






制约程序性能的根源
常用的性能评估指标
- 并发:同一时间多少请求访问:如同一时间10个用户请求,并发就是10
- TPS:transaction per second:相当于写操作
- QPS:query per second:相当于读请求,从数据库读出写到缓存一般认为是QPS
- 耗时:
端到端耗时,从发起到结束,影响用户体验的耗时,包含了网络耗时;
服务端耗时,出去了公网的网络带宽,是机房内网串联的耗时;
应用程序耗时,摒弃了外围的存储,外围的数据库和外围的一些系统,单纯的应用程序的耗时,最小原子化耗时
95线:95%的请求落在什么范围内
99线:99%的请求落在什么范围内
制约程序性能的根源到处都在,可以分为以下几部分
- 网络
- 应用本身
- 数据库
- 缓存
- 消息
- 操作系统
- 内存
- IO
- CPU
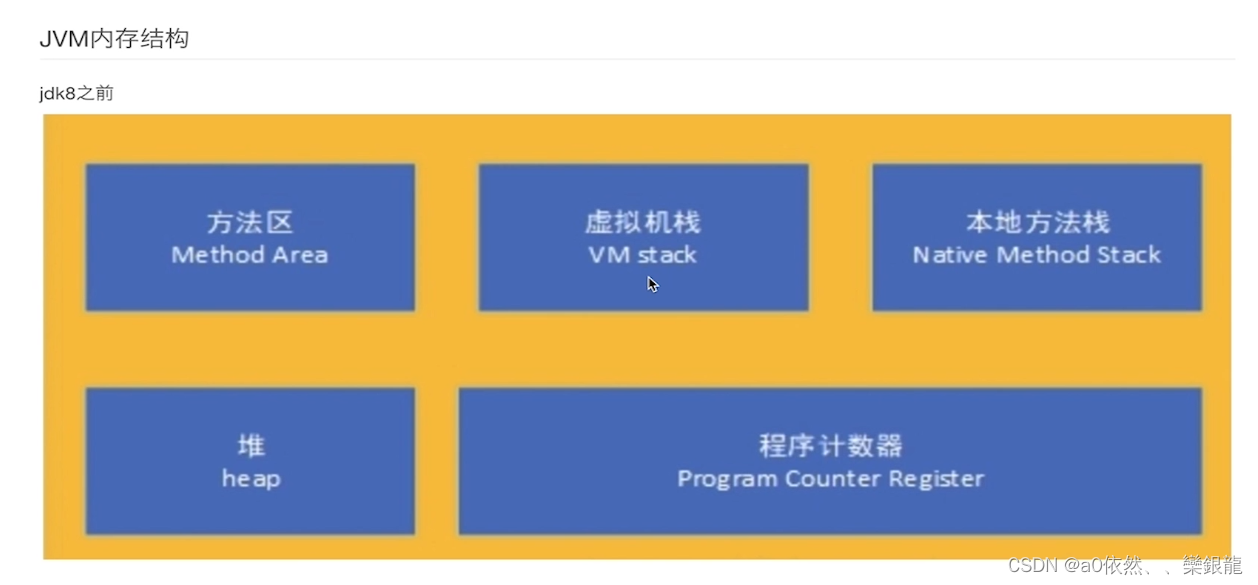
- 程序计数器(线程私有,每个线程均有一个自己的程序计数器)
记录虚拟机字节码指令的地址(当前指令的地址,记录当前线程运行到了哪里) - java虚拟机栈
线程私有,每个方法(public,private等等)在执行的时候也会创建一个栈帧,存储了局部变量,操作数,动态链接,方法返回地址;靠入栈和出栈来完成 - 本地方法栈
和虚拟机栈类似,主要为虚拟机使用到的Native方法服务 - 堆
被所有线程共享的一块区域内存,在虚拟机启动的时候创建,用于存放对象实例(所有new的对象)。 - 方法区
用于存储已经被虚拟机加载的类信息class,常量,静态变量等
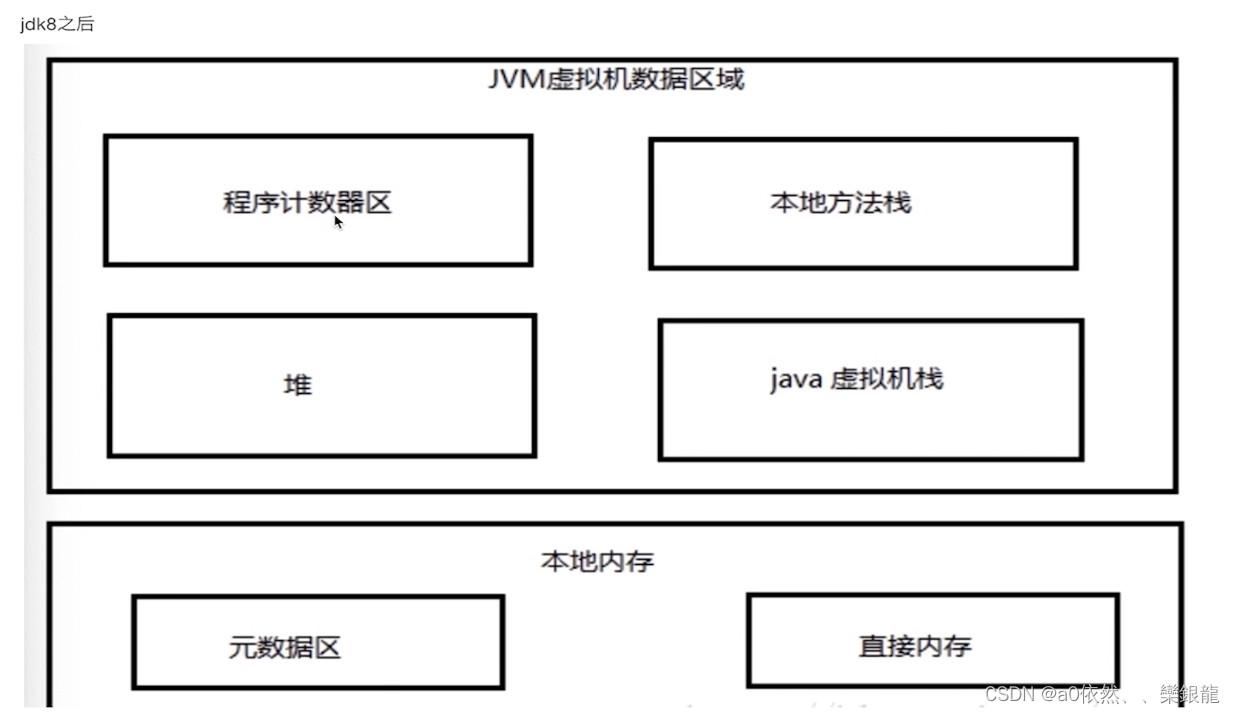
- 元数据区
替代永久代,类信息class,常量,静态变量等,字符串在1.7开始放到了堆中
GC算法
1.算法本质
- 标记-清除
优点:简单
缺点:碎片化,导致可能某一大对象可以存放,而被碎片化之后不能存放了 - 复制
优点:吞吐量高,无碎片化
缺点:空间利用率低 - 标记-整理
优点:兼顾了时间和空间问题
缺点:效率非最优
2.算法策略
分代GC回收算法
-
年轻代:复制算法
1.Eden(1个,新生代区),新创建对象首先放这里,达到一定阈值触发GC,首次GC把有引用的复制到随机一个Survivor区域如1,清空Eden; ,第二次触发GC时会把使用的Survivor1和Eden在使用的复制到另一个Survivor2中清空前一个有数据的Survivor1,第三次时会把Eden和第二次有数据的Survivor2复制到前面清空的Survivor1,然后清空Survivor2
2.Survivor(两个,幸存者区) -
老年代:标记整理算法,15次的垃圾回收仍存活会从年轻代进入老年代。老年代快满之后会触发老年代的GC;老年代和年轻代同时快满时会触发FullGC
-
串行Serial,并行Parallel
-
CMS(Concurrent Mark-Sweep Collector)
1.Initial Mark初始标记:标记可直达的存活对象
2.Concurrent Mark并发标记:通过遍历第一阶段(Initial Mark)标记出来的存活对象继续递归遍历老年代,并标记可直接或间接达到的所有老年代存活对象
3.Concurrent Preclean并发预清理:将会重新扫描前一个阶段标记的Dirty对象直接或间接引用的对象,然后清除Card标识
4.Concurrent Abortable Preclean可中止的并发预处理:尽可能承担更多的并发预处理工作,从而减轻在Final Remark阶段的Stop-the-world,处理from和to区的对象,标记可达的老年代对象,并处理Dirty对象
5.Final Remark重新标记:重新扫描之前并发处理阶段的所有残留更新对象
6.Concurrent Sweep并发清理:清理所有未被标记的死亡对象,回收被占用的空间
7.Concurrent Reset并发重置:清理并恢复在CMS GC过程中的各种状态,重新初始化CMS相关数据结构

-
G1,jdk1.9默认
类似CMS的实现,保留了Initial Mark和Final Remark的两次Stop-the-world;内存空间默认做了优化,分单元区块,会去评审每一块区域的回收价值,确定那一块回收收益最高,控制垃圾回收的时间;每个区块都有rememberedSet(记忆集合) 管理自己区块所有内存使用的GCroot的状态即在做内存分配时就已经知道了内存内的现状,每个对象分别指向了什么对象,在做Final Remark时不需要跨区,减少路径扫描的时耗同事能更快的决策知道每个对象的分布
内存大小的取舍
1.扩大内存可以更少的触发GC
2.内存太大触发GC时候的停顿时间会长
- 因此要根据实际的业务场景设置一个“合适”的值,并配合压测和线上环境的实际情况不断调优;
- 达到:吞吐量=花在非GC停顿时间上的工作时间/总时间 >=95%
-Xms 启动JVM时堆内存的大小
-Xmx 堆内存最大限制
两者需要设置一样,防止扩缩容;
-XX:NewSize 年轻代大小,比老年代稍微大些
-XX:MaxNewSize 最大年轻代大小
两者需要设置一样,防止扩缩容;
-XX:SurvivorRatio 表示Eden survivor占比,默认为8,Eden 至少是survivor的两倍
Eden需要比Survivor尽可能的大,防止多次触发young gc导致年龄快速增长到可以进入老年代的case
-XX:MetaspaceSize元空间 初始空间大小
-XX:MetaspaceSizey元空间最大空间,默认是没有限制的,不建议设置
GC优化
1.将进入老年代的对象减少到最低:可通过调整新生代的大小
2.young gc: 40ms以内
3.major gc:stop-the-world时间总和100ms以内:如果触发的不是特别频繁,可放到200ms甚至500ms以内
4.full gc :尽可能少,且时间在1s内
除了cms和g1外其余的串行或并行的GC major gc=full gc
GC策略开启参数
jdk1.9之前建议使用cms;1.9之后默认G1

CMS变成Full GC条件,尽可能的减少
- promotion failure :由于内存碎片导致的晋升空间不足,发生在新生代往来年代晋升时
- Concurrent mode failed:还未完成cms又触发了下一次major gc,发生在内存分配的速度比cms执行速度更短时
cms调优,整个调优看实验情况,具体使用如下参数之间取舍
-XX:ParallelGCThreads=N设置年轻代的并行收集线程数,避免docker踩坑;如果不配置JVM会获取当前主机上的CPU的核数来决策放多少线程数合适,早起版本在docker中读取的是物理机的并非是docker的核
-XX:ParallelCMSThreads=N设置cms的并行收集线程数,避免docker踩坑;清除老年代的并发的线程数,如果指定了上一个参数,这个参数可以根据第一个参数做线性调整,往往不需要设置此参数
-XX:+UseCMSCompactAtFullCollection FullGC情况下的Initial remark 或者Final remark都整理内存碎片
-XX:+CMSFullGCsBeforeCompaction=4 两次FullGC情况下的Initial remark 或者Final remark 4次后才整理内存碎片,与上一个参数配合使用,更好的权衡性能和内存的关系
-XX:+UseCMSInitiatingOccupancyOnly 让阈值驱动cms触发时机
-XX:+CMSInitiatingOccupancyFraction=70 表示老年代70%占满才触发cms;往往与上一个放一起使用,需要上一个参数开启使用防止jvm瞎搞,70较合理
-XX:+CMSParallelRemarkEnabled :final remark阶段并行remark
-XX:+CMSScavengeBeforeRemark remark前先做一次major gc,为了将younggc的内容释放一部分
G1参数调优
-XX:+UseG1GC开启G1参数,1.9之后不需要指定使用
-XX:MaxGCPauseMillis=n GC最大停顿时间,程序可容忍多久的停顿,JVM会尽可能的满足,软性参数
-XX:G1HeapRegionSize=n 每个Region的大小,需要不断试验确定Region的大小
Best pratise
- 多分析线上case,并设置不同的内存大小观察GC日志,寻找最佳策略
- 通过改善以上参数避免common类型问题
日志优化
内容是否有意义,有效,并且足够精炼,是否是debug问题的关键,如toString方法只放相对有效的精炼信息
- 同步日志(刷盘阻塞)/异步日志(内存管道buffer,不需要等到刷盘,写磁盘时可能失败,导致致命的日志缺失)
- 日志归档时间,如log4j按天,每天0点切换文件(可设置偏移几秒执行),切换文件时会info上锁打zip,然后清空info
- 日志大小拆分,如200M,也不建议切分太小,会导致查询困难,太大或导致切换上锁时间过长
池化策略(线程池,连接池)
- Idle数量,与cpu数量贴近,建议IO密集型核心线程数是cpu核数*2;计算密集型核心线程数和cpu核数+1;根据实际线上应用的数量和server(mysql server最大500个)可以承载的最大连接数判断和取舍















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









