







目录
一.在浏览器输入一个网址
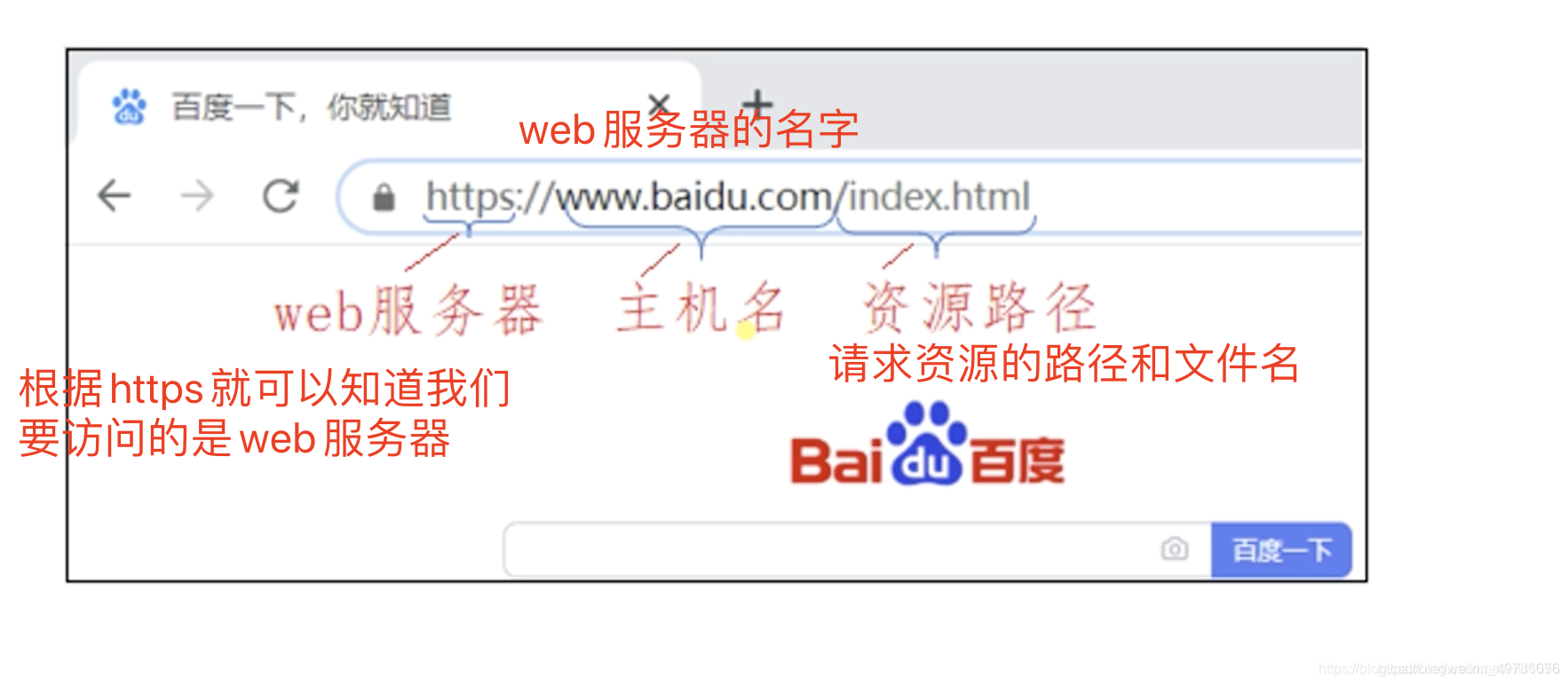
当输入https://www.baidu.com/index.html,浏览器进行URL解析,首先会看https,就知道我们要访问的是web服务器,www.baidu.com是web服务器名字,后面index.html就是数据源路径和文件名。
二.DNS 进行域名解析工作
浏览器生成了HTTP请求后,需要操作系统来把数据发送出去,内核协议栈用的是IP,并不是域名,所以要利用DNS来进行域名解析。web浏览器中其实就是gethostbyname (“www.baidu.com”),就可以获得对应域名的IP地址。
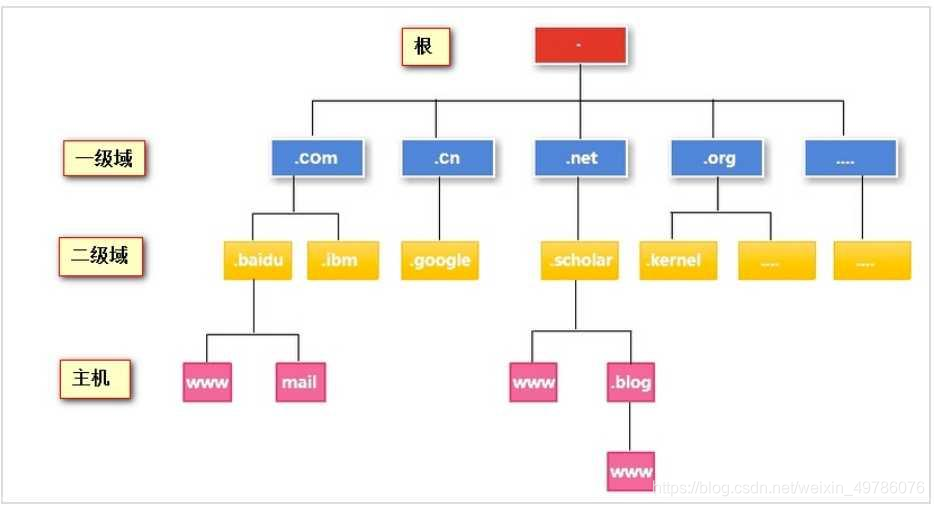
目前全球有13组根域名服务器,又有几百台镜像,保证一定能被访问得到。有了这个系统,我们查询域名www.baidu.com对应的IP,按照如下顺序:
- 访问根域名服务器,它告诉我们com域名服务器地址。
- 访问com域名服务器,它告诉我们baidu.com域名服务器的地址。
- 访问baidu.com域名服务器,得到www.baidu.com的地址。
我们为了加速域名解析,也可以在自己公司内部搭建DNS服务器,缓存域名对应的IP。其实我们操作系统也会缓存曾经访问过的域名。当然,我们还可以在操作系统的hosts文件中,记录域名对应的IP地址。如果在这些地方能够找到ip地址,就避免了远程访问DNS服务器,加快了DNS解析过程,也减轻了DNS服务器的压力。
换一种说法:
对 www.baidu.com 这个网址进行 DNS 域名解析工作,得到对应的 IP 地址
1.Chrome浏览器会首先搜索浏览器的DNS缓存,看自身的缓存中是否有www .baidu .com对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
2.如果浏览器自身的缓存里面没有找到对应的条目,那么Chrome会搜索操作系统的DNS缓存,如果找到且没有过期则停止搜索解析到此结束。
3.如果在Windows系统的DNS缓存也没有找到,那么尝试读取hosts文件,看看
这里面有没有该域名对应的IP地址,如果有则解析成功。
。。。。。以此类推
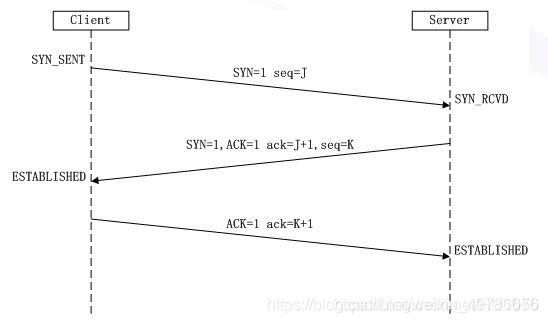
三.根据这个 IP 地址,找到对应的服务器,发起 TCP 的三次握手请求
拿到域名对应的IP地址之后,浏览器会以一个随机端口向服务器的WEB程序80端口发起TCP的连接请求。这个连接请求到达服务器端后, 进入到网卡,然后是进入到内核的TCP/IP协议栈,还有可能要经过防火墙的过滤,最终到达WEB程序,
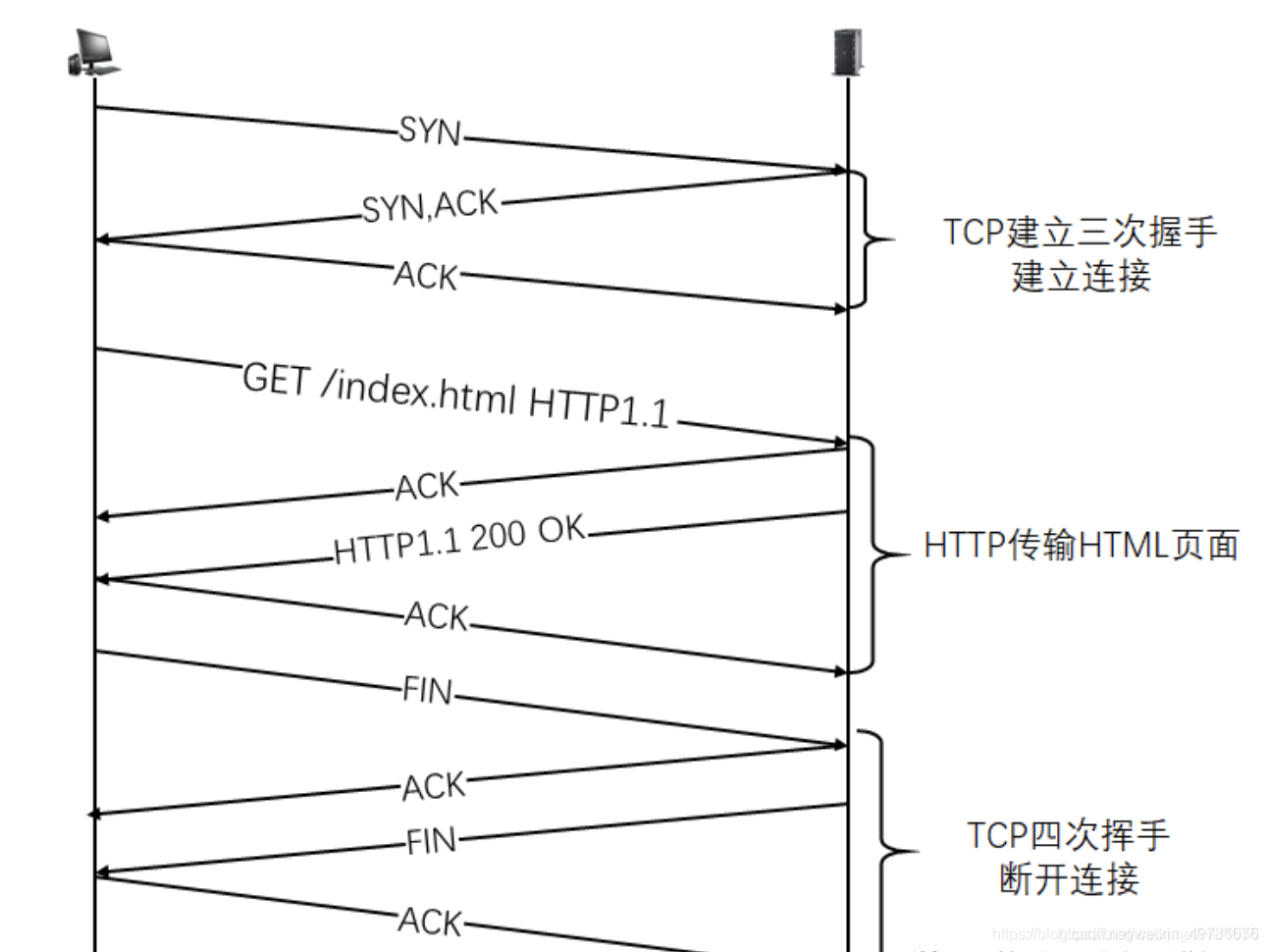
最终建立了TCP/IP的连接。如下图:
四.建立 TCP 连接后发送 HTTP 请求
HTTP请求报文的方法是 get ,如果浏览器存储了该域名下的 Cookies,那么会把 Cookies放入 HTTP请求头里发给服务器,用于识别用户信息。
根据上面的解析结果生成HTTP请求消息:
GET /index.html HTTP/1.1 <!-- 请求行 -->
User-Agent: curl/7.29.0
Host: www.baidu.com
Accept: */*
<!-- 空行 -->
五.服务器响应 HTTP 发送来的请求,浏览器得到 html 代码
服务器端WEB程序接收到http请求以后,就开始处理该请求,处理之后就返回给浏览器html文件。
发送请求后,会得到服务器的响应消息。
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Connection: keep-alive
Content-Length: 2443
Content-Type: text/html<!-- 空行 -->
<html>
<!-- ........省略...... -->
</html>
六.释放TCP连接(TCP的四次挥手)
- 浏览器所在主机向服务器发出连接释放报文,然后停止发送数据;
- 服务器接收到释放报文后发出确认报文,然后将服务器上未传送完的数据发送完;
- 服务器数据传输完毕后,向客户机发送连接释放报文;
- 客户机接收到报文后,发出确认,然后等待一段时间后,释放TCP连接;
七.浏览器解析 html 代码,并请求 html 代码中的相关资源(如 JS,CSS,图片等)
浏览器拿到 index.html 文件后,就开始解析其中的 html 代码,遇到 js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这个时候就用上 keep-alive 特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序就是按照代码里的顺序。
八.浏览器对页面进行渲染呈现给用户
最后,Chrome 浏览器利用自己内部的工作机制,把请求到的静态资源和 html 代码进行渲染,渲染之后呈现给用户。
当然,如果近期访问过的网页,很有可能缓存在本地,这样再次访问,就不需要去服务器拿数据,直接访问本地缓存数据,可以降低服务器的压力,提高响应速度。
九.总结
内核协议栈做了哪些事情:
因为HTTP协议底层用的是TCP协议,所以要经过三次握手进行连接,传送数据,最后四次挥手断开连接。
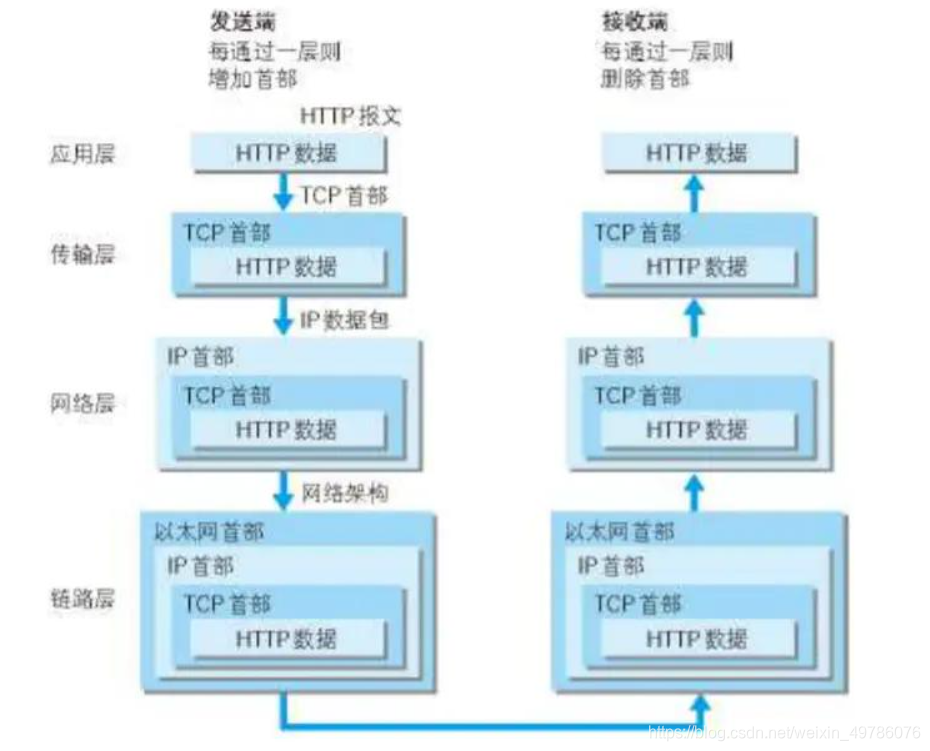
内核协议栈主要是将应用层HTTP请求按照TCP/IP协议栈的要求,经过层层封装后成帧,然后将报文的类似0101001串转换成电信号发送出去。














 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









