






```python
import pandas as pd
import os
read_path = ('D:\**\goods(1)\goods')
save_path = ('D:\**\goods(1)\goods')
save_name = 'change1.csv'
os.chdir(read_path) #改变当前路径,改为read_path路径
csv_name_list = os.listdir()
with open(csv_name_list[1]) as file:
data = pd.read_csv(file)
data.to_csv('D:\**\\000001.csv',encoding='utf_8_sig')
# A = data.to_csv(save_path + '\\' + save_name,index=False)
# A = df.to_csv(save_path + '\\' + save_name,index=False,encoding= 'utf-8')
# for i in range(len(df)):
# df = pd.read_csv( csv_name_list[i] )
# df.to_csv(save_path + '\\' + save_name ,encoding="utf-8",index=False, header=False, mode='a+')
# print(csv_name_list)
# print(csv_name_list[0])
先上代码,讲道理这个代码很简单,需求就是让CSV格式的内容合并(我要做的是先合并他们再把他们按月份分成不同表)就是这个合并,出现了乱码,合并是可以合并了
1、为啥出现乱码?
答:想了一晚上,我明明读取出来可以,但为啥导入却出现乱码?原来是encoding这个东西搞的鬼!!encoding居然有utf-8和utf_8_sig两种!!而且下划线和破折线还是不一样的,离谱!我昨晚各种方法都试了!
data.to_csv('D:\**\\000001.csv',encoding='utf_8_sig')
2、utf-8和utf_8_sig有啥区别?
答:我一开始认为没啥区别。。我一直写成utf-8-sig。。。NMD,居然也不报错。。。我一直在想,诶是不是要把它先转成GBK格式,在转换回来,BUT永远都在乱码。
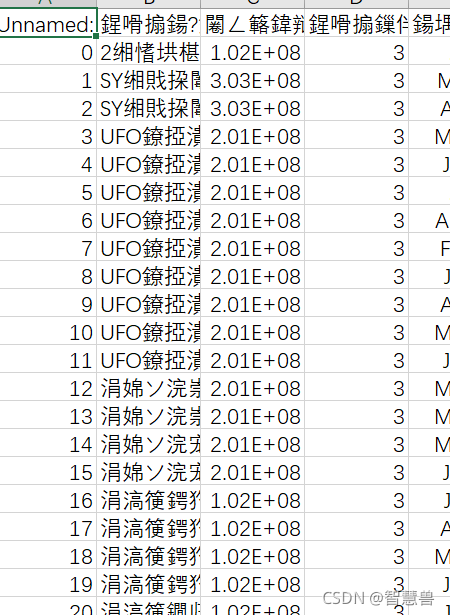
但关于UTF-8和UTF_8_sig区别还没在论坛上发现比较口语化的说明,我暂且理解为utf_8_sig是带有中文格式的编码,如果utf-8会出现乱码,就试试utf_8_sig吧!
PS:另外关于to_csv的保存内容,我还得在复习复习,感觉这个东西有点复杂,首先是参数mode,我刚刚试了一下,mode:'a’和mode:'a+'区别有点大(重点看看),现在我这边已经合并好表格了,接下来就是把它们按照月份划分。
f = ('D:\**\goods(1)\goods\change1.csv')
with open(f,"r",encoding=('utf-8')) as file:
data = pd.read_csv(file)
# print(data["月份"])
for i in data.groupby("月份"):
save_name = i[0]
i[1].to_csv('D:\网鱼\goods(1)\\'+save_name+".csv",encoding="utf_8_sig")
# A= data.groupby("月份")
利用月份划分,其实不难,只需要用好pd.groupby()这个聚合函数,我把月份进行一个聚合,只是这边出现了个问题(我是在CSV里调整日期格式,而不是PYTHON里调整,这里需要去学一下),然后进行一个for循环,save_name就是表名字,i[1]就是group by里内容(表内容),然后我再进行一个to_csv,就出来了。














 1440
1440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









