







1. java包层次讲解
针对java工程里的各种带O的对象,进行分析,了解各自的作用。
PO:persistent object,持久对象。与数据库里表字段一一对应。PO是一些属性,以及set和get方法组成。一般情况下,一个表,对应一个PO。是直接与操作数据库的crud相关。
VO:vlue object,又名:表现层对象,即view object。通常用于业务层之间的数据传递,和PO一样也是仅仅包含数据而已。但应是抽象出的业务对象,可以和表对应,也可以不,这根据业务的需要。对于页面上要展示的对象,可以封装一个VO对象,将所需数据封装进去。
BO:bussiness object,业务对象。封装业务逻辑的 java 对象 , 通过调用 DAO 方法 , 结合 PO,VO 进行业务操作。 一个BO对象可以包括多个PO对象。如常见的工作简历例子为例,简历可以理解为一个BO,简历又包括工作经历,学习经历等,这些可以理解为一个个的PO,由多个PO组成BO。
DAO:data access object,数据访问对象。此对象用于访问数据库。通常和 PO 结合使用, DAO 中包含了各种数据库的操作方法。通过它的方法 , 结合 PO 对数据库进行相关的操作。夹在业务逻辑与数据库资源中间。
DTO:data trasfer object,数据传输对象。主要用于远程调用等需要大量传输对象的地方。
比如我们一张表有 100 个字段,那么对应的 PO 就有 100 个属性。 但是我们界面上只要显示 10 个字段, 客户端用 WEB service 来获取数据,没有必要把整个 PO 对象传递到客户端,
这时我们就可以用只有这 10 个属性的 DTO 来传递结果到客户端,这样也不会暴露服务端表结构 . 到达客户端以后,如果用这个对象来对应界面显示,那此时它的身份就转为 VO。
POJO:plain ordinary java object) 简单无规则 java 对象 ,纯的传统意义的 java 对象。
2. for、foreach、stream 哪个处理效率更高,以及lambda注意事项
(1)串行
public static void streamMethod(List<Integer> list){
list.stream().forEach(i ->{
System.out.println("========");
});
}
(2)并行
public static void streamMethod(List<Integer> list){
list.parallelStream().forEach(i ->{
System.out.println("========");
});
}
-
针对不同的数据结构,Stream流的执行效率是不一样的
-
针对不同的数据源,Stream流的执行效率也是不一样的
-
Stream并行流计算 >> 普通for循环 ~= Stream串行流计算 (之所以用两个大于号,你细品)
-
数据容量越大,Stream流的执行效率越高。
-
Stream并行流计算通常能够比较好的利用CPU的多核优势。CPU核心越多,Stream并行流计算效率越高。
在大多数的核心业务场景下及常用数据结构下,Stream的执行效率比for循环更高,并行计算有时需要预热才显示出效率优势,很多时候计算速度没有比传统的 for 循环快。
数据量少用增强for,数据量大用foreach
Stream的优势在于,提供了并行处理(parallelStream()方法),数据达到百万可以使用,但是要注意线程安全问题,stream api提供了异步处理机制,可以充分利用CPU核数,大大提升效率!
对于列表单字段少量数据建议使用传统collections.sort方式排序,多字段的排序为了美观也可使用stream,效率并不快。
lamba表达式虽然简洁,但是可读性查,由于Lambda表达式执行时需要在编译时反推将其转换为对象,所以效率比较低,适合在并行流中使用。在要求效率不高,但是代码美观的时候,建议使用Lambda,在要求高效率的时候,不建议使用。
3. map的四种遍历方式
public static void main(String[] args) {
// 循环遍历Map的4中方法
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
map.put(1, 2);
// 1. entrySet遍历,在键和值都需要时使用(最常用)
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue());
}
// 2. 通过keySet或values来实现遍历,性能略低于第一种方式
// 遍历map中的键
for (Integer key : map.keySet()) {
System.out.println("key = " + key);
}
// 遍历map中的值
for (Integer value : map.values()) {
System.out.println("key = " + value);
}
// 3. 使用Iterator遍历
Iterator<Map.Entry<Integer, Integer>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, Integer> entry = it.next();
System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue());
}
// 4. java8 Lambda
// java8提供了Lambda表达式支持,语法看起来更简洁,可以同时拿到key和value,
// 不过,经测试,性能低于entrySet,所以更推荐用entrySet的方式
map.forEach((key, value) -> {
System.out.println(key + ":" + value);
});
}
4. 数组转集合,Arrays.asList的缺陷,集合转数组
4.1. 数组转集合
-
asList避免使用基本数据类型数组转换为列表
asList 接受的参数是一个泛型的变长参数,基本数据类型是无法泛型化的, 要想作为泛型参数就必须使用其所对应的包装类型。
public static void main(String[] args) {
int[] ints = {1,2,3,4,5};
List list = Arrays.asList(ints);
System.out.println("list'size:" + list.size());
}
------------------------------------
outPut:
list'size:1
-
asList 产生的列表不可操作
asList 返回的列表只不过是一个披着 list 的外衣,它并没有 list 的基本特性(变长)。该 list 是一个长度不可变的列表,传入参数的数组有多长,其返回的列表就只能是多长。
-
创建可操作的List
List<Integer> list = new ArrayList<>(Arrays.asList(1,2,3));
4.2. 集合转数组

5. Bean复制的方法和性能(BeanUtils、PropertyUtils、BeanCopier)
5.1. 性能比较
从整体的表现来看,Cglib的BeanCopier的性能是最好的无论是数量较大的1万次的测试,还是数量较少10次,几乎都是趋近与零损耗,Spring是在次数增多的情况下,性能较好,在数据较少的时候,性能比PropertyUtils的性能差一些。而Apache的BeanUtil的性能最差,无论是单次Copy还是大数量的多次Copy性能都不是很好。
5.2. BeanUtil.copyProperties拷贝的使用
/**
* 复制Bean对象属性<br>
* 限制类用于限制拷贝的属性,例如一个类我只想复制其父类的一些属性,就可以将editable设置为父类
*
* @param source 源Bean对象
* @param target 目标Bean对象
* @param ignoreProperties 不拷贝的的属性列表
*/
public static void copyProperties(Object source, Object target, String... ignoreProperties) {
copyProperties(source, target, CopyOptions.create().setIgnoreProperties(ignoreProperties));
}
5.3. BeanCopier拷贝的使用
public class Enum2StringConverter implements Converter {
@Override
public Object convert(Object o, Class aClass, Object o1) {
if (o instanceof Enum) {
return o.toString();
}else {
return o;
}
}
}
//设置为true才按照自定义转换器来转化两个类
BeanCopier copier = BeanCopier.create(BaseInfoForm.class, TbContManBasic.class,true);
Enum2StringConverter converter = new Enum2StringConverter();
//manContractForm.getBaseInfoForm(): src, tbContManBasic: target, converter:转换器
copier.copy(manContractForm.getBaseInfoForm(), tbContManBasic, converter);
6. Lambda 表达式的使用
6.1. 对接口的要求
Lambda 规定接口中只能有一个需要被实现的方法,不是规定接口中只能有一个方法。
jdk 8 中有另一个新特性:default, 被 default 修饰的方法会有默认实现,不是必须被实现的方法,所以不影响 Lambda 表达式的使用。
6.2. @FunctionalInterface注解
修饰函数式接口的,加了后要求接口中的抽象方法只有一个。这个注解往往会和 lambda 表达式一起出现。
6.3. Lambda 基础语法
我们这里给出六个接口,后文的全部操作都利用这六个接口来进行阐述。
/**多参数无返回*/
@FunctionalInterface
public interface NoReturnMultiParam {
void method(int a, int b);
}
/**无参无返回值*/
@FunctionalInterface
public interface NoReturnNoParam {
void method();
}
/**一个参数无返回*/
@FunctionalInterface
public interface NoReturnOneParam {
void method(int a);
}
/**多个参数有返回值*/
@FunctionalInterface
public interface ReturnMultiParam {
int method(int a, int b);
}
/*** 无参有返回*/
@FunctionalInterface
public interface ReturnNoParam {
int method();
}
/**一个参数有返回值*/
@FunctionalInterface
public interface ReturnOneParam {
int method(int a);
}
语法形式为 () -> {},其中 () 用来描述参数列表,{} 用来描述方法体,-> 为 lambda运算符 ,读作(goes to)。
import lambda.interfaces.*;
public class Test1 {
public static void main(String[] args) {
//无参无返回
NoReturnNoParam noReturnNoParam = () -> {
System.out.println("NoReturnNoParam");
};
noReturnNoParam.method();
//一个参数无返回
NoReturnOneParam noReturnOneParam = (int a) -> {
System.out.println("NoReturnOneParam param:" + a);
};
noReturnOneParam.method(6);
//多个参数无返回
NoReturnMultiParam noReturnMultiParam = (int a, int b) -> {
System.out.println("NoReturnMultiParam param:" + "{" + a +"," + + b +"}");
};
noReturnMultiParam.method(6, 8);
//无参有返回值
ReturnNoParam returnNoParam = () -> {
System.out.print("ReturnNoParam");
return 1;
};
int res = returnNoParam.method();
System.out.println("return:" + res);
//一个参数有返回值
ReturnOneParam returnOneParam = (int a) -> {
System.out.println("ReturnOneParam param:" + a);
return 1;
};
int res2 = returnOneParam.method(6);
System.out.println("return:" + res2);
//多个参数有返回值
ReturnMultiParam returnMultiParam = (int a, int b) -> {
System.out.println("ReturnMultiParam param:" + "{" + a + "," + b +"}");
return 1;
};
int res3 = returnMultiParam.method(6, 8);
System.out.println("return:" + res3);
}
}
6.4. Lambda 语法简化
我们可以通过观察以下代码来完成代码的进一步简化,写出更加优雅的代码。
import lambda.interfaces.*;
public class Test2 {
public static void main(String[] args) {
//1.简化参数类型,可以不写参数类型,但是必须所有参数都不写
NoReturnMultiParam lamdba1 = (a, b) -> {
System.out.println("简化参数类型");
};
lamdba1.method(1, 2);
//2.简化参数小括号,如果只有一个参数则可以省略参数小括号
NoReturnOneParam lambda2 = a -> {
System.out.println("简化参数小括号");
};
lambda2.method(1);
//3.简化方法体大括号,如果方法条只有一条语句,则可以胜率方法体大括号
NoReturnNoParam lambda3 = () -> System.out.println("简化方法体大括号");
lambda3.method();
//4.如果方法体只有一条语句,并且是 return 语句,则可以省略方法体大括号
ReturnOneParam lambda4 = a -> a+3;
System.out.println(lambda4.method(5));
ReturnMultiParam lambda5 = (a, b) -> a+b;
System.out.println(lambda5.method(1, 1));
}
}
6.5. Lambda 表达式常用示例
6.5.1. lambda 表达式引用方法
有时候我们不是必须要自己重写某个匿名内部类的方法,我们可以可以利用 lambda表达式的接口快速指向一个已经被实现的方法。
语法
方法归属者::方法名 静态方法的归属者为类名,普通方法归属者为对象
public class Exe1 {
public static void main(String[] args) {
ReturnOneParam lambda1 = a -> doubleNum(a);
System.out.println(lambda1.method(3));
//lambda2 引用了已经实现的 doubleNum 方法
ReturnOneParam lambda2 = Exe1::doubleNum;
System.out.println(lambda2.method(3));
Exe1 exe = new Exe1();
//lambda4 引用了已经实现的 addTwo 方法
ReturnOneParam lambda4 = exe::addTwo;
System.out.println(lambda4.method(2));
}
/**
* 要求
* 1.参数数量和类型要与接口中定义的一致
* 2.返回值类型要与接口中定义的一致
*/
public static int doubleNum(int a) {
return a * 2;
}
public int addTwo(int a) {
return a + 2;
}
}
6.5.2. 构造方法的引用
一般我们需要声明接口,该接口作为对象的生成器,通过 类名::new 的方式来实例化对象,然后调用方法返回对象。
interface ItemCreatorBlankConstruct {
Item getItem();
}
interface ItemCreatorParamContruct {
Item getItem(int id, String name, double price);
}
public class Exe2 {
public static void main(String[] args) {
ItemCreatorBlankConstruct creator = () -> new Item();
Item item = creator.getItem();
ItemCreatorBlankConstruct creator2 = Item::new;
Item item2 = creator2.getItem();
ItemCreatorParamContruct creator3 = Item::new;
Item item3 = creator3.getItem(112, "鼠标", 135.99);
}
}
6.5.3. lambda 表达式创建线程
我们以往都是通过创建 Thread 对象,然后通过匿名内部类重写 run() 方法,一提到匿名内部类我们就应该想到可以使用 lambda 表达式来简化线程的创建过程。
Thread t = new Thread(() -> {
for (int i = 0; i < 10; i++) {
System.out.println(2 + ":" + i);
}
});
t.start();
6.5.4. 遍历集合
我们可以调用集合的public void forEach(Consumer<? super E> action) 方法,通过 lambda 表达式的方式遍历集合中的元素。以下是 Consumer 接口的方法以及遍历集合的操作。Consumer 接口是 jdk 为我们提供的一个函数式接口。
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
//....
}
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1,2,3,4,5);
//lambda表达式 方法引用
list.forEach(System.out::println);
list.forEach(element -> {
if (element % 2 == 0) {
System.out.println(element);
}
});
6.5.5. 删除集合中的某个元素
我们通过public boolean removeIf(Predicate<? super E> filter)方法来删除集合中的某个元素,Predicate 也是 jdk 为我们提供的一个函数式接口,可以简化程序的编写。
ArrayList<Item> items = new ArrayList<>();
items.add(new Item(11, "小牙刷", 12.05 ));
items.add(new Item(5, "日本马桶盖", 999.05 ));
items.add(new Item(7, "格力空调", 888.88 ));
items.add(new Item(17, "肥皂", 2.00 ));
items.add(new Item(9, "冰箱", 4200.00 ));
items.removeIf(ele -> ele.getId() == 7);
//通过 foreach 遍历,查看是否已经删除
items.forEach(System.out::println);
6.5.6. 集合内元素的排序
在以前我们若要为集合内的元素排序,就必须调用 sort 方法,传入比较器匿名内部类重写 compare 方法,我们现在可以使用 lambda 表达式来简化代码。
ArrayList<Item> list = new ArrayList<>();
list.add(new Item(13, "背心", 7.80));
list.add(new Item(11, "半袖", 37.80));
list.add(new Item(14, "风衣", 139.80));
list.add(new Item(12, "秋裤", 55.33));
/*
list.sort(new Comparator<Item>() {
@Override
public int compare(Item o1, Item o2) {
return o1.getId() - o2.getId();
}
});
*/
list.sort((o1, o2) -> o1.getId() - o2.getId());
System.out.println(list);
6.6. Lambda 表达式中的闭包问题
这个问题我们在匿名内部类中也会存在,如果我们把注释放开会报错,告诉我 num 值是 final 不能被改变。这里我们虽然没有标识 num 类型为 final,但是在编译期间虚拟机会帮我们加上 final 修饰关键字。
import java.util.function.Consumer;
public class Main {
public static void main(String[] args) {
int num = 10;
Consumer<String> consumer = ele -> {
System.out.println(num);
};
//num = num + 2;
consumer.accept("hello");
}
}
7. stream的使用
-
stream的三大特性:一、不存储数据;二、不改变源数据;三、延时执行。
-
并行流ParallelStream框架的性能受以下因素影响:
- 数据大小:数据够大,每个管道处理时间够长,并行才有意义;
- 源数据结构:每个管道操作都是基于初始数据源,通常是集合,将不同的集合数据源分割会有一定消耗;
- 装箱:处理基本类型比装箱类型要快;
- 核的数量:默认情况下,核数量越多,底层fork/join线程池启动线程就越多;
- 单元处理开销:花在流中每个元素身上的时间越长,并行操作带来的性能提升越明显;
源数据结构分为以下3组:
- 性能好:ArrayList、数组或IntStream.range(数据支持随机读取,能轻易地被任意分割)
- 性能一般:HashSet、TreeSet(数据不易公平地分解,大部分也是可以的)
- 性能差:LinkedList(需要遍历链表,难以对半分解)、Stream.iterate和BufferedReader.lines(长度未知,难以分解)
7.1. 开始管道
主要负责新建一个Stream流,或者基于现有的数组、List、Set、Map等集合类型对象创建出新的Stream流。
| API | 功能说明 |
|---|---|
| stream() | 创建出一个新的stream串行流对象 |
| parallelStream() | 创建出一个可并行执行的stream流对象 |
| Stream.of() | 通过给定的一系列元素创建一个新的Stream串行流对象 |
7.2. 中间管道
负责对Stream进行处理操作,并返回一个新的Stream对象,中间管道操作可以进行叠加。
| API | 功能说明 |
|---|---|
| filter() | 按照条件过滤符合要求的元素, 返回新的stream流 |
| map() | 将已有元素转换为另一个对象类型,一对一逻辑,返回新的stream流 |
| flatMap() | 将已有元素转换为另一个对象类型,一对多逻辑,即原来一个元素对象可能会转换为1个或者多个新类型的元素,返回新的stream流 |
| limit() | 仅保留集合前面指定个数的元素,返回新的stream流 |
| skip() | 跳过集合前面指定个数的元素,返回新的stream流 |
| concat() | 将两个流的数据合并起来为1个新的流,返回新的stream流 |
| distinct() | 对Stream中所有元素进行去重,返回新的stream流 |
| sorted() | 对stream中所有的元素按照指定规则进行排序,返回新的stream流 |
| peek() | 对stream流中的每个元素进行逐个遍历处理,返回处理后的stream流 |
7.3. 终止管道
顾名思义,通过终止管道操作之后,Stream流将会结束,最后可能会执行某些逻辑处理,或者是按照要求返回某些执行后的结果数据。
| API | 功能说明 |
|---|---|
| count() | 返回stream处理后最终的元素个数 |
| max() | 返回stream处理后的元素最大值 |
| min() | 返回stream处理后的元素最小值 |
| findFirst() | 找到第一个符合条件的元素时则终止流处理 |
| findAny() | 找到任何一个符合条件的元素时则退出流处理,这个对于串行流时与findFirst相同,对于并行流时比较高效,任何分片中找到都会终止后续计算逻辑 |
| anyMatch() | 返回一个boolean值,类似于isContains(),用于判断是否有符合条件的元素 |
| allMatch() | 返回一个boolean值,用于判断是否所有元素都符合条件 |
| noneMatch() | 返回一个boolean值, 用于判断是否所有元素都不符合条件 |
| collect() | 将流转换为指定的类型,通过Collectors进行指定 |
| toArray() | 将流转换为数组 |
| iterator() | 将流转换为Iterator对象 |
| foreach() | 无返回值,对元素进行逐个遍历,然后执行给定的处理逻辑 |
7.4. 示例
List<Dept> results = ids.stream() .filter(s -> s.length() > 2) .distinct() .map(Integer::valueOf) .sorted(Comparator.comparingInt(o -> o)) .limit(3) .map(id -> new Dept(id)) .collect(Collectors.toList()); System.out.println(results); }
- 使用filter过滤掉不符合条件的数据
- 通过distinct对存量元素进行去重操作
- 通过map操作将字符串转成整数类型
- 借助sorted指定按照数字大小正序排列
- 使用limit截取排在前3位的元素
- 又一次使用map将id转为Dept对象类型
- 使用collect终止操作将最终处理后的数据收集到list中
8. stream多字段排序的使用
8.1. 传统排序
List<Double> salesData = new ArrayList<>();
Collections.sort(salesData);
Collections.reverse(salesData);
Collections.reverse(salesData,new Comparator<T>(){
@Override
public int compare(Double o1, Double o2) {
return o1-o2;
}
});
salesData.sort(new Comparator<Double>() {
@Override
public int compare(Double o1, Double o2) {
return o1 - o2;
})}
});
8.2. 多字段排序
//stream+lambda方式
List<类> rankList = new ArrayList<>(); 表明某个集合
//返回 对象集合以类属性一升序排序
rankList.stream().sorted(Comparator.comparing(类::属性一));
//注意两种写法
//返回 对象集合以类属性一降序排序
rankList.stream().sorted(Comparator.comparing(类::属性一).reversed());
//先以属性一升序,而后对结果集进行属性一降序
rankList.stream().sorted(Comparator.comparing(类::属性一, Comparator.reverseOrder()));
//返回 对象集合以类属性一降序 属性二升序
rankList.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二));
由于lambda在串行少量数据下效率并不高,可以去掉。
lists.sort(new Comparator<StreamConfig>() {
@Override
public int compare(StreamConfig o1, StreamConfig o2) {
return o1.getDetectRate() - o2.getDetectRate();
}
});
9. 时间戳和LocalDateTime和Date互转和格式化
9.1. 时间戳与LocalDateTime互转
// 获得当前时间转为时间戳
LocalDateTime localDateTime = LocalDateTime.now();
// 将当前时间转为毫秒级时间戳
long second = localDateTime.toInstant(ZoneOffset.ofHours(8)).toEpochMilli();
// 将当前时间转为秒级时间戳
long second1 = localDateTime.toInstant(ZoneOffset.ofHours(8)).getEpochSecond();
System.out.println(second);
//时间戳转回LocalDateTime
//ms级别
LocalDateTime localDateTime1=Instant.ofEpochMilli(second).atZone(ZoneOffset.ofHours(8))
.toLocalDateTime();
//s级别
LocalDateTime localDateTime=Instant.ofEpochSecond(second1).atZone(ZoneOffset.ofHours(8))
.toLocalDateTime();
9.2. LocalDateTime与Date互转
// 创建时间
Date date = new Date();
// 方式1
LocalDateTime localDateTime =date.toInstant().atOffset(ZoneOffset.ofHours(8)).toLocalDateTime();
// 方式2,使用系统默认时区
LocalDateTime localDateTime1 = LocalDateTime.ofInstant(date.toInstant(), ZoneId.systemDefault());
// 转换回去
Date from = Date.from(localDateTime1.atZone(ZoneId.systemDefault()).toInstant());
9.3. Data和字符串转换
// 创建时间
Date date = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
String format = simpleDateFormat.format(date);
Date date1 = simpleDateFormat.parse(format);
9.4. LocalDateTime 和字符串转换
// 获得 localDateTime
LocalDateTime localDateTime = LocalDateTime.now();
// 指定模式
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy/MM/dd HH/mm/ss:SSS");
// 将 LocalDateTime 格式化为字符串
String format = localDateTime.format(dateTimeFormatter);
LocalDateTime parse = LocalDateTime.parse(format, dateTimeFormatter);
10. fastJson的使用
10.1. 反序列化漏洞
maven引入fastjson后,会把RequestBody的反序列过程替换成fastjson的
反序列化漏洞详细可看如下内容
https://www.cnblogs.com/escape-w/p/14745024.html
10.2. 常用方法
Object parse1 = JSON.parse("{}");
JSONObject jsonObject = JSON.parseObject("{}");
JSONArray objects = JSON.parseArray("{}");
String s = JSON.toJSONString(jsonObject);
List<M1> m1s = JSON.parseArray("{}", M1.class);
//存在多种get方法
Object jdjn = jsonObject.get("jdjn");
11. springBoot日志框架
- Logback 是
log4j框架的作者开发的新一代日志框架,它效率更高、能够适应诸多的运行环境,同时天然支持SLF4J Logback的定制性更加灵活,同时也是spring boot的内置日志框架
11.1. springboot内置日志框架
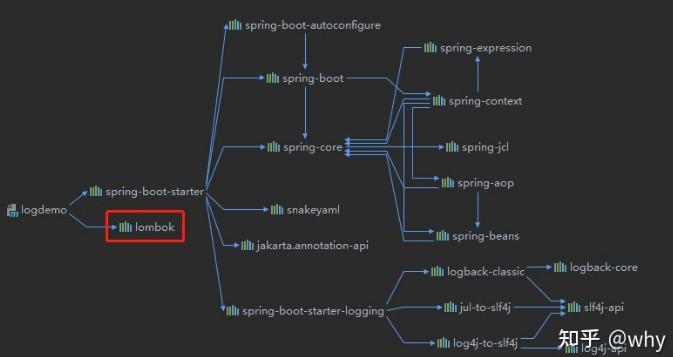
SpringBoot支持log4j、logback作为日志框架。 如果你使用starters启动器,Spring Boot将使用Logback作为默认日志框架。Spring-boot-starter启动器包含spring-boot-starter-logging启动器并集成了slf4j日志抽象及Logback日志框架。
11.2. 使用
默认情况下Spring Boot将日志输出到控制台,不会写到日志文件。如果要编写除控制台输出之外的日志文件,则需在application.yaml中设置logging.file或logging.path属性
logging:
file:
path: 日志文件路径
name: 文件名
level: debug
pattern:
console: 日志打印规则
11.3. logback-spring.xml详解
Spring Boot官方推荐优先使用带有-spring的文件名作为你的日志配置(如使用logback-spring.xml,而不是logback.xml),命名为logback-spring.xml的日志配置文件,将xml放至 src/main/resource下面。
在讲解 logback-spring.xml之前我们先来了解三个单词:Logger, Appenders和Layouts(记录器、附加器、布局):Logback基于三个主要类:Logger,Appender和Layout。 这三种类型的组件协同工作,使开发人员能够根据消息类型和级别记录消息,并在运行时控制这些消息的格式以及报告的位置。首先给出一个基本的xml配置如下:
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- encoders are assigned the type
ch.qos.logback.classic.encoder.PatternLayoutEncoder by default -->
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<logger name="chapters.configuration" level="INFO"/>
<!-- Strictly speaking, the level attribute is not necessary since -->
<!-- the level of the root level is set to DEBUG by default. -->
<root level="DEBUG">
<appender-ref ref="STDOUT" />
</root>
</configuration>
logback.xml配置文件的基本结构可以描述为<configuration>元素,包含零个或多个<appender>元素,后跟零个或多个<logger>元素,后跟最多一个<root>元素(也可以没有)。下面说明了这种基本结构:
<logger>元素只接受一个必需的name属性,一个可选的level属性和一个可选的additivity属性,允许值为true或false。 level属性的值允许一个不区分大小写的字符串值TRACE,DEBUG,INFO,WARN,ERROR,ALL或OFF。<logger>元素可以包含零个或多个<appender-ref>元素; 这样引用的每个appender都被添加到指定的logger中。logger元素级别具有继承性。
<root>元素配置根记录器。 它支持单个属性,即level属性。 它不允许任何其他属性,因为additivity标志不适用于根记录器。 此外,由于根记录器已被命名为ROOT,因此它也不允许使用name属性。level属性的值可以是不区分大小写的字符串TRACE,DEBUG,INFO,WARN,ERROR,ALL或OFF之一<root>元素可以包含零个或多个<appender-ref>元素; 这样引用的每个appender都被添加到根记录器中。
appender使用<appender>元素配置,该元素采用两个必需属性name和class。 name属性指定appender的名称,而class属性指定要实例化的appender类的完全限定名称。 <appender>元素可以包含零个或一个<layout>元素,零个或多个<encoder>元素以及零个或多个<filter>元素。
encoder中最重要就是pattern属性,它负责控制输出日志的格式,这里给出一个我自己写的示例:
<pattern>
%d{yyyy-MM-dd HH:mm:ss.SSS} %highlight(%-5level) --- [%15.15(%thread)] %cyan(%-40.40(%logger{40})) : %msg%n
</pattern>
- %d{yyyy-MM-dd HH:mm:ss.SSS}:日期
- %-5level:日志级别
- %highlight():颜色,info为蓝色,warn为浅红,error为加粗红,debug为黑色
- %thread:打印日志的线程
- %15.15():如果记录的线程字符长度小于15(第一个)则用空格在左侧补齐,如果字符长度大于15(第二个),则从开头开始截断多余的字符
- %logger:日志输出的类名
- **%-40.40():如果记录的logger字符长度小于40(第一个)则用空格在右侧补齐,如果字符长度大于40(第二个),则从开头开始截断多余的字符 **
- %cyan:颜色
- %msg:日志输出内容
- %n:换行符
11.4. 详细示例
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="true">
<!-- appender是configuration的子节点,是负责写日志的组件。 -->
<!-- ConsoleAppender:把日志输出到控制台 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- 默认情况下,每个日志事件都会立即刷新到基础输出流。 这种默认方法更安全,因为如果应用程序在没有正确关闭appender的情况下退出,则日志事件不会丢失。
但是,为了显着增加日志记录吞吐量,您可能希望将immediateFlush属性设置为false -->
<!--<immediateFlush>true</immediateFlush>-->
<encoder>
<!-- %37():如果字符没有37个字符长度,则左侧用空格补齐 -->
<!-- %-37():如果字符没有37个字符长度,则右侧用空格补齐 -->
<!-- %15.15():如果记录的线程字符长度小于15(第一个)则用空格在左侧补齐,如果字符长度大于15(第二个),则从开头开始截断多余的字符 -->
<!-- %-40.40():如果记录的logger字符长度小于40(第一个)则用空格在右侧补齐,如果字符长度大于40(第二个),则从开头开始截断多余的字符 -->
<!-- %msg:日志打印详情 -->
<!-- %n:换行符 -->
<!-- %highlight():转换说明符以粗体红色显示其级别为ERROR的事件,红色为WARN,BLUE为INFO,以及其他级别的默认颜色。 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %highlight(%-5level) --- [%15.15(%thread)] %cyan(%-40.40(%logger{40})) : %msg%n</pattern>
<!-- 控制台也要使用UTF-8,不要使用GBK,否则会中文乱码 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- info 日志-->
<!-- RollingFileAppender:滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件 -->
<!-- 以下的大概意思是:1.先按日期存日志,日期变了,将前一天的日志文件名重命名为XXX%日期%索引,新的日志仍然是project_info.log -->
<!-- 2.如果日期没有发生变化,但是当前日志的文件大小超过10MB时,对当前日志进行分割 重命名-->
<appender name="info_log" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!--日志文件路径和名称-->
<File>logs/project_info.log</File>
<!--是否追加到文件末尾,默认为true-->
<append>true</append>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>DENY</onMatch><!-- 如果命中ERROR就禁止这条日志 -->
<onMismatch>ACCEPT</onMismatch><!-- 如果没有命中就使用这条规则 -->
</filter>
<!--有两个与RollingFileAppender交互的重要子组件。 第一个RollingFileAppender子组件,即RollingPolicy:负责执行翻转所需的操作。
RollingFileAppender的第二个子组件,即TriggeringPolicy:将确定是否以及何时发生翻转。 因此,RollingPolicy负责什么和TriggeringPolicy负责什么时候.
作为任何用途,RollingFileAppender必须同时设置RollingPolicy和TriggeringPolicy,但是,如果其RollingPolicy也实现了TriggeringPolicy接口,则只需要显式指定前者。-->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 日志文件的名字会根据fileNamePattern的值,每隔一段时间改变一次 -->
<!-- 文件名:logs/project_info.2017-12-05.0.log -->
<!-- 注意:SizeAndTimeBasedRollingPolicy中 %i和%d令牌都是强制性的,必须存在,要不会报错 -->
<fileNamePattern>logs/project_info.%d.%i.log</fileNamePattern>
<!-- 每产生一个日志文件,该日志文件的保存期限为30天, ps:maxHistory的单位是根据fileNamePattern中的翻转策略自动推算出来的,例如上面选用了yyyy-MM-dd,则单位为天
如果上面选用了yyyy-MM,则单位为月,另外上面的单位默认为yyyy-MM-dd-->
<maxHistory>30</maxHistory>
<!-- 每个日志文件到10mb的时候开始切分,最多保留30天,但最大到20GB,哪怕没到30天也要删除多余的日志 -->
<totalSizeCap>20GB</totalSizeCap>
<!-- maxFileSize:这是活动文件的大小,默认值是10MB,测试时可改成5KB看效果 -->
<maxFileSize>10MB</maxFileSize>
</rollingPolicy>
<!--编码器-->
<encoder>
<!-- pattern节点,用来设置日志的输入格式 ps:日志文件中没有设置颜色,否则颜色部分会有ESC[0:39em等乱码-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level --- [%15.15(%thread)] %-40.40(%logger{40}) : %msg%n</pattern>
<!-- 记录日志的编码:此处设置字符集 - -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- error 日志-->
<!-- RollingFileAppender:滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件 -->
<!-- 以下的大概意思是:1.先按日期存日志,日期变了,将前一天的日志文件名重命名为XXX%日期%索引,新的日志仍然是project_error.log -->
<!-- 2.如果日期没有发生变化,但是当前日志的文件大小超过10MB时,对当前日志进行分割 重命名-->
<appender name="error_log" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!--日志文件路径和名称-->
<File>logs/project_error.log</File>
<!--是否追加到文件末尾,默认为true-->
<append>true</append>
<!-- ThresholdFilter过滤低于指定阈值的事件。 对于等于或高于阈值的事件,ThresholdFilter将在调用其decision()方法时响应NEUTRAL。 但是,将拒绝级别低于阈值的事件 -->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level><!-- 低于ERROR级别的日志(debug,info)将被拒绝,等于或者高于ERROR的级别将相应NEUTRAL -->
</filter>
<!--有两个与RollingFileAppender交互的重要子组件。 第一个RollingFileAppender子组件,即RollingPolicy:负责执行翻转所需的操作。
RollingFileAppender的第二个子组件,即TriggeringPolicy:将确定是否以及何时发生翻转。 因此,RollingPolicy负责什么和TriggeringPolicy负责什么时候.
作为任何用途,RollingFileAppender必须同时设置RollingPolicy和TriggeringPolicy,但是,如果其RollingPolicy也实现了TriggeringPolicy接口,则只需要显式指定前者。-->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 活动文件的名字会根据fileNamePattern的值,每隔一段时间改变一次 -->
<!-- 文件名:logs/project_error.2017-12-05.0.log -->
<!-- 注意:SizeAndTimeBasedRollingPolicy中 %i和%d令牌都是强制性的,必须存在,要不会报错 -->
<fileNamePattern>logs/project_error.%d.%i.log</fileNamePattern>
<!-- 每产生一个日志文件,该日志文件的保存期限为30天, ps:maxHistory的单位是根据fileNamePattern中的翻转策略自动推算出来的,例如上面选用了yyyy-MM-dd,则单位为天
如果上面选用了yyyy-MM,则单位为月,另外上面的单位默认为yyyy-MM-dd-->
<maxHistory>30</maxHistory>
<!-- 每个日志文件到10mb的时候开始切分,最多保留30天,但最大到20GB,哪怕没到30天也要删除多余的日志 -->
<totalSizeCap>20GB</totalSizeCap>
<!-- maxFileSize:这是活动文件的大小,默认值是10MB,测试时可改成5KB看效果 -->
<maxFileSize>10MB</maxFileSize>
</rollingPolicy>
<!--编码器-->
<encoder>
<!-- pattern节点,用来设置日志的输入格式 ps:日志文件中没有设置颜色,否则颜色部分会有ESC[0:39em等乱码-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level --- [%15.15(%thread)] %-40.40(%logger{40}) : %msg%n</pattern>
<!-- 记录日志的编码:此处设置字符集 - -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!--给定记录器的每个启用的日志记录请求都将转发到该记录器中的所有appender以及层次结构中较高的appender(不用在意level值)。
换句话说,appender是从记录器层次结构中附加地继承的。
例如,如果将控制台appender添加到根记录器,则所有启用的日志记录请求将至少在控制台上打印。
如果另外将文件追加器添加到记录器(例如L),则对L和L'子项启用的记录请求将打印在文件和控制台上。
通过将记录器的additivity标志设置为false,可以覆盖此默认行为,以便不再添加appender累积-->
<!-- configuration中最多允许一个root,别的logger如果没有设置级别则从父级别root继承 -->
<root level="INFO">
<appender-ref ref="STDOUT" />
</root>
<!-- 指定项目中某个包,当有日志操作行为时的日志记录级别 -->
<!-- 级别依次为【从高到低】:FATAL > ERROR > WARN > INFO > DEBUG > TRACE -->
<logger name="com.sailing.springbootmybatis" level="INFO">
<appender-ref ref="info_log" />
<appender-ref ref="error_log" />
</logger>
<!-- 利用logback输入mybatis的sql日志,
注意:如果不加 additivity="false" 则此logger会将输出转发到自身以及祖先的logger中,就会出现日志文件中sql重复打印-->
<logger name="com.sailing.springbootmybatis.mapper" level="DEBUG" additivity="false">
<appender-ref ref="info_log" />
<appender-ref ref="error_log" />
</logger>
<!-- additivity=false代表禁止默认累计的行为,即com.atomikos中的日志只会记录到日志文件中,不会输出层次级别更高的任何appender-->
<logger name="com.atomikos" level="INFO" additivity="false">
<appender-ref ref="info_log" />
<appender-ref ref="error_log" />
</logger>
</configuration>
12. Lombok和jdk1.7对流处理的新特性
12.1. Lombok缺点
Lombok本质上是一个预处理程序,最大的问题是你看到的代码和编译器看到的代码不一样,会导致很多问题无法及时发现,跟C的define类似,所以不推荐使用。
12.2. Lombok中注解使用方法
常用注解:@Getter和 @Setter-该字段自动生成 getter 和 setter 方法和方法的访问级别
ToString和@EqualsAndHashCode,@NonNull(方法/构造器的参数和成员变量,判断该参数不能为 null,如果为 null 则抛出 NullPointerException)。
| 构造注解 | 注解含义 |
|---|---|
@NoArgsConstructor | 生成类的无参构造函数 |
@RequiredArgsConstructor | 生成类的被 @NonNull 修饰和 final 修饰且没有赋初始值的有参构造函数 |
@AllArgsConstructor | 生成类的全参构造函数 |
@Data是注解 @Getter @Setter @RequiredArgsConstructor @ToString @EqualsAndHashCode 的组合写法
@Builder和@Accessors是流式编程和链式编程。
12.3. 对流处理新特性(需要关闭的资源声明在try的小括号里)
jdk1.7以前处理文件:
/**
* 获取文件内容
* @param file 文件
* @return 内容
*/
public String getText(File file){
FileInputStream fis = null;
try {
fis = new FileInputStream(file);
byte[] b = new byte[(int) file.length()];
fis.read(b);
return new String(b, "UTF-8");
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return "";
}
但jdk1.7及以后就可以改写为下面格式了:把需要关闭的资源声明在try的小括号里
/**
* 获取文件内容
* @param file 文件
* @return 内容
*/
public String getText(File file){
try(FileInputStream fis = new FileInputStream(file)) {
byte[] b = new byte[(int) file.length()];
fis.read(b);
return new String(b, "UTF-8");
} catch (IOException e) {
e.printStackTrace();
}
return "";
}
13. Java8之Optional 判空
Optional 类是一个可以为 null 的容器对象。如果值存在则 isPresent() 方法会返回 true,调用 get() 方法会返回该对象。Optional 是个容器:它可以保存类型 T 的值,或者仅仅保存 null。
13.1. Optional 实例使用
13.1.1. of
为非 null 的值创建一个 Optional。of 方法通过工厂方法创建 Optional 类。需要注意的是,创建对象时传入的参数不能为 null。如果传入参数为 null,则抛出 NullPointerException 。
Optional<String> optional = Optional.of("xiaoming");
//传入null,抛出NullPointerException
Optional<Object> o = Optional.of(null);
13.1.2. ofNullable
为指定的值创建一个 Optional,如果指定的值为 null,则返回一个空的 Optional。
Optional<Object> o1 = Optional.ofNullable(null);
13.1.3. isPresent
值存在返回 true,否则返回 false
Optional<String> optiona2 = Optional.of("xiaoming");
System.out.println(optiona2.isPresent());
13.1.4. get
Optional 有值就返回,没有抛出 NoSuchElementException
Optional<Object> o1 = Optional.ofNullable(null);
System.out.println(o1.get());
13.1.5. ifPresent
如果 Optional 有值则调用 consumer 处理,否则不处理
Optional<Object> o1 = Optional.ofNullable(null);
o1.ifPresent(s -> System.out.println(s));
13.1.6. orElse
如果有值则将其返回,否则返回指定的其它值
Optional<Object> o1 = Optional.ofNullable(null);
System.out.println(o1.orElse("输出orElse")); // 输出orElse
13.1.7. orElseGet
orElseGet 与 orElse 方法类似,区别在于得到的默认值。orElse 方法将传入的字符串作为默认值,orElseGet 方法可以接受 Supplier 接口的实现用来生成默认值
Optional<Object> o1 = Optional.ofNullable(null);
System.out.println(o1.orElseGet(() -> "default value")); // default value
- 注意:orElse 和 orElseGet 看似差不多,其实有很大不同;看下面例子
Shop shop = null;
System.out.println("test orElse");
Optional.ofNullable(shop).orElse(createNew());System.out.println("test orElseGet");
Optional.ofNullable(shop).orElseGet(()->createNew());
//createNew
private static Shop createNew() { System.out.println("create new");
return new Shop("尺子", 50);
}//输出:
test orElsecreate newtest orElseGetcreate new
Shop shop = new Shop("钢笔",100);
System.out.println("test orElse");
Optional.ofNullable(shop).orElse(createNew());System.out.println("test orElseGet");
Optional.ofNullable(shop).orElseGet(()->createNew());
//输出
test orElsecreate newtest orElseGet
从上面两个例子可以看到,当 Optional 为空时,orElse 和 orElseGet 区别不大,但当 Optional 有值时,orElse 仍然会去调用方法创建对象,而 orElseGet 不会再调用方法;在我们处理的业务数据量大的时候,这两者的性能就有很大的差异。
13.1.8. orElseThrow
如果有值则将其返回,否则抛出 supplier 接口创建的异常。
Optional<Object> o1 = Optional.ofNullable(null);
try {
o1.orElseThrow(() -> new Exception("异常!"));
} catch (Exception e) {
System.out.println("info:" + e.getMessage());
}//输出:info:异常!
13.1.9. map
如果有值,则对其执行调用 mapping 函数得到返回值。如果返回值不为 null,则创建包含 mapping 返回值的 Optional 作为 map 方法返回值,否则返回空 Optional。
Optional<String> optional = Optional.of("xiaoming");
String s = optional.map(e -> e.toUpperCase()).orElse("shiyilingfeng");
System.out.println(s); //输出: XIAOMING
13.1.10. flatMap
如果有值,为其执行 mapping 函数返回 Optional 类型返回值,否则返回空 Optional。与 map 不同的是,flatMap 的返回值必须是 Optional,而 map 的返回值可以是任意的类型 T
Optional<String> optional = Optional.of("xiaoming");
Optional<String> s = optional.flatMap(e -> Optional.of(e.toUpperCase()));
System.out.println(s.get()); //输出:XIAOMING
13.1.11. filter
List<String> strings = Arrays.asList("rmb", "doller", "ou");
for (String s : strings) {
Optional<String> o = Optional.of(s).filter(s1 -> !s1.contains("o"));
System.out.println(o.orElse("没有不包含o的"));
}//输出:
rmb
没有不包含o的
没有不包含o的
14. Java 小数点位数保留的解决方案
14.1. 第一种方法
使用DecimalFormat类
举个例子,假如我们需要保留两位小数,我们可以这样写
DecimalFormat df = new DecimalFormat("0.00");
测试如下:
double d = 0.200;
DecimalFormat df = new DecimalFormat("0.00");
System.out.println(df.format(d));
输出结果为:
0.20
若double d=0.000;输出结果为0.00;
若double d=0;输出结果为0.00;
若double d=41.2345;输出结果为41.23;
经测试,不管double d的值为多少,最后结果都是正常的两位小数。
同理若是保留一位小数DecimalFormat df = new DecimalFormat("0.0");其他以此类推
若是这种写法DecimalFormat df = new DecimalFormat("0.00"),不管传入的任何值,均保留两位小数
还有一种写法是这样:
double d = 41.123;
DecimalFormat df = new DecimalFormat("#.##");
System.out.println(df.format(d));
输出结果为:
41.12
若double d=2.00,输出结果为2;
若double d=41.001,输出结果为41;
若double d=41.010,输出结果为41.01;
若double d=0,输出结果为0;
若double d=0.200,输出结果为0.2;
总结:若是这种写法DecimalFormat df = new DecimalFormat("#.##"),则保留小数点后面不为0的两位小数,这种写法不能保证保留2为小数,但能保证最后一位数不为0;
14.2. 第二种方法
测试:
double d = 0.6544;
String s=String.format("%.2f",d);
System.out.println(s);
输出结果为:
0.65
若double d=0.6566,输出结果为0.66;
若double d=0,输出结果为0.00;
其中String s=String.format("%.2f",d)表示小数点后任意两位小数,其中2为表示两位小数,若需要三位小数,把2改为3即可,其他同理。
总结:这种方法不管传入的值是多少,均保留两位小数,并且符合四舍五入的规则。
14.3. 第三种方法:
使用BigDecimal类
测试:
double d = 1.000;
BigDecimal bd=new BigDecimal(d);
double d1=bd.setScale(2,BigDecimal.ROUND_HALF_UP).doubleValue();
System.out.println(d1);
输入结果:1.0
若double d=0,输出结果为0.0;
若double d=1.999,输出结果为2.0;
若double d=1.89,输出结果为1.89;
总结:使用这种写法若小数点后均为零,则保留一位小数,并且有四舍五入的规则。
15. 设置HashMap的初始值大小
了解了扩容机制后,现在回到开始的问题,已知集合有两个元素待加入,HashMap 的容量初始化为多少最合适?
只需要满足 capacity * 0.75 >= expectedSize 即可,所以容量设置可以使用如下公式
capacity = (int) Math.ceil((float) expectedSize / 0.75F)
15.1. Lists & Maps 工具类
如果觉得自己去理清这些东西比较麻烦的话,有人已经帮我们把这些都考虑到了,使用现成的工具类即可解决这些问题。
在 Guava 提供的工具类中,Lists 及 Maps 中提供了相应的 API
Map<String, Integer> map = Maps.newHashMapWithExpectedSize(2);
ArrayList 初始化时,设置容量为多少,数组长度即为多少,不会进行多一次计算
List<String> list = Lists.newArrayListWithCapacity(2);















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









