






目录
2.4 R的数据结构
2.4.1 R的对象与属性
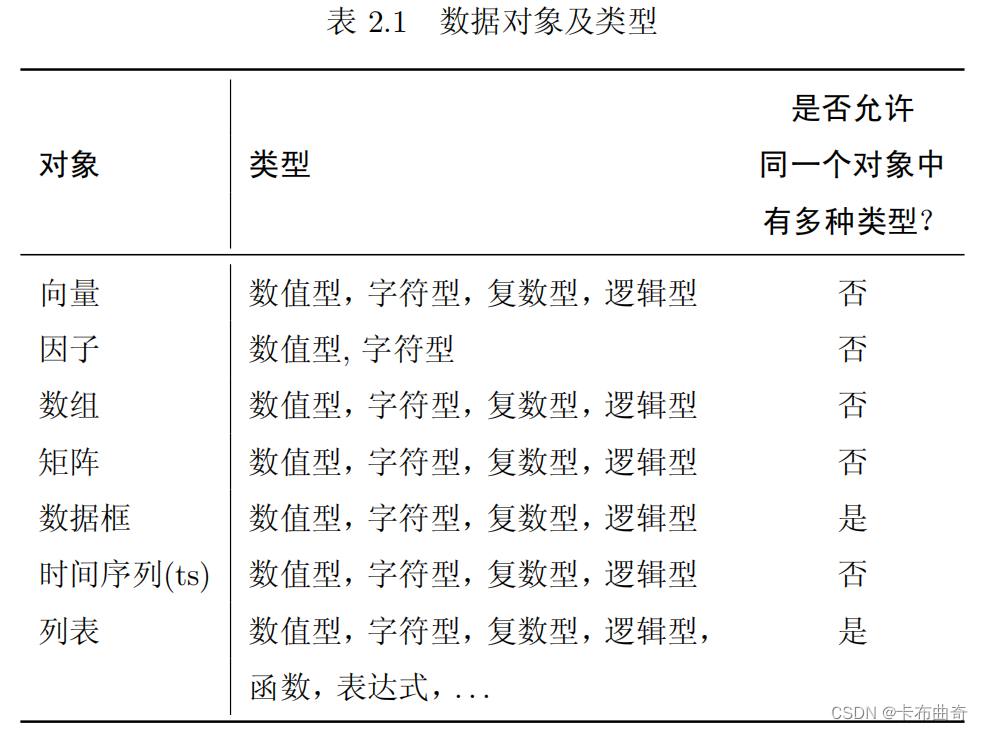
1) 向量是一个变量(的取值),是R中最常用、最基本的操作对象;因子是一 个分类变量;数组是一个k维的数据表;矩阵是数组的一个特例,其维数k =2.
注意
:
数组或者矩阵中的所有元素都必须是同一种类型的;数据框是由 一个或几个向量和(或)因子构成,它们必须是等长的,但可以是不同的数据类型;“ts
”表示时间序列数据,它包含一些额外的属性,例如频率和时间;列表可以包含任何类型的对象,包括列表!
2)
对于一个向量,用它的类型和长度足够描述数据;而其它的对象则另需一些额外信息,这些信息由外在的属性给出, 例如这些属性中的表示对象
维数的dim.
比如一个
2
行
2
列的的矩阵,它的
dim
是一对数值
[2,2]
,但是其长度是4.
3)
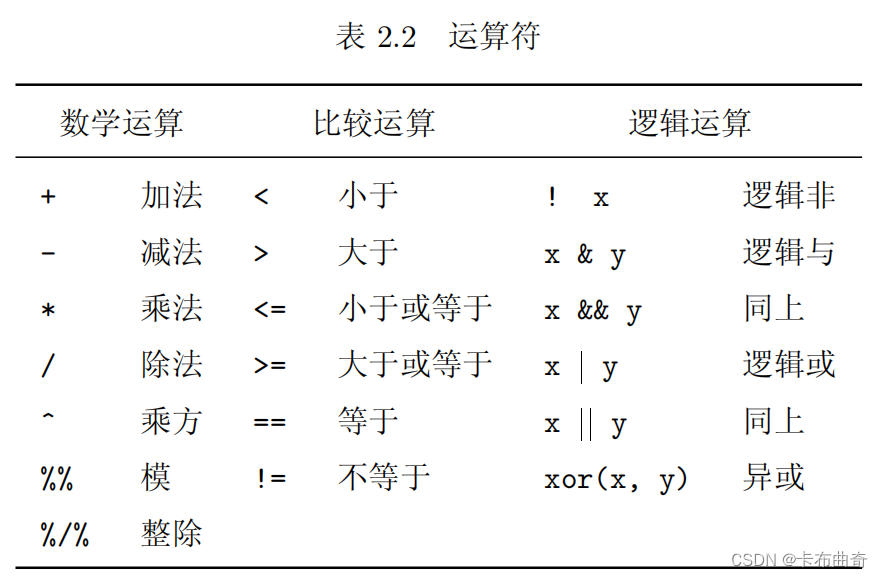
R
中有三种主要类型的运算符
,
表
2.2
是这些运算符的列表
.
2.4.2 浏览对象的信息
函数ls( )
的功能是显示所有在内存中的
对象名。如:
> name <- "Carmen"; n1 <- 10; n2 <- 100; m <- 0.5
> ls( )
[1] "m" "n1" "n2" "name"
如果只要显示出在名称中带有某个指定字符的对象,则通过设定选项pattern来实现(
可简写为
pat
) ):
> ls(pat = "m")
[1] "m" "name"如果进一步限定显示名称中以某个字母开头的对象,则可使用命令:
> ls(pat = "^m")
[1] "m"运行函数ls.str( )将会显示内存中所有对象的详细信息:
> ls.str( )
m : num 0.5 n1 : num 10 n2 : num 100 name : chr "Carmen"
要在内存中删除某个对象,可利用函数
rm( )
.
例如
运行
rm(x)
将会删除对象
x
运行
rm(x,y)
将会删除对象
x
和
y
运行
rm(list=ls( ))
则会删除内存中的所有对象
运行
rm(list=ls(pat="^m"))
则会删除对象中以字母
m
开头的对象
2.4.3 向量的建立
数值型向量的建立
统计分析中最为常用的是数值型的向量
,
它们可用下面的四种函数建立
:
1)
seq( )
或“
:” # 若向量(
序列
)
具有较为简单的规律
2) rep( ) # 若向量(
序列
)
具有较为复杂的规律
3) c( ) # 若向量(序列
)
没有什么规律
4) scan( ) # 通过键盘逐个输入
> 1:10
[1] 1 2 3 4 5 6 7 8 9 10
> 1:10-1
[1] 0 1 2 3 4 5 6 7 8 9
> 1:(10-1)
[1] 1 2 3 4 5 6 7 8 9 # 注意括号有无的区别
> z <- seq(1,5,by=0.5) # 等价于 seq(from=1,to=5,by=0.5)
> z
[1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
> z <- seq(1,10,length=11) # 等价于 seq(1,10,length.out=11)
> z
[1] 1.0 1.9 2.8 3.7 4.6 5.5 6.4 7.3 8.2 9.1 10.0
> z <- rep(2:5,2) # 等价于 rep(2:5, times=2)
> z
[1] 2 3 4 5 2 3 4 5
> z <- rep(2:5,rep(2,4))
[1] 2 2 3 3 4 4 5 5
> z <- rep(1:3, times = 4, each = 2)
> z
[1] 1 1 2 2 3 3 1 1 2 2 3 3 1 1 2 2 3 3 1 1 2 2 3 3
> z <- x<-c(42,7,64,9)
> z
[1] 42 7 64 9
> z <- scan( ) # 通过键盘建立向量
1: 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
10:
Read 9 items
> z
[1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
> z <- sequence(3:5)
> z
[1] 1 2 3 1 2 3 4 1 2 3 4 5
> z <- sequence(c(10,5))
> z
[1] 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5
字符型向量的建立
字符和字符向量在
R
中广泛使用,比如图表的标签
.
在显示的时候,相应的字符串由双引号界定,字符串在输入时可以使用单引号(’)
或双以号
(”).
引号(”)
在输入时应当写作
\
”.
字符向量可以通过函数
c( )
连接
.
函数
paste()
可以接受任意个参数,并从它们中逐个取出字符并连成字符串,形成的字符串的个数与参数中最长字符串的长度相同.
如果参数中包含数字的话,数字将被强制转化为字符串.
在默认情况下,参数中的各字符串是被一个空格分隔的,不过通过参数sep=string
用户可以把它更改为其他字符串,包括空字符串
.
例如
> Z <- c("green","blue sky","-99")
> Z
[1] "green" "blue sky" "-99"
> labs <- paste(c("X","Y"), 1:10, sep="")
> labs
[1] "X1" "Y2" "X3" "Y4" "X5" "Y6" "X7" "Y8" "X9" "Y10"
逻辑型向量的建立
与数值型向量相同,
R
允许对逻辑向量进行操作
.
一个逻辑向量的值可以是TRUE
,
FALSE
和
NA
.
前两个通常简写为
T
和
F
2
.
逻辑向量是由条件给出的
.
如
> x <- c(10.4, 5.6, 3.1, 6.4, 21.7)
> temp <- x > 13
> temp
[1] FALSE FALSE FALSE FALSE TRUE
> 7!=6
[1] TRUE
> !(7==6)
[1] TRUE
> !(7==6)==1
[1] TRUE
> (7==9)|(7>0)
[1] TRUE
> (7==9)&(7>0)
[1] FALSE
因子型向量的建立
一个因子或因子向量不仅包括分类变量本身,
还包括变量不同的可能水平(
即使它们在数据中不出现
).
因子利用函数
factor( )
创建
.
factor( )
的调用格式如下:
factor(x, levels = sort(unique(x), na.last = TRUE),
labels = levels, exclude = NA, ordered = is.ordered(x))
说明
:
levels
用来指定因子的水平
(
缺省值是向量
x
中不同的值
)
;
labels
用来指定水平的名字;exclude
表示从向量
x
中剔除的水平值;
ordered
是一个逻辑型选项,
用来指定因子的水平是否有次序
.
这里
x
可以是数值型或字符型
,
这样对应的因子也就称为数值型因子或字符型因子.
因此
,
因子的建立可以通过字符型向量或数值型向量来建立,
且可以转化
.
1) 将字符型向量转换成因子
> a <- c("green", "blue", "green", "yellow")
> a <- factor(a)
a
[1] green blue green yellow
Levels: blue green yellow
2) 将数值型向量转换成因子
> b <- c(1,2,3,1)
> b <- factor(b)
> b
[1] 1 2 3 1
Levels: 1 2 3
3) 将字符型因子转换为数值型因子
> a <- c("green", "blue", "green", "yellow")
> a <- factor(a)
> levels(a)<-c(1,2,3,4)
> a
[1] 2 1 2 3
Levels: 1 2 3 4
> ff <- factor(c("A", "B", "C"), labels=c(1,2,3))
> ff
[1] 1 2 3
Levels: 1 2 3
4) 将数值型因子转换为字符型因子
> b <- c(1,2,3,1)
> b <- factor(b)
> levels(b) <- c("low", "middle", "high")
> b
[1] low middle high low
Levels: low middle high
> ff <- factor(1:3, labels=c("A", "B", "C"))
ff
[1] A B C
Levels: A B C
注: 函数levels( )用来提取一个因子中可能的水平值, 例如
> ff <- factor(c(2, 4), levels=2:5)
> ff
[1] 2 4
Levels: 2 3 4 5
> levels(ff)
[1] "2" "3" "4" "5"
5) 函数gl( )能产生规则的因子序列. 这个函数的用法是gl(k,n),其中k是水平数, n是每个水平重复的次数. 此函数有两个选项:length用来指定产生数据的个数, label用来指定每个水平因子的名字. 例如:
> gl(3, 5)
[1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3
Levels: 1 2 3
> gl(3, 5, length=30)
[1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3
Levels: 1 2 3
> gl(2, 6, label=c("Male", "Female"))
[1] Male Male Male Male Male Male
[7] Female Female Female Female Female Female
Levels: Male Female
> gl(2, 10)
[1] 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2
Levels: 1 2
> gl(2, 1, length=20)
[1] 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2
Levels: 1 2
> gl(2, 2, length=20)
[1] 1 1 2 2 1 1 2 2 1 1 2 2 1 1 2 2 1 1 2 2
Levels: 1 2
数值型向量的运算
向量可以用于算术表达式中,操作是按照向量中的元素一个一个进行的.同一个表达式中的向量并不需要具有相同的长度,
如果它们的长度不同
,
表达式的结果是一个与表达式中最长向量有相同长度的向量,
表达式中较短的向量会根据它的长度被重复使用若干次(
不一定是整数次
)
,直到与长度最长的向量相匹配,
而常数将被不断重复
—
这一规则称为循环法则
(recycling rule).
例如,
命令
> x <- c(10.4, 5.6, 3.1, 6.4, 21.7)
> y <- c(x,0,x)
> v <- 2*x + y + 1
> 5+c(4,7,17)
[1] 9 12 22
> 5*c(4,7,17)
[1] 20 35 85
> c(-1,3,-17)+c(4,7,17)
[1] 3 10 0
> c(2,4,5)^2
[1] 4 16 25
> sqrt(c(2,4,25))
[1] 1.414214 2.000000 5.000000
> 1:2+1:4
[1] 2 4 4 6
> 1:4+1:7
[1] 2 4 6 8 6 8 10
Warning message:
长的目标对象长度不是短的目标对象长度的整倍数 in: 1:4 + 1:7
常用统计函数
最后列出统计分析中常用的函数与作用(
见表
2.1
).
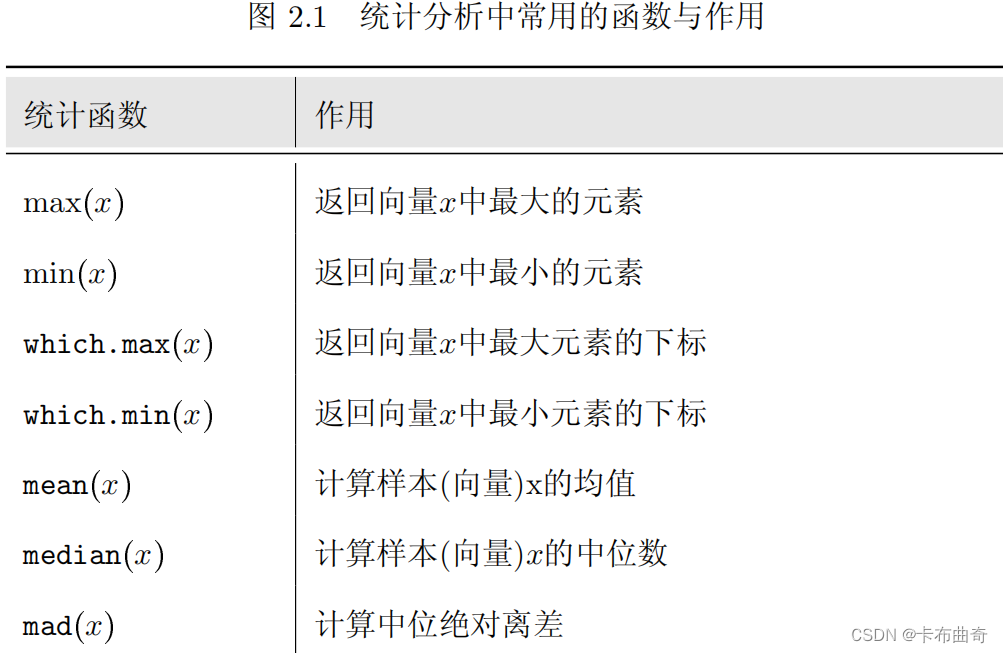



函数max(), min(), median( ), var( ), sd( ), sum( ), cumsum( ), cumprod( ), cummax( ), cummin( )对于矩阵及数据框的意义有方向性. 对于矩阵, cov( )和cor( ) 分别用于求矩阵的协方差阵和相关系数阵.
向量的下标(index)与子集(元素)的提取
选择一个向量的子集(元素)可以通过在其名称后追加一个方括号中的索引向量来完成. 更一般地,任何结果为一个向量的表达式都可以通过追加索引向量来选择其中的子集. 这样的索引向量有四种不同的类型.
1)
正整数向量
> x[1:10]
选取了
x
的前
10
个元素
(
假设
x
的长度不小于
10).
> x[c(1,4)]
取出向量
x
的第
1
和第
4
个元素
.
2)
负整数向量
> y <- x[-(1:5)]
从
x
中去除前
5
个元素得到
y
.
3)
字符串的向量
.
> fruit <- c(5, 10, 1, 20)
> names(fruit) <- c("orange", "banana", "apple", "peach")
fruit
orange banana apple peach
5 10 1 20
> lunch <- fruit[c("apple","orange")]
> lunch
apple orange
1 5
4)
逻辑的向量
> x <- c(42,7,64,9)
> x>10 # 值大于10的元素逻辑值
[1] TRUE FALSE TRUE FALSE
> x[x>10] # 值大于10的元素
[1] 42 64
> x[x<40&x>10]
numeric(0)
> x[x>10] <- 10
> x
[1] 10 7 10 9
>y = runif(100,min=0,max=1) #(0,1)上100个均匀分布随机数
>sum(y<0.5) # 值小于0.5的元素的个数
[1] 47
>sum(y[y<0.5]) # 值小于0.5的元素的值的和
[1] 10.84767
> y <- x[!is.na(x)] # x中的非缺失值
> z <- x[(!is.na(x))&(x>0)] # x中的非负非缺失值















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









