







awk命令的简要处理流程
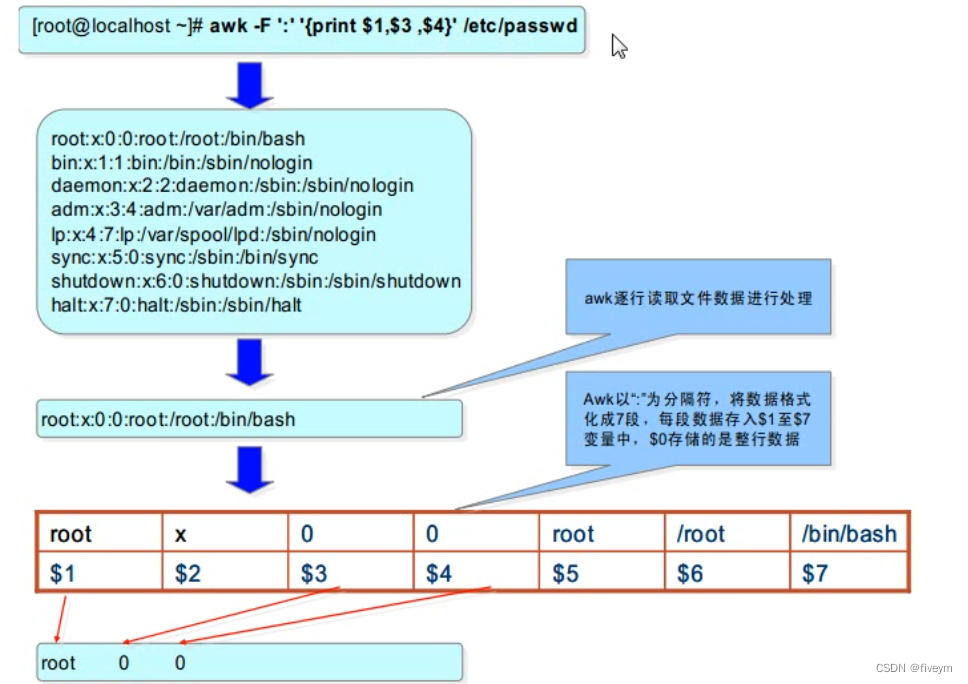
awk命令的执行过程
awk 'BEGIN{commands} pattern{commands} END{commands}'files
- 执行BEGIN {commands}语句块中的语句
- 从文件或stdin中读取第一行
- 有无模式匹配,若无则执行{}中的语句
- 若有则检查该整行与pattern是否匹配,则执行{}中的语句
- 若不匹配则不执行{}中的语句,接着读取下一行
- 重复这个过程,直到所有行被读取完毕
- 执行END{commands}语句块中的语句
[root@kafka3 lianxi]# cat a.txt
山东 aa 2
河南 bb 3
江西 cc 3
山东 bb 10
江西 dd 6
[root@kafka3 lianxi]# cat a.txt | awk '{pro[$1] += $3}END{ for (i in pro) print i,pro[i] }'
河南 3
江西 9
山东 12
NR
NR表示行号,是awk内置的一个变量
number of record —>行号
[root@kafka3 nginx]# w
13:43:14 up 4:11, 2 users, load average: 0.08, 0.04, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root tty1 09:26 1:44m 0.01s 0.01s -bash
root pts/1 192.1x8.1x1.1 11:59 2.00s 3.82s 0.00s w
[root@kafka3 nginx]# w|awk '{print $3}'
4:11,
FROM
09:26
192.168.171.1
[root@kafka3 nginx]# w|awk 'NR>=3 {print $3}'
09:26
192.168.171.1
[root@kafka3 nginx]#
输出分割符和输入分割符
OFS输出分隔符
FS输入分割符,也可以用-F表示
[root@kafka3 /]# awk 'BEGIN{FS=":"}OFS="#"{print $1,$3}' /etc/passwd
root#0
bin#1
daemon#2
adm#3
lp#4
sync#5
shutdown#6
案例
[root@kafka3 /]# ps aux | awk '$3 >0.1 || $4 >0.1 {print $2,$11 }'
1 /usr/lib/systemd/systemd
709 /usr/bin/VGAuthService
710 /usr/bin/vmtoolsd
711 /usr/lib/polkit-1/polkitd
725 /usr/sbin/NetworkManager
1001 /usr/bin/python2
[root@kafka3 /]# watch -n 2 -d "ifconfig|awk 'NR==5{print $5}'"
#显示每隔两秒显示的流量变化
awk命令引用shell变量
-v引入shell变量
#!/bin/bash
name=haha
echo | awk '{print $name}'
#!/bin/bash
name=haha
echo |awk -v abc=$name '{print abc}'
awk的几个内置函数
length函数,统计长度
[root@kafka3 ~]# awk -F: 'length($1)>=5&&length($1)<=10&&$3>500&&/bash$/{print NR,$1,$7}' /etc/passwd
27 sanle1 /bin/bash
34 yanding /bin/bash
37 luyunchao /bin/bash
38 xiayixing /bin/bash
43 zhaoliying /bin/bash
split函数,切割出来存放到一个数组里,下标从1开始
[root@kafka3 ~]# awk -F: 'length($1)>=5&&length($1)<=10&&$3>500&&/bash$/{split($7,s,"/");print NR,$1,s[1],s[2],s[3]}' /etc/passwd
27 sanle1 bin bash
34 yuanding bin bash
37 luyunchao bin bash
38 xiayixing bin bash
43 zhaoliying bin bash
substr函数,一个切片操作,substr($1,1,4)
[root@kafka3 ~]# awk -F: 'length($1)>=5&&length($1)<=10&&$3>500&&/bash$/{split($7,s,"/");print NR,substr($1,1,4),s[1],s[2],s[3]}' /etc/passwd
27 sanl bin bash
34 yuan bin bash
37 liuy bin bash
38 xiay bin bash
43 zhao bin bash
流控
if语句
[root@kafka3 ~]# ifconfig | awk 'NR==4||NR==6{if($1 == "RX")print "接受的流量:"$5;else print "发送的流量:"$5}'
接受的流量:1116716
发送的流量:42797852
数组
awk里如何使用数组来存放数据?
1.将所有/etc/passwd所有的用户存放在user数组里
[root@kafka~]# cat /etc/passwd|awk -F :'{user[$1]=$3}
将$3里的值赋值给user[$1]数组,$1其实就是/etc/passwd里的用户名
将用户和用户对应的uid将其关联,用户名做些表关键字,uid做数组元素对应的值
awk里如何取出数组里存放的数据?
2.将user数组的值全部取出来
[root@kafka3 ~]# cat /etc/passwd|awk -F: ‘{user[$1]=$3}END{for (i in user)print i,user[i]}’
[root@kafka3 ~]# cat /etc/passwd|awk -F: '{user[$1]=$3}END{for (i in user)print i,user[i]}'
adm 3
yuanding 2011
wyy 2016
案例
[root@kafka3 lianxi]# cat a.txt
山东 aa 2
河南 bb 3
江西 cc 3
湖南 aa 40
山东 bb 10
江西 dd 6
河北 cc 3
湖南 cc 3
[root@kafka3 lianxi]# cat a.txt|awk '{b[$1]+=$3}END{for (i in b)print i,b[i]}'|sort -k2 -n
河北 3
河南 3
江西 9
山东 12
湖南 43
[root@kafka3 lianxi]#















 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









