







文章内容
如果觉得有帮助,麻烦动动手指点赞加关注💗💗💗 非常感谢!!!
有想看源码的小伙伴请移步这里👉https://gitee.com/fearless123/demo/tree/master/src/main/java/com/ma/structure
一、树的基本概念
1. 定义
将具有一对多关系的集合中的元素按照下图中的逻辑结构存储,整个存储形状从逻辑结构上看就像现实生活中一颗倒着生长的树,毕竟形象生动,所以这种数据结构也就被叫做树(Tree),这种存储结构也称为树形存储结构
树(tree)是包含n(n>=0)个结点的有穷集,其中:
- 每个元素称为结点(node);
- 有一个特定的结点被称为根结点或树根(root)。
- 除根结点之外的其余数据元素被分为m(m≥0)个互不相交的集合T1,T2,……Tm-1,其中每一个集合Ti(1<=i<=m)本身也是一棵树,被称作原树的子树(subtree)
简单的说就是,一颗树由根结点和m(m>=0)棵子树构成,或者说由n(n>=0)个结点构成一颗树
如果某棵树没有结点,即n = 0 ,那这就是一颗空树;即使只有一个结点,没有子树,依然可以构成一颗树,即n = 1,m = 0

2. 基本术语
- 结点:结点不仅包含
数据元素,而且包含指向子树的分支。例如,A结点不仅包含数据元素A,而且包含3个指向子树的指针。 - 结点的度:结点拥有的
子树个数或者分支的个数。
树的度:树中各结点度的最大值。 - 叶子结点:又叫作终端结点,指度为0的结点。图中D、E、F、H都是叶子结点。
- 非终端结点:又叫作分支结点(A、B、C、G),指度不为0的结点。除根节点以外的非终端结点,也叫作内部结点(B、C、G)。
- 孩子:结点的子树的根。如结点A的孩子是B、C
- 双亲:与孩子的定义对应。如B、C的双亲是A
- 兄弟:同一双亲的孩子之间互为兄弟。如B、C互为兄弟
- 祖先:从根到某结点的路径上的所有结点,都是这个结点的祖先。如H的祖先是A、C、G,因为路径是A-C-G-H
- 子孙:以某结点为根的子树中的所有结点,都是该结点的子孙。如C的子孙为F、G、H。
- 层次:从根开始,根为第一层,根的孩子为第二层,根的孩子的孩子为第三层,以此类推。
- 树的高度(或深度):树中结点的最大层次。
- 结点的深度和高度:
1)结点的深度是从根结到该结点路径上的结点个数。
2)从某结点到达叶子结点的最长路径的长度即为该结点的在树中的高度。
3)根结点的高度为树的高度 - 堂兄弟:双亲在同一层的结点互为堂兄弟。
- 有序树:树中结点的子树从左到右是有次序的,不能交换,这样的树叫作有序树
- 无序树:树中结点的子树没有顺序,可以任意交换,称为无序树
- 丰满树:丰满树即理想平衡树,要求出最底层外,其它层都是满的。
- 森林:若干棵互不相交的树的集合。
3. 存储结构
1)顺序存储结构
树的顺序存储结构中最简单直观的是双亲存储结构,用一维数组即可实现。假如定义int tree[maxSize],数组存储的内容就用来表示树中父子之间逻辑关系。

用数组下标表示树中的结点,数组元素的内容表示该结点的双亲结点。如上图所示,下标为5、6、7的双亲为3,对应数组中存储的数值3;下标1上的内容为-1,表示1为根结点。用这种存储结构来存储的数,当知道一个结点后就很容易找到其双亲结点(如知道结点i,则tree[i]即为i的双亲结点),因此也成为双亲存储结构。
2)链式存储结构
介绍两个常用的:
- 孩子存储结构。与图的领接表存储结构有关,后面讲…
- 孩子兄弟存储结构。树和森林与二叉树的相互转换关系密切,后面讲…
二、二叉树
1. 定义
在树的定义基础上,加上两个限制条件:
- 每个结点最多只能有两棵子树,即二叉树中结点的度只能是0、1、2。
- 子树有左右顺序之分,不能颠倒

在一棵二叉树中,如果所有的分支结点都有左孩子和右孩子结点,并且叶子结点都集中在二叉树的最下一层,则这样的二叉树称为满二叉树。

如果二叉树中除去最后一层节点为满二叉树,且最后一层的结点依次从左到右分布,则此二叉树被称为完全二叉树。(完全二叉树就是根据满二叉树从右至左,从下至上挨个删除得到的)

2. 主要性质
- 性质1:非空二叉树上叶子结点数等于双分支结点数加1(N0=N2+1)**
- 性质2:二叉树的第i层上最多有2i-1(i >=1,i为层号)个结点
- 性质3:高度(或深度)为k的二叉树最多有2k-1(k>=1)个结点
- 性质4:有n个结点的完全二叉树,对结点从上到下、从左到右依次编号(编号范围为1~n),则结点之间有如下关系(i为某结点a的编号):
- 如果i≠1,则a双亲结点的编号为 ⌊ i / 2 ⌋ \lfloor i/2\rfloor ⌊i/2⌋(表示i/2向下取整)
- 如果2i<=n,则a左孩子的编号为2i;如果2i>n,则a无左孩子
- 如果2i+1<=n,则a有孩子的编号为2i+1;如果2i+1>n,则a无右孩子
- 性质5:函数Catalan():给定n个结点,能构成h(n)种不同的二叉树,h(n) = C 2 n n n + 1 \dfrac{C_{2n}^{n}}{n+1} n+1C2nn
- 性质6:具有n(n>=1)个结点的完全二叉树的高度(或深度)为 ⌊ log 2 n ⌋ + 1 \lfloor \log _{2}n\rfloor +1 ⌊log2n⌋+1
根据性质2推广得,对于一棵有n个结点的完全二叉树有:
- 若n为奇数,则树只有度为0和2的结点,则度为2的结点有Math.floor(n/2),度为0的比度为2的结点多1个
- 如n为偶数,则除了度为0、2的结点外,还有1个度为1的结点
注:总分支数 = 总结点数 - 1,适用于所有树。
3. 存储结构
1)顺序存储结构
顺序存储结构即用一个数组BTree[size]来存储一棵二叉树,这种存储方式最适合于完全二叉树,用于存储一般的二叉树会浪费大量的存储空间(非完全二叉树会造成不连续存储,数组有空间浪费),然后再根据性质2来判断左右孩子的位置编号。
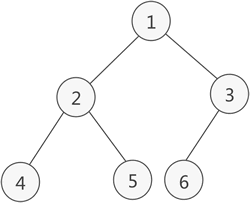

例如,上图知道顶点2的下标是1,要得到顶点2的左孩子结点就需要访问BTree[1*2]即可。类似地,如果知道了一个结点i,如果2i不大于n,则i的左孩子结点就存在于BTree[2*i]内。
1)链式存储结构
顺序存储结构有很大局限性,不便于存储任意形态的二叉树。因此设计出包含一个数据域和两个指针域的链式结点结构,具体如下:

其中,data表示数据域,用于存储对应的数据元素;lchild和rchild分别表示左指针域和右指针域,分别用于存储左右孩子结点的位置。这种存储结构又称为二叉链表存储结构,定义如下:
public class Node<T> {
/**
* 数据域
*/
T data;
/**
* 左孩子结点的引用
*/
Node lchild;
/**
* 右孩子结点的引用
*/
Node rchild;
}
4. 二叉树的遍历算法
常见的几种遍历算法总结:
- 先序(前序或先根):从根开始,遇见根(双亲)就访问
- 中序(中根):从根开始,访问完左子树再访问根节点
- 后序(后根):从根开始,访问完左、右子树后访问根节点
- 层次:按照如图箭头所指方向,1、2、3、4的顺序逐层遍历。(也可以从右向左)

先序、中序和后序代码实现类似,直接以先序遍历做示例:
package com.ma.structure.tree;
import com.ma.structure.stack.SeqStack;
import lombok.Data;
/**
* @Description 思考:二叉树三种遍历算法的实际应用有哪些呢???区别是什么??
* @Classname Node
* @Created by Fearless
* @Date 2022/2/18 13:43
*/
@Data
public class TreeNode<T> {
/**
* 数据域
*/
T data;
/**
* 左孩子结点的引用
*/
TreeNode lchild;
/**
* 右孩子结点的引用
*/
TreeNode rchild;
/**
* 结点数量
*/
int size;
private final static Integer MAX_SIZE = 1024;
public TreeNode() {
this.size = 0;
}
/**
* 二叉树 先序遍历(递归)
* @param bt
*/
public void preorder(TreeNode bt){
if (bt != null){
Visit(bt);
preorder(bt.getLchild());
preorder(bt.getRchild());
}
}
/**
* 根据前中或中后遍历的字符串转成对应的二叉树(适用于任意二叉树)
* @param type 1-表示前中遍历的数组
* 2-表示中后遍历的数组
* 例如:先序:ABDECFHIG 中序:DBEAHFICG
* => 二叉树来源自《20版数据结构与算法高分笔记P143 图6-10》
* => 后序:DEBHIFGCA
* 层次:ABCDEFGHI
* @param pre 前或中遍历数组
* @param mid 中或后遍历数组
* @return
*/
public TreeNode array2Btree(int type, String[] pre, String[] mid){
TreeNode<Object> bt = new TreeNode<>();
bt.setSize(pre.length);
if (type == 1){ // pre 前 mid 中
int len = pre.length;
bt.setData(pre[0]);
// 说明只剩一个了,表示叶子结点,递归可以退出
if (pre.length == 1){
bt.setLchild(null);
bt.setRchild(null);
return bt;
}
// 中间值 在{DBEAHFICG}中间值应该是3
int index = 0 ;
for (int i = 0; i < len; i++){
// 在中序中找到
if (pre[0] == mid[i]){
index = i;
break;
}
}
if (index > 0){ // 非非根节点
// 左子树的先序
String[] leftPre = new String[index];
String[] leftMid = new String[index];
for (int j = 0; j < index; ++j){
leftPre[j] = pre[j + 1];
leftMid[j] = mid[j];
}
bt.setLchild(array2Btree(type, leftPre, leftMid));
} else {
bt.setLchild(null);
}
if (pre.length - (index + 1) > 0){ // 表示存在右子树结点
// 右子树的先序,长度为 总-根-左子树
String[] rightPre = new String[pre.length - (index + 1)];
String[] rightMid = new String[pre.length - (index + 1)];
for (int j = index + 1; j < len; ++j){
// 找出右子树先序及中序子数组 两个数组下标从0开始,故从j - (index + 1)开始
rightPre[j - (index + 1)] = pre[j];
rightMid[j - (index + 1)] = mid[j];
}
bt.setRchild(array2Btree(type, rightPre, rightMid));
} else {
bt.setRchild(null);
}
}
return bt;
}
/**
* 访问根节点元素
* @param treeNode
*/
private void Visit(TreeNode treeNode) {
System.out.print(treeNode.getData() + ",");
}
}
层次遍历需要建立一个循环队列,将二叉树头结点入队列,然后出队列,访问该结点,如果有左子树,则将左子树的根节点入队列;如果有右子树,则将右子树的根节点入队列。然后出队列,对出队列结点访问,如此反复,知道队列为空为止。由此得到对应的算法如下:
/**
* 二叉树 层次遍历
* @param node
*/
public void level(Node node){
int front,rear;
Node[] queue = new Node[MAX_SIZE]; // 定义一个循环队列,用来记录将要访问的层次上的结点
int maxSize = MAX_SIZE;
front = rear = 0;
Node q;
if (node != null){
rear = (rear + 1) % maxSize;
queue[rear] = node; // 根节点入队
while(front != rear){
front = (front + 1) % maxSize;
q = queue[front]; // 队头结点出队
Visit(q); // 访问结点元素
if (q.getLchild() != null){ // 左子树不为空,左根节点入队
rear = (rear + 1) % maxSize;
queue[rear] = q.getLchild();
}
if (q.getRchild() != null){ // 右子树不为空,右根节点入队
rear = (rear + 1) % maxSize;
queue[rear] = q.getRchild();
}
}
}
}
5. 二叉树遍历算法的改进
1)二叉树深度优先遍历算法的非递归实现(利用用户自定义栈来代替递归方式的借用的系统栈,进而提高遍历效率)
/**
* 二叉树 先序遍历(非递归,容易理解)
* @param bt
* @throws Exception
*/
public void preorderNorecursion(TreeNode bt) throws Exception {
if (bt != null){
SeqStack<TreeNode> stack = new SeqStack<>(MAX_SIZE);
TreeNode p = null;
// 根节点入栈
stack.push(bt);
while (!stack.isEmpty()){
// 栈非空循环出栈访问节点
p = stack.pop();
Visit(p);
// 左右子树存在就入栈 等待后续出栈访问 (注意这块先访问右孩子是由于栈的先进后出特性)
if (p.getRchild() != null){
stack.push(p.getRchild());
}
if (p.getLchild() != null){
stack.push(p.getLchild());
}
}
}
}
/**
* 二叉树 中序遍历(非递归,比较难理解)
* @param bt
* @throws Exception
*/
public void inorderNonrecursion(TreeNode bt) throws Exception {
if (bt != null){
// 建立栈
SeqStack<TreeNode> stack = new SeqStack<>(MAX_SIZE);
TreeNode p = bt;
while(!stack.isEmpty() || p != null){
while (p != null){ // 左孩子存在,则持续入栈
stack.push(p);
p = p.getLchild();
}
if (!stack.isEmpty()){
p = stack.pop();
Visit(p);
p = p.getRchild(); // 转到右孩子上
}
}
}
}
/**
* 二叉树 后序遍历(非递归,比较难理解):逆后序遍历是将先序遍历过程中的左右子树遍历顺序
* 互换即可得到,因此该算法的流程是 先序 => 逆后序 => 后序 需要两个栈,一个用来辅助作逆
* 后序遍历,另一个存逆后序的结果,最后出栈即可
* @param bt
* @throws Exception
*/
public void postorderNonrecursion(TreeNode bt) throws Exception {
if (bt != null){
SeqStack<TreeNode> stack1 = new SeqStack<>(MAX_SIZE);
SeqStack<TreeNode> stack2 = new SeqStack<>(MAX_SIZE);
TreeNode p;
stack1.push(bt);
while (!stack1.isEmpty()){
p = stack1.pop();
stack2.push(p); // 注意这块改为入栈2
if (p.getLchild() != null){
stack1.push(p.getLchild());
}
if (p.getRchild() != null){
stack1.push(p.getRchild());
}
}
while (!stack2.isEmpty()){ // 栈2出栈得到结果
p = stack2.pop();
Visit(p); // 访问结点
}
}
}
测试代码如下:
public static void main(String[] args) throws Exception {
String[] pre = {"A","B","D","E","C","F","H","I","G"};
String[] mid = {"D","B","E","A","H","F","I","C","G"};
// 创建二叉树
TreeNode<Object> node = new TreeNode<>();
TreeNode treeNode = node.array2Btree(1, pre, mid);
System.out.println("先序遍历结果如下:");
node.preorder(treeNode);
System.out.println();
System.out.println("先序遍历非递归方式结果如下:");
node.preorderNorecursion(treeNode);
System.out.println();
System.out.println("中序遍历非递归方式结果如下:");
node.inorderNonrecursion(treeNode);
System.out.println();
System.out.println("后序遍历非递归方式结果如下:");
node.postorderNonrecursion(treeNode);
System.out.println();
System.out.println("层次遍历结果如下:");
node.level(treeNode);
}

2)线索二叉树
对于二叉链表存储机构,n个结点的二叉树有n+1个空链域(单结点有2个指针域,n结点理论上有2n指针域。又有总分支数=结点数-1,因此空链域=2n-(n-1)=n+1)。将这些空链域利用起来,建立起“前驱”和“后继”信息,就可以把二叉树看做一个链表结构,从而像遍历链表那样来遍历二叉树,进而提高效率。线索化的规则是,左线索指针指向当前结点在遍历序列中的前驱结点,右线索指针指向后继结点。同时添加线索标识,将线索指针和子节点指针区分开来。
package com.ma.structure.tree;
import lombok.AllArgsConstructor;
import lombok.Data;
/**
* @Description TODO
* @Classname TBTNode 线索二叉树
* @Created by Fearless
* @Date 2022/2/22 15:00
*/
@Data
public class TBTNode {
// 结点存储结构,这里为了方便直接使用静态内部类
static class Node{
String data; // 数据域
Node left; // 左指针域
Node right; // 右指针域
boolean isLeftThread = false; // 左指针线索标识
boolean isRightThread = false; // 右指针线索标识
Node(String data){
this.data = data;
}
}
private Node preNode; //线索化是记录前一个结点
/**
* 通过数组构造二叉树(完全二叉树,按数组下标逐层构建)
* @param array
* @param index
* @return
*/
static Node createBinaryTree(String[] array, int index){
Node node = null;
if (index < array.length){
node = new Node(array[index]);
node.left = createBinaryTree(array, index * 2 + 1);
node.right = createBinaryTree(array, index * 2 + 2);
}
return node;
}
/**
* 中序线索化二叉树
* @param node
*/
public void inThreadOrder(Node node){
if (node == null){
return;
}
// 处理左子树
inThreadOrder(node.left);
// 左指针为空,将左指针指向前驱结点
if (node.left == null){
node.left = preNode;
node.isLeftThread = true;
}
// 前一个结点的后继结点指向当前结点
if (preNode != null && preNode.right == null){
preNode.right = node;
preNode.isRightThread = true;
}
preNode = node;
// 处理右子树
inThreadOrder(node.right);
}
/**
* 中序遍历线索二叉树,按照后继方式遍历(思路:找到最左子节点开始)
* 得到的是中序遍历的结果
* @param node
*/
public void inThreadList(Node node){
// 1、找中序遍历方式开始的结点
while(node != null && !node.isLeftThread){
node = node.left;
}
while(node != null){
System.out.println(node.data + ", ");
// 如果右指针是线索
if (node.isRightThread){
node = node.right;
} else { // 如果右指针不是线索,找到右指针开始的结点
node = node.right;
while(node != null && !node .isLeftThread){
node = node.left;
}
}
}
}
/**
* 中序遍历线索二叉树,按照前驱方式遍历(思路:找到最右边子节点开始倒序遍历)
* 得到的是逆中序遍历结果
* @param node
*/
public void inPreThreadList(Node node){
// 找到最后一个结点
while(node.right != null && !node.isRightThread){
node = node.right;
}
while(node != null){
System.out.println(node.data + ", ");
// 如果左指针是线索
if (node.isLeftThread){
node = node.left;
} else { // 如果左指针不是线索,找到左子树开始的结点
node = node.left;
while(node.right != null && !node.isRightThread){
node = node.right;
}
}
}
}
/**
* 前序线索化二叉树
* @param node
*/
void preThreadOrder(Node node) {
if(node == null) {
return;
}
//左指针为空,将左指针指向前驱节点
if(node.left == null) {
node.left = preNode;
node.isLeftThread = true;
}
//前一个节点的后继节点指向当前节点
if(preNode != null && preNode.right == null) {
preNode.right = node;
preNode.isRightThread = true;
}
preNode = node;
//处理左子树
if(!node.isLeftThread) {
preThreadOrder(node.left);
}
//处理右子树
if(!node.isRightThread) {
preThreadOrder(node.right);
}
}
/**
* 前序遍历线索二叉树(按照后继线索遍历)
* @param node
*/
public void preThreadList(Node node){
while(node != null){
while(!node.isLeftThread){
System.out.println(node.data + ", ");
node = node.left;
}
System.out.println(node.data + ", ");
node = node.right;
}
}
public static void main(String[] args) {
String[] array = {"A", "B", "C", "D", "E", "F", "G", "H"};
Node root = createBinaryTree(array, 0);
TBTNode tree = new TBTNode();
tree.inThreadOrder(root);
System.out.println("中序按后继节点遍历线索二叉树结果:");
tree.inThreadList(root);
Node root2 = createBinaryTree(array, 0);
TBTNode tree2 = new TBTNode();
tree2.preThreadOrder(root2);
tree2.preNode = null;
System.out.println("\n前序按后继节点遍历线索二叉树结果:");
tree.preThreadList(root2);
}
}

三、树与二叉树的应用
1. 哈夫曼树和哈夫曼编码
1)概念
哈夫曼树又叫作最优二叉树,它的特点是带权路径最短(注意哈夫曼树一般是二叉的,也有哈夫曼n叉树有n个子树)。关于路径的几个概念如下:
- 路径:指从树中的一个结点到另一个结点的分支所构成的路线。
- 路径长度:路径上的分支数目
- 树的路径长度:指从根到每个结点的路径长度之和。
- 带权路径长度:结点具有权值,从该结点到根之间的路径长度乘以结点的权值,就是结点的带权路径长度。
- 树的带权路径长度(WPL):树的带权路径长度是指树中所有叶子结点的带权路径长度之和。
2)哈夫曼树构造规则
给定n个权值,用这n个权值来构造哈夫曼树,流程如下:
- 将这n个权值分别看作只有根节点的n棵二叉树,这些二叉树构成的集合记为F
- 从F中选出两棵根节点的权值最小的树(假设a、b)作为左、右子树,构造一颗新的二叉树(假设c),新的二叉树的根结点的权值为左、右子树根结点权值之和。
- 从F中删除a、b,加入新构造的树c
- 重复进行2)、3)两步,直到F中只剩下一棵树为止,这棵树就是哈夫曼树。

哈夫曼树的特点:
- 权值越大的结点,距离根结点越近
- 树中没有度为1的结点。这类树又叫作正则(严格)二叉树
- 树的带权路径最短(WPL最小)
3)哈夫曼编码
哈夫曼编码是哈弗曼树的经典应用,主要用来做压缩存储用的。
例如将字符串“S=AAABBACCCDEEA”进行存储,则可以按照下表规则转换成二进制进行存储:
| A | B | C | D | E |
|---|---|---|---|---|
| 000 | 001 | 010 | 011 | 100 |
| S串编码后: | ||||
| T(S) = 000 000 000 001 001 000 010 010 010 011 100 100 000 (39位) |
利用哈夫曼编码规则,可以使其变得更短一些压缩存储。统计字符在字符串中出现的次数如下表:
| A | B | C | D | E |
|---|---|---|---|---|
| 5次 | 2次 | 3次 | 1次 | 2次 |
| 画出的哈夫曼树如图: | ||||
 |
对上图哈夫曼树中每个结点的足有分支进行编号,左0右1,则从根到每个结点的路径上的数字序列即为每个字符的编码。
| A | B | C | D | E |
|---|---|---|---|---|
| 0 | 110 | 10 | 1110 | 1111 |
| 则S串的编码为:H(s) = 0 0 0 110 110 0 10 10 10 1110 1111 1111 0(29位) |
有人可能会问这块会不会存在诸如此类问题,如A编码是0,B的编码是00,解码00是该解码成AA还是B呢???
这里需要介绍下前缀码。前缀码的特点是任一字符的编码串都不是另一个字符编码串的前缀,而由哈夫曼编码规则产生的恰好是前缀码,即H(s)就是前缀码。原因是由于哈夫曼树中根结点通往任一叶子结点的路径都不可能是通往其余叶子结点路径的子路径。这就避免了可能存在的解码歧义问题。
解码过程就是以H(s)串为指示,一次次沿着根节点走向叶子结点并读出字符的过程。

如上图,H(s)串第一个字符为0,从根开始沿着0方向走来到叶子结点,解码出A;回到根,重复上述过程,解码出后面两个A;此时遇到1,从根沿着1方向走,遇到的不是叶子结点,继续读H(s)串,直到读到0到达叶子结点,读出B。回到根节点,如此进行下去,直到将所有字符读出来。
2. 二叉排序树
1)概念
二叉排序树(BST)满足以下特点:
- 若它的左子树不空,则左子树上所有关键字的值均小于根关键字的值;
- 若它的右子树不空,则右子树上所有关键字的值均大于根关键字的值。
- 左右子树又各是一棵二叉排序树。
2)常见操作及Java实现代码
定义树结点Node
public class Node {
private Node leftNode;
private Node rightNode;
private int value;
public Node(int value) {
this.value = value;
}
}
二叉排序树基本算法
package com.ma.structure.tree;
import com.ma.exception.DataException;
import com.ma.structure.stack.SeqStack;
import lombok.Data;
/**
* @Description 二叉树三种遍历算法的实际应用有哪些呢???
* @Classname TreeNode
* @Created by Fearless
* @Date 2022/2/18 13:43
*/
@Data
public class TreeNode<T> {
/**
* 数据域
*/
private T data;
/**
* 左孩子结点的引用
*/
private TreeNode<T> lchild;
/**
* 右孩子结点的引用
*/
private TreeNode<T> rchild;
/**
* 结点数量(每次put进结点+1)
*/
int size;
private final static Integer MAX_SIZE = 1024;
public TreeNode() {
this.size = 0;
}
public TreeNode(T data) {
this.data = data;
}
/*----------------------------------------------------二叉树API--------------------------------------------------*/
/**
* 二叉树 先序遍历(递归)
* @param bt
*/
public static void preorder(TreeNode bt){
if (bt != null){
Visit(bt);
preorder(bt.getLchild());
preorder(bt.getRchild());
}
}
/**
* 二叉树 中序遍历(递归)
* @param bt
*/
public static void inoder(TreeNode bt){
if (bt != null){
preorder(bt.getLchild());
Visit(bt);
preorder(bt.getRchild());
}
}
/**
* 二叉树 后序遍历(递归)
* @param bt
*/
public static void postorder(TreeNode bt){
if (bt != null){
preorder(bt.getLchild());
preorder(bt.getRchild());
Visit(bt);
}
}
/**
* 二叉树 先序遍历(非递归,容易理解)
* @param bt
* @throws Exception
*/
public static void preorderNorecursion(TreeNode bt) throws Exception {
if (bt != null){
SeqStack<TreeNode> stack = new SeqStack<>(MAX_SIZE);
TreeNode p = null;
// 根节点入栈
stack.push(bt);
while (!stack.isEmpty()){
// 栈非空循环出栈访问节点
p = stack.pop();
Visit(p);
// 左右子树存在就入栈 等待后续出栈访问 (注意这块先访问右孩子是由于栈的先进后出特性)
if (p.getRchild() != null){
stack.push(p.getRchild());
}
if (p.getLchild() != null){
stack.push(p.getLchild());
}
}
}
}
/**
* 二叉树 中序遍历(非递归,比较难理解)
* @param bt
* @throws Exception
*/
public static void inorderNonrecursion(TreeNode bt) throws Exception {
if (bt != null){
// 建立栈
SeqStack<TreeNode> stack = new SeqStack<>(MAX_SIZE);
TreeNode p = bt;
while(!stack.isEmpty() || p != null){
while (p != null){ // 左孩子存在,则持续入栈
stack.push(p);
p = p.getLchild();
}
if (!stack.isEmpty()){
p = stack.pop();
Visit(p);
p = p.getRchild(); // 转到右孩子上
}
}
}
}
/**
* 二叉树 后序遍历(非递归,比较难理解):逆后序遍历是将先序遍历过程中的左右子树遍历顺序
* 互换即可得到,因此该算法的流程是 先序 => 逆后序 => 后序 需要两个栈,一个用来辅助作逆
* 后序遍历,另一个存逆后序的结果,最后出栈即可
* @param bt
* @throws Exception
*/
public static void postorderNonrecursion(TreeNode bt) throws Exception {
if (bt != null){
SeqStack<TreeNode> stack1 = new SeqStack<>(MAX_SIZE);
SeqStack<TreeNode> stack2 = new SeqStack<>(MAX_SIZE);
TreeNode p;
stack1.push(bt);
while (!stack1.isEmpty()){
p = stack1.pop();
stack2.push(p); // 注意这块改为入栈2
if (p.getLchild() != null){
stack1.push(p.getLchild());
}
if (p.getRchild() != null){
stack1.push(p.getRchild());
}
}
while (!stack2.isEmpty()){ // 栈2出栈得到结果
p = stack2.pop();
Visit(p); // 访问结点
}
}
}
/**
* 二叉树 层次遍历
* @param bt
*/
public static void level(TreeNode bt){
int front,rear;
TreeNode[] queue = new TreeNode[MAX_SIZE]; // 定义一个循环队列,用来记录将要访问的层次上的结点
int maxSize = MAX_SIZE;
front = rear = 0;
TreeNode q;
if (bt != null){
rear = (rear + 1) % maxSize;
queue[rear] = bt; // 根节点入队
while(front != rear){
front = (front + 1) % maxSize;
q = queue[front]; // 队头结点出队
Visit(q); // 访问结点元素
// 访问完结点进行累加
if (q.getLchild() != null){ // 左子树不为空,左根节点入队
rear = (rear + 1) % maxSize;
queue[rear] = q.getLchild();
}
if (q.getRchild() != null){ // 右子树不为空,右根节点入队
rear = (rear + 1) % maxSize;
queue[rear] = q.getRchild();
}
}
}
}
/**
* 根据前中或中后遍历的字符串转成对应的二叉树
* @param type 1-表示前中遍历的字符串
* 2-表示中后遍历的字符串
* 例如:先序:ABDECFHIG 中序:DBEAHFICG
* => 二叉树来源自《20版数据结构与算法高分笔记P143 图6-10》
* => 后序:DEBHIFGCA
* 层次:ABCDEFGHI
* @param pre 前或中遍历数组
* @param mid 中或后遍历数组
* @return
*/
public static TreeNode array2Btree(int type, String[] pre, String[] mid){
TreeNode<Object> bt = new TreeNode<>();
bt.setSize(pre.length);
if (type == 1){ // pre 前 mid 中
int len = pre.length;
bt.setData(pre[0]);
// 说明只剩一个了,表示叶子结点,递归可以退出
if (pre.length == 1){
bt.setLchild(null);
bt.setRchild(null);
return bt;
}
// 中间值 在{DBEAHFICG}中间值应该是3
int index = 0 ;
for (int i = 0; i < len; i++){
// 在中序中找到
if (pre[0] == mid[i]){
index = i;
break;
}
}
if (index > 0){ // 非非根节点
// 左子树的先序
String[] leftPre = new String[index];
String[] leftMid = new String[index];
for (int j = 0; j < index; ++j){
leftPre[j] = pre[j + 1];
leftMid[j] = mid[j];
}
bt.setLchild(array2Btree(type, leftPre, leftMid));
} else {
bt.setLchild(null);
}
if (pre.length - (index + 1) > 0){ // 表示存在右子树结点
// 右子树的先序,长度为 总-根-左子树
String[] rightPre = new String[pre.length - (index + 1)];
String[] rightMid = new String[pre.length - (index + 1)];
for (int j = index + 1; j < len; ++j){
// 找出右子树先序及中序子数组 两个数组下标从0开始,故从j - (index + 1)开始
rightPre[j - (index + 1)] = pre[j];
rightMid[j - (index + 1)] = mid[j];
}
bt.setRchild(array2Btree(type, rightPre, rightMid));
} else {
bt.setRchild(null);
}
}
return bt;
}
/**
* 访问根节点元素
* @param treeNode
*/
private static void Visit(TreeNode treeNode) {
System.out.print(treeNode.getData() + ",");
}
/*----------------------------------------------------二叉排序树API--------------------------------------------------*/
/**
* 二叉排序树结点插入
* @param node
*/
public void add(TreeNode node) {
if (node == null) {
return;
}
// 根结点值大于当前结点,作为左子树
if (compareTo(this.data, node.data) > 0) {
if (this.lchild == null) {
this.lchild = node;
} else {
this.lchild.add(node);
}
} else { // 根结点值小于当前结点,作为由子树
if (this.rchild == null) {
this.rchild = node;
} else {
this.lchild.add(node);
}
}
}
private int compareTo(Object obj1, Object obj2) {
int cmp = 0;
if (obj1 instanceof Integer && obj2 instanceof Integer) {
cmp = Integer.compare((Integer) obj1, (Integer) obj2);
}
return cmp;
}
/**
* 二叉排序树的检索某结点
* @param value
* @return
*/
public TreeNode<T> search(T value) {
if (value == this.data) {
return this;
} else if (compareTo(value, this.data) > 0) { // 大于value,查询左子树
if (this.rchild != null) {
return this.rchild.search(value);
}
} else if (compareTo(value, this.data) < 0) { // 小于value,查询右子树
if (this.lchild != null) {
return this.lchild.search(value);
}
}
return null;
}
/**
* 二叉排序树的检索某结点的父级结点
* @param value
* @return
*/
public TreeNode<T> searchParent(T value) {
if ((this.lchild != null && value.equals(this.lchild.getData()))
|| (this.rchild != null && value.equals(this.rchild.getData()))) {
return this;
} else {
if (compareTo(this.data, value) > 0 && this.lchild != null) {
return this.lchild.searchParent(value);
} else if (compareTo(this.data, value) < 0 && this.rchild != null) {
return this.rchild.searchParent(value);
}
}
return null;
}
/**
* 二叉排序树删除某结点
* @param value
*/
public void delete(T value) {
if (value == null) {
throw new DataException("value参数为空!");
}
// 查找待删除的结点
TreeNode<T> target = search(value);
if (target != null) {
//在查找的同时需要记录一下待删除节点的父亲
TreeNode<T> parent = searchParent(value);
TreeNode<T> parentRchild = parent.getRchild();
TreeNode<T> parentLchild = parent.getLchild();
TreeNode<T> targetRchild = target.getRchild();
TreeNode<T> targetLchild = target.getLchild();
// 2、如果待删结点的左右结点都不存在,那么直接删除
if (targetRchild == null && targetLchild == null) {
if (parentRchild != null && value.equals(parentRchild.getData())) {
parent.setRchild(null);
} else {
parent.setLchild(null);
}
// 3、如果待删结点的左右结点都存在
} else if (targetRchild != null && targetLchild != null) {
// 此时删除后继结点,注意前驱和后继是待删结点的前一个结点或者后一个结点
// 二叉排序树中,前驱结点就是左子树下最右子树结点;后继结点就是右子树下最左子树结点
target.setData(deleteNextNode(targetRchild)); // 返回后继结点,直接覆盖待删结点value,即为删除
// 4、如果待删结点的左子树或右子树存在
} else {
if (targetLchild != null) {
if (parentLchild != null && value.equals(parentLchild.getData())) {
parent.setLchild(targetLchild);
} else {
parent.setRchild(targetLchild);
}
} else {
if (parentLchild != null && value.equals(parentLchild.getData())) {
parent.setLchild(targetRchild);
} else {
parent.setRchild(targetRchild);
}
}
}
}
}
/**
* 删除node结点的后继结点,并返回后继结点的value
* @param node
* @return
*/
private T deleteNextNode(TreeNode<T> node) {
TreeNode<T> target = node;
while(target.getLchild() != null) {
target = target.getLchild();
}
delete(target.getData());
return target.getData();
}
}
package com.ma.structure.tree;
/**
* @Classname BinarySortTree
* @Description 二叉排序树
* @Created by Fearless
* @Date 2023/2/12 12:39
*/
public class BinarySortTree<T> {
private TreeNode<T> root;
public static void main(String[] args) {
int[] arr = new int[]{1,2,3,4,5};
BinarySortTree binarySortTree = new BinarySortTree<Integer>();
for (int i : arr) {
// 构造二叉排序树
binarySortTree.addNode(new TreeNode<>(i));
}
// 中序遍历(前后序遍历会造成结果无序,因为构造就是按照中序构造的)
TreeNode.inoder(binarySortTree.root);
TreeNode search = binarySortTree.search(1);
if (search != null) {
System.out.println(search.getData());
}
TreeNode psearch = binarySortTree.searchParent(2);
if (psearch != null) {
System.out.println(psearch.getData());
}
/*Integer num1 = new Integer(1);
Integer num2 = new Integer(1);
System.out.println(Integer.compare(num1, num2));*/
}
/**
* 二叉排序树插入结点(递归实现)
* 递归代码的结构是将一个大问题变为小问题,把整个树转为更小的子树处理
* @param node
*/
public void addNode(TreeNode node) {
if (this.root == null) {
root = new TreeNode<>();
} else {
root.add(node);
}
}
/**
* 查找某个节点
* @param value
* @return
*/
public TreeNode search(T value) {
if (this.root == null) {
return null;
} else {
return root.search(value);
}
}
/**
* 查找某结点对应的父结点
* 与查找某个节点的方法区别是:
* 对于查找父节点,我们拿到当前节点后,比较的是当前节点的子节点值是否与所传参数值相等,
* 相等返回当前节点。因为子节点与所传值相等了,当前这个节点就是父节点了。
* @param value
* @return
*/
public TreeNode searchParent(T value) {
if (this.root == null) {
return null;
} else {
return root.searchParent(value);
}
}
/**
* 删除结点
* @param value
*/
public void delete(T value) {
this.root.delete(value);
}
}
3. 平衡二叉树
1)概念
二叉搜索树存在一个问题,就是树的姿态和数据的插入顺序是有关系的,有时候树会变成某一边的子树高度过高,甚至直接退化成斜二叉树,使得查找从二分查找跌落为顺序查找:
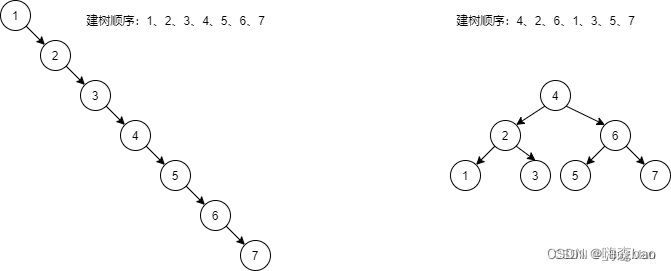
由此可见,二叉排序树的高度决定查找效率,树越矮查找效率越高,进而改进二叉排序树为平衡二叉树(AVL)。其中左右子树高度之差的绝对值不超过1,同样的左右子树也都是平衡二叉树。
平衡因子:左子树高度 - 右子树高度(只能取-1、0、1)
2)平衡调整
最小不平衡树,即从高度差超过1的两条分支开始向上找,找到它们的第一个共同父结点,以这个父节点为根结点的子树就是最小不平衡树。
AVL的不平衡调整有四种:
- LL调整
- RR调整
- LR调整
- RL调整
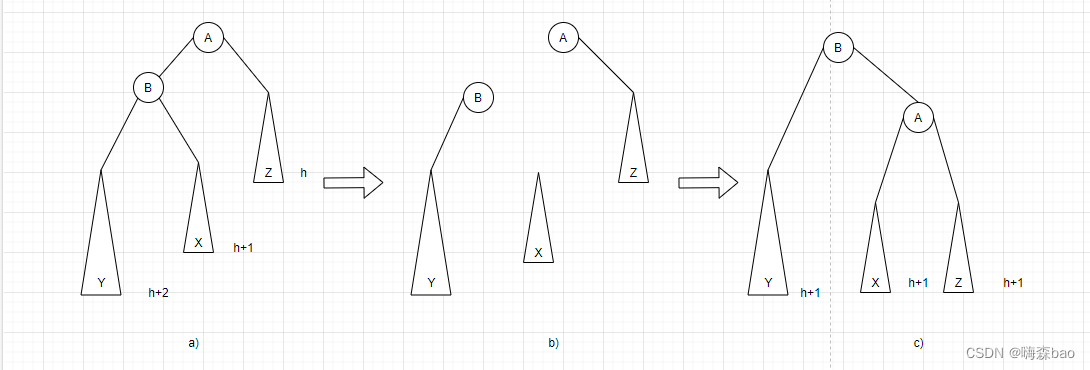
LL调整:也叫右单旋转调整。某时刻在B的左子树插入一个结点,导致A的左子树高度为h+2,右子树高度为h,发生不平衡。此时应该将A结点下移一个结点高度,B上移一个结点高度,也就是将B从A的左子树取下,然后将B的右子树挂在A的左子树,最后将A挂在B的右子树上以达到平衡。(总结:A、B两结点顺时针旋转调换,中间结点插入到原不平衡子树的根节点A)
RR调整:左单旋转调整。与LL调整左换成右,右换成左即可。假设不平衡子树根节点为B,A、B两结点逆时针旋转调换,中间结点插入到原不平衡子树的根节点。
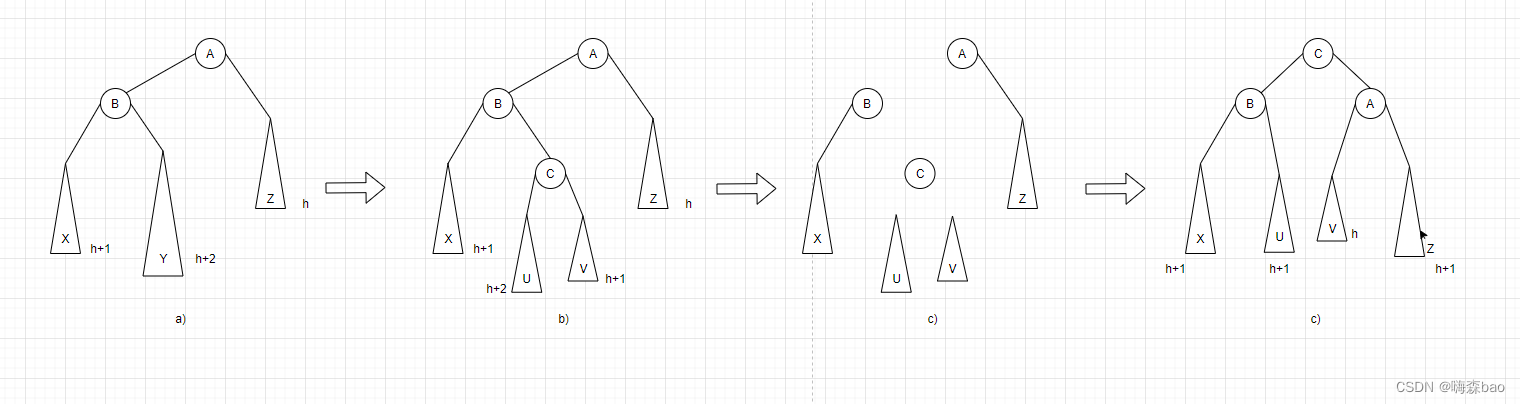
LR调整:先左后右双旋转调整。某时刻B的右子树Y上插入一个结点导致不平衡。此时需要将子树Y拆分成两个子树U和V,根结点为C,并将B的右子树、A的左子树和C的左右子树都取下。然后将C作为A和B两棵子树的根,B为左子树,A为右子树,C原来的左子树U作为B的右子树,C原来的右子树V作为A的左子树以达到平衡。(LR的含义表示新插入的结点落入左孩子的右子树上,造成Y与Z的不平衡)
RL调整:先右后左双旋转调整。B在A的右子树,且插入结点在B的左子树,即与上图对称的情况,只需做上述过程的对称处理即可。
2)常见操作及Java实现代码















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









