能,弥合 sim 和 real 之间的差异。
对于复杂应用场景,Real2Real 的数据非常有限,完全依靠这类数据来实现具身智能是不够的。通过结合真实数据进行模拟仿真,然后高逼真生成仿真数据,扩展真实数据的边界,这样的 Real2Sim2Real 框架成为推动具身智能发展的重要途径。

编辑
在无人驾驶等工业界推进迅速的领域内,“现实到模拟”(real-to-sim)与 “模拟到现实”(sim-to-real)的双向转换上已经取得了显著成效。比如我们展示的这些例子,当然还有更多。但若仅将模拟技术局限于数据生成层面,是对 Simulation 潜力的一种低估,被大材小用了。

编辑
事实上,图形仿真不再仅仅局限于数据提供者的角色,而是成为了一个训练环境的构建者。通过强化学习等先进技术,图形仿真能够直接为训练过程提供环境支持,使得智能体能够学习并优化其决策推理能力,而这正是世界模型所应该构建的能力,实现理解、预测、策略、执行等关键功能。提供训练环境这一点对于推动人工智能技术的发展具有重要意义。身为计算机图形学领域的研究人员,我深感自豪的是,图形学在现在乃至未来的人工智能发展中将占据越来越重要的位置。

编辑
在多个领域,如数字人和机器人的运动控制、无人车行为控制等,深度强化学习已成为一种高效训练方式。该方法利用模拟环境(sim)提供的丰富交互场景,通过深度强化学习算法学习背后的策略(policy),从而更有效地获得预测能力。北京大学的刘利斌老师围绕数字人体的运动控制,在结合仿真环境这个方向上发表了许多优秀工作。在这些强化学习的工作中,物理仿真环境的有效交互成功推进了这些模型的鲁棒性和泛化性。

编辑
以下是利斌研究工作的展示。这些工作从捕获人体真实的动作开始,然后通过模拟(sim)环境与深度强化学习(deep reinforcement learning)技术相结合的方式,成功学习并模拟出相当复杂的动作策略(policy),比如滑滑板、使用筷子等等。注意,模拟的精确性是非常重要的 —— 模拟越精确,学到的内容质量越高,越接近真实世界。例如,最右侧的研究中引入了肌肉(muscle)模型,超越了传统关节动画,更加贴近真实的人体运动机制。这种准确的模型可以模拟许多真实的运动细节,例如长时间奔跑后体力下降,疲劳感所带来的动作变化等等,为人工智能在人体运动模拟领域的应用提供了新的可能。

编辑
在机器人领域,许多近期的工作通过采用一些高效的仿真框架,例如英伟达的 Omniverse 平台,深入探索了仿真(simulation)技术的潜力。他们利用该平台构建了大量仿真环境,并在其中应用强化学习(reinforcement learning)技术来训练和优化机器人的行为策略(policy),从而推动了机器人技术的创新与发展。

编辑
当前,仿真环境在多个领域已展现出良好的应用前景,但现有技术往往仍局限于刚体(rigid body)模拟,还存在大量的真实现象不能支持。为了更贴近现实场景,提升仿真效果,我们必须超越刚体模拟的范畴,探索软体、流体,甚至刚体与软体融合的多物理场(multiphysics)场景。在此过程中,如何实现多物理仿真,如何提高仿真的保真度(fidelity)和性能(performance),成为图形学领域的核心挑战与使命。因此,不断推进正向仿真(forward simulation)技术的边界,增强其综合性全面性的能力和真实感,是我们当前的重要任务,也是图形学非常硬核的(hard core)研究课题。

编辑
近年来,我的实验室持续致力于软体仿真领域的技术创新与突破,以下介绍几个代表性成果。例如,我们已成功实现了大规模软体的实时变形仿真。左图中的结构可能几何形态看似简单,但它其实包含大量四面体网格,需要在准确计算形变的同时,维持软体体积不可压缩的约束,其动态的计算不仅复杂,其计算量还非常巨大,而我们基于 GPU 的方法实现了实时的解算。此外,我们还深入研究了参数化表面的连续碰撞问题,这是仿真领域长期存在的复杂问题。右侧视频中的碰撞模拟效果展现了我们准确处理复杂参数化表面碰撞的能力。诸如此类的软体动态仿真是我们当前仿真环境所急需的能力。

编辑
进一步扩展到多物理方面,我们团队在流体与固体交互领域取得了一系列具有影响力的研究成果(博士生阮良旺、幸京睿、陶凝骁)。通过精确构建液体表面张力和流固相互作用的模型,我们成功实现了单一固体或液体仿真难以达成的真实感效果,为复杂物理现象的模拟提供了新工具。

编辑
我们团队针对磁流磁软体这一特殊领域的研究一直是国际领先的,如上图所示,取得了一系列的前沿进展。我的博士生倪星宇对此领域展现出浓厚兴趣,持续深耕这个子领域,不断地推进磁场流固现象仿真的边界。其中,他今年在 Siggraph 上的工作尤为突出,该工作能够广泛适用于磁场中的流体和刚体、软体,且相较于传统技术,实现了约 100 倍的性能提升。具体而言,在处理 512 立方体数据时,我们成功将帧率提升至每秒一帧,而此前则需耗时约 100 秒才能完成一帧的渲染,这一突破极大地加速了磁流磁软体模拟的实时性。

编辑
观察现实世界中的物体及其动态现象,其复杂性与多样性令人叹为观止。因此,如何构建更加精准、全面的仿真环境,以模拟这些复杂多变的物理现象,是我们需要不断探索和努力的方向。我们在推动仿真环境的研究将丰富强化学习环境,使其真正接近于真实的、多物理的世界,进一步提升世界模型的能力,大大扩展其应用领域。

编辑
尽管仿真作为强化学习训练环境展现出巨大潜力,但强化学习在长时间尺度下仍面临奖励序列冗长、策略优化易陷入困境及收敛困难等关键问题。为解决此挑战,可微分模拟的重要性日益凸显。通过引入可微分性,我们能够实现精细化的梯度回传机制,构建起监督学习的闭环系统,从而优化策略学习过程。
此转变要求 simulation 过程全面实现可微分,以确保有效的梯度传递与策略优化。相较于传统仅提供训练环境的仿真方法,这是一个比较新的研究领域,其核心在于实现全面的可微分性,将为模型训练的发展提供新的有效途径。
编辑
可微模拟领域尽管已有初步探索,但整体而言相关研究尚不充分,近年来,可微模拟正在逐步受到领域内的重视。以下我举几个例子,介绍可微的、逆向的模拟,以及它能实现的一些有效的优化和训练。
编辑
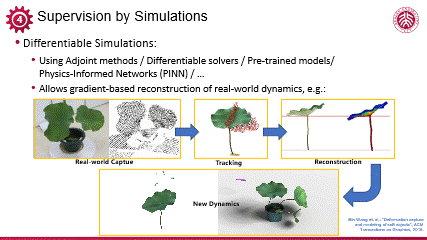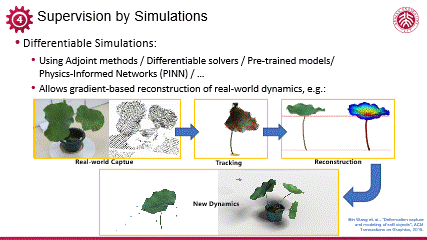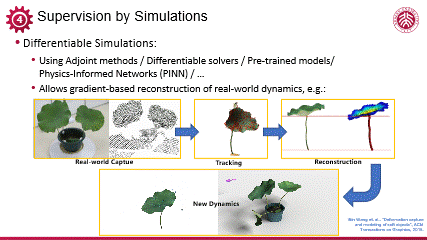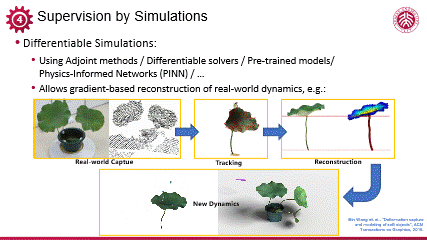
我的长期合作者王滨博士在逆向软体仿真方面做出了开创性的工作。首先,通过捕捉实际荷叶在受外力作用下的晃动,获取其动态点云数据及其表面几何变化;随后,结合物理学模型与参数,利用可微构建闭环的模拟系统,该系统首先前向模拟荷叶动态,继而通过可微优化残差,逐步拟合真实捕捉的动态数据。整个过程中,所有参数及模拟流程均实现可微分性,从而实现准确优化。一旦物理参数优化完成,我们即可准确模拟该数字化荷叶在不同条件下的动态响应,展现出强大的、与真实世界高度一致的预测能力。

编辑
这一方法论不仅限于软体,对于更变化多端的流体,我们也可以借助可微模拟来实现从真实世界的数据捕捉,到数字世界的流体物理场重建。比如这是北大楚梦渝老师的流体重建工作,它基于物理知悉网络(PINN)的可微性,实现了对真实世界流体的拟合、重建和模拟。

编辑
可微模拟技术不仅意味着我们可以拟合和重建真实世界的动态和静态数据,更在优化设计领域开辟了新路径。以下工作是我们团队的研究成果,展示了可微模拟在磁软体机器人控制中的应用(博士生陈旭雯)。磁软体机器人是一个具有磁性的,可以通过外磁场控制的软体机器人。我们的工作希望以外磁场为媒介,在现实复杂环境下,实现目标导向的控制,如爬坡、越障及穿越复杂地形等。这一过程涉及复杂的反向优化,即通过不断优化外部磁场参数,实现精准的动态调整。该优化过程高度依赖于可微模拟技术提供的实时反馈与梯度信息,外磁场在梯度的指导下灵活调整,操纵磁软体机器人应对各种挑战。
此外,可微模拟还赋予了我们设计软磁体机器人形状与物理参数的能力,为其在更广泛领域的应用提供了可能。
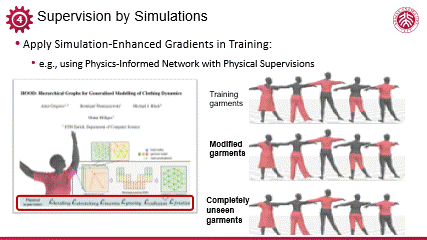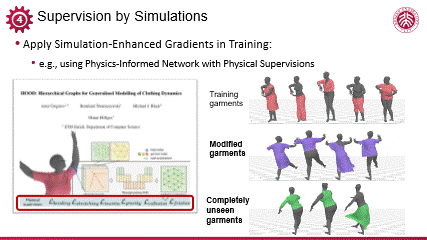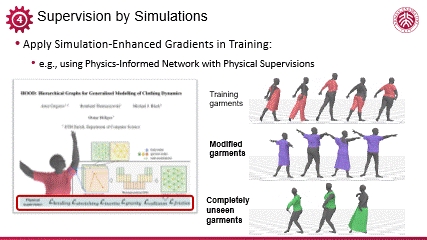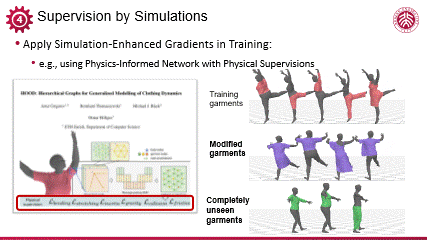
编辑
将可微模拟用于动态现象的生成,Michel Black 团队一个近期的工作具有代表性。他们通过少量数据训练了一个能够模拟人与衣物动态变化的模型。该方法的核心在于采用了一种基于可微模拟监督(differential phyisics supervision)的训练方法,有效利用物理知识等先验,克服了数据稀缺的挑战,从而构建出一个具有广泛适用性的模型。该模型能够在人体姿态与衣物状态发生显著变化时,依然能够生成合理且自然的动态效果。
这不仅展示了可微模拟监督在数据效率方面的优势,也体现了该模型在处理复杂物理交互问题上的强大潜力。
编辑
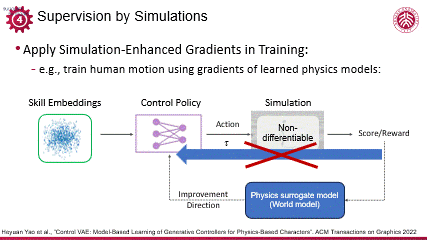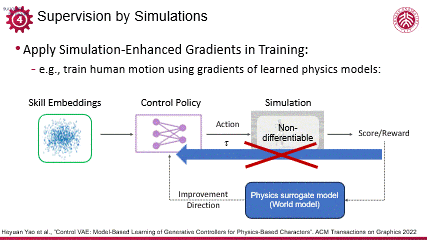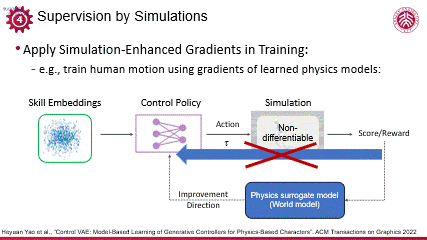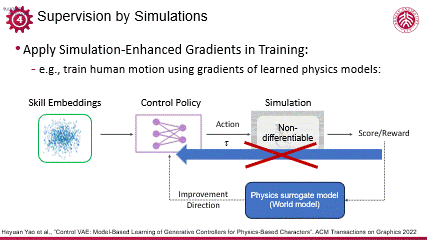
同样利用可微仿真,刘利斌老师在人体运动控制领域做出了一些突出的研究成果。面对人体运动的仿真环境不可微(non-differentiable)的难题,他们的工作采用了基于模型的学习思路,构建了一个可学习的物理代理模型(physics surrogate model),这一代理模型类似于世界模型,能够模拟物理行为,且具备可微分性和鲁棒性,从而提供了通过反向传播(backpropagation)进行物理监督和约束的能力。

编辑
通过这一方法,利斌团队使用较少的迭代次数,成功训练出了一个具有高度泛化能力的动作控制模型。该模型能够有效地处理人体运动控制中的复杂问题,展现了在复杂模拟中进行高效可微监督的潜力,不仅推动了人体运动控制技术的发展,也为其他领域中的非直接可微的系统优化提供借鉴。
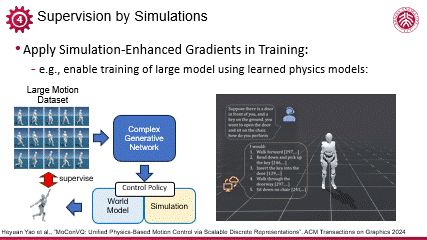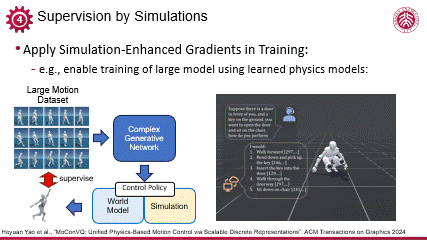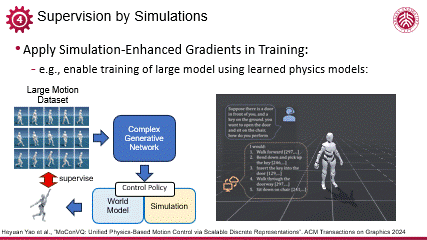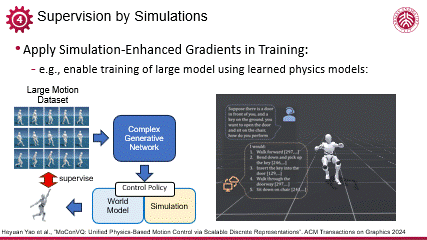
编辑
可微代理模型在训练稳定性和高效性上的显著优势,使得它可以被应用于数据维度更大的任务当中,比如利斌后续的基于大量运动数据训练人体动作的生成模型的工作,可以有效压缩几十小时的多样化运动数据,首次实现大规模运动控制的生成式建模。可微的物理代理模型在其中负责提供鲁棒的基于物理等先验知识的约束,提高了复杂网络结构下的控制策略训练的稳定性,保证训练在较短时间收敛。这一工作也验证了可微模型在大数据与复杂环境下的有效性。

编辑
在探索可微模拟这一前沿领域时,我们不可避免地面临诸多挑战。首先,尽管已取得一定进展,但实际应用场景仍相对有限,且计算量极为庞大,对资源提出了高要求。此外,部分复杂现象因其非平滑特性,难以直接应用微分方法处理,这进一步增加了技术难度。再者,训练过程中收敛速度较慢,且存在扩展性问题(scaling issue),这些都是亟待解决的关键难题。尽管如此,该方法展现出了极高的可靠性和应用潜力,为提升世界模型指引了一个非常有发展潜力的路径。

编辑
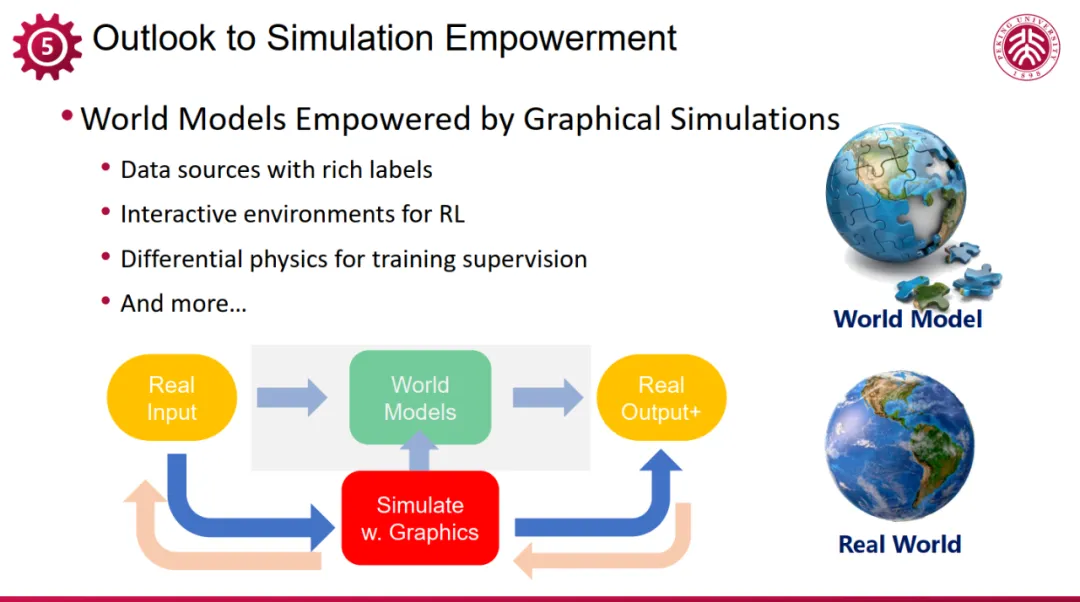
编辑
以上,我们介绍和展望了图形仿真在世界模型训练中的突出作用,具体提出了几个新路径。前述种种策略与手段,不仅各自具备强大潜力,更蕴含着融合共生、协同增效的无限可能。具体而言,我们可以灵活整合数据资源,将其融入基于模拟的训练环境中,并利用微分方法实施监督学习等。在此,我绘制了一幅示意性综合图,旨在直观展现这些元素的融合汇聚,系统性推动世界模型的优化与发展。可以看到,simulation 在其中处于核心地位,是我们在真实数据稀缺时,延续 Scaling Law, 构建世界模型的坚实基石。

编辑
总结,回到当下人工智能与图形学领域,图形仿真无疑是亟待突破的关键方向之一,其发展空间广阔且充满挑战。从多物理现象的逼真与高效模拟,到交互性体验的全面提升,再到各动态现象的可微分表达,都是当前面对的核心问题。
值得一提的是,英伟达黄仁勋先生在 Siggraph 主题报告的间隙时间与观众交流,特别提到了 “微分物理”(differential physics)的重要性,他在这方面的呼吁我是非常认可的,我也拍下视频在朋友圈做了分享。我坚信,计算机图形技术对现实世界的高逼真模拟仿真能力将赋能人工智能,帮助其突破当下大模型训练 scaling law 的数据瓶颈,超越传统的数据增广,在建立新的路径上有巨大的探索空间。
以上便是我今日分享的主要内容,期待与各位进行更深入的探讨。谢谢大家。
#李飞飞等人有了新使命
初衷是好的,但做法还有待商榷。
刚刚,被讨论了大半年的 SB 1047 终于迎来了大结局:加州州长 Gavin Newsom 否决了该法案。
SB 1047 全称是「Safe and Secure Innovation for Frontier Artificial Intelligence Act(《前沿人工智能模型安全创新法案》)」,旨在为高风险的 AI 模型建立明确的安全标准,以防止其被滥用或引发灾难性后果。
具体来说,该法案旨在从模型层面对人工智能进行监管,适用于在特定计算和成本阈值之上训练的模型。但如果严格按照规定的计算和成本阈值来算,现在市面上所有主流的大型模型都会被认为存在「潜在危险」。而且,法案要求模型背后的开发公司对其模型的下游使用或修改承担法律责任,这被认为会给开源模型的发布带来「寒蝉效应」。
法案链接:https://leginfo.legislature.ca.gov/faces/billTextClient.xhtml?bill_id=202320240SB1047
该法案于今年 2 月份在参议院被提出,随后一直争议不断。李飞飞、Yann LeCun、吴恩达都持反对态度。前段时间,李飞飞亲自撰文,阐述了法案可能带来的诸多不利影响。加州大学的数十名师生还签署了联名信,以反对这一法案(参见《李飞飞亲自撰文,数十名科学家签署联名信,反对加州 AI 限制法案》)。不过,也有很多人支持该法案,比如马斯克、Hinton、Bengio。在法案被提交给加州州长之前,双方展开了多次激烈论战。
如今,一切尘埃落定。在给出的否决声明中,州长 Newsom 列举了影响他做决断的多个因素,包括该法案会给人工智能公司带来的负担、加州在该领域的领先地位以及对该法案可能过于宽泛的批评。
在消息发布后,Yann LeCun 代表开源社区表达了对加州州长的感谢。
吴恩达则肯定了 Yann LeCun 一直以来向公众解释该法案弊端的努力。
不过,有人欢喜有人忧 —— 法案的提出者、加州参议员 Scott Wiener 表示对结果非常失望。他在一个帖子中写道,这次否决「对所有相信将对大公司实施监督的人来说都是一个挫折,这些公司正在做出影响公共安全和福利以及『地球的未来』的关键决策」。
需要指出的是,否决 SB 1047 并不意味着加州对 AI 安全问题置之不理,州长 Newsom 在声明中提到了这一点。同时,他还宣布,李飞飞等人将协助领导加州制定负责任的生成式人工智能部署防护措施。
加州州长:SB 1047 存在很多问题
对于 SB 1047,加州州长 Newsom 拥有最终决断权。他为什么会否决该法案?一份声明提供了答案
声明链接:https://www.gov.ca.gov/wp-content/uploads/2024/09/SB-1047-Veto-Message.pdf
声明节选如下:
在全球 50 家领先的 Al 公司中,加州拥有 32 家,它们是现代史上重要的技术进步的先驱。我们在这一领域处于领先地位,这得益于我们的研究和教育机构、多元化和积极进取的劳动力,以及我们对思想自由的自由奔放的培养。作为未来的管理者和创新者,我认真对待监管这一行业的责任。
SB 1047 夸大了关于部署 Al 可能带来的威胁的讨论。辩论的关键在于,监管的门槛是应该基于开发 Al 模型所需的成本和计算数量,还是应该不考虑这些因素而评估系统的实际风险。这一全球性的讨论是在 Al 的能力以惊人的速度不断扩展的情况下进行的。与此同时,应对灾难性危害风险的战略和解决方案也在迅速发展。
SB 1047 法案只关注最昂贵和最大规模的模型,它建立的监管框架可能会让公众对控制这种快速发展的技术产生错误的安全感。与 SB 1047 所针对的模型相比,较小的、专业化的模型可能同样危险,甚至更危险。
在我们争分夺秒监管一项仍处于起步阶段的技术时,适应性至关重要。这需要一种微妙的平衡。尽管 SB 1047 法案的初衷是好的,但它并没有考虑到 Al 系统是否部署在高风险环境中、是否涉及关键决策或敏感数据的使用。相反,该法案甚至对最基本的功能也采用了严格的标准 —— 只要大型系统部署了这些功能。我认为这不是保护公众免受该技术实际威胁的最佳方法。
我同意作者所说的我们不能等到发生重大灾难时才采取行动保护公众。加州不会放弃自己的责任。必须采纳安全协议。应该实施主动的防护措施,对于不良行为者必须有明确且可执行的严厉后果。然而,我不同意的是,为了保证公众的安全,我们必须满足于一种没有对人工智能系统和能力进行经验轨迹分析的解决方案。最终,任何有效规范 AI 的框架都需要跟上技术本身的步伐。
对于那些说我们没有解决问题,或者说加州在监管这项技术对国家安全的潜在影响方面没有作用的人,我不同意。只在加州采用这种方法可能是有道理的,尤其是在国会没有采取联邦行动的情况下,但这种方法必须建立在经验证据和科学的基础上。
隶属于美国国家科学技术研究院(National Institute of Science and Technology)的美国 AI 安全研究所(The U.S. Al Safety Institute)正在根据实证方法制定国家安全风险指南,以防范对公共安全的明显风险。
根据我在 2023 年 9 月发布的一项行政命令,我的政府内部各机构正在对加州关键基础设施使用 AI 的潜在威胁和脆弱性进行风险分析。
在专家的领导下,我们正在开展多项工作,向政策制定者介绍植根于科学和事实的 AI 风险管理实践,这些只是其中的几个例子。
通过这些努力,我在过去 30 天内签署了十多项法案,对 AI 造成的已知具体风险进行监管。
30 天内签署十多项法案,加州的密集 AI 安全举措
在声明中,Newsom 提到他在 30 天内签署了十多项法案。这些法案涉及面非常广,包括打击露骨的 Deepfake 内容,要求对 AI 生成的内容添加水印,保护表演者的数字肖像、已故人物的声音或肖像版权、消费者隐私,探讨人工智能纳入教学的影响等多个方面。
法案列表链接:https://www.gov.ca.gov/2024/09/29/governor-newsom-announces-new-initiatives-to-advance-safe-and-responsible-ai-protect-californians/
针对 SB 1047 对 AI 风险的评估缺乏科学分析这个问题,州长宣布,他已要求全球领先的生成式 AI 专家帮助加州开发部署生成式 AI 的可行护栏。
除了李飞飞,美国国家科学院计算研究社会和伦理影响委员会成员 Tino Cuéllar 以及加州大学伯克利分校计算、数据科学和社会学院院长 Jennifer Tour Chayes 也是该计划的成员之一。
他们的工作重点是对前沿模型及其能力和随之而来的风险进行经验性的、基于科学的轨迹分析。这一工作任重道远。
#LeCun批评o1根本不像研究
Noam Brown回怼:已发表的研究都是废话
LeCun 认为,OpenAI 只发博客,相比技术论文来说,还是差的太远。
图灵奖三巨头之一 Yann LeCun 又和别人吵起来了,这次是 Noam Brown。
Noam Brown 为 OpenAI o1 模型的核心贡献者之一,此前他是 Meta FAIR 的一员,主导了曾火遍一时的 CICERO 项目,在 2023 年 6 月加入 OpenAI 。
这次吵架的内容就是围绕 o1 展开的。众所周知,从 AI 步入新的阶段以来,OpenAI 一直选择了闭源,o1 的发布也不例外。
这也引来了广大网友的吐槽,干脆叫 CloseAI 算了,反观 Meta,在开源领域就做的很好,o1 的发布,更是将这一争论进行了升级。
这不,面对广大网友的吐槽,OpenAI 显然是知道的。就在前两天 Noam 发了一条消息:「我们这些参与 o1 的人听到,外界声称 OpenAI 降低了研究的优先级,听到这些消息我们感觉很奇怪。我向大家保证,事实恰恰相反。」
对于这一说法,Yann LeCun 不满意了,直接跑到评论区开怼「如果你们不能(公开)谈论它,那就不是研究。」
Noam Brown 显然对 LeCun 的回答不是很满意,回击表示:(无需谈论,)有时一幅图胜过千言万语。在 Noam Brown 引用的这张图里,上面还配了一段文字「o1 经过 RL 训练,在通过私有思维链做出反应之前会先进行思考。思考的时间越长,它在推理任务上的表现就越好。这为扩展开辟了一个新的维度。我们不再受预训练的瓶颈限制。我们现在也可以扩展推理计算了。」
更进一步的,Noam Brown 表示在 OpenAI 发布的这篇博客文章中,他们分享了大量的信息,包括 CoT 的内容,Noam Brown 表示这些信息非常具有启发性。(为了让大家更好的了解 o1)上周,他还在加州大学伯克利分校就 o1 模型进行了一次演讲。
Noam 言外之意就是,你看 OpenAI 也是会介绍技术相关的内容的,OpenAI 并不是大家认为的对技术避而不谈。
对于这一说法,显然 LeCun 很不满意:「我很抱歉 Noam,但博客文章与技术论文相比,远远达不到可复现性、方法论以及与最新技术的公正比较等标准。当你们在压力下开发新技术以产生短期产品影响时,你们只需尽快构建你认为最有可能发挥作用的东西。如果它足够好,你就部署它。你们可能不在乎它是否真的具有新奇的创新,是否真的超越了最先进的技术,或者它是否是一个糟糕的临时解决方案,或者从长远来看是否是正确的选择。你们可以自欺欺人地认为这是自切片面包以来最好的东西,只要你的老板和产品人员也能被欺骗。但你知道研究不是这样的。」
Noam 反驳道「我认为恰恰相反。坦白说,很多已经发表的研究说的都是废话,作者只需要欺骗 3 位审稿人和一位 AC。但当你发布一个数百万人使用的东西时,你不能只是发布欺骗自己、老板和产品人员的产品,用户会有自己的决定。」
随后,哈佛大学计算机科学教授 Boaz Barak(资料显示,从 2024 年 1 月开始,Barak 离开哈佛大学前往 OpenAI 工作一年)表示:「我认为你们俩的观点都很好。o1 背后的研究绝对具有创新性,草莓团队已经完成了惊人的工作和想法,OpenAI 正在改变人们扩展新人工智能系统的方式。
虽然我们发表了博客,Noam 也做了相关演讲,但从纯粹加速科学进步的角度来看,如果能够发布所有的细节,开源所有的代码和权重,那就更好了。然而,正如我们博客中所说,我们还有其他考虑,包括竞争压力和安全因素,因此目前还不宜这样做。」
对此,LeCun 认为 OpenAI 不公布技术细节,出于竞争压力的考量还是可信的,但他绝不相信 OpenAI 是为了安全。
至此,这段 battle 告一段落。但大家讨论的热情居高不下。
「对于一家拥有数百名高级专家的非营利组织怎么可能每年只发表很少的论文?我认为自 2021 年以来,OpenAI 每年只有 2-3 篇论文?OpenAI 是过去 20 年来最不开放的前沿科技公司。」
还有网友表示「虽然这是一项很酷的研究,但我同意 Yann 的观点 —— 不符合研究标准,因为 OpenAI 没有发表论文、进行同行评审或研究的可复现性。OpenAI 在 GPT-3 之前发表了很棒的研究,之后就是让人怀疑的博客文章和炒作(例如 Sora)。我希望 OpenAI 能推动研究团队和管理层再次发表文章,如果有真正新颖的东西,就申请专利。如果 OpenAI 能发表文章,那么其影响力会更大;这几年 OpenAI 的闭源真是令人失望。」
最后,还有网友灵魂一问:那他们(Ilya Sutskever、Mira Murati 等)为什么都离开了?
「人才流失如此之快的原因到底是什么?」
对于这场辩论,你怎么看?欢迎评论区留言。
参考链接:https://x.com/polynoamial/status/1839836929115721915
#AGILE
端到端优化所有能力,字节跳动提出强化学习LLM Agent框架
大语言模型(Large Language Models, LLMs)的强大能力推动了 LLM Agent 的迅速发展。围绕增强 LLM Agent 的能力,近期相关研究提出了若干关键组件或工作流。然而,如何将核心要素集成到一个统一的框架中,能够进行端到端优化,仍然是一个亟待解决的问题。
来自字节跳动 ByteDance Research 的研究人员提出了基于强化学习(Reinforcement Learning, RL)的 LLM Agent 框架 ——AGILE。该框架下,Agent 能够拥有记忆、工具使用、规划、反思、与外界环境交互、主动求助专家等多种能力,并且通过强化学习实现所有能力的端到端训练。尤其值得注意的是,AGILE 框架允许 Agent 在不自信时主动向人类专家寻求建议。这带来了两大优势:首先,Agent 在处理复杂问题时能够持续保持高准确率;其次,通过向人类学习,增强了其快速适应新任务的泛化能力。
- 论文地址:https://arxiv.org/abs/2405.14751
- 代码地址:https://github.com/bytarnish/AGILE
研究者让 AGILE 框架在复杂问答任务中进行了验证。在 ProductQA 与 MedMCQA 任务上,经过 RL 训练后的 13B 模型或者 7B 模型能够超越提示工程构建的 GPT-4 Agent。
AGILE Agent 框架
如图 1 (a) 所示,AGILE 框架包含四个核心模块:LLM、记忆(Memory)、工具(Tools)和执行器(Executor)。LLM 负责预测动作;记忆模块记录 Agent 的轨迹;工具模块提供 Agent 可以调用的外部 API;执行器会监听 LLM 的输出,根据 LLM 的输出调用相应的模块执行具体的操作,并将执行操作得到的结果添加到 LLM 的上下文中。
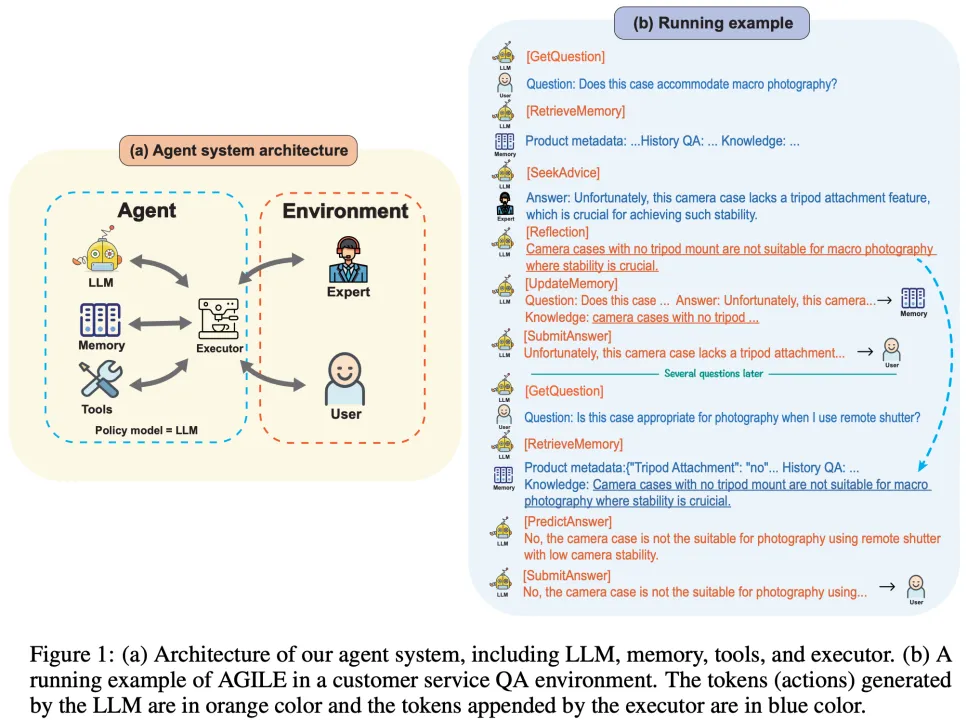
编辑
图 1 (b) 展示了 AGILE Agent 在电商问答场景中的一个示例。电商问答是一个复杂的实际应用场景,面临的挑战包括需要海量商品的领域知识、灵活运用商品检索工具、以及快速适应不断涌现的新商品。如图 1 (b) 所示,AGILE Agent 会根据用户的问题检索记忆,如果无法确定问题的答案,Agent 会向人类专家寻求帮助。在获得专家的反馈后,Agent 会反思并将新掌握的领域知识存储在记忆中。在未来,面对新的问题时,Agent 能够从记忆中检索到这条知识,并基于这些知识直接给出准确的答案。除此之外,AGILE Agent 也会根据用户的问题选择是否调用外部工具(如搜索、数据库检索),辅助生成最终的回答。
强化学习定义:LLM Agents 被定义为一个 token-level MDP(Markov Decision Process)。动作空间(Action space)由 LLM 的词表构成,LLM 生成的每一个 token 是一个动作,LLM 本身则作为 Agent 的策略模型(Policy model)。Agent 的状态(State)由 LLM 上下文和记忆组成。在每个时刻,LLM 预测动作,执行器根据预定义的逻辑完成状态转移,同时环境给予 Agent 相应的奖励(Reward)。
在 AGILE 框架下,Agent 有两种策略学习方法。第一种是模仿学习,通过收集人类轨迹数据或更高级别 Agent 的轨迹数据,对 LLM 进行 SFT 训练。第二种是强化学习,通过定义奖励函数,利用强化学习算法来训练 LLM。
此外,LLM Agent 可能会产生跨越数百万个 tokens 的轨迹,这为直接训练带来了挑战。为了应对这种长程依赖的问题,研究人员提出了一种片段级别的优化算法。
主动寻求帮助:AGILE 框架允许 Agent 主动向外部的人类专家寻求帮助。这种机制有两个优势:首先,当 Agent 遇到不确定的情况时,通过求助人类专家,确保其在实际应用中达到高准确率。其次,Agent 能够通过对人类的反馈反思并积累知识,从而更快适应新环境,提升其泛化能力。然而决定何时寻求帮助是一个复杂决策,它涉及到 Agent 的自我评估、人类反馈对未来的价值以及人类专家的成本。因此,标注何时应该求助是很难的。但在强化学习框架中,可以通过定义相关奖励,将这种求助能力作为策略模型的一部分,在端到端训练中得到提升。
实验结果
ProductQA
ProductQA 是一个商品问答任务。该数据集包含 26 个对应不同商品类别的 QA 任务,每个任务平均包含 3,393 个问题。ProductQA 包括基于事实的问题、推理问题和商品推荐问题,它能够全面评估 Agent 处理历史信息和累积知识、利用工具、向人求助、自我评估和反思的能力。此外,训练和测试集由不同的任务构成,以评估 Agent 在新商品问答上的泛化能力。
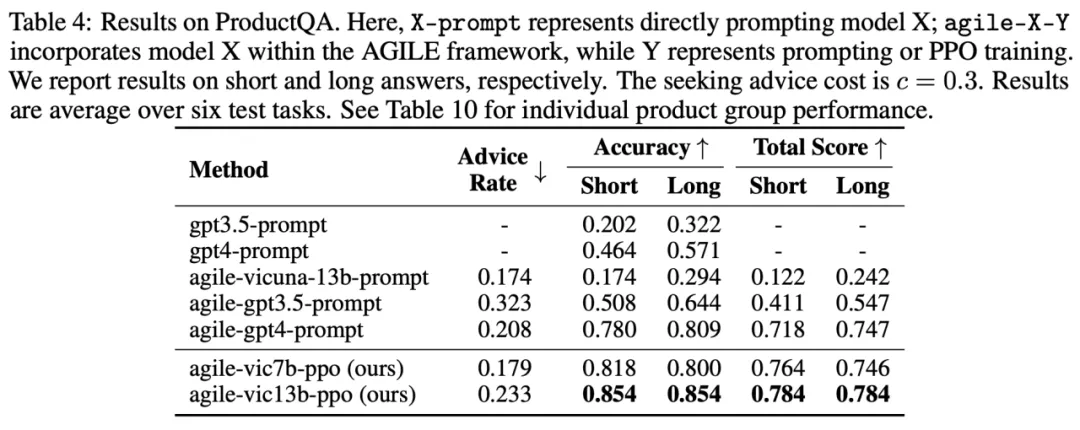
编辑
在商品问答(ProductQA)任务上,基于 Vicuna-13b 训练的 AGILE Agent(agile-vic13b-ppo)表现超过了 GPT-4(gpt4-prompt)与提升工程构建的 GPT-4 Agent(agile-gpt4-prompt)。在使用了相当的求助比例(Advice Rate)的情况下,agile-vic13b-ppo 的 acc 相比于 agile-gpt4-prompt 提升了 7.4%,在 Total Score 上提升了 9.2%。
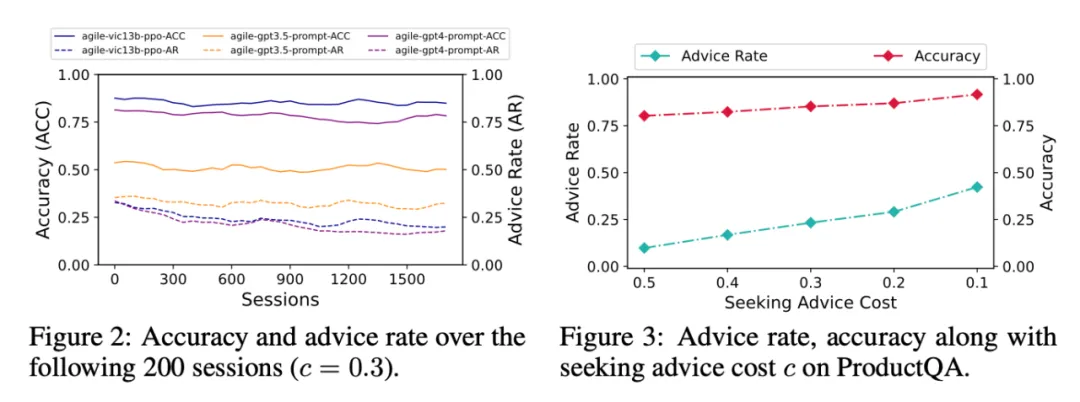
编辑
从上图可以看出,在执行包含上千个问答的任务整个过程中,agile-vic13b-ppo 的 acc 持续稳定地高于 agile-gpt4-prompt。同时寻求人类帮助的频率(Advice Rate)随着问答轮数的增加逐渐下降。此外,通过调整人类的咨询成本(Seeking Advice Cost)和进行强化学习训练,AGILE Agent 可以有效实现准确率与专家成本的权衡。
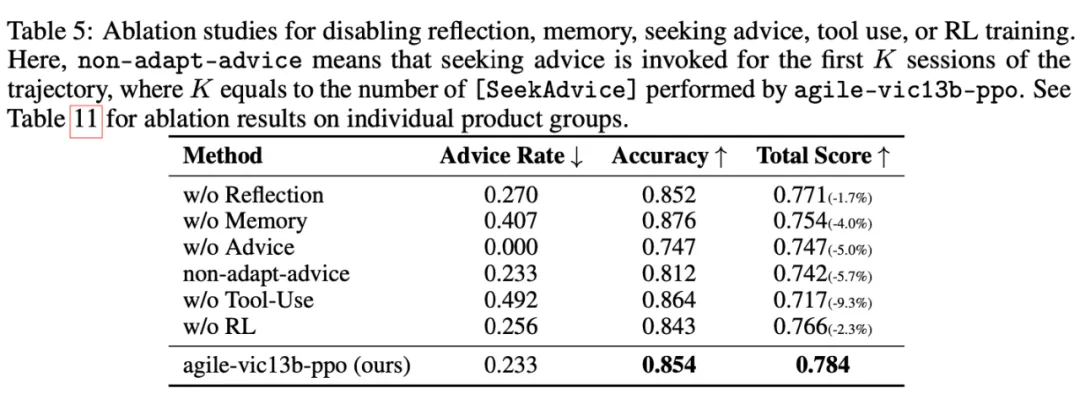
编辑
消融实验结果显示,记忆、反思、咨询人类建议、工具使用、RL 训练在实现高性能的 AGILE Agent 中均具有重要作用。
MedMCQA
MedMCQA 是一个多项选择的问答数据集,其问题来自医学院入学考试。在 MedMCQA 任务上,基于 Meerkat-7b 训练的 AGILE Agent(agile-mek7b-ppo)表现优于 GPT-4 Agent。准确率达到了 85.2%,超过了之前的 SOTA 方法 ——GPT 4-MedPrompt 的 79.1%。消融实验结果进一步验证了记忆、咨询人类建议、反思和 RL 训练的重要性。
编辑
更多研究细节,可参考原论文。
总结
AGILE是一种基于强化学习的LLM Agent框架。AGILE Agent具备拥有长期记忆、使用外部工具、向人类专家进行咨询、反思等能力,并且所有能力可以进行端到端的统一优化。AGILE的一个重要特点是Agent在遇到无法自行解决的问题时可以向人类专家咨询,这种机制保证了应用场景中对高准确率的要求,同时增强了Agent的学习与泛化能力。实验表明,经过强化学习训练的13B或7B模型的Agent,其能力可以超过GPT-4 Agent。
团队介绍
ByteDance Research 专注于人工智能领域的前沿技术研究,涵盖了机器翻译、视频生成基础模型、机器人研究、机器学习公平性、量子化学、AI 制药、分子动力学等多技术研究领域,同时致力于将研究成果落地,为公司现有的产品和业务提供核心技术支持和服务。
#中国科学家让薛定谔的猫活了23分钟
量子物理领域,一新纪录被中国科学家打破——
中科大团队成功让薛定谔的猫活了长达整整23分钟!
什么概念呢?
以往人们以薛定谔的猫「到底是生是死」来阐释原子的量子叠加状态。因为环境非常不稳定,所以这种状态往往存续十分短暂——几秒或者几毫秒。
但现在这样的存续时间有了质的飞跃,中国团队成功让这种量子叠加状态持续了1400秒的时间。
这项研究由中科大少年班学院院长卢征天教授、合肥国家实验室研究员夏添领衔,其成果发表在《自然·光子学》。
一旦证明这一长寿命薛定谔猫态的制备可行,那么将来对于量子物理世界的研究有重要意义。
比如用来检测和研究磁力、探索物理学中新的和奇异的效应,甚至可以用于非常稳定的量子计算机内存。
薛定谔的猫多活了23分钟
先来简单了解下物理学四大神兽之一——薛定谔的猫。
“薛定谔的猫”是一个著名的思想实验,由奥地利物理学家埃尔温·薛定谔在1935年提出。
回顾一下实验:
想象一个封闭的盒子里有一个猫,一个装有毒气的瓶子,以及一个放射性原子。如果放射性原子衰变,就会触发一个机制打碎瓶子,释放毒气,猫就会死。如果原子没有衰变,猫就活着。
在量子力学中,放射性原子在没有观测之前,同时处于衰变和未衰变的叠加状态。这意味着,在没有打开盒子观察之前,猫既是死的也是活的,处于一种生死叠加的状态。
当我们打开盒子观察猫的状态时,量子叠加状态会“坍缩”,猫的状态从既是死又是活的状态变为确定的死是活。这个过程也被称为波函数坍缩。
而这种一个系统同时处于两种或多种截然相反状态的量子叠加,就是薛定谔猫态。
在实验中实现和维持薛定谔猫态非常困难,因为这需要极高的隔离以防止温度、磁场等环境干扰导致它们在几秒或毫秒内坍缩到单一状态。
本文研究科学家们历史性地让薛定谔猫态保持了长时间的稳定,相干时间长达23分钟。
(相干时间是指量子系统在退相干之前能够保持量子特性的时间,退相干指的是量子系统逐渐失去其量子特性的过程。)
在这个实验中,薛定谔猫态是通过非线性自旋旋转实现的,即原子的自旋同时指向两个完全相反的方向。
具体来说,研究团队利用波长为1036nm、功率为16W的线性偏振光晶格激光束(束腰为20μm),在魔术波长上捕获了大约10⁴个¹⁷³Yb原子。原子首先在邻近腔室的磁光阱中被预冷并加载,随后通过移动光学偶极阱沿x轴方向输送到测量室。
实验装置被四层磁屏蔽所保护,内置cos(θ)线圈在z方向上产生一个稳定均匀的1.24μT磁场,以最小化外部磁场干扰。
实现上,团队采用了以下三步骤的创新方案:
- 使用与¹S₀(F=5/2)→¹P₁(F′=5/2)能级跃迁共振的σ+偏振泵浦激光脉冲,将原子初始化到|F, F〉拉伸态。
- 应用离共振的σ⁺偏振控制激光束,沿x轴方向传播,通过调节非线性交互作用(张量交流斯塔克位移)诱导自旋旋转。
- 使用与¹S₀(F=5/2)→³P₁(F′=7/2)能级跃迁共振的σ⁺偏振探测光束测量|F, F〉态中的归一化布居数,利用光学晶格引入的差分张量光移位进行状态选择性测量。
通过精确控制控制激光的频率和强度(80 mW/cm²),实验中测得的拉比频率为:
![]()
编辑
这一系列精确操作成功制备出了¹⁷³Yb原子的薛定谔猫态,该状态是具有自旋量子数5/2的原子核自旋投影态m=+5/2和m=−5/2的量子叠加。
关键是,团队发现这个猫态被保护在无退相干子空间中,对光晶格产生的非均匀张量光移具有免疫力。这是因为光晶格的哈密顿量Hₜ与猫态密度矩阵ρcat和Hₒ都对易,从而避免了光场带来的退相干。
这使得猫态实现了1.4(1)×10³秒的超长相干时间,即约23分钟,远超常规相干自旋态(CSS)在相同条件下实现的0.9(2)×10³秒相干时间。
值得注意的是,目前实验中的真空阱寿命为71(1)秒,研究人员指出通过改善真空条件,猫态的寿命有望进一步延长以匹配其相干时间,同时还可以借助自旋回波技术来进一步减少退相干效应。
测量灵敏度接近海森堡极限
为表征猫态对1.24-μT静态磁场的灵敏度,研究人员进行了拉姆齐干涉测量。
通过两个间隔为τ的(π/2)cat脉冲序列,在160秒的测量时间内,态的布居数保持在0.90(3),干涉条纹对比度达到0.88(3)。
最终实现了0.12(1)nT的磁场测量灵敏度,比标准量子极限0.22nT提高了约1.8倍,接近海森堡极限(HL)的0.10nT。
作为对比,同样条件下的相干自旋态只能达到0.70(10)nT的灵敏度,比标准量子极限0.22nT的灵敏度差了约3.2倍。
这项工作的意义体现在多个方面。
具有长相干时间的高自旋系统在量子科技领域具有广泛应用前景,可用于发展量子存储器,并为量子计算中的错误纠正提供必要的冗余度。
特别值得一提的是,这项工作为寻找自旋传感器提供了新的可能性。传统上,具有基态J=0和核自旋I=1/2的原子(如³He、¹²⁹Xe、¹⁷¹Yb和¹⁹⁹Hg)被认为是理想的自旋传感器候选者。
而这项研究表明高自旋同位素同样可以胜任这一角色。例如,¹⁷¹Yb/¹⁷³Yb这样的同位素对为开发双物种冷原子共磁力计提供了新的可能性。
更重要的是,这个展现出接近海森堡极限磁场测量灵敏度的猫态,不仅可用于高精度磁场测量,还可应用于寻找永久电偶极矩、检验洛伦兹不变性,以及探索超出标准模型的新物理现象,为量子精密测量领域开辟了新的研究方向。
中科大少年班院长领衔
此次研究来自中科大夏添、卢征天、邹长铃等人一起合作。
通讯作者之一卢征天,目前是中国科学技术大学物理学院杰出讲席教授、少年班学院院长。
研究方向包括检验时空及物质与反物质之间的对称性,寻找标准模型之外的新物理;发展超灵敏同位素痕量探测新技术,同时开展在地球与环境科学中的应用;对于原子核、原子与分子的精密测量。
另一位通讯作者夏添,目前是合肥国家实验室研究员。他本科毕业于清华大学,随后前往普林斯顿大学攻读博士。
研究方向包括通过对原子固有电偶极矩的测量来检测基本作用中对称性的破缺来寻找标准模型之外的新物理;以原子物理为平台的精密测量;以中性原子为平台的量子信息;用光抽运的方法实现原子自旋的磁极化。
对于这项成果,研究人员表示,这一长寿命薛定谔猫态的制备,将为原子磁力计、量子信息纠错以及探索新物理等开辟出新途径。
参考链接:
[1]https://www.wired.com/story/scientists-have-pushed-the-schrodingers-cat-paradox-to-new-limits
[2]https://news.ustc.edu.cn/info/1056/89559.htm
[3]https://arxiv.org/abs/2410.09331v1
#真正的LLM Agent
本文探讨了未来 LLM 智能体的发展方向,强调模型本身而非工作流将成为核心,通过强化学习与推理的结合实现真正的智能体功能。
知名 AI 工程师、Pleias 的联合创始人 Alexander Doria 最近针对 DeepResearch、Agent 以及 Claude Sonnet 3.7 发表了两篇文章,颇为值得一读,尤其是 Agent 智能体的部分。
Alexander的观点很明确:未来 AI 智能体的发展方向还得是模型本身,而不是工作流(Work Flow)。还拿目前很火的 Manus 作为案例:他认为像 Manus 这样基于「预先编排好的提示词与工具路径」构成的工作流智能体,短期或许表现不错,但长期必然遇到瓶颈。这种「提示驱动」的方式无法扩展,也无法真正处理那些需要长期规划、多步骤推理的复杂任务。
而下一代真正的 LLM 智能体,则是通过「强化学习(RL)与推理(Reasoning)的结合」来实现。文章举例了 OpenAI 的 DeepResearch 和 Anthropic 的 Claude Sonnet 3.7,说明未来智能体会自主掌控任务执行的全过程,包括动态规划搜索策略、主动调整工具使用等,而不再依靠外部提示或工作流驱动。这种转变意味着智能体设计的核心复杂性将转移到模型训练阶段,从根本上提升模型的自主推理能力,最终彻底颠覆目前的应用层生态。
01 模型即产品(The Model is the Product)
过去几年里,人们不断猜测下一轮 AI 的发展方向:会是智能体(Agents)?推理模型(Reasoners)?还是真正的多模态(Multimodality)?但现在,是时候下结论了:AI 模型本身,就是未来的产品。 目前,无论是研究还是市场的发展趋势,都在推动这个方向。
为什么这么说?
- 通用型模型的扩展,遇到了瓶颈。 GPT-4.5 发布时传递的最大信息就是:模型的能力提升只能呈线性增长,但所需算力却在指数式地飙升。尽管过去两年 OpenAI 在训练和基础设施方面进行了大量优化,但仍然无法以可接受的成本推出这种超级巨型模型。
- 定向训练(Opinionated training)的效果,远超预期。强化学习与推理能力的结合,正在让模型迅速掌握具体任务。这种能力,既不同于传统的机器学习,也不是基础大模型,而是某种神奇的第三形态。比如一些极小规模的模型突然在数学能力上变得惊人强大;编程模型不再只是简单地产生代码,甚至能够自主管理整个代码库;又比如 Claude 在几乎没有专门训练、仅靠非常贫乏的信息环境下,竟然也能玩宝可梦。
- 推理(Inference)的成本,正在极速下降。DeepSeek 最新的优化成果显示,目前全球所有可用的 GPU 资源,甚至足以支撑地球上每个人每天调用一万个顶尖模型的 token。而实际上,目前市场根本不存在这么大的需求。简单卖 token 赚钱的模式已经不再成立,模型提供商必须向价值链更高层发展。
但这个趋势也带来了一些尴尬,因为所有投资人都将宝压在了「应用层」上。然而,在下一阶段的 AI 革命中,最先被自动化、被颠覆的,极有可能就是应用层。
02 下一代 AI 模型的形态
过去几周,我们看到了两个典型的「模型即产品」的案例:OpenAI 推出的 DeepResearch 和 Anthropic 推出的 Claude Sonnet 3.7。
关于 DeepResearch,很多人存在误解,这种误解随着大量仿制版本(开源和闭源)的出现,变得更严重了。实际上,OpenAI 并非简单地在 O3 模型外面套了层壳,而是从零开始训练了一个全新的模型。
*OpenAI 的官方文档:https://cdn.openai.com/deep-research-system-card.pdf这个模型能直接在内部完成搜索任务,根本不需要外部调用、提示词或人工流程干预:
「该模型通过强化学习,自主掌握了核心的网页浏览能力(比如搜索、点击、滚动、理解文件)……它还能自主推理,通过大量网站的信息合成,直接找到特定的内容或生成详细的报告。」
DeepResearch 不是标准的大语言模型(LLM),更不是普通的聊天机器人。它是一种全新的研究型语言模型(Research Language Model),专为端到端完成搜索类任务而设计。任何认真用过这个模型的人都会发现,它生成的报告篇幅更长,结构严谨,内容背后的信息分析过程也极为清晰。
相比之下,正如 Hanchung Lee 所指出的,其他的 DeepSearch 产品,包括 Perplexity 和 Google 版,其实不过就是普通模型加了一点额外的小技巧:https://leehanchung.github.io/blogs/2025/02/26/deep-research/
「虽然谷歌的 Gemini 和 Perplexity 的聊天助手也宣称提供了『深度搜索』的功能,但他们既没有公开详细的优化过程,也没有给出真正有分量的量化评估……因此我们只能推测,它们的微调工作并不显著。」
Anthropic 的愿景也越来越明确。去年 12 月,他们给出了一个颇有争议,但我认为相当准确的「智能体」定义*。与 DeepSearch 类似,一个真正的智能体必须在内部独立完成任务:「智能体能够动态地决定自己的执行流程和工具使用方式,自主掌控任务的完成过程。」
*Anthropic 的定义:https://www.anthropic.com/research/building-effective-agents
但市面上大多数所谓的智能体公司,目前做的根本不是智能体,而是「工作流」(workflows):
也就是用预先定义好的代码路径,串联 LLM 与其他工具。这种工作流仍然有一定价值,尤其是在特定领域的垂直应用上。但对于真正从事前沿研究的人来说,很明显:未来真正的突破,必须是直接从模型层面入手,重新设计 AI 系统。
Claude 3.7 的发布,就是一个实实在在的证明:Anthropic 专门以复杂的编程任务为核心训练目标,让大量原本使用工作流模型(比如 Devin)的产品,在软件开发(SWE)相关的评测中表现大幅提升。
再举一个我们公司 Pleias 更小规模的例子:
我们目前正在探索如何彻底自动化 RAG(基于检索的生成系统)。
现阶段的 RAG 系统由许多复杂但脆弱的流程串联而成:请求路由、文档切分、重排序、请求解释、请求扩展、来源上下文理解、搜索工程等等。但随着模型训练技术的进步,我们发现完全有可能把这些复杂流程整合到两个相互关联的模型中:
一个专门负责数据准备,另一个专门负责搜索、检索、生成报告。这种方案需要设计一套非常复杂的合成数据管道,以及完全全新的强化学习奖励函数。
这是真正的模型训练,真正的研究。
03 这一切对我们意味着什么?
意味着复杂性的转移。 通过训练阶段预先应对大量可能的行动和各种极端情况,部署时将变得异常简单。但在这个过程中,绝大部分价值都将被模型训练方创造,并且最终被模型训练方所捕获。
简单来说,Anthropic 想要颠覆并替代目前的那些所谓「智能体」工作流,比如像 llama index 的这种典型系统:

Llama Index Basic Agent
Llama Index Basic Agent转变为这种完全模型化的方案:

Claude Agent
04 模型供应商与应用开发商的蜜月期结束了
目前 AI 的大趋势已经明朗:
未来 2-3 年内,所有闭源 AI 大模型提供商都会停止向外界提供 API 服务,而将转为直接提供模型本身作为产品。这种趋势并非猜测,而是现实中的多重信号都指向了这一点。Databricks 公司生成式 AI 副总裁 Naveen Rao 也做了清晰的预测:
在未来两到三年内,所有闭源的 AI 模型提供商都会停止销售 API 服务。
简单来说,API 经济即将走向终结。模型提供商与应用层(Wrapper)之间原本的蜜月期,已彻底结束了。
市场方向可能的变化:
- Claude Code 和 DeepSearch都是这种趋势的早期技术与产品探索。你可能注意到,DeepSearch 并未提供 API 接口,仅作为 OpenAI 高级订阅的增值功能出现;Claude Code 则只是一个极为简单的终端整合。这清晰表明,模型厂商已开始跳过第三方应用层,直接创造用户价值。
- 应用层企业开始秘密地布局模型训练能力。 当前成功的应用型公司,也都意识到了这种威胁,悄悄尝试转型。例如 Cursor 拥有一款自主开发的小型代码补全模型;WindSurf 内部开发了 Codium 这样一款低成本的代码模型;Perplexity 此前一直依靠内部分类器进行请求路由,最近更是转型训练了自己的 DeepSeek 变体模型用于搜索用途。
- 当前成功的「应用套壳商」(Wrappers)实际上处于困境之中:他们要么自主训练模型,要么就等着被上游大模型彻底取代。他们现在所做的事情,本质上都是为上游大模型厂商进行免费的市场调研、数据设计和数据生成。
接下来发生什么还不好说。成功的应用套壳商现在陷入两难处境:「自己训练模型」或者「被别人拿来训练模型」。据我所知,目前投资者对「训练模型」极为排斥,甚至使得一些公司不得不隐藏他们最具价值的训练能力,像 Cursor 的小模型和 Codium 的文档化至今都极为有限。
05 市场完全没有计入强化学习(RL)的潜力
目前 AI 投资领域存在一个普遍的问题:所有投资几乎都是高度相关的。
现阶段几乎所有的 AI 投资机构,都抱持以下一致的想法:
- 封闭 AI 厂商将长期提供 API;
- 应用层是 AI 变现的最佳途径;
- 训练任何形式的模型(不论预训练还是强化学习)都是在浪费资源;
- 所有行业(包括监管严格的领域)都会继续长期依赖外部 AI 提供商。
但我不得不说,这些判断日益看起来过于冒险,甚至是明显的市场失灵。
尤其是在最近强化学习(RL)技术取得突破的情况下,市场未能正确对强化学习的巨大潜力进行定价。
眼下,「强化学习」的威力根本没有被资本市场准确评估和体现。
从经济学角度看,在全球经济逐渐迈入衰退背景下,能够进行模型训练的公司具有巨大的颠覆潜力。然而很奇怪的是,模型训练公司却根本无法顺利获得投资。以西方的新兴 AI 训练公司 Prime Intellect 为例,它拥有明确的技术实力,有潜力发展为顶级 AI 实验室,但即便如此,其融资仍面临巨大困难。
纵观欧美,真正具备训练能力的新兴 AI 公司屈指可数:
Prime Intellect、EleutherAI、Jina、Nous、HuggingFace 训练团队(规模很小)、Allen AI 等少数学术机构,加上一些开源基础设施的贡献者,基本涵盖了整个西方训练基础设施的建设和支持工作。
而在欧洲,据我所知,至少有 7-8 个 LLM 项目正在使用 Common Corpus 进行模型训练。
然而,资本却对这些真正能够训练模型的团队冷眼旁观。
「训练」成为被忽略的价值洼地
最近,甚至连 OpenAI 内部也对目前硅谷创业生态缺乏「垂直强化学习」(Vertical RL)表达了明显的不满。

我相信,这种信息来自于 Sam Altman 本人,接下来可能会在 YC 新一批孵化项目中有所体现。
这背后的信号非常明确:大厂将倾向于直接与掌握垂直强化学习能力的创业公司合作,而不仅仅依赖应用层套壳。
这种趋势也暗示了另一个更大的变化:
未来很多最赚钱的 AI 应用场景(如大量仍被规则系统主导的传统产业)尚未得到充分开发。谁能训练出真正针对这些领域的专用模型,谁就能获得显著优势。而跨领域、高度专注的小型团队,也许才更适合率先攻克这些难题,并最终成为大型实验室潜在收购的目标。
但令人担忧的是,目前大部分西方 AI 企业还停留在「纯应用层」的竞争模式上。甚至大部分人都没有意识到:
仅靠应用层打下一场战争的时代已经结束了。
相比之下,中国的 DeepSeek 已经走得更远:它不再仅仅把模型视作产品,而是视为一种通用的基础设施。正如 DeepSeek 创始人梁文锋在公开采访中明确指出:
「就像 OpenAI 和 Anthropic 一样,我们将计划直接公开说明:DeepSeek 的使命并不是仅仅打造单个产品,而是提供一种基础设施层面的能力……我们会首先投入研究和训练,将其作为我们的核心竞争力。」
可惜的是,在欧美,绝大部分 AI 初创公司仍只专注于构建单纯的应用层产品,这就如同「用过去战争的将领去打下一场新战争」,甚至根本没意识到上一场战争其实已经结束了。
06 关于简单 LLM 智能体的「苦涩教训」
最近被热炒的 Manus AI 属于典型的「工作流」。我整个周末的测试*都在不断验证着这种系统的根本性局限,而这些局限早在 AutoGPT 时代就已经显现出来。尤其是在搜索任务中,这种局限表现得极为明显:
*https://techcrunch.com/2025/03/09/manus-probably-isnt-chinas-second-deepseek-moment/
- 它们缺乏真正的规划能力,经常在任务进行到一半时就「卡住」了,无法推进;
- 它们无法有效地记忆长期的上下文,通常任务持续超过 5 到 10 分钟便难以维持;
- 它们在长期任务中表现很差,多个步骤的任务会因为每一步的细微误差被放大,导致最终失败。
今天我们尝试从这个全新的、更严格的角度出发,重新定义 LLM 智能体的概念。以下内容,是在整合了来自大公司有限的信息、开放研究领域近期成果,以及我个人的一些推测之后,做的一次尽可能清晰的总结。
智能体这个概念,本质上几乎与基础的大语言模型完全冲突。
在传统的智能体研究中,智能体(Agent)总是处于一个有约束的环境里:比如想象一下你被困在一个迷宫里,你可以向左走,也可以向右走,但你不能随便飞起来,也不能突然钻进地下,更不能凭空消失——你会受到物理规则甚至游戏规则的严格限制。真正的智能体,即便处于这种约束环境中,也会拥有一些自由度,因为你有多种方式来完成游戏。但无论怎么行动,每一次决策背后,都需要你有明确的目标:赢得最终的奖励。有效的智能体会逐渐记忆过去走过的路,形成一些有效的模式或经验。
这种探索的过程,被称为 「搜索(search)」。而这个词其实非常贴切:一个智能体在迷宫中的探索行为,和人类用户在网络搜索时不停点击链接,探索自己想要的信息,几乎是完美的类比。关于「搜索」的研究,学界已经有几十年的历史。举一个最新的例子:Q-star 算法(曾被传言是 OpenAI 新一代模型背后的算法,当然至今还没完全确认)其实来源于 1968 年的 A-Star 搜索算法。而最近由 PufferLib 完成的宝可梦训练实验,就生动地展现了这种智能体「搜索」的全过程:我们看到智能体不断尝试路径,失败后再重试,不断地往返摸索最优路径。

Pokemon RL experiment by PufferLib
基础语言模型和智能体的运行方式几乎截然相反:
- 智能体会记住它们的环境,但基础语言模型不会。语言模型只根据当前窗口内的信息来回应。
- 智能体有明确的理性约束,受限于实际条件,而基础语言模型只是生成概率较高的文本。虽然有时它们也能表现出前后一致的逻辑,但始终无法保证,甚至随时可能因为「美学需求」而脱离轨道。
- 智能体能制定长期策略,它们可以规划未来的行动或回溯重来。但语言模型只擅长单一推理任务,在面对需要多步复杂推理的问题时,很快就会「饱和」(multi-hop reasoning),难以处理。整体来看,它们被文本规则约束,而不是现实世界的物理或游戏规则。
将语言模型与智能体化结合的最简单方法,就是通过预定义的提示(prompt)和规则来约束输出。目前绝大部分的语言模型智能体系统都是这种方式,然而这种做法注定会撞上 Richard Sutton 提出的「苦涩教训」(Bitter Lesson)。
人们经常误解「苦涩教训」,认为它是指导语言模型预训练的指南。但它本质上讲的是关于智能体的设计,讲的是我们往往想直接把人类的知识「硬编码」到智能体当中——例如「如果你碰壁了,就换个方向;如果多次碰壁,就回头再试试」。这种方法在短期来看效果很好,很快就能看到进步,不需要长时间训练。但长期来看,这种做法往往走向次优解,甚至会在意料之外的场景里卡住。Sutton 这样总结道:
「我们必须学会苦涩的教训:人为地去预设我们思考的方式,长期来看并不奏效。AI 研究的历史已经反复验证:
1)研究者经常试图将知识提前写入智能体;
2)这种做法短期内效果明显,也让研究者本人很有成就感;
3)但长期来看,性能很快达到上限,甚至阻碍后续发展;
4)最终的突破反而来自完全相反的方法,即通过大量计算资源进行搜索和学习。最终的成功让人有些苦涩,因为它否定了人们偏爱的、以人为中心的方法。」
我们再把这个道理迁移到现在 LLM 的生产应用中。像 Manus 或常见的 LLM 封装工具,都在做着「人为设定知识」的工作,用提前设计好的提示语引导模型。这或许短期内最省事——你甚至不需要重新训练模型——但绝不是最优选择。最终你创造的是一种混合体,部分靠生成式 AI,部分靠规则系统,而这些规则恰恰就是人类思维中对空间、物体、多智能体或对称性等概念的简单化抽象。
更直白地讲,如果 Manus AI 至今无法很好地订机票,或在与老虎搏斗时提出有用建议,并不是因为它设计得差,而是它遭遇了「苦涩教训」的反噬。提示(Prompt)无法无限扩展,对规则硬编码无法无限扩展。你真正需要的是从根本上设计能够搜索、规划和行动的真正的 LLM 智能体。
07 真正的成功之路
这是一个很难的问题。现在公开的信息很少,只有 Anthropic、OpenAI、DeepMind 等少数实验室了解细节。到目前为止,我们只能根据有限的官方消息、非正式传言以及少量的公开研究来了解一些基本情况:
- 与传统智能体类似,LLM 智能体同样采用强化学习进行训练。你可以把语言模型的学习看作一个「迷宫」:迷宫里的道路就是关于某件事可能写出来的所有文字组合,迷宫的出口就是最终想要的「奖励」(reward)。而判断是否抵达奖励的过程就称为「验证器」(verifier)。William Brown 的新开源库 Verifier 就是专门为此设计的工具。目前的验证器更倾向于针对数学公式或代码这样的明确结果进行验证。然而,正如 Kalomaze 所证明的,即使针对非严格验证的结果,通过训练专门的分类器,也完全可以构建有效的验证器。这得益于语言模型的一个重要特点:它们评估答案的能力远远优于创造答案的能力。即使用规模较小的语言模型来做「评委」,也能明显提高整体性能和奖励机制的设计效果。
- LLM 智能体的训练是通过「草稿」(draft)来完成的,即整个文本被生成后再被评估。这种方式并不是一开始就确定的,最初研究倾向于对每个单独的词汇(token)展开搜索。但后来由于计算资源有限,以及近期推理(Reasoning)模型取得突破性的进展,「草稿式」推理逐渐成为主流训练方式。典型的推理模型训练过程,就是让模型自主生成多个逻辑步骤,最终选择那些能带来最佳答案的草稿。这可能会产生一些出人意料的现象,比如 DeepSeek 的 R0 模型偶尔在英文与中文之间突然切换。但强化学习并不在乎看起来是不是奇怪,只在乎效果是否最好。就像在迷宫里迷路的智能体一样,语言模型也必须通过纯粹的推理寻找出路。没有人为预定义的提示,没有提前规定好的路线,只有奖励,以及获得奖励的方法。这正是苦涩教训所给出的苦涩解决方案。
- LLM 的草稿通常会被提前划分为结构化的数据片段,以方便奖励的验证,并在一定程度上帮助模型整体的推理过程。这种做法叫做「评分标准工程」(rubric engineering),既可以直接通过奖励函数来实现,也可以在大实验室更常见的方式下,通过初步的后训练阶段完成。
- LLM 智能体通常需要大量草稿数据以及多阶段训练。例如,当进行搜索任务训练时,我们不会一下子评价搜索结果,而是评价模型获取资源的能力、生成中间结果的能力、再获取新资源、继续推进、改变计划或回溯等等。因此,现在训练 LLM 智能体最受青睐的方法是 DeepSeek 提出的GRPO,特别是与 vllm 文本生成库配合时效果最佳。前几周,我还发布了一个非常受欢迎的代码笔记本(Notebook),基于 William Brown 的研究成果,仅使用 Google Colab 提供的单个 A100 GPU,就成功地实现了 GRPO 算法。这种计算资源需求的大幅下降,毫无疑问将加速强化学习与智能体设计在未来几年真正走向大众化。
08 等一下,这东西怎么规模化?
上面说的那些内容都是基础模块。从这里出发,想走到 OpenAI 的 DeepResearch,以及现在各种新兴的、能处理一连串复杂任务的智能体,中间还隔着一段距离。允许我稍微展开一点联想。
目前,开源社区的强化学习(RL)和推理研究,主要集中在数学领域,因为我们发现网上有很多数学习题的数据,比如一些被打包进 Common Crawl 里的题库,再被 HuggingFace 的分类器抽取出来(比如 FineMath)。但是,很多其他领域,特别是「搜索」,我们是没有现成数据的。因为搜索需要的不是静态的文本,而是真实的行动序列,比如用户浏览网页时的点击、查询日志、行为模式等等。
我之前做过一段时间的日志分析,当时模型(尽管还是用马尔科夫链这种比较老旧的方法,虽然最近几年这个领域飞速发展了)居然还经常用上世纪 90 年代末泄露出来的 AOL 搜索数据训练!近来,这个领域终于多了一个关键的开源数据集:维基百科的点击流数据(Wikipedia clickstream),这个数据集记录了匿名用户从一篇维基百科文章跳到另一篇文章的路径。但我问你一个简单的问题:这个数据集在 HuggingFace 上有吗?没有。事实上,HuggingFace 上几乎没有真正具备「行动性」(agentic)的数据,也就是说,这些数据能帮助模型学习规划行动。目前整个领域依然默认要用人工设计的规则系统去「指挥」大语言模型(LLM)。我甚至怀疑,连 OpenAI 或者 Anthropic 这种大厂,也未必能拿到足够数量的这种数据。这是传统科技公司,尤其是谷歌这样的公司,依然占据巨大优势的地方——毕竟,你不可能随便买到谷歌积累的海量用户搜索数据(除非数据在暗网上泄露了某些片段)。
但其实有一种解决办法,就是模拟生成数据,也就是「仿真」。传统的强化学习模型是不需要历史数据的,它们通过反复不断的尝试,探索并学会环境里的各种规律和策略。如果我们把这种方式用到搜索任务上,就会类似于游戏领域的 RL 训练:让模型自由探索,找到正确答案时给奖励。可是,在搜索领域,这种探索可能会非常漫长。比如你想找到某个特别冷门的化学实验结果,可能隐藏在 1960 年代某篇苏联老论文里,模型只能靠暴力搜索和语言上的一些微调,一次又一次地尝试后终于偶然找到了答案。然后,模型再尝试理解并总结出那些能提高下次找到相似答案可能性的规律。
我们算一下这种方式的成本:以一种典型的强化学习方法为例,比如 GRPO,你一次可能同时有 16 个并发的探索路径(我甚至猜测大实验室的真实训练并发数远不止 16 个)。每个探索路径都可能连续浏览至少 100 个网页,那意味着一次小小的训练步骤里就要发出大概 2,000 次搜索请求。而更复杂的强化学习训练,往往需要数十万甚至上百万个步骤,尤其是想让模型拥有通用的搜索能力的话。这意味着一次完整训练可能需要数亿次的网络请求,说不定会把一些学术网站顺便给 DDOS 攻击了……这样一来,你真正的瓶颈反倒不再是计算资源,而变成了网络带宽。
游戏领域的强化学习也碰到了类似的问题,这也是为什么现在最先进的方法(比如 Pufferlib)会把环境重新封装成「对模型而言看起来像雅达利游戏的样子」,其实本质没变,只不过模型能看到的数据是高度标准化的、经过优化的。当把这个方法应用到搜索上时,我们可以直接利用现成的 Common Crawl 大规模网络数据,把这些数据「伪装」成实时的网页返回给模型,包括 URL、API 调用和各种 HTTP 请求,让模型误以为它正在真实地访问网络,而实际上所有数据早就提前准备好了,直接从本地的高速数据库里查询就可以了。
所以,我估计未来要训练一个能够搜索的 LLM 强化学习智能体,可能的方式会是这样的:
- 先创建一个大型的模拟搜索环境,这个环境的数据集是固定的,但在训练时不断「翻译」成模型能理解的网页形式反馈给模型。
- 在强化学习正式训练之前,先用一些轻量的有监督微调(SFT)给模型「预热」一下(类似 DeepSeek 的 SFT-RL-SFT-RL 这种训练路线),用的可能是一些已经有的搜索模式数据,目的是让模型提前熟悉搜索思考的逻辑和输出格式,从而加速后面的 RL 训练。这类似一种人为设定好的训练「模板」。
- 然后,需要准备一些难度不同的复杂查询问题,以及对应的明确的验证标准(verifier)。具体操作可能是搭建复杂的合成数据管道,从现有资源反向推导出这些标准,或者干脆直接雇佣一批博士级别的专家来手动打标签(代价非常高昂)。
- 接下来就是真正的多步强化学习训练了。模型收到一个查询后,会主动发起搜索,得到结果后,可以进一步浏览网页,或者调整搜索关键词,这个过程是分成多个连续步骤的。从模型角度来看,就像是在真实地浏览互联网,而实际上背后的一切数据交换都是提前准备好的搜索模拟器在完成。
- 当模型足够擅长搜索之后,可能还会再做一轮新的强化学习(RL)和监督微调(SFT),但这一次的重心转向「如何写出高质量的最终总结」。这步很可能也会用到复杂的合成数据管道,让模型将之前输出的长篇内容切成小片段,再经过某种推理重新组装起来,提升它生成结果的质量和逻辑连贯性。
09 真正的智能体,是不靠「提示词」工作的
终于,我们真正拥有了「智能体」(Agent)模型。那么相比原本的工作流程或模型编排来说,它到底带来了哪些变化?只是单纯提高了质量,还是意味着一种全新的范式?
我们先回顾一下 Anthropic 对智能体的定义:「大语言模型(LLM)智能体能动态地自主指挥自己的行动和工具使用,并始终掌控完成任务的具体方式。」为了更直观地理解这一点,我再用一个我熟悉的场景举个例子:搜索。
之前业内曾广泛猜测,随着大语言模型拥有了更长的上下文窗口,传统的「检索增强生成」(RAG)方法会逐渐消亡。但现实情况并非如此。原因有几个:超长上下文计算成本太高,除了简单的信息查询外,准确性不够,并且很难追溯输入的来源。因此,真正的「智能体搜索」并不会完全取代 RAG。更可能发生的是,它会高度自动化,帮我们把复杂的向量数据库、路由选择、排序优化等过程自动整合。未来一个典型的搜索过程可能会是这样的:
- 用户提出问题后,智能体会分析并拆解问题,推测用户的真实意图。
- 如果问题模糊,智能体会主动向用户提问,以便进一步确认(OpenAI 的 DeepResearch 已经能做到这一点)。
- 然后,模型可能会选择进行一般性搜索,也可能根据情况直接选择特定的专业数据源。由于模型记住了常见的 API 调用方式,它可以直接调用对应的接口。为了节约计算资源,智能体会更倾向于利用网络上已有的 API、站点地图(sitemaps)以及结构化的数据生态。
- 搜索过程本身会被模型不断学习和优化。智能体能够自主判断并放弃错误的搜索方向,并像经验丰富的专业人员一样,转而尝试其他更有效的路径。目前 OpenAI 的 DeepResearch 一些非常惊艳的结果就展示了这种能力:即便某些资源没有被很好地索引,它也能通过连续的内部推理找到准确的资源。
- 整个搜索过程中,智能体的每一步决策和推理都会留下清晰的内部记录,从而实现一定程度的可解释性。
简单来说,搜索过程将会被智能体直接「工程化」。智能体不需要额外的数据预处理,而是直接基于现有搜索基础设施去灵活应变,寻找最佳路径。同时,用户也无需专门训练就能与生成式 AI 高效交互。正如 Tim Berners-Lee 十多年前所强调的:「一个真正的智能体,就是在每个具体场景中,都能自动完成用户心里想做却没明确说出来的事情。」 我们再将这种实际的智能体思路应用到其他领域去看一下实际效果:比如一个网络工程智能体,也将能直接与现有基础设施交互,自动生成路由器、交换机、防火墙的配置方案,根据需求分析网络拓扑结构、给出优化建议,或自动解析错误日志,定位网络问题的根本原因。
再比如金融领域的智能体,未来则能够自动、精准地实现不同金融数据标准之间的转换,比如从 ISO 20022 到 MT103 标准的翻译。以上这些能力,现阶段通过简单的系统提示(system prompts)是根本做不到的。
然而,目前能够真正开发出这样智能体的公司只有少数几个巨头实验室。他们手握所有关键资源:专有技术、部分关键数据(或者制造这些数据的合成技术),以及将模型变成产品的整体战略眼光。这种技术高度集中未必是一件好事,但某种程度上,也要归咎于资本市场对模型训练长期价值的低估,使得这一领域的创新发展受到限制。
我通常不喜欢过度炒作某些新概念,但智能体背后蕴藏的巨大颠覆潜力和商业价值,让我坚信我们迫切需要民主化地推动实际智能体的训练和部署:公开验证模型、GRPO(目标导向的奖励策略优化)的训练数据样本,以及在不久的将来,公开复杂的合成数据管道和仿真器等基础设施。
2025 年会是智能体崛起的一年吗?或许还有机会,我们拭目以待
#谷歌Gemini Live上新功能
能看懂手机屏幕、还能实时视频
好消息,谷歌在 MWC 上关于 Project Astra 与 Gemini Live 集成的承诺兑现了。
刚刚,谷歌发言人 Alex Joseph 在给 The Verge 的邮件中确认,谷歌已经开始向 Gemini Live 推出新的 AI 功能,能够共享用户的手机屏幕或者通过智能手机摄像头回答相关问题。这对于实时人工智能交互来说是一个重大进步。
这些功能的推出距离谷歌首次展示「Project Astra」项目已经过去一年时间。
有 Reddit 用户表示自己已经率先体验到了屏幕共享功能,该功能通过一个名为「Share screen with Live」的新按钮来实现。

这位用户还发布了一段视频来证明。
通过视频我们可以看出 Gemini 根据用户共享的屏幕,回答出了今天的日期、温度等信息。
另外,Gemini Live 推出的另一项功能是实时视频功能,它可以让 Gemini 实时解读你手机摄像头的画面,并回答相关问题。
效果如何,我们通过示例来感受一下。在谷歌本月发布的一段演示视频中,用户使用该功能向 Gemini 求助,他们上釉的陶器选择什么颜色的颜料最合适。
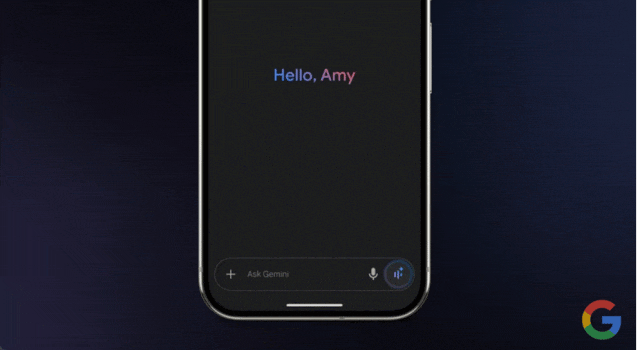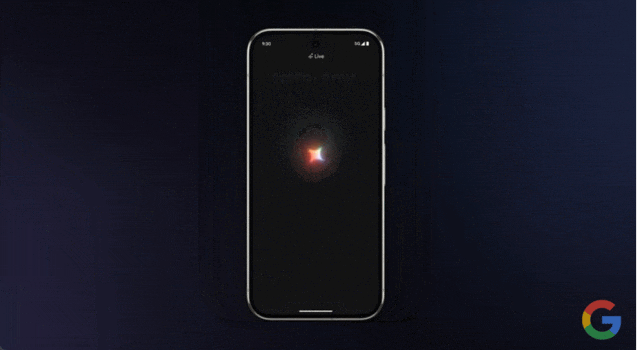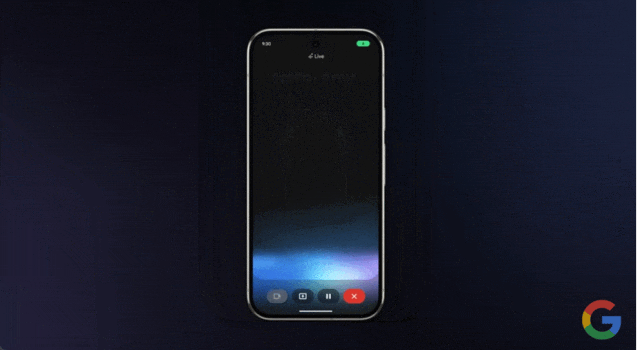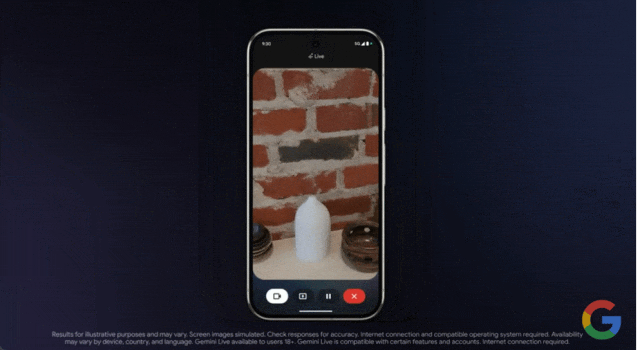
只见用户打开手机摄像头,对准物体进行实时拍摄,然后询问这些釉料中哪一种最适合?
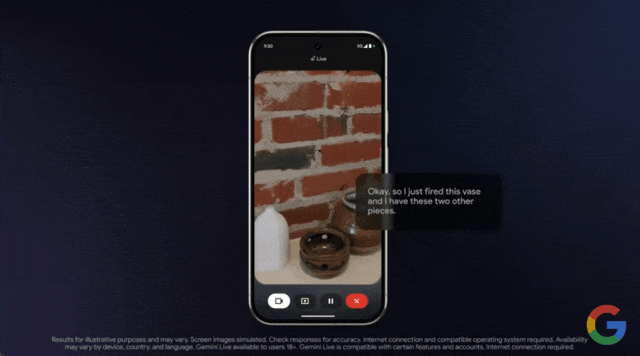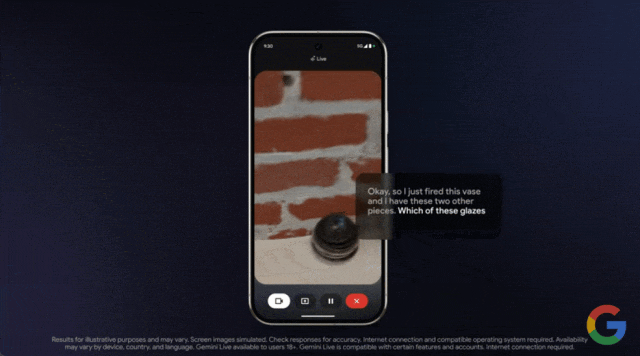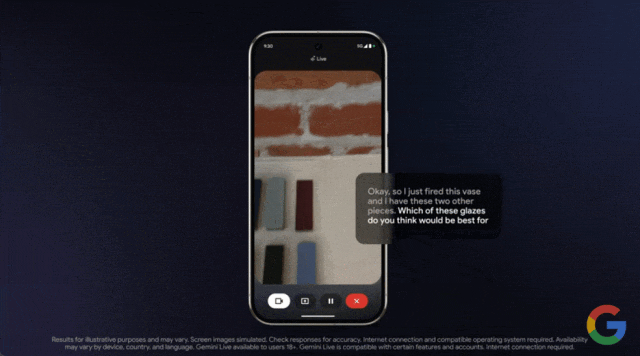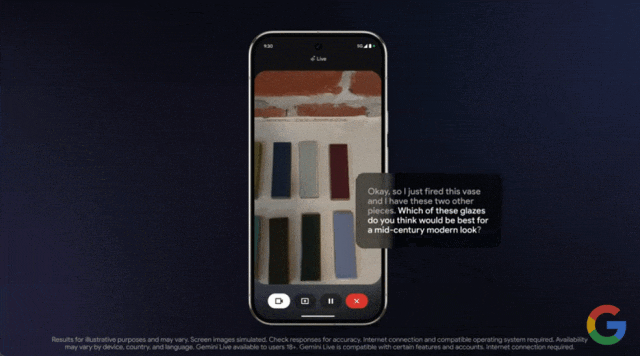
几乎是毫无延迟的 Gemini 给出了回答:

一个问题回答完毕后,你也可以继续追问,Gemini 都能对答如流
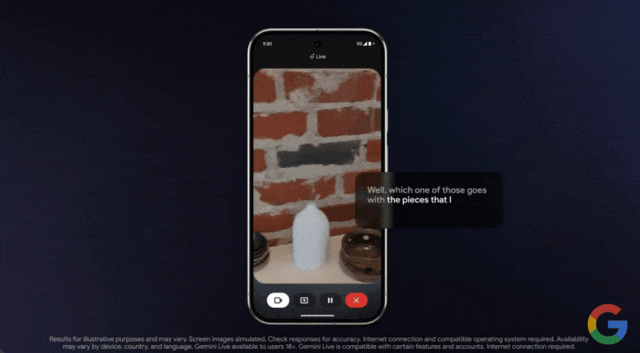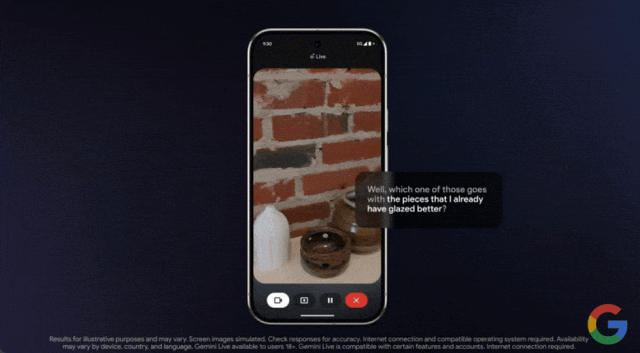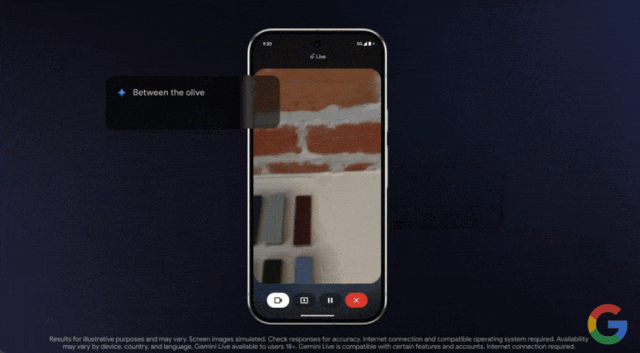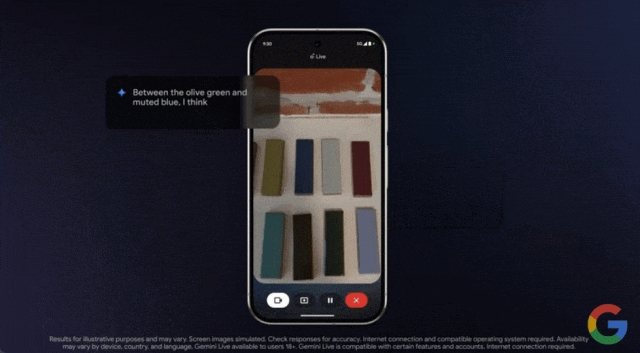
Project Astra 是谷歌去年发布的 AI 智能体项目,用户通过摄像头,可以与大模型进行实时的视觉与语音交互,也是谷歌对标 GPT-4o 的又一项重要研究。
Project Astra 有三个特点:
- 实时对话可以进行实时音频和视频对话,低延迟,还掌握多种语言。
- 记忆:通过记住过去对话的关键细节以及当前会话中最多 10 分钟的内容来完善其回答。
- 工具调用:提出问题后,Project Astra 可以使用谷歌搜索、地图等来提供答案。

此外,Project Astra 还可以跨设备工作,用户可以在安卓手机或原型眼镜上使用 Project Astra 功能。

视频对话功能并非新概念。最早公开演示 AI 视频通话的 OpenAI,则在去年 12 月底就在自家产品上线了对应能力:在 ChatGPT 的移动端应用程序 App 中,高级语音模式 Advanced Voice 提供了视频和共享屏幕功能。目前该功能还没有免费开放,也是 Plus 用户和 Pro 用户才能使用。
谷歌此时推出这些功能,至少证明了 Gemini 在努力保持人工智能助手领域的「前排」地位。
与之形成鲜明对比的是,苹果推迟了 Siri 的升级。彭博社前几天报道,一份 Siri 团队内部会议的记录显示,我们期待的 Apple Intelligence 仍遥遥无期。
会议由负责该部门的高级主管 Robby Walker 主持。他称此次延迟是一个「糟糕的」情况,并同情那些可能因苹果的决定和 Siri 仍然不佳的声誉而感到疲惫或沮丧的员工。
Robby Walker 还表示,承诺过的 Siri 功能不一定会在今年出现在 iOS 19 中:「这是该公司目前的目标,但并不意味着我们会在那时推出。」
近几周,苹果一直无法摆脱有关其在 Siri 和人工智能方面进展缓慢的负面新闻。去年 6 月承诺过的高级智能功能至今无法兑现。几个月过去了,除了更漂亮的 Siri 动画外,几乎没有任何成果。
除此之外,苹果尚未公开评论此事。当时该公司表示,高级 Siri 功能「比预期耗时更长」。但 Robby Walker 告诉员工,公司的软件主管、人工智能主管等高管正在为这一困境承担「个人责任」,然而这一困境引发了广泛的、激烈的批评。
这些功能对于 Siri 的现代化、苹果在人工智能竞赛中的追赶其实非常重要。我们仍然不知道这些 Apple Intelligence 功能何时会到来。似乎,从最近这次全体会议的讨论内容来看的话,苹果本身也不知道。
参考链接:
https://www.theverge.com/news/629940/apple-siri-robby-walker-delayed-ai-features
#SeeGround
Qwen让AI「看见」三维世界,SeeGround实现零样本开放词汇3D视觉定位
3D 视觉定位(3D Visual Grounding, 3DVG)是智能体理解和交互三维世界的重要任务,旨在让 AI 根据自然语言描述在 3D 场景中找到指定物体。
具体而言,给定一个 3D 场景和一段文本描述,模型需要准确预测目标物体的 3D 位置,并以 3D 包围框的形式输出。相比于传统的目标检测任务,3DVG 需要同时理解文本、视觉和空间信息,挑战性更高。


之前主流的方法大多基于监督学习,这类方法依赖大规模 3D 标注数据进行训练,尽管在已知类别和场景中表现优异,但由于获取 3D 标注数据的成本高昂,同时受限于训练数据分布,导致它难以泛化到未见过的新类别或新环境。为了减少标注需求,弱监督方法尝试使用少量 3D 标注数据进行学习,但它仍然依赖一定数量的 3D 训练数据,并且在开放词汇(Open-Vocabulary)场景下,模型对未见物体的识别能力仍然受限。
最近的零样本 3DVG 方法通过大语言模型(LLM)进行目标推理,试图绕开对 3D 训练数据的需求。然而,这类方法通常忽略了 3D 视觉细节,例如物体的颜色、形状、朝向等,使得模型在面对多个相似物体时难以进行细粒度区分。这些方法就像让 AI “闭着眼睛” 理解 3D 世界,最终导致模型难以精准定位目标物体。
因此,如何在零样本条件下结合视觉信息与 3D 空间关系,实现高效、准确的 3DVG,成为当前 3D 视觉理解领域亟待解决的问题。

为此,来自香港科技大学(广州)、新加坡 A*STAR 研究院和新加坡国立大学的研究团队提出了 SeeGround:一种全新的零样本 3DVG 框架。该方法无需任何 3D 训练数据,仅通过 2D 视觉语言模型(VLM)即可实现 3D 物体定位。其核心创新在于将 3D 场景转换为 2D-VLM 可处理的形式,利用 2D 任务的强大能力解决 3D 问题,实现对任意物体和场景的泛化,为实际应用提供了更高效的解决方案。
SeeGround 已被 CVPR 2025 接收,论文、代码和模型权重均已公开。
- 论文标题:SeeGround: See and Ground for Zero-Shot Open-Vocabulary 3D Visual Grounding
- 论文主页:https://seeground.github.io
- 论文地址:https://arxiv.org/pdf/2412.04383
- 代码:https://github.com/iris0329/SeeGround
SeeGround:用 2D 视觉大模型完成 3D 物体定位
如图所示,SeeGround 主要由两个关键模块组成:透视自适应模块(PAM)和融合对齐模块(FAM)。PAM 通过动态视角选择,确保 VLM 能够准确理解物体的空间关系;FAM 则通过视觉提示增强技术,将 2D 图像中的物体与 3D 坐标信息对齐,提升定位精度。

透视自适应模块(Perspective Adaptation Module, PAM)
在 3D 物体定位任务中,直接使用一个固定视角将 3D 场景渲染为 2D 图像(如俯视图)虽然能提供物体的颜色、纹理等信息,但却存在一个关键问题 ——VLM 本质上是基于平面的视觉感知模型,它只能 “看到” 图像中的物体,而无法推理 3D 物体的空间位置,比如前后、左右关系。
因此,如果描述中涉及相对空间位置(如 “桌子右边的椅子”),VLM 很可能误判。例如,在俯视视角下,桌子和椅子的相对位置可能会因透视投影而发生变化,原本在桌子右边的椅子可能会被误认为在左边,而 VLM 只能依赖 2D 图像中的视觉特征,无法推断物体在三维空间中的实际位置。直接使用固定视角渲染的 2D 图像作为输入,会导致模型在涉及空间位置关系的任务上表现不佳。

为了解决这个问题,SeeGround 设计了一个动态视角选择策略,先解析用户输入的文本,识别出描述中涉及的锚定物体(anchor object),即用于参考空间关系的对象。随后,系统根据锚定物体的位置计算最佳观察角度,调整虚拟摄像机,使其从更符合人类直觉的角度捕捉场景,确保 VLM 可以准确理解物体的空间关系。最终,SeeGround 生成一张符合查询语义的 2D 图像,该图像能够更清晰地呈现目标物体与其参考物体的相对位置,使 VLM 具备更强的 3D 关系推理能力。这一策略不仅提高了 VLM 在 3D 物体定位任务中的准确率,同时也避免了因固定视角导致的方向性误判和遮挡问题,使得零样本 3DVG 任务在复杂环境下依然具备稳定的泛化能力。
融合对齐模块(Fusion Alignment Module, FAM)
透视自适应模块(PAM)能够为 VLM 提供更符合任务需求的观察视角,但即使如此,VLM 仍然面临一个关键挑战:它无法直接推理 3D 物体的空间信息,也无法自动对齐 2D 渲染图中的物体与 3D 位置描述中的物体。
SeeGround 将 3D 场景表示为 2D 渲染图像 + 文本 3D 坐标信息,然而,当 VLM 看到 2D 渲染图像时,它并不知道图中的椅子对应的是哪个 3D 坐标。这意味着,如果场景中有多个相似物体(如多把椅子),VLM 可能会误解 2D 图像中的目标物体,导致错误的 3D 预测。

SeeGround 通过视觉提示增强(Visual Prompting) 技术,在 2D 渲染图像中标注出关键物体的位置,使 VLM 能够识别出 2D 画面中的具体目标物体,并将其与 3D 坐标数据关联。
首先,SeeGround 使用对象查找表(Object Lookup Table) 来获取场景中的所有物体的 3D 坐标。然后,使用投影技术将 3D 物体的空间位置转换为 2D 图像中的对应位置,并在渲染图像上添加可视化标注,以便 VLM 在推理时能够准确识别出目标物体。同时,在文本描述输入部分,SeeGround 进一步增强了 3D 物体的空间描述,使 VLM 在推理时能够结合 2D 视觉特征和 3D 坐标信息,从而准确匹配目标物体。
实验结果
为了验证 SeeGround 在零样本 3D 视觉定位(3DVG)任务中的有效性,作者在 ScanRefer 和 Nr3D 数据集上进行了广泛的实验。结果表明,SeeGround 在多个基准测试中显著超越了现有零样本方法,并在某些任务上接近弱监督甚至全监督方法的性能。

此外,在对比实验中,即使去除部分文本信息,SeeGround 仍然能够利用视觉线索进行准确定位,进一步验证了该方法在不完全信息条件下的稳健性。
作者专门设计了一个场景,即让模型在文本描述缺失关键物体信息的情况下,尝试定位目标物体:在 “请找到打印机上方的柜子” 这一查询任务中,文本输入被刻意去除了 “打印机” 和 “柜台” 等关键信息,仅提供物体类别及其位置信息。

在这种情况下,仅依赖文本推理的 LLM 由于无法获取必要的上下文信息,错误地匹配到了错误的柜子。而 SeeGround 通过 VLM 结合视觉信息成功识别出图像中的打印机,并准确定位其上方的柜子。
这一特性进一步提升了 SeeGround 在复杂现实环境中的适用性,使其能够在 3D 物体定位任务中表现出更强的稳健性和泛化能力。

结论
SeeGround 通过无需 3D 训练数据的创新设计,成功解决了现有零样本方法在视觉细节和空间推理上的不足,显著提升了 3DVG 任务的泛化能力。这一突破为增强现实、机器人导航和智能家居等领域提供了更高效、灵活的 3D 物体定位方案。
作者介绍
SeeGround 是香港科技大学(广州)、新加坡 A*STAR 研究院和新加坡国立大学团队的合作项目。
本文的第一作者为港科广博士生李蓉,通讯作者为港科广 AI Thrust 助理教授梁俊卫。其余作者包括新加坡国立大学博士生孔令东,以及 A*STAR 研究院研究员李仕杰和 Xulei Yang。
#UFO
统一细粒度感知!北大&阿里提出:无需SAM,16个token让MLLM实现精准分割
本文作者来自北京大学和阿里通义万相实验室。其中论文第一作者是汤昊,北京大学 2022 级博士生,目前主要关注统一的多模态任务建模算法。指导教授是王立威老师,北京大学智能学院教授,曾获 NeurIPS 2024 最佳论文奖、ICLR 2023 杰出论文奖及 ICLR 2024 杰出论文提名奖。
无需 SAM 和 Grounding DINO,MLLM 也能做分割和检测!统一细粒度感知的多模态大模型 UFO 来了!
- 论文标题:UFO: A Unified Approach to Fine-grained Visual Perception via Open-ended Language Interface
- 论文链接:https://arxiv.org/abs/2503.01342
- 开源代码:https://github.com/nnnth/UFO
- 开源模型:https://huggingface.co/kanashi6/UFO
具体来说,UFO 提出了一种基于特征检索的分割方法,将分割任务重新定义为计算 token 特征和图像特征的相似度,无需 SAM,最多仅需输出 16 个 token 即可实现 MLLM 的精细分割。UFO 还支持文本格式的目标框输出,通过并行解码高效支持密集检测和分割。

背景介绍
多模态大模型(MLLM)统一了视觉-语言任务,但在细粒度感知任务中(如检测、分割)仍依赖任务解码器(如 SAM、Grounding DINO),结构和训练非常复杂。
基于文本的方法采用粗糙的多边形表示,表达能力不足,且在密集场景(如 COCO 数据集)中性能不佳。因此,亟需开发无需额外解码器、与视觉-语言任务统一且性能优异的细粒度感知方法。
为此,研究团队提出了基于特征检索的方式来支持分割:模型通过预测<MASK>标记,计算其特征与图像特征的相似度实现分割。
这种方式有效地挖掘了多模态大模型的图像表征能力。研究团队认为,既然多模态大模型可以回答物体的类别和位置,那么图像特征中已经包含物体的分割信息。
对于检测任务,UFO 将目标框转换成文本格式的坐标,使得检测和分割的任务输出都可以通过文本统一。
针对密集感知场景,研究团队提出了一种并行解码策略,将多个预测拆分成多个单目标的子任务,通过局部图像特征进行区分。这种方式可以大大简化任务难度,同时加速推理。
方法细节

基于特征检索的分割方式
在执行分割时,模型被训练输出<MASK>标记,如上图(a)所示。给定输入图像
![]()
和分割提示
![]()
,模型生成文本响应
![]()
以及相应的文本特征
![]()
和图像特征
![]()
:
![]()
从
![]()
中提取与<MASK>标记对应的掩码标记特征
![]()
。然后通过缩放点积计算掩码标记特征
![]()
与图像特征
![]()
之间的相似性。检索正分数以形成二值掩码
![]()
。该过程表示为:

其中 d 是特征维度,
![]()
表示相似性分数,
![]()
是指示函数,将相似性分数转换为二值掩码。
通过多个掩码标记上采样
在上述方法中,相似度使用下采样的图像特征计算,导致生成的掩码分辨率低。
为此,研究团队提出了一种通过预测多个掩码标记进行上采样的方法。
给定图像
![]()
,下采样后的图像特征为
![]()
,模型需要自回归地预测
![]()
个<MASK>标记,其特征表示为

。每个标记对应于 NxN 上采样网格中的一个位置,如上图(b)所示。
对于每个掩码标记特征
![]()
,计算其与视觉特征
![]()
的相似性,得到

然后,这些分数被连接并重塑为上采样后的相似性图:

最后在
![]()
中检索正分数,以生成上采样后的二值掩码

。默认情况下,N 设置为 4,预测 16 个<MASK>标记,这将输出掩码上采样 4 倍。
多任务数据模版

对于单一预测的任务,任务模板为:<Text Prompt><Image><Text Response>。
对于多预测任务,比如目标检测和实例分割,UFO 将其拆分为多个单一预测的独立子任务,使得他们能在同一个批处理内并行。模板结构是:<Text Prompt><Image><Local><Text Response>。其中<Local>指局部图像特征,作为局部视觉提示,用于区分不同子任务。
如上图右侧所示,UFO 在整个图像上均匀采样网格点,并在每个网格位置插值局部图像特征。每个网格点预测最近的目标,如果没有则预测结束标记。
实验结果
多任务训练

UFO 在 GiT 提出的多任务基准上取得显著提升,在 COCO 实例分割上相比 GiT-H 提升 12.3 mAP,在 ADE20K 语义分割上提升 3.3 mIoU。
视觉定位

无需任务解码器,UFO 在引用表达式理解(REC)和分割(RES)两种任务展现出优越的性能。
推理分割

推理分割要求模型进行深层推理得出分割目标,更加困难。UFO 可以深度融合文本推理和分割能力,性能超过基于 SAM 的 LISA。
视网膜血管分割

视网膜血管形状不规则且狭窄,难以用多边形表示。UFO 在 DRIVE 上进行了训练,取得了 77.4 的 Dice 系数,验证了在极细粒度结构上的有效性。
深度估计

UFO 可以用类似分割的方式支持深度估计,取得具有竞争力的性能。
可视化结果
UFO 可以适应任意数量的预测和任意形式的描述。

采用 4 个<MASK>标记时,每个掩码标记能捕捉不同细节,使得融合的掩码更精细。

结论
UFO 提出了一种统一的细粒度感知框架,通过开放式语言界面处理各种细粒度的视觉感知任务,无需修改架构即可在多模态大模型上实现出色的性能。
UFO 的核心创新是一种新颖的特征检索方法用于分割,有效利用了模型的图像表征能力。
UFO 的统一方式完全对齐视觉-语言任务,提供了一种灵活、有效且可扩展的解决方案,以增强多模态大模型的细粒度感知能力,为构建更通用的多模态模型铺平了道路。
#Uni-Gaussians
小米汽车首曝自动驾驶研究:相机和LiDAR联合重建框架
论文的主要作者来自香港科技大学、小米汽车和华中科技大学。论文的共同第一作者为香港科技大学博士后研究员袁子康、小米汽车算法工程师蒲粤川、罗鸿城。论文作者还包括小米汽车世界模型负责人孙海洋。通讯作者是华中科技大学的教授杨欣。
在自动驾驶技术商业化落地的关键阶段,高质量仿真系统成为行车安全验证的核心基础设施。针对动态驾驶场景中相机与 LiDAR 联合仿真难题,Uni-Gaussians 提出一种基于统一高斯表征的分治渲染框架,实现精确性与计算效率的协同优化。
当前主流神经渲染方案存在显著局限性:
- 基于 NeRF 的方法虽能通过连续场景表征统一渲染相机图像与 LiDAR 点云,但其依赖密集采样的体渲染机制导致计算效率低下;
- 基于高斯溅射(Gaussian Splatting)的方法利用高斯基元实现场景表征,并通过光栅化(Rasterization)达成实时渲染,但其基于线性光学假设的渲染管线难以精确建模非线性光学传感器特性,导致该方法在针孔相机之外的传感器类型中应用受限。
为攻克上述挑战,来自香港科技大学、小米汽车和华中科技大学的研究团队提出了 Uni-Gaussians,实现了动态驾驶场景的高斯基元统一表征与分治渲染的架构。使用动态高斯场景图(Gaussian scene graph),建模静态背景与动态实体(如刚性车辆、非刚性行人)。图像数据采用光栅化(Rasterization)进行渲染,确保高帧率输出。LiDAR 数据则引入高斯光线追踪(Gaussian Ray-Tracing),精确模拟激光脉冲传播特性。该工作为自动驾驶场景下的相机与 LiDAR 数据提供的仿真方式,在质量与计算效率方面都取得了重大进展。
- 论文标题:Uni-Gaussians: Unifying Camera and Lidar Simulation with Gaussians for Dynamic Driving Scenarios
- 论文链接:https://arxiv.org/pdf/2503.08317
- 项目主页:https://zikangyuan.github.io/UniGaussians/
论文贡献
Uni-Gaussians 主要有以下贡献:
- 提出了一种统一、高效的仿真系统,能够利用高斯基元实现相机和激光雷达数据的联合重建。
- 实现了包含车辆、行人和骑车人在内的所有交通参与者的高质量 LiDAR 仿真。
- 通过大量的实验证明了统一的高斯表征和混合渲染方法的优势。

图一展示了最新 SOTA 方法 LiDAR4D 和该方法仿真结果的对比。相比之前方法,该方法可以准确地重建出各种可移动物体,包括行人和车辆。同时该方法对图像也可以进行高质量的重建。
方法概述

如图二所示,对于一个动态驾驶场景,该方法建立一个高斯场景图来进行解耦建模,其中包含静态背景和各种运动物体,例如刚性的车辆和非刚性的行人、骑车人。方法对整个场景进行相机和激光雷达同时的模拟。对于相机图像数据,方法采用 2D 高斯基元(2D Gaussian primitives)的栅格化渲染。对于激光雷达数据,计算高斯球和射线的交点并构建光线追踪来进行模拟,结合反射强度(SH intensity)与射线丢弃概率(SH ray-drop probability)建模 LiDAR 的主动感知机制。
实验结果
Uni-Gaussians 在 Waymo 公开数据集上进行了评估。针对激光雷达数据,该工作采用 Chamfer Distance 和 F-score 来进行点云几何精度评估。并使用 RMSE、MedAE、LPIPS、SSIM 和 PSNR 来评估雷达测距性能和反射强度质量。同时实验报告了渲染的耗时和存储占用量。对于相机图像渲染质量,则采用了 SSIM 和 PSNR 进行评估。
点云对比

表一,展示该方法和 lidar 仿真 SOTA 方法的定量比较。加粗为最优结果,加下划线为次优结果。和之前的 SOTA 方法相比,该方法在所有指标上均表现出卓越的性能。证明了这种联合仿真的优势。与 DyNFL 和 LiDAR4D 相比,该方法的 CD 指标分别降低了 40.9% 和 46.7%,同时渲染耗时和计算内存消耗也大幅降低。下面图 3 和图 4 展示可视化效果,该方法能够准确而精细地模拟动态驾驶场景中的各种类型的可移动实体,展现出明显优势。


图像对比


如表二所示,对于图像,该方法能保持高质量的渲染质量。此外该方法在新视角下也能表现出优越的泛化性能。
综上所述,Uni-Gaussians 通过统一的高斯表征和分治渲染的方法,实现了一套视觉和雷达点云的联合仿真框架。该工作在点云和图像上均展现出强大的仿真性能,兼顾高效率和高质量,为行业提供了一套优秀的解决方案。
#音乐界迎来自己的DeepSeek
全球首个音乐推理大模型Mureka O1上线,超越Suno
2025 年第一款现象级的 AI 音乐爆品,就这么华丽丽地来了!
国产大模型在技术实力上,又一次站在了世界前沿。
3 月 26 日,国内「All in AGI 与 AIGC」的科技公司 —— 昆仑万维,发布了最新音乐大模型 Mureka V6 和 O1,给全球音乐圈带来了不小的震撼。
,时长08:18
最值得关注的是,昆仑万维带来了全球首个引入 CoT 的音乐推理大模型 Mureka O1。在文本、视觉任务之外,「强推理、慢思考」的风终于吹到了音乐生成领域。
得益于生成过程中加入思考与自我批判能力,前者使得生成音乐的风格流派更符合用户预期、音乐整体结构和连贯性更强、旋律更好听,后者通过自动、客观的评分来验证生成曲风、结构和旋律的好坏。如此一来,Mureka O1 创作的音乐质量大幅度提高,达到了 SOTA 级别的生成效果。
在与 Suno V4 的直接较量中,Mureka O1 不仅丝毫不怵,还在主客观评测的多项指标上完成了超越。其中在主观评测中,Mureka O1 的整体听感超过了 Suno V4,人声(Vocal)、背景音乐(BGM)和混音(Mixing)质感明显超越了后者,并在配器丰富度(Instrumentation Richness)、作曲结构(Composition Structure)和旋律动机质量(Motif Quality)方面实现了显著提升。

对于客观评测,包括发音准确率、音乐片段连贯性、文本相关性以及包括内容享受度、内容可用度、制作复杂度在内的制作质量指标上,Mureka O1 相较于 Suno V4 均实现了不同程度的领先。


音乐质量更高的同时,生成速度同样更快了。从完整歌曲生成时长来看,Mureka O1 甚至要比 Suno V4 缩短了 1/2。

这意味着,随着思考能力的加入,AI 音乐生成在创作逻辑性与连贯性、创作自由度与个性化、情感表达、生成速度等多个方面迈入一个全新的阶段。
Mureka O1 依托的是昆仑万维此次升级的音乐生成基座模型 Mureka V6,不仅支持 10 种语言的歌词和歌曲生成,同时支持纯音乐生成、音色克隆等功能。可以说,国产 AI 音乐生成产品能玩的花样更多了。此外,Mureka V6 还创下了两个「全球前列」:
- 全球首批开放(五种)API 服务的高质量 AI 音乐生成平台。开发者和音乐平台可以将 Mureka 的音乐生成能力无缝集成到自家产品或平台中,加速 AI 音乐创作的应用并实现商业价值。
- 全球首个开放模型微调功能的 AI 音乐生成平台。用户借助 Mureka 基础模型可以训练符合自己需求的专属音乐模型,增强了 AI 音乐创作的灵活性和个性化,在满足具体音乐场景需求的过程中为音乐人、制作人乃至品牌和游戏开发者提供定制化的 AI 音乐解决方案。
目前,Mureka O1 和 Mureka V6 已经全面上线,感兴趣的小伙伴可以在 Mureka 官网体验。
Mureka 官网地址:https://www.mureka.ai
上手实测
AI 也有潜力成为神曲制造机
Mureka 的创作界面如下图所示,我们可以自由切换 Mureka V6 和 Mureka O1,选择最适合自己想要生成的音乐风格的模型版本。

我们首先测试了一番 Mureka V6。首次实现支持 10 种语言之外,Mureka V6 生成的人声更清晰、编曲更出色、歌词也更准确。
都说音乐无国界,但歌手的口音不标准非常影响歌曲听感,换成 Mureka,这个问题就完全不存在了。如此一来,全世界都能听到你灵感的回响。我们让 Mureka V6 根据同一段中文提示词创作中文、英文和日文歌,这是 Mureka V6 的答卷:
提示词:一首悠闲、梦幻的浪漫歌曲、适合跳舞,充满感染力的能量、强烈的节拍和歌词,歌词是关于春天、美好的生命,时间飞逝,珍惜春光的中 / 英 / 日文歌。
春之舞,2分钟
SpringtimeSerenade,2分钟
春の舞,2分钟
旋律清新,尤其是这首日文歌,不标明是 AI 生成,还以为是某个热播动漫的片头曲呢!
Mureka V6 的另一个亮点是支持生成纯音乐。

视频号每天都在面对一个刚需,要为视频添加 BGM 来丰富内容。输入提示词:「带有合成器音波的充满活力的电子流行音乐,适合科技向视频」,我们得到了这样的结果:
科技启航,2分钟
感觉 Mureka V6 生成的这首,质量丝毫不逊色于平时在无版权网站上精心挑选半天后选出的那首最佳 bgm。
加持了思考能力的 Mureka O1 就像是一个口袋里的专业音乐工作室。大部分 AI 生成的音乐都有几个通病:旋律特别简单,或者是听感奇怪的和弦凑够了时长,不符合歌曲的「起承转合」结构。
Mureka O1 的思维链能力为它注入了连贯的中间推理和决策步骤,赋予其生成更具深度和层次感的音乐的能力。与 V6 以及其他音乐生成模型相比,Mureka O1 的编曲更加丰富,旋律起伏自然,结构也更加合理,真正做到了「有理有据」的音乐创作。
它的操作简单到甚至不需要提示词,就能跳过歌词、编曲、录音和混音的复杂步骤,享受给自己写歌的乐趣。我们只需要选择简单模式,在输入框内输入想要的风格,或者点击右下角的骰子,随机摇出一些风格选项。

等待一下,就能得到一首听起来有望冲进 billboard 年度前 200 的抒情歌:
family memory,3分钟
当然,我们也可以切换到高级模式,输入歌词,再添加一些歌曲描述:


在别人还在用千篇一律的 bgm 发短视频的时候,用上 Mureka O1 的用户,每个想要记录的瞬间就拥有了量身打造的旋律:
坏猫之歌,1分钟
Mureka O1 不仅简化了复杂的音乐编辑任务,还保留了专业级的控制选项。无论你是经验丰富的音乐人,还是五线谱都看不懂的小白,它都能在你的工作流中上大分。
首先是参考歌曲功能。都说 AI 生图需要抽卡,其实 AI 作曲也一样,不是每次结果都能让人满意。
相比图像,单纯用语言更难描述出音乐的感觉,但插上耳机,听到重金属摇滚和 rap 之间的那段古典钢琴,我们就能立刻辨认出:「这就是周杰伦的感觉!」
Mureka O1 还支持上传歌曲,作为 AI 的创作参考,让我们的脑洞不再受技术限制。
想知道华语流行音乐天王为《APT》作曲会不会更高级?打开 Mureka O1 试试就知道了,操作也很简单。
第一步,先输入《APT》的歌词,再点击参考歌曲,上传周杰伦的一首代表作。在此,我们选择了《青花瓷》。


按下创作按钮,就可以静待中国风满满的《APT》出炉了。
APT,3分钟
听一下效果,编曲层次丰富,还设计了合声,就连困扰 AI 音乐生成已久的人声不清晰问题也解决了。人声质感更为自然,整体混音设计也更加到位。
此外,Mureka O1 充分考虑到了歌曲创作的自由度,我们可以右键点开菜单,选择局部重新生成或延长,延长 AI 灵感乍现的一瞬间。
编曲讲究「ABAAB」的结构,正好这首《春の踊り》前奏很不错,想延长几个小节来作「Intro」。我们不需要再跳转到音乐编辑软件中截取,就可以得到这样的效果了:
,时长00:39
作为全球首个正式开放五种 API 服务的音乐生成模型,Mureka 确实也是把探索深度拉满了。接入 API 后,就能在 Mureka 的基础上,微调专属音乐模型。音乐人、制作人、品牌和游戏开发者想要定制 AI 音乐,也更加自由和高效。
除了音乐,Mureka API 还支持日常对话,其中预置了多种音色,结合音色克隆技术,连播客节目也能自己做。
这波体验下来,我们最大的感受是:刚上手时,零基础也能轻松搞定专业效果;深入探索,成熟的工具链蕴含无限可能,人声的清晰度和旋律的听感都已经超越 Suno,神曲也可信手拈来。
CoT 思考能力加身
音乐生成迈入 O1 时代
在 AI 音乐生成中引入 CoT 思考能力,为什么会对生成的质量提升如此之大?从昆仑万维公开的技术报告以及对 Mureka 算法负责人 Max 的专访中,我们对 Mureka O1 的先进性有了深刻的洞见。
项目主页:https://MusiCoT.github.io/
在谈到为何要在音乐生成加入思考能力时,Max 表示,以前的音乐生成模型(比如自回归 AR 模型)更多采用的是类似语言大模型中的「下一个 token」预测范式,这不太符合人类音乐创作和制作的方式与过程。因此,虽然 AR 模型在高保真音乐生成中展现出了卓越的能力,但这种偏离人类创作模式的做法可能会限制生成结果的结构一致性和音乐性。
针对 AR 模型存在的局限性,昆仑万维打造出了一套与众不同的解法,以 MeLoDy 音乐生成框架为主干并受到语言建模中 CoT 提示技术的启发,为音乐生成量身打造了一种新颖的 CoT 提示词技术 —— MusiCoT。
不同于文本与视觉任务,音乐生成中引入思考能力需要克服一些不一样的技术难点,包括:1)连续复杂的音频信号输入、2)跨模态的文本输入到音频输出、3)高维特征的学习与高维数据的处理、4)音乐理论知识的融入以及 5)实时生成质量与速度的权衡。因此,为了在 AI 音乐生成中发挥作用,MusiCoT 针对这些难点做到了有的放矢,并形成了自己的技术优势。
利用 MusiCoT,AR 模型的生成范式发生了变化,引入了中间推理。模型可以先定义好整体音乐结构以及与生成作品相关的一些元素(比如风格、乐器等),然后再生成音频 token,从而更加贴合人类的创作模式。
同时,通过使用对比语言 - 音频预训练(CLAP)架构来定义音乐思维链,MusiCoT 在同一个空间中对文本与音频进行学习和训练,实现二者更强的匹配性,使音乐结构(如乐器编排)得到分析。基于这种思维链的可分析性,可以将推理到的 CLAP 特征与指定的文本进行空间上的距离分析,并让思维链过程中模型创作的曲风、乐器、调性等变得透明可知。
此外,MusiCoT 可以自然地为 AR 模型提供音乐参考功能,将输入的可变长度的音乐音频作为可选风格参考。一方面可以将参考歌曲变成 CLAP 中的音频嵌入,然后直接提取来替代要推理的思维链过程,这样跳过中间推理直接过渡到音频生成;另一方面引入残差矢量量化(RVQ)对音频向量信息进行量化处理,让音频信息更模糊,从而更容易规避直接抄袭的风险。最后,MusiCoT 相较于其他 CoT 方法实现了可扩展性并且可以不依赖人工标记的数据。
下图为原始 AR 音乐生成(上)与基于 MusiCoT 的 AR 音乐生成(下)流程对比,并以乐器编排为例说明。其中箭头的不同颜色表示相应乐器的不同强度,颜色越深、乐器强度越高,反之亦然。

接下来,我们将对 MusiCoT 的实现过程进行逐一分解,主要由以下三个阶段组成:
首先是将 CLAP 音频嵌入视为可分析的音乐思考。MusiCoT 并没有使用自然语言来描述音乐内容,而是提出使用对比训练的跨领域嵌入模型(即 CLAP)来表征中间音乐思考。具体来讲,CLAP 模型将每 10 秒的音乐音频编码为了一个连续值嵌入。因此,给定一首 3 分钟时长的典型歌曲,可以从 CLAP 中获得一个音频嵌入序列

并作为音乐思维链,其中每个嵌入都对应一段 10 秒的音乐片段。
其次是通过预测由粗放到精细的展平 RVQ 来实现更稳定的 MusiCoT 训练。建立音乐思维链之后,又出现了一个重大阻碍:由于 CLAP 音频嵌入为高维连续特征,典型训练目标(如均方误差损失、L1 损失和对比 infoNCE 损失)在音乐生成中皆效果不佳。
为了克服 MusiCoT 中的训练问题,昆仑万维设计了一种基于 RVQ 的粗放到精细 tokenization 方法,具体如下图所示。RVQ 模型由 L 个码本组成,而 RVQ token 以粗放到精细的顺序被展开以进行 LM 预测,较粗放的 token(靠前码本)总是在较精细的 token(靠后码本)之前预测。
不过,与传统 CoT 将复杂任务拆解为更小步骤不同,音乐生成需要作为一个整体来看待(因为任何一块的局部修改都可能影响整体的音乐性效果)。昆仑万维对中间音乐思考的定义满足了这一标准,每个 token 序列与生成的整体音乐片段实现了精确时间对齐。此外,L 个码本可以看作是 L 个粒度级别,生成这些中间 token 类似于从粗放到精细的方式来设计音乐结构。

在实际训练中,语义 LM 将展平 CLAP RVQ token 作为了额外的预测目标,如下图所示。与典型的 CoT 训练类似,这些预测的 token 采用了与音频 token 相同的处理方式,即用来计算交叉熵损失。唯一的区别是添加了两个新的特殊 token(<cot_bos> 和 < cot_eos>),以预测何时从生成 MusiCoT token 转换为音频 token。
根据 CLAP 嵌入的性质,预测的 RVQ token 可以在联合语言音频潜在空间中进行分析,因此可以检查音乐音频中每 10 秒片段的音乐特征。以乐器编排为例,通过计算生成嵌入与不同乐器的文本嵌入之间的余弦相似度,对乐器编排进行分析,从而了解不同乐器在生成的音乐中随时间切换的情况。

最后是 MusiCoT 的双重采样策略。在 MusiCoT 中,来自三个领域的 token,即文本 token、展平 CLAP RVQ token 和音频 token,被集成到了一个 LM 中。这引发了一个重要的采样策略问题:应该对后两种模型预测的 token 使用相同的采样方法还是采用不同的采样策略?
昆仑万维提出了两种新颖的 MusiCoT 采样配置。一个是双温度采样,选择温度值作为采样超参数对于提升语言模型性能至关重要,在音乐生成领域同样如此。MusiCoT 采用了双温度采样方法,即为语义 LM 配置了两组采样温度,一组用于采样展平 CLAP RVQ token,另一组用于采样音频 token。双温度采样的有效性得到了实验验证。
另一个是双尺度无分类器指导。无分类器指导(CFG)是扩散生成模型常用的一种方法,在 AudioGen 和 MusicGen 等语言建模中取得了成功。MusiCoT 设计了一种可以改变对数概率的双尺度采样策略,公式如下:

得益于以上技术先进性,MusiCoT 在主客观指标中持续产生出色的生成性能,实现了超越当前 SOTA 音乐生成模型的效果。
结语
去年 3 月,Suno V3 横空出世,成为一款现象级的 AI 音乐生成产品。用户可以使用简单的提示词创建从歌词、人声到伴奏的所有内容,一方面降低了音乐创作门槛,让门外汉也能体验一把当音乐制作人的乐趣;另一方面,专业音乐人开始探索将 AI 工具融入到音乐创作过程中,提升效率,推动 AI 在音乐领域的应用和发展。
此后,音乐大模型迈上了快车道,有实力的玩家开始在这个领域狂奔。在国内,昆仑万维入局非常早,并且拉开了与其他竞品厂商的差距。基于早期在音乐赛道上的积累,2024 年 4 月昆仑万维推出了 AI 音乐商用创作平台 Mureka V1,逐渐成长为了这条赛道的行业引领者。
截至目前,Mureka 访问用户遍布全球 100 多个国家和地区。并且,昆仑万维围绕 Mureka 形成了多样化的变现路径,包括 C 端用户付费、B 端合作、API 服务和模型微调能力。
此次推出的 Mureka V6 以及思考能力加身的 Mureka O1,在带来更高生成质量、更多样创作模式的同时,无疑会巩固昆仑万维在 AI 音乐生成领域的领先性,并进一步促进 AI 音乐创作的普及,为音乐产业带来了更多的创新和盈利机会。
未来,昆仑万维会继续加大在模型能力上的投入,让音乐大模型保持全球第一梯队。同时,依托 Mureka 基座模型可以期待更丰富的音乐功能,包括音乐生成的二次编辑、歌曲二创等。
当然,在持续优化和迭代 Mureka 功能之外,昆仑万维同样看重 AI 音乐创作的开发者生态与合作伙伴建设。如今的大模型竞争不再只是技术层面的较量,更是生态的比拼,更强大、更活跃的 AI 生态会助力降低开发门槛、加速各行业的深度应用落地和扩展商业模式,从而在市场竞争中立于不败之地。
在「实现通用人工智能,让每个人能够更好地表达自我」的使命驱使下, 昆仑万维近年来立足于「AI 前沿基础研究 —— 基座模型 ——AI 矩阵产品 / 应用」的全产业链,在 AIGC 创作领域积极布局,陆续推出了涵盖文本、视频和音乐等多个方面的创新产品。
AIGC 的美好想象正一步步走向现实。
最后来欣赏一段全网首发的《Mureka》AI 音乐人 MV,歌手为 Mureka。该作品由 AI 生成,其中音乐由 Mureka 生成,视频由 SkyReels 技术支持生成。
#为什么是梁文锋做出了DeepSeek?
正确的道路从来只有一条。
这是2025年开年最火的科技明星,短短几天时间,梁文锋从小到大的种种过往都被展现在世人眼前,包括他来不及装修的新房以及在房子里睡觉用的帐篷,都成为了他独特个性的象征。
独特个性固然为人津津乐道,但并不是成功的关键,这个籍籍无名的大学生,在过去的十几年中所能倚靠的,只有他的思想和能力。
所有人都好奇这样一个问题,为什么是梁文锋做出了DeepSeek?这其中固然有时代的因素,以及他本人迥异于其他大模型研究者的个人经历。但AI科技评论认为,理解梁文锋是个什么样的人,才是理解这个问题的关键。
1 找人才不需要标签
猎头都觉得,帮梁文锋的公司找人太不容易了。
一位从21年开始就与幻方深度合作的猎头告诉我们,招人招得让他“想哭”,因为难度太高了。
“清华本博,六篇顶会,你觉得肯定没问题了吧,哎,怎么简历直接挂了;一个清华本科的MIT博士,第二轮面试就被淘汰了。”
如果要在大厂内部找候选人,他认为,幻方和DeepSeek基本上不会对标国内公司,他们只会对标Google和Meta这样的海外大厂。
另外一位猎头一谈到DeepSeek也是忍不住头大,“太挑剔了,推过一个在字节绩效非常好的年轻中层,聊了之后没过。我就很奇怪,去问他们,给我的回答是,这个人对AI没有热情。人家都是做过一些AI Agent相关的项目了,一般是不太会说这样的评价的。”
梁文锋对人才没有标签,不论学历背景,不论过往业绩,他只看这个人的个人能力和个人素质。
极高的人才门槛,造就了如今的DeepSeek。在国内的大模型团队中,DeepSeek的人才厚度可能不足以跟顶尖公司相提并论,但是人才密度绝对可以说得上是第一档。
留住这些人才,除了DeepSeek的高薪酬外,还有充分尊重创意与idea的管理模式。“无固定团队、无汇报关系、无年度计划”与其说是管理,不如说是信任。《奈飞文化手册》一书曾经说过,“优秀的同事和艰巨的挑战是吸引人们来公司工作的最大因素”。对AI从业者而言,再没有比AGI更艰巨的挑战了。
做最难的事,就要找到最好的人,给出充足的资源与信任。得到信任的顶级人才往往会带来巨大的爆发力,这一理论可以在抖音崛起中得到印证。
在2018年春节期间,抖音日新增用户超过千万量级。一位负责增长的产品经理曾提及,这个增长项目完全没有绩效压力,而且向财务发了一封邮件,他的账户中就多出了上亿元的投放预算。他当时就意识到,“这样的团队,做啥打不赢呢?”
DeepSeek也是同理。被筛掉简历的人,一定不是学历问题;面试通不过,肯定也不是能力问题;人才的需求集中为一句话就是,这个人是可以被信任一同为AGI努力的人吗?
这就是DeepSeek的人才观,理解了这种人才观,就是理解梁文锋的第一步。
2 极简主义的价值观
尽管做了多年量化,但是梁文锋并不认为自己是个做金融的,他对自己的看法是,“我是做AI的,只不过做的是量化场景”。
几乎所有与梁文锋交流过的人,都说出他是一个不会受到外界干扰的人,“他的思维方式极其纯粹,特别注重第一性原理”,“说话很慢”,“一开口就切中要害”。
量化投资的特性恰好契合了他这种极简主义的风格——它不需要与复杂的上下游产业链打交道,只需专注于纯粹的市场数据。
时至今日,梁文锋依然常常沉浸在自己的技术世界中,专注于解决问题。比如做大模型这件事,他会告诉别人,“想清楚了就能干,只要有卡就行”,其他困难不在考虑范围之内。
对待金钱也是如此。钱就是用来投资,或者做慈善事业的,只要能花在合适的地方,亏损并不值一提。
2023年底,曾有一个旨在扶助聋哑人士的手语大模型项目,为了拉投资找到了梁文锋。梁文锋提出,这个项目的优点是公益性突出,缺点是市场规模有限,其中的隐患是,这是一个Top高校大学生团队的项目,他们可能不会长期坚持。
尽管极有可能得不到任何回报,他仍然提出,只要团队愿意继续推进项目,他就愿意投入。
过去梁文锋每年会拿出5亿元用于投资或慈善上,现在他把这笔钱花在了DeepSeek上。炒股是为了挣钱,投入大模型是为了AGI,仅此而已。
DeepSeek有将近两万张卡,他对算力极其慷慨,对上述的手语大模型团队,他就承诺过,算力集群会随时向他们开放。但是他又有点“小气”,对这近两万张卡的利用率要求很高,力求打满,不要空转。
这两种行为看似矛盾,如果按照极简主义的观点来解释,那就行得通了:卡的存在就是为了用的,能用尽用,万勿浪费。
3 不以商业化为限
没花一分钱投放费用,DeepSeek的App只用7天时间就得到了一个亿用户,对这一奇迹般的增长,梁文锋怎么看?
有投资人在春节期间专门问了梁文锋这个问题,但是梁文锋看起来对这么大的流量根本毫不在意,投资人得到的回答是,“这距离AGI的路还很远”。
这并不是梁文锋在故作姿态。据AI科技评论了解,DeepSeek只安排了两三个人负责App维护、对话网页开发、以及充值后台的管理工作。所以它不好用是正常的。
DeepSeek在B端市场的种种事迹,流传更广。比如此前他们的私有化部署定价仅为45万元,其中不仅包含一台H20或910b的使用权,还附赠大模型服务,使用期限为一年。而同样的价格,在华为云上仅仅只能租到 910b一年的使用权,这也就意味着 DeepSeek 的大模型近乎免费提供。
私有化部署不挣钱,DeepSeek也不在乎靠API挣不挣钱。一位对接DeepSeek的大厂员工吐槽它有一种“爱用不用”的气质,总是很难用,总是不调整。
再大的客户和调用量,都不值得另眼相看。一切大厂在高峰期都要排队,用户体验很差。大客户的反馈也很多,要求DeepSeek扩容扩容再扩容,至少回应流畅一些,不要两次请求就有一次失败,这种失败几乎不能忍受。
外界喧喧嚣嚣,不过梁文锋看起来并不是很在意这件事情。
这种情况应该如何解决?不少公司为此苦恼。根据一些内部流传出来的说法,梁文锋认为,大厂完全有能力自己想办法解决请求失败的问题,他们应该自己给自己兜底,而不是过度依赖 DeepSeek来保障服务。
这个回答简直要把人给气笑了。
可以说,现在的梁文锋不在乎商业化的一切可能。
在不少团队投入到应用的今天,梁文锋曾经跟一个好友说过,“你不要一直去看应用和行业落地的事情,你现在去看只能把你自己禁锢住了,因为没有到时候,现在想的一切都是错的。而且你在错误的路上你还投入了更多时间、精力和钱。”
这是对好友的忠告,也是自己的践行。将精力投入到应用上,投入到商业化上,对梁文锋来说,不论做什么,都是一条错误的道路。
而正确的道路从来只有一条,他现在已经走在了正确的道路上。
#AI框架缔造者或卖出数亿美金
贾扬清创业2年,老黄砸重金收购!
巨头英伟达,即将收购阿里前副总裁贾扬清的初创Lepton AI,交易价值或达数亿美元!而Lepton AI,仅仅创立两年。
就在刚刚,国内AI圈被这一消息刷屏了。
贾扬清成立两年的AI初创公司Lepton AI,即将被英伟达收购。
据外媒The Information报道,英伟达正在接近达成收购Lepton AI的协议,交易金额为数亿美元。
而Lepton AI的主要业务,就是专门出租由英伟达AI芯片驱动的服务器。
根据贾扬清介绍,在SemiAnalysis评选的neolcould解决方案中,Lepton AI是唯一一个没有重金采购GPU的公司。
因为他们采用的是云原生的多云解决方案,能让任何一家GPU提供商迅速升级。
为什么英伟达选择在此时重金收购Lepton AI?
原因是,亚马逊和谷歌这些老客户步步紧逼,英伟达被逼得实在没有办法了,不得不立刻转型!
老客户背刺,英伟达被迫转型
本来,亚马逊和谷歌都是英伟达的最大客户,但现在,它们纷纷通过开发、低价租赁替代芯片,来降低对英伟达的依赖。
这样导致的结果,就是英伟达的收入大幅减少。
而收购Lepton AI,是英伟达进军云计算和企业软件市场战略布局的一部分,目的就是为了和亚马逊、谷歌开战。
Lepton AI的总部位于加州,在租赁英伟达GPU服务器业务上,它和Together AI之类的初创公司是直接竞品。
注意,这些公司并不会自行管理数据中心或服务器,而是先从云服务提供商租用服务器,再租给自己的客户。
这个业务,利润空间就很大了。
据悉,Together AI如今已经实现了超过1.5亿美元的年化收入,换算一下,就是大概1250万美元的月收入。
这类企业,在业内被称为「推理服务提供商」或「GPU转售商」。
另外,他们的业务除了硬件租赁,还包括开发自己的软件平台,帮助其他初创公司或软件企业这类客户在云环境中构建和管理自己的生成式AI应用。
不过跟Together相比,Lepton AI的收入规模就没有那么大了。
他们AI云服务的主要客户,有游戏初创公司Latitude.io和科研初创公司SciSpace。前者使用使用Lepton AI来运行AI模型,支持一项月活用户已达数十万的服务。后者使用Lepton AI为学术论文搜索引擎提供技术支持。
总之外媒称,跟Together、Firewoks这些竞争对手相比,Lepton AI在市场上的形象总体比较低调。
被英伟达高价收购的Letpon AI,是何背景?
2023年7月,贾扬清离职阿里4个月后,新公司Letpon AI正式浮出水面。
这是一家专注于人工智能基础设施的公司,总部位于美国加利福尼亚州Palo Alto。Lepton AI这个名称源自物理学中的一种基本粒子——轻子。
公司曾于23年5月成立之前,完成了首轮1100万美元天使融资,由Fusion Fund、CRV领投。
当时,贾扬清在回复Pytorch之父评论中,曾提到还有两位联创与其一起创办了新公司,分别是ONNX创始人以及etcd的创始人。
此前,贾扬清最初在谷歌大脑担任研究科学家,还参与构建了部分支持Kubernetes的软件,Kubernetes是一个起源于谷歌的大规模云应用程序管理工具。
2016年,他加入Meta担任AI研究员后,又与白俊杰一起参与了PyTorch的开发。
Letpon AI的核心定位是,成为「AI时代云服务提供商」,旨在建立高效的AI应用平台。
其主要业务通过提供大模型推理引擎和云GPU解决方案,帮助企业去快速部署AI应用。而且,他们还建立了多云平台,整合全球GPU资源,让用户获得极具性价最高计算资源。
而且,团队还开发了一款智能搜索引擎Lepton Search,仅用500行Python代码构建,以轻量级、高效著称。
英伟达之困:光靠卖GPU,已经不够了
为什么英伟达要收购Lepton AI?显然,这是计划的一部分。
英伟达,如今显而易见正在构建全新的业务版图。
虽然它的云计算和软件业务目前尚处于起步阶段,但它已经开始向企业出租由自家芯片驱动的服务器,同时还会提供软件,帮企业开发AI模型和应用,以及管理用于训练AI的GPU集群。
根据英伟达的估计,这些业务未来有望创造高达1500亿美元的收入。
GTC大会上,老黄宣布:英伟达正在构建3个AI基础设施——云上AI基础设施,企业AI基础设施和机器人AI基础设施
不过有些微妙的是,在本月中最近一次季度财报电话会议上,英伟达却完全回避了这一话题。
三个月前,英伟达靠软件、服务和支持业务,已经实现了15亿美元的年化收入(每月约1.25亿美元),而英伟达预计,这一数字将在2024年底前攀升至20亿美元。
而英伟达的芯片业务,在截至1月26日的财季中创造的收入为356亿美元。
总之,虽然AI芯片仍然是英伟达的核心收入来源,但显然,软件、服务和支持业务的增长潜力巨大,英伟达已经下定决心,瓜分这一块蛋糕。
英伟达2025财年第四季度财报显示,公司发展一片大好,市场对AI芯片的需求依旧强劲
英伟达,大力发展工业客户
符合这一步调的是,英伟达最近几个月一直在大力宣传自家的软件产品。
虽然过去几年中,英伟达大概一半的AI服务器芯片,都是被云服务提供商买走了,不过老黄表示——
长期来看,英伟达对其他类型企业的销售额占比,将远远大于对云服务提供商的销售额。
他还暗示道,包括汽车制造商在内的工业企业,未来会直接购买AI芯片,而不是从云服务商那里租用。
此前大家对AI芯片的批评,主要就集中在价格昂贵、需求旺盛,让企业想扩展AI应用规模时,面临成本上的巨大压力。
但最近,DeepSeek这种价格亲民的强大模型,已经让局面彻底改变了。
而这几年,英伟达也在一刻不停地收购小型生成式AI和云计算初创公司,为的就是降低成本,让开发者能轻松使用英伟达芯片。
过去一年,英伟达就斥巨资收购了Run.ai和Deci,代价或许超过10亿美元。而最近收购的则是OctoAI和Gretel。
英伟达一直在收购小型生成式AI和云计算初创公司,以降低成本并使开发者更容易使用其芯片运行AI模型
GPU云服务评级,贾扬清初创进第二梯队
SemiAnalysis最新文章中,发布了世界上首个GPU云服务评级系统ClusterMAX™。
这个系统主要以普通用户的角度对GPU进行评,共分为5个不同等级:白金、黄金、白银、青铜和不及格。
目前,他们已独立测试了数十种GPU。
白金代表着引领行业标准的GPU云服务,目前也仅有一家CoreWeave达到这一级别。而在超大规模云服务提供商中,Oracle的GPU租赁价格是最低的之一。
评测结果还显示,一些青铜提供商,已经在努力赶上如谷歌云。谷歌云也在快速发展,有望下次冲进黄金/白金。
值得一提的是,Lepton AI这家仅成立2年的公司,成功进入第二梯队(黄金)。
Lepton AI,具体是干什么的
Lepton AI本身不拥有GPU硬件,而是专注于提供一个ML平台软件层,用于管理和优化GPU资源。
不论是初创公司,还是个人开发者, Lepton AI宣称皆能赋予专业级算力支持。
他们提供了两种灵活的使用方式,具体来说:
· 租用GPU:Lepton AI会从其他供应商租用GPU,在叠加上自家软件层,每GPU小时仅需额外之父几分钱。
· 自选GPU:从价格更优的Nebius租用GPU,然后单独购买Lepton AI软件和服务,同样是每GPU小时几分钱,即可享受完整的平台功能。
他们将谷歌、Meta等科技巨头在机器学习平台上的经验「平民化」,让普通用户也能轻松上手。
这种灵活性,能够让用户根据预算和需求自行选择。Lepton AI工程团队凭借着敏锐的产品洞察力,确保了平台高效性。
针对训练,他们提供了一种类似Slurm的作业提交方法。
在SemiAnalysis测试中,将现有的sbatch脚本正常运行在Lepton AI平台上,仅需几分钟的时间。而且,转换到平台进行训练的过程相当直观。
不过,Lepton AI提供的类似于Slurm sbatch功能,而非完整的 sbatch超集API。
此外,Lepton AI的控制台仪表板,是其一大亮点。
用户可以轻松查看节点生命周期,实时监控每个节点当前的作业和状态,可视化功能仅次于CoreWeave的节点生命周期仪表板。
并且,Lepton AI推出的开源解决方案gpud,已经为大多数被动健康检查项目提供了全面的支持。
虽然这个被动GPU检查系统仍在持续优化中,但已经算是非常强大的解决方案。
此外,Lepton AI也会提供手动主动健康检查功能,比如DCGM诊断和nccl-tests,但这些检查需要通过UI仪表板手动运行,不像CoreWeave那样能够自动按周进行定期检查。
还不足的是,Lepton AI没有提供NCCL测试的参考数值,也缺少Megatron Loss收敛主动健康检查或Nvidia TinyMeg2静默数据损坏(SDC)检测器主动健康检查。
另外,Lepton AI还提供了一些测试版功能,比如一键式零影响NCCL分析器。
只需点击一个复选框,就能充分利用其自主研发的内部NCCL分析器来可视化集体通信瓶颈,这样就能帮助客户优化网络性能瓶颈。
贾扬清:Caffe之父,AI框架缔造者
提到贾扬清,可以说是业内耳熟能详的「框架大神」。
作为主流AI框架Caffe创始人、TensorFlow的作者之一,PyTorch 1.0的共同缔造者,他的贡献早已深入AI开发的每个角落。
贾扬清,浙江绍兴人,本科和研究生阶段都就读于清华大学自动化专业
在研究生学习期间,他曾在新加坡国立大学、微软亚洲研究院、NEC美国实验室和谷歌研究院工作/实习,积累了丰富的实践经验。
2008年,他赴往加州大学伯克利分校攻读计算机科学博士,导师是Trevor Darrell教授。
在博士期间,他创立并开源的深度学习框架Caffe。这个框架一经推出,因其高效性、易用性迅速走红,被微软、雅虎、英伟达、Adobe等公司采用。
毕业后,2013年,贾扬清正式加入谷歌大脑团队,在Hinton和Jeff Dean等人的带领下,参与了TensorFlow平台的开发 。
此外,他还与同事一起建立了全新深度学习架构GoogLeNet——首个在图像分类任务中,超越人类准确性的神经网络。
3年后,贾扬清转投Facebook(Meta),在Yann LeCun领导下担任研究科学家,并在2017年,晋升为AI架构总监。
在此期间,贾扬清在AI架构的大道上一路进击:
· 2016年11月,Facebook推出轻量级模块化的深度学习框架Caffe2Go,让手机也能运行深度神经网络模型。
· 2017年4月,Facebook宣布开源产品级深度学习框架Caffe2,带来跨平台机器学习工具。
· 2017年,创建了首个开放模型格式ONNX原型,后来被FB、微软、亚马逊等公司联合推广。2018年5月,Facebook正式公布的PyTorch 1.0整合了ONNX格式。
2019年3月18日,贾扬清加入阿里达摩院,担任技术副总,负责大数据以及AI方向的技术、产品和业务。
直到2023年3月,他官宣离职,并在几个月之后创办了Lepton AI。
根据个人主页,贾扬清被引数最高的三篇论文,TensorFlow和Caffe赫然在列,他的每一步都推动了深度学习工具普及与进化。
曾有网友戏称,学物理绕不开牛顿,搞深度学习,绕不开贾扬清。
参考资料:
https://techcrunch.com/2025/03/26/nvidia-is-reportedly-in-talks-to-acquire-lepton-ai/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









