






在百度学术中,当我们查找论文原文时,需要知道该论文的DOI(Digital Object Identifier),通过它可以方便、可靠地链接到论文全文。但是,如果我们所需查找的同主题论文数目繁多,这时候我们再手动操作,难免机械重复、劳心劳力。于是乎,我们可以通过Python来帮助我们实现论文的自动化查找。
主要思路是:爬取DOI→构建sci-hub下载链接→下载到指定文件夹
Python源代码如下:
【注】编辑器为JupyterNotebook!
# 导入所需模块
import requests
import re# 获取URL信息
def get_url(key):
url = 'https://xueshu.baidu.com/s?wd=' + key + '&ie=utf-8&tn=SE_baiduxueshu_c1gjeupa&sc_from=&sc_as_para=sc_lib%3A&rsv_sug2=0'
return url# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0',
'Accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Cookie': 'BIDUPSID=392A50D1602036829D4D83663DAB5E33; PSTM=1598783167; __yjs_duid=1_f559395b7ba14f64aff23f9d8995dfc71620357250648; H_WISE_SIDS=110085_127969_179347_184716_185638_188743_189660_191067_191254_191370_192382_194085_194529_195342_195468_196428_197241_197711_197956_198263_198418_199022_199082_199176_199440_199467_199567_199597_200150_200736_200993_201180_201191_201706_202058_202651_202759_202821_202906_203196_203310_203360_203504_203520_203606_203882_203886_204032_204099_204132_204203_204304_204321_204371_204659_204823_204860_204902_204941_205008_205086_205218_205235_205419_205430_205690_205813_205831_205920_206120_206353_206729_206734_206766_8000096_8000116_8000129_8000138_8000145_8000157_8000164_8000175_8000179_8000186; Hm_lvt_d0e1c62633eae5b65daca0b6f018ef4c=1651067269; MAWEBCUID=web_ccakfRUsJFnDDnXyWtcalXAVadIzWlmlxPOmGCxPgXyaSDcJgY; Hm_lvt_f28578486a5410f35e6fbd0da5361e5f=1656925444; H_WISE_SIDS_BFESS=110085_127969_179347_184716_185638_188743_189660_191067_191254_191370_192382_194085_194529_195342_195468_196428_197241_197711_197956_198263_198418_199022_199082_199176_199440_199467_199567_199597_200150_200736_200993_201180_201191_201706_202058_202651_202759_202821_202906_203196_203310_203360_203504_203520_203606_203882_203886_204032_204099_204132_204203_204304_204321_204371_204659_204823_204860_204902_204941_205008_205086_205218_205235_205419_205430_205690_205813_205831_205920_206120_206353_206729_206734_206766_8000096_8000116_8000129_8000138_8000145_8000157_8000164_8000175_8000179_8000186; BDUSS=FvZDRQVUNWbVY4VUltSUZSTUJvQ1poVUVIdVh6MW92S0pLT1lyUn53MEp0MlJqRVFBQUFBJCQAAAAAAAAAAAEAAADgUq-Zy6zAyrXE6sTOotCmAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAkqPWMJKj1jZz; BDUSS_BFESS=FvZDRQVUNWbVY4VUltSUZSTUJvQ1poVUVIdVh6MW92S0pLT1lyUn53MEp0MlJqRVFBQUFBJCQAAAAAAAAAAAEAAADgUq-Zy6zAyrXE6sTOotCmAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAkqPWMJKj1jZz; MCITY=-179:160:; BAIDUID=341A9FBAE5290A6E169DD43A9CD990D9:FG=1; BAIDUID_BFESS=341A9FBAE5290A6E169DD43A9CD990D9:FG=1; BA_HECTOR=a425aga18k2k2g8k242009ra1hnh4er1f; ZFY=:BybHCaJNuYUhkf0CNFay87ozUvsDn0pIJF0rM:BJkW1Y:C; RT="z=1&dm=baidu.com&si=esq53blym7&ss=lannr653&sl=0&tt=0&bcn=https://fclog.baidu.com/log/weirwood?type=perf&ld=8bq&ul=5b5go&hd=5b5ik"; BDRCVFR[ibifSmLtzfY]=mk3SLVN4HKm; delPer=0; PSINO=3; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm; BDRCVFR[Txj84yDU4nc]=mk3SLVN4HKm; BDRCVFR[A24tJn4Wkd_]=mk3SLVN4HKm; H_PS_PSSID=; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; ab_sr=1.0.1_NTBmNzRmZWMyYWEzYWQ1ODhhMjBlYzBkYmI3NWU0NDQxODRiN2U3ZDk0NjI1Zjg5N2JlMGUzMmFmZTkzMDJkOWE3YTc5YzE0M2I5MDI1OTk5ODdkMzExNmEyYjliZDUwNTBiODNlZGNmZjIzMTFhZjRiYmI3Y2U3MjNjNzc4YmVkY2U2M2M5MzQ0ZGQ2ZDIzOGRjZmY3NzVlN2UyZjIxZWVmZjZhMjZmNmMzMTJmNzg4YjYxNjI4OWNkZTM3NzI0; BD_CK_SAM=1; BDSVRTM=221'
}# 获取相关论文的DOI列表
def get_paper_link(headers, key):
response = requests.get(url=get_url(key), headers=headers)
response.encoding = 'utf-8'
res1_data = response.text
# print(res1_data)
# 找论文链接
paper_link = re.findall(r'<h3 class=\"t c_font\">\n +\n +<a href=\"(.*)\" data-click',
res1_data)
doi_list = [] # 用一个列表接收论文的DOI
for link in paper_link:
response2 = requests.get(url=link, headers=headers)
res2_data = response2.text
# 提取论文的DOI
try:
paper_doi = re.findall(r'\'doi\'}\">\n +(.*?)\n ', res2_data)
if str(10) in paper_doi[0]:
doi_list.append(paper_doi)
except:
pass
return doi_list【注】调用上一个代码块中的get_paper_link()函数,传入参数为“请求头”和“关键词”。
下方的代码块为测试代码:
a = get_paper_link(headers, 'cancer')
print(a)测试结果如下:

以上结果表明:获取的论文doi正常。
# 构建sci-hub下载链接
def doi_download(headers, key):
doi_list = get_paper_link(headers, key)
lst = []
for i in doi_list:
lst.append(list(i[0]))
for i in lst:
for j in range(8, len(i)):
if i[j] == '/':
i[j] = '%252F'
elif i[j] == '(':
i[j] = '%2528'
elif i[j] == ')':
i[j] = '%2529'
else:
i[j] = i[j].lower()
for i in range(len(lst)):
lst[i] = ''.join(lst[i])
for doi in lst:
down_link = 'https://www.sci-hub.ren/pdf/' + doi + '.pdf'
print(down_link)
file_name = doi.split('/')[-1] + '.pdf'
try:
with open(file_name, 'wb') as f:
r = requests.get(url=down_link, headers=headers)
f.write(r.content)
print('下载完毕:' + file_name)
except:
print("该文章为空")
pass# 检索及下载
key = input("请输入您想要下载论文的关键词(英文):")
doi_download(headers, key)以Philosophy(哲学)为例,运行结果如下:
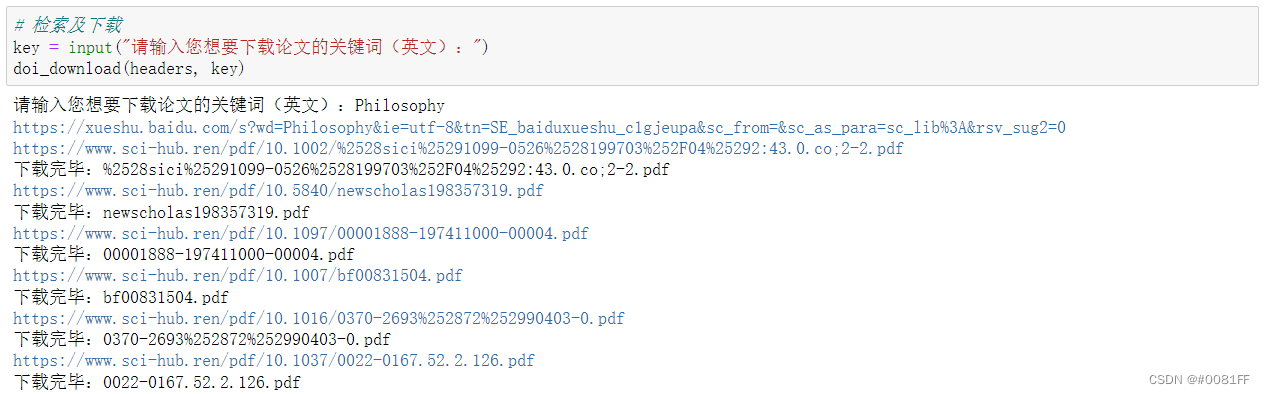
我们打开已经下载好的一篇论文:

全过程约 1 min,可见用Python进行论文自动化下载,的确在一定程度上提高了我们的工作效率!
笔者目前本科在读,因课业缘故,回复评论速度较慢,以后一定改正,还望各位监督。
同时,由于本人非科班出身,学习计算机编程全凭兴趣,因此水平有限,不足之处,还请指教!
最后感谢友友们的阅读和指正,源代码已做修改,之前的bug已经修复啦!
感谢各位读者对于本作品的支持,笔者也在为各位提出的问题的解答中受益良多。针对10个月以来大家所提出的问题,我简要地总结为以下三点:
- 请求头(headers)定义不充分或有错误,导致被Baidu或SCI-HUB“反爬”
- 论文DOI源地址(百度学术)和目的地址(SCI-HUB)的网站脚本结构出现变动,导致先前的程序无法适应
- 解析网站脚本(HTML)时出现错误
针对以上三点,笔者分别做出了以下修改,并覆盖了先前的代码(便于大家拷贝交流):
- 增加Accept和Cookie等headers参数以适应“百度安全验证”
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0',
'Accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Cookie': 'BIDUPSID=392A50D1602036829D4D83663DAB5E33; PSTM=1598783167; __yjs_duid=1_f559395b7ba14f64aff23f9d8995dfc71620357250648; H_WISE_SIDS=110085_127969_179347_184716_185638_188743_189660_191067_191254_191370_192382_194085_194529_195342_195468_196428_197241_197711_197956_198263_198418_199022_199082_199176_199440_199467_199567_199597_200150_200736_200993_201180_201191_201706_202058_202651_202759_202821_202906_203196_203310_203360_203504_203520_203606_203882_203886_204032_204099_204132_204203_204304_204321_204371_204659_204823_204860_204902_204941_205008_205086_205218_205235_205419_205430_205690_205813_205831_205920_206120_206353_206729_206734_206766_8000096_8000116_8000129_8000138_8000145_8000157_8000164_8000175_8000179_8000186; Hm_lvt_d0e1c62633eae5b65daca0b6f018ef4c=1651067269; MAWEBCUID=web_ccakfRUsJFnDDnXyWtcalXAVadIzWlmlxPOmGCxPgXyaSDcJgY; Hm_lvt_f28578486a5410f35e6fbd0da5361e5f=1656925444; H_WISE_SIDS_BFESS=110085_127969_179347_184716_185638_188743_189660_191067_191254_191370_192382_194085_194529_195342_195468_196428_197241_197711_197956_198263_198418_199022_199082_199176_199440_199467_199567_199597_200150_200736_200993_201180_201191_201706_202058_202651_202759_202821_202906_203196_203310_203360_203504_203520_203606_203882_203886_204032_204099_204132_204203_204304_204321_204371_204659_204823_204860_204902_204941_205008_205086_205218_205235_205419_205430_205690_205813_205831_205920_206120_206353_206729_206734_206766_8000096_8000116_8000129_8000138_8000145_8000157_8000164_8000175_8000179_8000186; BDUSS=FvZDRQVUNWbVY4VUltSUZSTUJvQ1poVUVIdVh6MW92S0pLT1lyUn53MEp0MlJqRVFBQUFBJCQAAAAAAAAAAAEAAADgUq-Zy6zAyrXE6sTOotCmAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAkqPWMJKj1jZz; BDUSS_BFESS=FvZDRQVUNWbVY4VUltSUZSTUJvQ1poVUVIdVh6MW92S0pLT1lyUn53MEp0MlJqRVFBQUFBJCQAAAAAAAAAAAEAAADgUq-Zy6zAyrXE6sTOotCmAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAkqPWMJKj1jZz; MCITY=-179:160:; BAIDUID=341A9FBAE5290A6E169DD43A9CD990D9:FG=1; BAIDUID_BFESS=341A9FBAE5290A6E169DD43A9CD990D9:FG=1; BA_HECTOR=a425aga18k2k2g8k242009ra1hnh4er1f; ZFY=:BybHCaJNuYUhkf0CNFay87ozUvsDn0pIJF0rM:BJkW1Y:C; RT="z=1&dm=baidu.com&si=esq53blym7&ss=lannr653&sl=0&tt=0&bcn=https://fclog.baidu.com/log/weirwood?type=perf&ld=8bq&ul=5b5go&hd=5b5ik"; BDRCVFR[ibifSmLtzfY]=mk3SLVN4HKm; delPer=0; PSINO=3; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm; BDRCVFR[Txj84yDU4nc]=mk3SLVN4HKm; BDRCVFR[A24tJn4Wkd_]=mk3SLVN4HKm; H_PS_PSSID=; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; ab_sr=1.0.1_NTBmNzRmZWMyYWEzYWQ1ODhhMjBlYzBkYmI3NWU0NDQxODRiN2U3ZDk0NjI1Zjg5N2JlMGUzMmFmZTkzMDJkOWE3YTc5YzE0M2I5MDI1OTk5ODdkMzExNmEyYjliZDUwNTBiODNlZGNmZjIzMTFhZjRiYmI3Y2U3MjNjNzc4YmVkY2U2M2M5MzQ0ZGQ2ZDIzOGRjZmY3NzVlN2UyZjIxZWVmZjZhMjZmNmMzMTJmNzg4YjYxNjI4OWNkZTM3NzI0; BD_CK_SAM=1; BDSVRTM=221'
}- 更正源和目的地址(主要是目的地址)以确保程序正常访问(200)
for doi in lst:
down_link = 'https://www.sci-hub.ren/pdf/' + doi + '.pdf'
print(down_link)
file_name = doi.split('/')[-1] + '.pdf'- 完善正则表达式以确保爬虫正确解析网站脚本获取有效数据
# 找论文链接
paper_link = re.findall(r'<h3 class=\"t c_font\">\n +\n +<a href=\"(.*)\" data-click',
res1_data)
doi_list = [] # 用一个列表接收论文的DOI
for link in paper_link:
response2 = requests.get(url=link, headers=headers)
res2_data = response2.text
# 提取论文的DOI
try:
paper_doi = re.findall(r'\'doi\'}\">\n +(.*?)\n ', res2_data)
if str(10) in paper_doi[0]:
doi_list.append(paper_doi)
except:
pass















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









