






点击蓝字,关注我们 作为DBA的你,是否曾遇到过CPU使用出现异常增长的情况? CPU使用率异常增长有多种原因,可能是查询负载过高、数据库服务器资源受限、参数设置不当等等。 本期为大家讲解某DBA在日常运维数据库时,遇到CPU使用率异常增长的故障处理案例。
2024年4月2日上午10点00分到10点20分,某电力客户某系统数据库CPU使用出现异常增长,平均达到了90%以上,峰值达到了100%;会话数也从10点20分开始持续升高,持续到10点28分会话数超过数据库最大连接数8000,业务会话受影响;10点50分数据库部分空闲会话kill,数据库可以连接,此时数据库会话数降低到6000左右;最终13点09分左右对数据库进行了重启操作,数据库连接数稳定在2000左右,CPU使用率也维持到50%左右,业务彻底恢复正常。
环境描述
openGuass 3.0.3版本主备模式架构。
故障处理

-
10点00分到10点20分某客户某系统数据库CPU使用出现异常增长使用率高达100%。
-
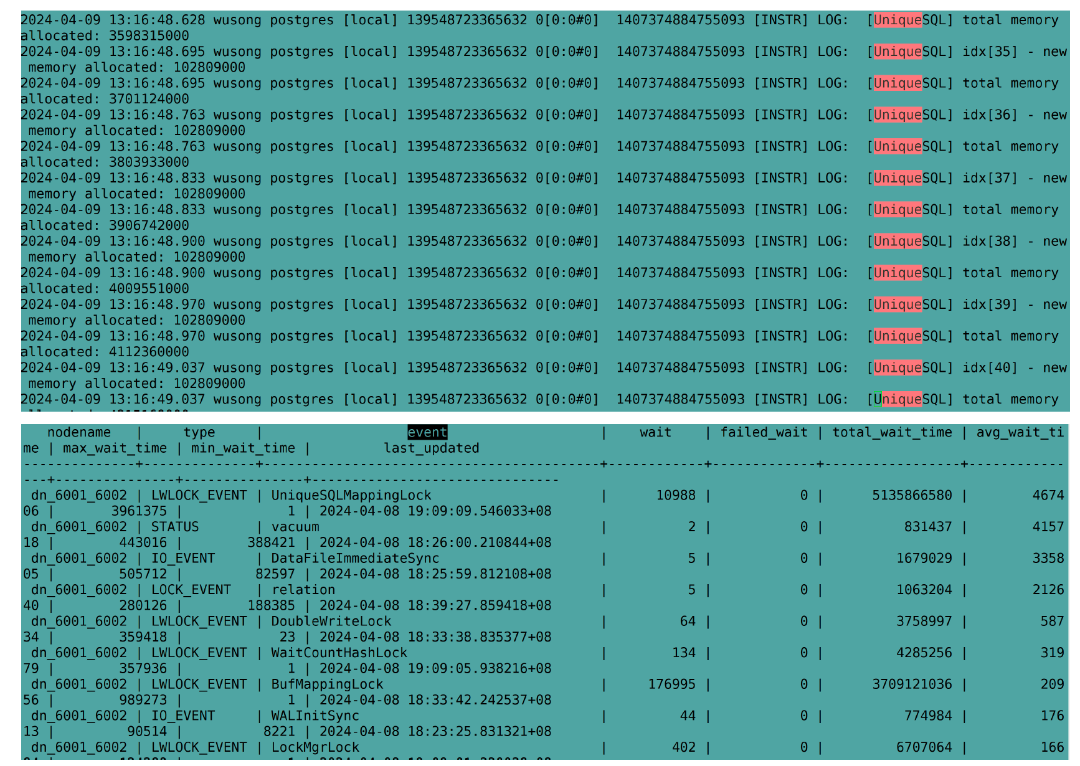
持续到10点28分会话数超过数据库最大连接数8000,此时业务会话受影响,在10点20到10点28分这个时段,UniqueSQLMappingLock等待会话数持续增加,从最开始的199个UniqueSQLMappingLock升高到4259个UniqueSQLMappingLock。
-
10点50左右采取kill部分空闲的会话,数据库连接数降低到6000左右,业务可以正常连接数据库,CPU使用率降低到70%左右,此时UniqueSQLMappingLock等待降低为1500左右。
-
13点09分左右对数据库进行了重启操作,并且扩容了shared buffer大小,之后数据库性能恢复正常,CPU使用率回落至50%左右,UniqueSQLMappingLock等待彻底消失。
故障现象
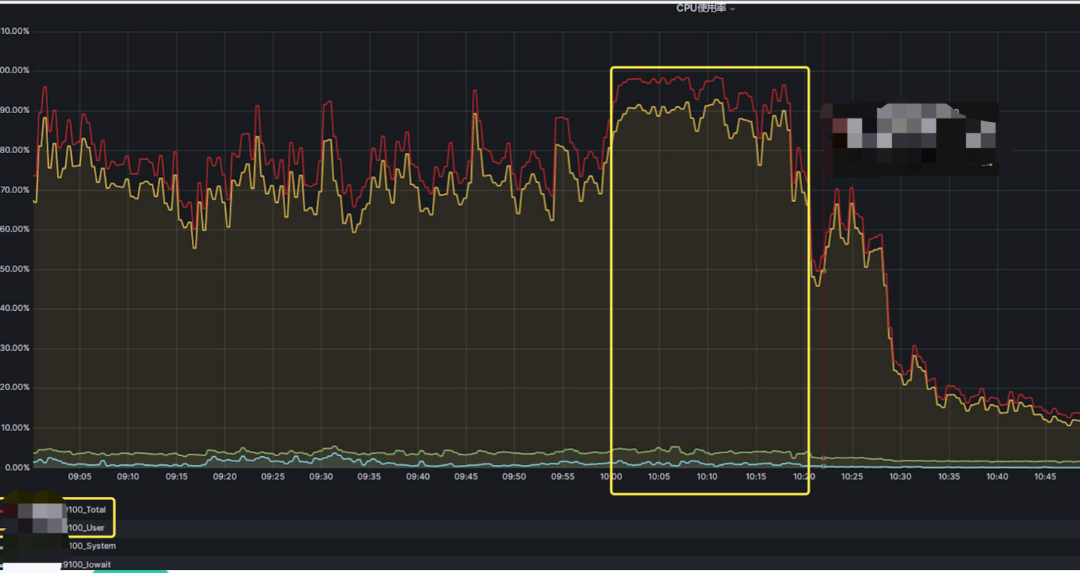
从上图可以看到:
-
数据库主机09:05:00至10:00:00,主机的CPU平均使用率已经达到70%左右,峰值会达到90%。
-
数据库主机10:00:00至10:20:00,主机的CPU平均使用率已经达到90%左右,峰值会达到100%。 这一负载与平日系统性能标准有显著偏差,平日系统CPU平均使用率业务繁忙期也就70%左右,峰值90%左右。
-
与此同时,内存、网络、IO等方面数据保持在正常范围内并无异常,系统主要的瓶颈还是CPU使用率较高,甚至峰值达到100%。
关于数据库主机CPU使用率100%的性能隐患:
1、性能下降:当CPU跑满时,服务器的处理能力已经达到极限,因此处理请求的速度变慢,响应时间延迟增加, 这将直接影响应用程序不稳定。
2、其他资源受限:当CPU负载高时,服务器上的其他资源,如内存、磁盘和网络带宽,可能会受到限制,从而 影响整体性能 。

通过上图zCloud数据库云管平台性能图表界面可以看到: 该系统在10:00:00到10:20:00时段,该系统的主机CPU使用率接近100%,较高的CPU使用率可能导致主机运行状态不稳定,进而导致数据库的各种内部调度任务响应时长受到影响,各项Latch、Lock、SQL响应时长增加等,数据库可能也因此出现各种异常等待,例如10点20到10点28分时段的uniquesqlMappinglock等待。 cpu 100%问题分析
zCloud数据库云管平台不仅可以图形化展示CPU使用趋势、内存消耗数等变化趋势,还可以展示TopSQL 详情,各会话连接消耗资源占比等。
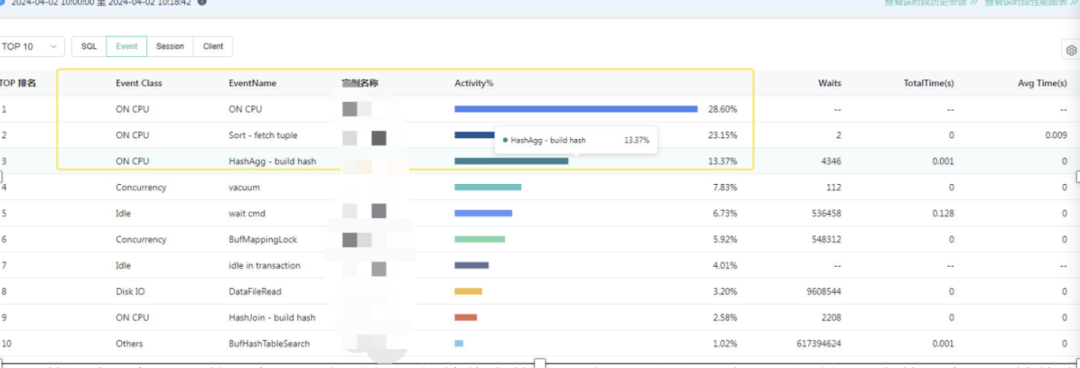
通过zCloud数据库云管平台展示的Top SQL界面可以看到:
数据库主机CPU使用率100%的时间段的等待事件:10点00分到10点20分时间段内数据库主要等待事件分类是on cpu、sort-fetch tuple和hashAgg-build hash,上述三个等待事件占据了数据库活动时间的63%以上,该等待事件主要由于出现大量top sql,大量的逻辑读 hash join 导致。
1、关于ON CPU等待: ON CPU等待主要是数据库运行相关SQL时候的IO读取写入(主要是逻辑读)、SQL解析、函数运算等消耗为主,我们希望数据库的主要等待事件是ON CPU为主,但是此时必须主机CPU使用率处于较低范围例如50%以下,如果此时主机CPU使用率依然较高,还是需要优化TOPSQL来降低ON CPU等待,进而降低系统主机的CPU使用率。
2、关于sort-fetch tuple等待: 表示是Sort算子做排序,fetch tuple表示Sort算子正在获取tuple,主要是SQL语句排序等消耗为主导致。
3、关于hashAgg-build hash等待: build hash表示当前HashAgg算子正在建立哈希表,主要用于SQL语句HASH Join关联产生的等待。
期间的主要TOPSQL优化分析如下:(后续TOPSQL重点优化,降低主机的CPU负载)
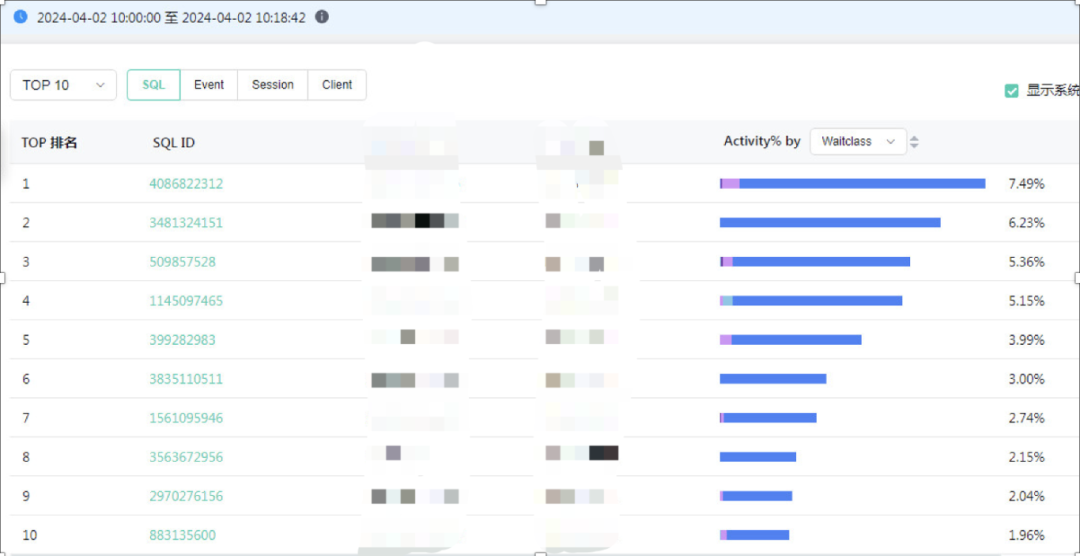
截取排名前面的TOPSQL语句全表扫描执行计划:
1、全表扫描业务表:
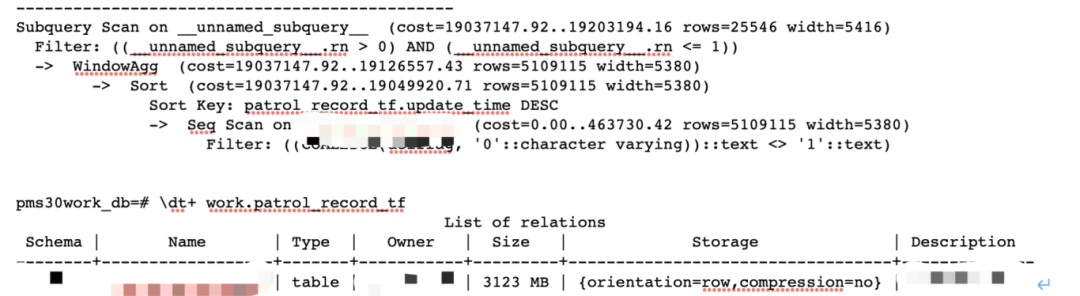
问题:
该SQL语句需要全表扫描,该表达到3GB容量,SQL的语句where语句并无合适的条件,无法使用索引去过滤数据,高并发的SQL全表扫描会消耗的较多的系统资源(CPU、IO等资源)。
2、全表扫描dbe_perf.statement视图
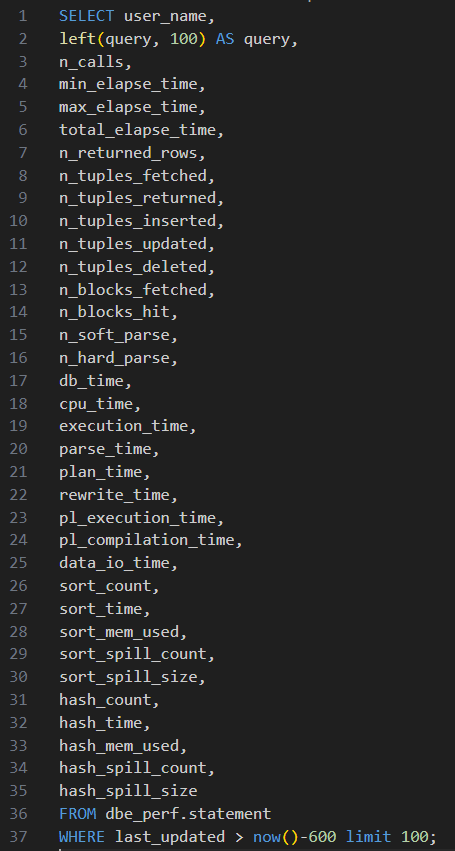
系统内一直有对dbe_perf.statement视图去做周期性的查询,获取相关的SQL语句用于监控,该SQL执行时间较长,单次需要20秒以上:
10点开始CPU使用率持续较高,并且峰值达到了100%,会话数的进一步增加,进而超过会话数最大值8000,业务受到影响。
10点18分到10点28分的会话数变化趋势:
-
10点18分会话数正常,连接会话数为2122;
-
10点20分会话数升高到2416(此时UniqueSQLMappinglock等待为199个);
-
10点24分会话数升高为5133(此时UniqueSQLMappingLock等待为2060);
-
10点28分会话数升高为8020(此时UniqueSQLMappingLock等待为4259);
-
2024-04-03_203328




关于UniqueSQLMappinglock数据库等待事件
UniqueSQLMappingLock在OpenGauss数据库中是用来控制对Unique SQL信息哈希表的并发访问的轻量级锁(LWLock)。Unique SQL是OpenGauss中用来追踪和统计数据库中执行的SQL语句的功能,它可以帮助数据库了解哪些SQL语句被执行,它们的执行频率,平均执行时间等信息。
在openGauss数据库中,Unique SQL信息是存储在一个全局哈希表中的。由于多个线程可能会同时尝试读取或更新这个哈希表中的信息,因此需要一个机制来保证对哈希表的访问是线程安全的。它确保在任何时候只有一个线程能够修改哈希表,而其他的线程必须等待直到UniqueSQLMappingLock锁被释放。
数据库归化unique sql的相关参数介绍
1、关于instr_unique_sql_count参数:
由于数据库在10点开始CPU持续升高,并且CPU使用率峰值达到了100%,此时数据库的归化SQL数量已经达到了instr_unique_sql_count数量250000,数据库将不会记录新的SQL都dbe_perf.statement视图中。为了收集更多的SQL语句来确认是否还有其他TOPSQL消耗较多的资源,数据库管理员在10点18分对数据库中的instr_unique_sql_count参数进行了调整,通过将该参数的值从250,000增加到300,000,能够扩大统计覆盖范围,可以记录更多的SQL语句。

之前也由于该业务系统数据库的业务SQL较多,为了更好的优化TOPSQL,也在线上调整该参数。这一调整基于文档的说明和之前的实践经验,已经证明这种方法能够有效地提高对资源密集型查询的识别能力,而不会牺牲数据库的稳定性或性能。
instr_unique_sql_count参数官方描述:
参数说明:控制系统中unique sql信息实时收集功能。配置为0表示不启用unique sql信息收集功能。
该值由大变小将会清空系统中原有的数据重新统计(备机不支持此能力);从小变大不受影响。
当系统中产生的unique sql条目数量(dbe_perf.statement/dbe_perf.summary_statement统计)大于instr_unique_sql_count时,若开启了unique sql自动淘汰(默认不开启,参数enable_auto_clean_unique_sql控制,默认该参数为off),则系统会按unique sql的更新时间由远到近自动淘汰一定比例的条目,使得新产生的unique sql信息可以继续被统计。若没有开启自动淘汰,则系统产生的新的unique sql信息将不再被统计。
默认值:100
取值范围:整型,0~2147483647
注意:
在开启自动淘汰的情况下,如果该值设置的较小,可能会导致系统频繁的进行自动淘汰,有可能会影响数据库系统性能,所以实际场景中建议不要将该值设置的过小,建议值为200000。
在开启自动淘汰的情况下,如果该值设置的较大(例如38347922),清理过程中可能会引发大内存问题而无法清理。
关于unique SQL自动淘汰enable_auto_clean_unique_sql参数:
由于开启unique SQL自动淘汰可能会引起wdr无法生成,因此该参数默认值也是off,默认不开启unique SQL自动淘汰任务。
enable_auto_clean_unique_sql参数官方描述:
参数说明:当系统中产生的unique sql条目数量大于等于instr_unique_sql_count时,是否启用unique sql自动淘汰功能。
取值范围:布尔型
默认值:off
注意:
由于快照有部分信息是来源于unique sql,所以开启自动淘汰的情况下,在生成wdr报告时,如果选择的起始快照和终止快照跨过了淘汰发生的时间,会导致无法生成wdr报告。
track_activity_query_size参数官方描述:
参数说明:设置用于跟踪每一个活动会话当前正在执行命令的字节数。
参数类型:POSTMASTER
取值范围:整型,100~102400
该参数控制记录单个uniqueSQL的最大行长,默认值是1024,该设置会直接对每个SQL分配这么大的内存区域,即使SQL文本远远小于该参数,也会分配这么大的内存区域。该参数一般不建议调整的特别大,避免较多的内存消耗,对于大部分系统1024已经足够,如果需要记录更长的SQL语句到相关视图,可以做一些变更调整。
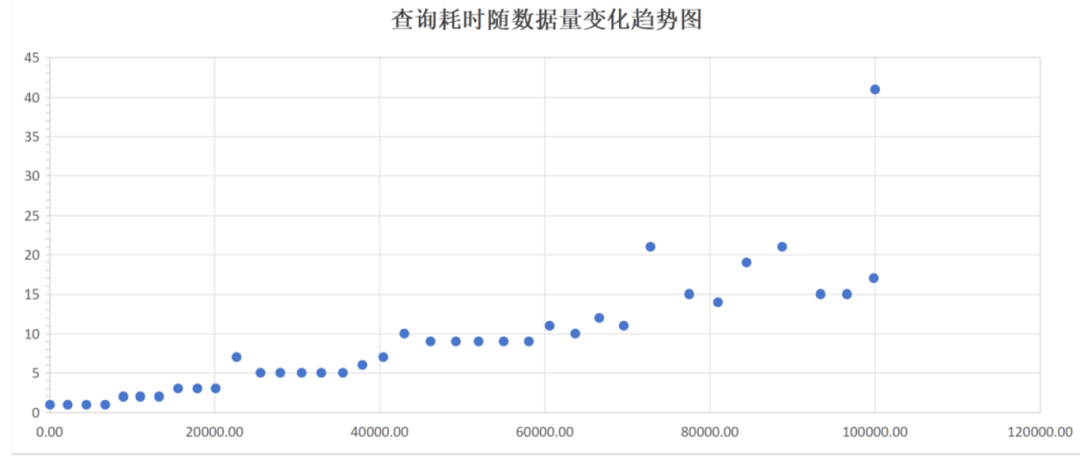
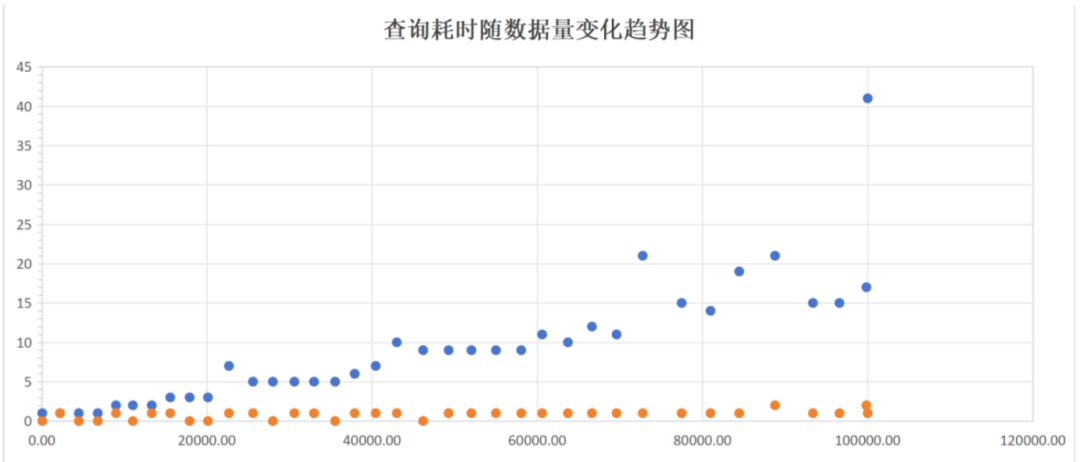
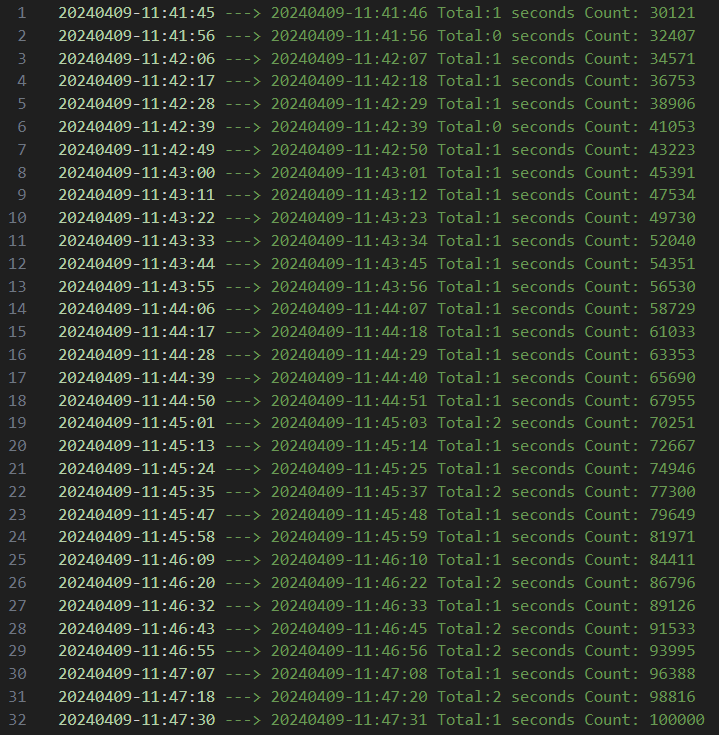
1、观察dbe_perf.statement查询耗时随着内存中unique sql条数增加变化曲线。测试过程中外部压力不变,通过构造空表的不同列的查询组合来模拟unique sql。CPU使用率为60%左右。
2. dbe_perf.statement 查询时间随着内存中unique sql数量越来越大,查询时间出现明显上涨。
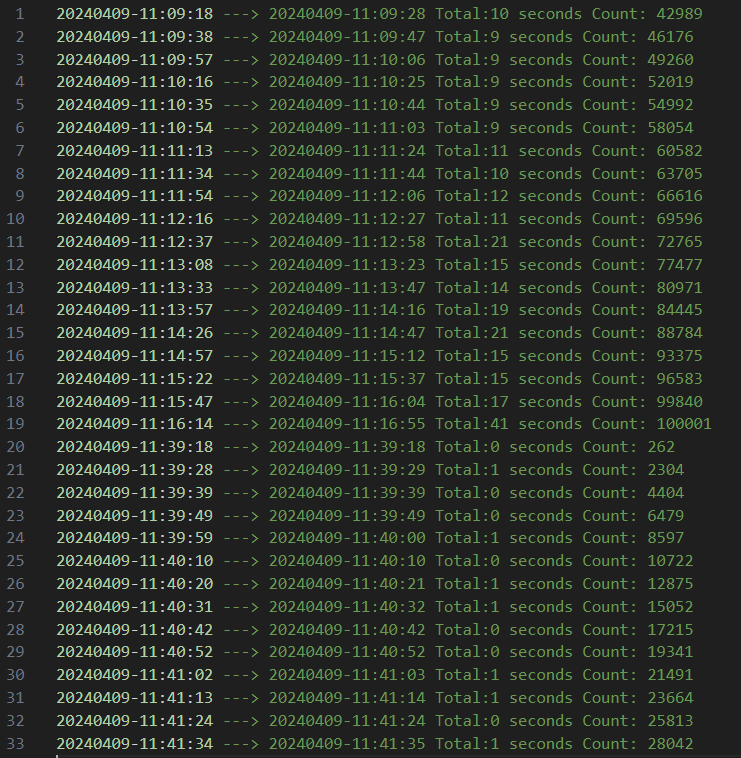
3. 参数track_activity_query_size 由51200 调整到1024 后, 相同测试条件下,dbe_perf.statement查询耗时如下。可以看到参数track_activity_query_size 调小后,查询耗时比较稳定,且数据库中未出现 【UniqueSQL】相关报错。
原理解释:
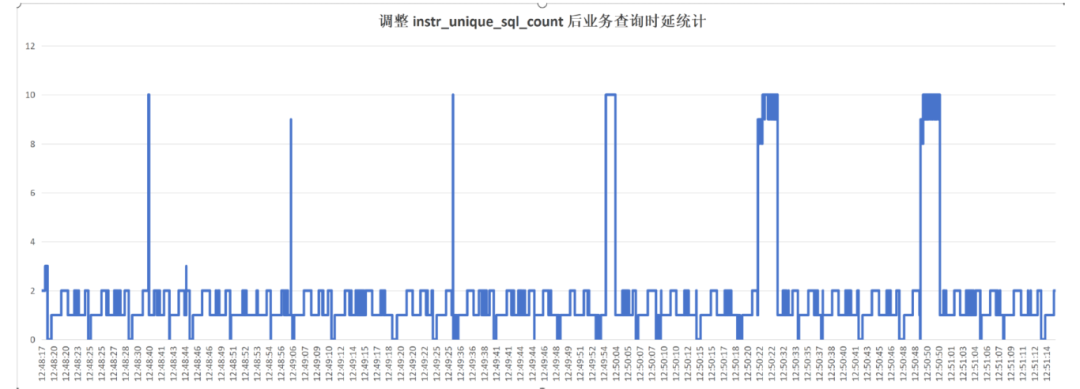
调大instr_unique_sql_count 后,内存的hash 表又可以写入,业务SQL 执行过程中需要向hashtabl写入数据,需要以EXCLUSIVE 模式申请UniqueSQLMappingLock ,会与查询dbe_perf.statement语句产生锁竞争。
下图是调整后业务时延随时间的变化图,可以看到业务有周期性的长时延,这与dbe_perf.statement的周期性查询有关。当查询dbe_perf.statement时,会导致业务SQL执行时间显著上升。这与之前故障环境修改参数后产生大量超时报错现象上是一致的。
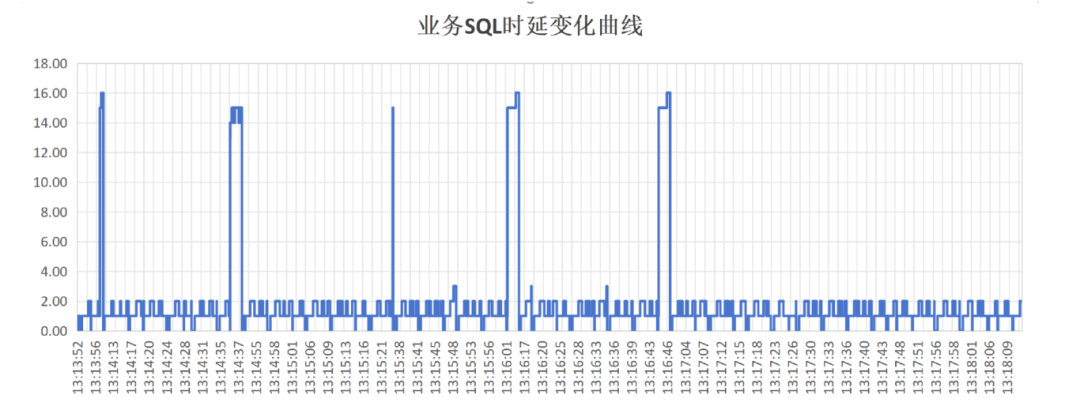
一旦内存中的unique sql 重新达到设置的最大值,业务SQL 就不会再去更新内存中hash 表,也就与查询dbe_perf.statement 不会有锁冲突,业务查询时延恢复到正常值。从下图可以看出unique sql达到最大值后,不再受dbe_perf.statement查询的影响。
此次问题的根源为 大量TOPSQL导致主机CPU使用率偏高 ,并且最终达到100%(特别大量全表扫描SQL),在CPU不足情况下数据库中SQL在执行过程中持有获取的锁时间将会加剧,业务SQL越跑越慢,连接数也会进一步的增加,系统出现大量的UniqueSQLMappingLock等待,并且最终超过数据库最大连接数8000,从而影响业务正常运行。
由于数据库目前的unique SQL数量已经达到了instr_unique_sql_count参数,不会记录新的SQL语句到数据库中。数据库管理员考虑到CPU使用率100%的风险,在线修改instr_unique_sql_count参数从250000为300000,以便可以收集更多的SQL语句来优化TOPSQL和降低CPU使用率,该参数之前也在线调整过并无异常,故障后也多次模拟在线修改该参数也并未触发异常,并且官方给出的文档中也并没有提及该参数修改可能会遇到相关风险和案例。
后续关于该参数instr_unique_sql_count修改和等待事件UniqueSQLMappingLock的关系模拟之后发现:
1、如果CPU系统本身负载较高,业务程序并发较大;
instr_unique_sql_count设置的较大,系统捕捉的uniqueSQL也就更多,并且track_activity_query_size设置的也比较大(本系统设置的102400),则instr_unique_sql_count*track_activity_query_size就是uniqueSQL部分的内存消耗为23.8GB(102400*250000/(1024*1024*1024))。
2、如果数据库在线调整instr_unique_sql_count参数期间,还有相关的UniqueSQLMappingLock资源请求发生(例如周期性的查询dbe_perf.statement视图获取相关SQL进行监控,该视图查询会请求UniqueSQLMappingLock资源),则可能触发和加剧更严重的等待竞争,例如出现严重的UniqueSQLMappingLock等待、on CPU等待。
总体分析: 基于目前的信息判断本次会话数超过最大连接数的主要原因还是主机CPU使用率达到100%诱因,此时导致数据库出现了较多的ON CPU、sort-fetch tuple和hashAgg-build hash等待;系统内的instr_unique_sql_count参数是250000,track_activity_query_size之前被调整为102400,这个设置导致uniqueSQL区域内存非常大,达到了23GB,系统内还有周期性的查询dbe_perf.statement视图(该视图就是uniqueSQL区域对应的视图,由于uniqueSQL达到了23GB,此时查询该视图就导致特别消耗资源,需要时间接近20秒以上还查询不出来)数据获取SQL语句来监控,如果此时调整instr_unique_sql_count参数,则可能进一步加剧系统负载,出现更为严重的UniqueSQLMappingLock和on cpu等待,进而达到数据库最大连接数8000,严重影响业务运行。
降低数据库的CPU负载优化业务SQL,确保CPU不会长时间处于高压力状态。当CPU承受过大压力时,数据库的整体性能可能会受到影响,包括但不限于数据块的访问、SQL语句的处理、WAL缓冲区的写入等关键操作的延迟。
instr_unique_sql_count变更规范:高CPU使用率场景下也不建议在线修改instr_unique_sql_count参数,避免在线修改参数触发openGauss数据库相关版本的未知缺陷或者不足(当前openGauss数据库目前版本是3.0.3版本,目前社区最新LTS版本是5.0.0版本)。
停机修改track_activity_query_size参数从102400降低到4096,为原来的4%,此时uniqueSQL区域将大幅度降低,也避免dbe_perf.statement视图查询时候出现的性能瓶颈。
附:数据库相关名词解释
1、uniqueSQLMappingLock等待:uniqueSQLMapping等待是用户保护数据库的uniquesql hash table,openGauss数据库中每个SQL语句会对应一个uniquesql,关于uniquesql解释如下:
用户执行SQL语句时,每一个SQL语句文本都会进入解析器(Parser),生成“解析树”(parse tree)。遍历解析树中各个结点,忽略其中的常数值,以一定的算法结合树中的各结点,计算出来一个整数值,用来唯一标识这一类SQL,这个整数值被称为Unique SQL ID,Unique SQL ID相同的SQL语句属于同一个“Unique SQL”。
例如,用户先后输入如下两条SQL语句:

这两条SQL语句除了过滤条件的常数值不同,其他地方都相同,由此生成的解析树的拓扑结构完全相同,故Unique SQL ID也相同。因此两条语句属于如下同一个Unique SQL:

GaussDB、Opengauss内核会对所有上面形式的SQL语句汇总统计信息,通过视图呈现给用户。通过这种方式,可以排除一些无关的常量值的干扰,获得某一类SQL语句的统计数据,为性能分析和问题定位提供数值依据。
2、instr_unique_sql_count参数:该参数控制unique SQL数量最大值,如果超过该数值(不开启SQL自动淘汰),则数据库不再记录新的SQL语句。
3、enable_auto_clean_unique_sql参数:该参数控制unique SQL自动淘汰特性是否开启,由于开启unique SQL自动淘汰可能会引起wdr无法生成,因此该参数默认值也是off,默认不开启unique SQL自动淘汰任务。
4、track_activity_query_size参数:该参数控制记录单个uniqueSQL的最大行长,默认值是1024,该设置会直接对每个SQL分配这么大的内存区域,即使SQL文本远远小于该参数,也会分配这么大的内存区域,该参数一般不建议调整的特别大,避免较多的内存消耗,对于大部分系统1024已经足够,如果需要记录更长的SQL语句到相关视图,可以做一些变更调整。
如果uniqueSQL超过track_activity_query_size该值,会导致数据库很多视图例如pg_stat_activity、db_perf.statement(uniqueSQL对应的视图)记录SQL出现截断,例如如下SQL测试用例
修改track_activity_query_size为100(该参数最小只能设置为100)
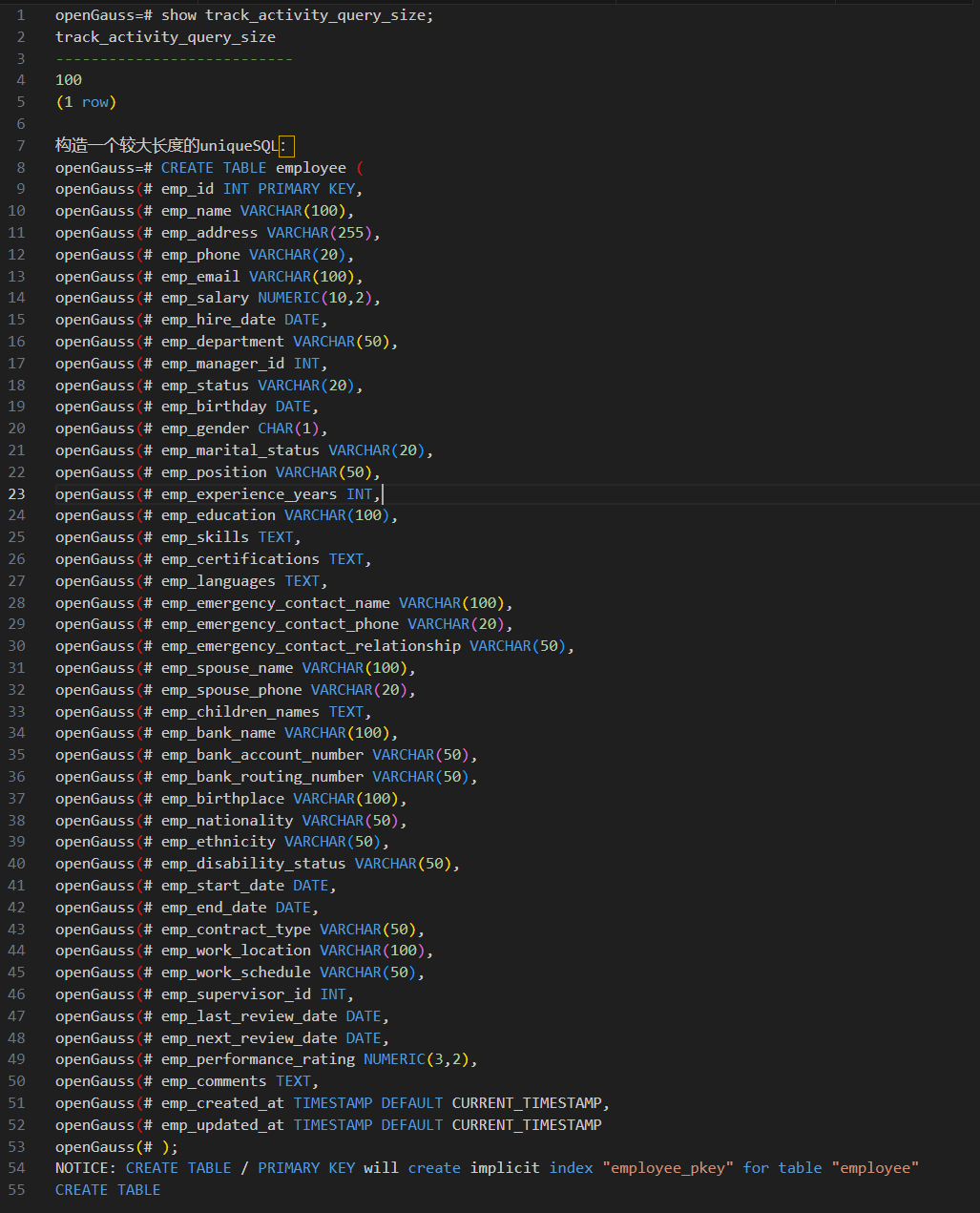
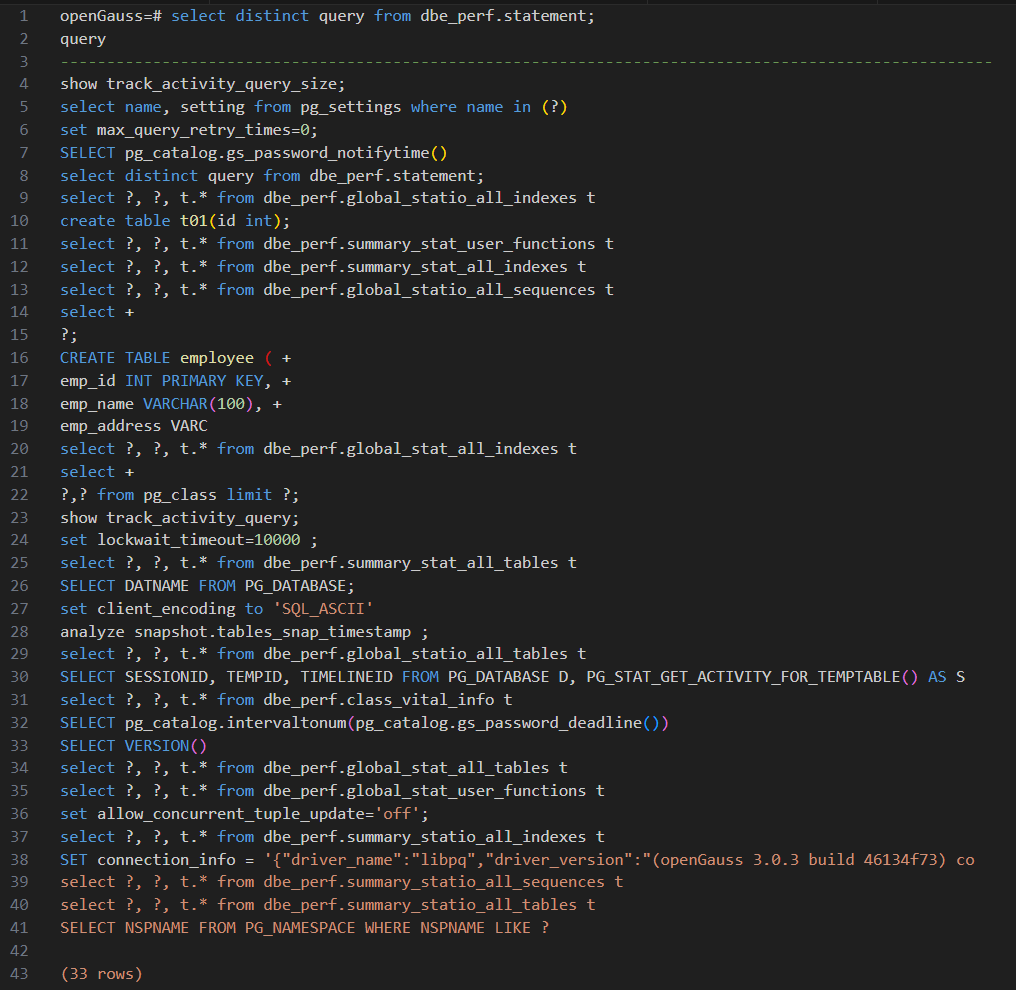
查看uniqueSQL对应的视图:create table对应的语句出现截断
上述处理CPU使用率异常增长的故障处理案例是不是又给了你新的灵感呢!
END 欢迎持续关注【zCloud智能运维经验分享】系列! 后续我们将为大家带来更多故障处理的经典案例! ( 访问zCloud 开放运维创新坊了解更多zCloud低代码能力: https://zcloud.enmotech.com/)

本文分享自微信公众号 - openGauss(openGauss)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“ OSC源创计划 ”,欢迎正在阅读的你也加入,一起分享。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











