







 本文介绍了如何使用Python和Excel的Office365版本从PDF中提取表格数据。Python通过库实现,而Excel365提供直观的导入选项。尽管Python代码可重复利用,对于复杂表格提取,作者推荐使用Excel。
本文介绍了如何使用Python和Excel的Office365版本从PDF中提取表格数据。Python通过库实现,而Excel365提供直观的导入选项。尽管Python代码可重复利用,对于复杂表格提取,作者推荐使用Excel。
Hi~大家好!
不知大家在工作中有没有过提取pdf表格数据的经历,按照普通人的思维,提取pdf的表格数据的方法可能会选择复制粘贴,但这是一个相当繁杂且重复的工作。而今天我们会讲解如何用python和excel来提取pdf的表格数据,看二者哪个更为方便!
一、Excel
本次依然使用excel的神器power qoery编辑器,而接下来的操作其实和合并工作表差不多,让我们来看看它是怎么操作的!
office2016版本
excel提取pdf表格数据最好用office365版本,office2016版本的会没有来自PDF这个选项,且不会出现导航器界面,它会连文本一起导入,无法直接选择需要导入的表格,但他可以进入power qoery编辑器时进行筛选出Table类型的表格!二者差别只在于前面几步,看完后有疑问的可以在后台提问哦!
office365安装包(附教程)获取可在公众号后台发送:365 获取!
这里先说下office2016版本的前面操作,从文件导入PDF文件:

这里下面需要选择所有文件,然后导入pdf文件;然后会进入power qoery编辑器,需要筛选出Table类型的表格,然后office365到将查询追加为新查询这一步时,2016版本和365版本的一样:
office365版本
导入pdf文件:①点击【数据】→②点击【获取数据】→③点击【来自文件】→④选择【来自PDF】

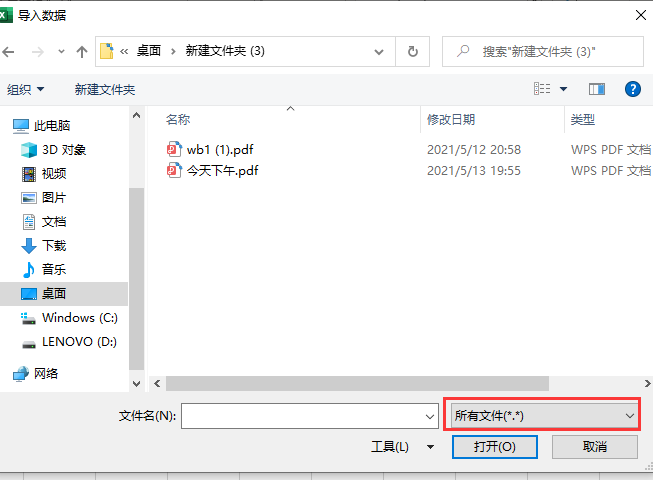
在弹出的【导入数据】窗口中选择PDF文件:

在弹出的【导航器】窗口中:①勾选【选择多项】→②在【pdf文件】下选择【Table类型的表格】→③查看数据,看是否为你需要的→④点击【转换数据】,跳转至power Query编辑器界面。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1323
1323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









