






正则化定义:凡是可以减少泛化误差,而不是去减小训练误差的方法,都可以称作为正则化方法。(直接理解:凡是能减小过拟合的方法,都叫做正则化方法)
本次主要介绍针对参数的正则化(针对参数,主要说的是
w
w
w)。
使用均方范数作为限制
可以通过限制参数值(一般来说是
w
w
w)的选择范围来控制模型容量/复杂度,进而防止过拟合:
m
i
n
l
(
w
,
b
)
,
∥
w
∥
2
≤
θ
\;\;\;\;\;\;\;\;min\,l(w,b),\lVert w \rVert^2\leq\theta
minl(w,b),∥w∥2≤θ
注:小的
θ
\theta
θ意味着更强的正则项
对于每个
θ
\theta
θ都可以找到
λ
\lambda
λ使上述的目标函数等价于下面的:
a
r
g
m
i
n
l
(
w
,
b
)
+
λ
2
∥
w
∥
\,\,\,\,\,\,\,\,\,\,\,\,\,arg \,\,min\,l(w,b)+\frac {\lambda} {2}\lVert w \rVert
argminl(w,b)+2λ∥w∥
可以通过拉格朗日乘子来证明,详细见https://www.bilibili.com/video/BV1Z44y147xA?spm_id_from=333.999.0.0
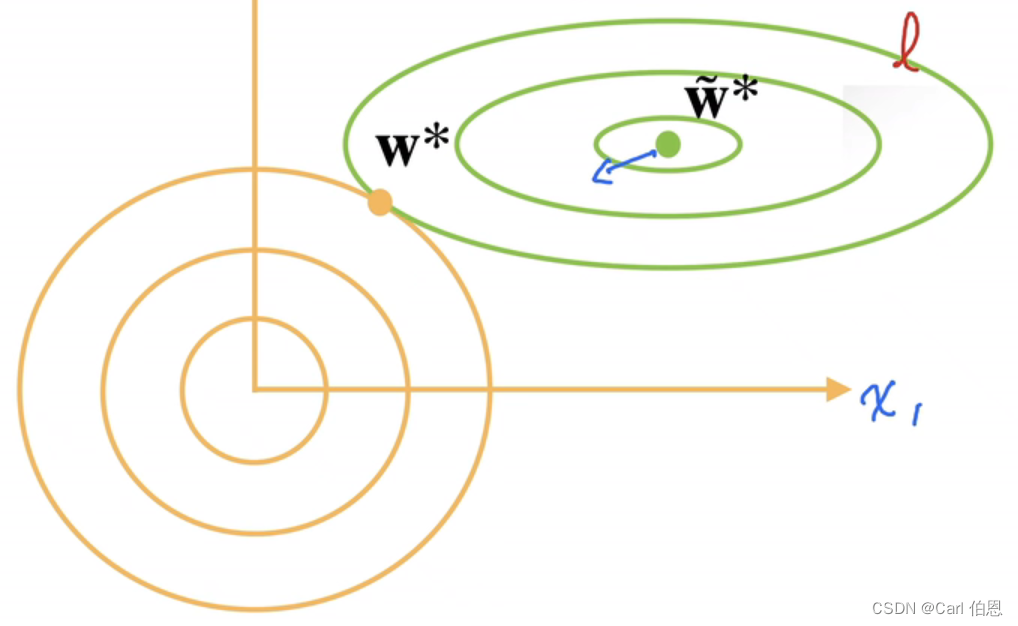
(绿色等高线代表损失函数 l l l,黄色的等高线代表我们加入的正则项(这里是 l 2 l_2 l2正则项)。)
原本经梯度下降到最小的
w
w
w为图中
w
∗
~
\widetilde{w^*}
w∗
,加入正则项后,要想使
a
r
g
m
i
n
l
(
w
,
b
)
+
λ
2
∥
w
∥
arg \,\,min\,l(w,b)+\frac {\lambda} {2}\lVert w \rVert
argminl(w,b)+2λ∥w∥,也就是将式子中的两项中和一下,则
w
∗
~
\widetilde{w^*}
w∗
会向黄色等高线方向移动。
通俗点讲,
w
∗
~
\widetilde{w^*}
w∗
受黄色等高线的吸引力,直到
w
∗
w^*
w∗时才保持平衡,此时取
w
∗
w^*
w∗会使
a
r
g
m
i
n
l
(
w
,
b
)
+
λ
2
∥
w
∥
arg \,\,min\,l(w,b)+\frac {\lambda} {2}\lVert w \rVert
argminl(w,b)+2λ∥w∥最小化。
正是因为加入正则项后,极小化损失函数 l l l所取得最优解 w ∗ ~ \widetilde{w^*} w∗ 向原点移动了,所以 w w w得取值减小了,所以也让模型得复杂度降低了。
参数更新法则
加入 L 2 L_2 L2正则项后,计算梯度
∂ ( l ( w , b ) + λ 2 ∥ w ∥ ) ∂ w \frac { \partial(l(w,b)+\frac {\lambda} {2}\lVert w \rVert)} {\partial w} ∂w∂(l(w,b)+2λ∥w∥)= ∂ l ( w , b ) ∂ w \frac { \partial l(w,b)} {\partial w} ∂w∂l(w,b)+ λ w \lambda w λw
更新参数
w
t
+
1
=
w
t
−
η
∂
(
l
(
w
t
,
b
)
+
λ
2
∥
w
t
∥
)
∂
w
t
w_{t+1}=w_t-\eta\frac { \partial(l(w_t,b)+\frac {\lambda} {2}\lVert w_t \rVert)} {\partial w_t}
wt+1=wt−η∂wt∂(l(wt,b)+2λ∥wt∥)
⇓
\qquad\qquad\qquad\Downarrow
⇓
w
t
+
1
=
(
1
−
η
λ
)
w
t
−
η
∂
l
(
w
t
,
b
)
∂
w
t
w_{t+1}=(1-\eta\lambda)w_t-\eta\frac { \partial l(w_t,b)} {\partial w_t}
wt+1=(1−ηλ)wt−η∂wt∂l(wt,b)
这里参照原来每次更新参数时都会多减去了 η λ w t \eta\lambda w_t ηλwt,通常 η λ < 1 \eta\lambda<1 ηλ<1,在深度学习中通常叫做权重衰退。
















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









