







手写一个GPT
在GPT,确切的说是Transformer,出现之前,一个问题长久地困扰着人们——如何让两句内容不同、但语义相近的句子得到较为接近的表示。
比如我们有两句话
- 我喜欢你
- 吾中意你
它们作为句子内容并不一样,但是表达的含义却是一样的。如果将句子作为
f(x)输入,进行情感分析或者翻译,最后得到的特征向量x也应该一样 (至少距离较近) 的。
对于文本来说,如何找到一种表达方式使得相似的文本得到相似的文本,这在过去十分困难,以至于衍生出了一个单独的研究领域——表征学习 (Representative Learning)。不过,Transformer的出现为这个问题提供了新的思路。
Transformer
背景
一个简单的事实——任意一个二维平面内的向量c可以由该平面内的两个向量a和b(不平行) 表示
c
→
=
m
a
→
+
n
b
→
m
,
n
∈
R
对于
∀
c
→
,
∃
m
,
n
使得
c
→
存在
\overrightarrow{c} = m\overrightarrow{a} + n\overrightarrow{b}\qquad m,n\in \R\\ 对于\forall \overrightarrow{c},\quad \exists \space m,n使得\space\overrightarrow{c}\space存在
c=ma+nbm,n∈R对于∀c,∃ m,n使得 c 存在
将这个事实推广,任意一个n维平面内的向量也可以这样表示
v
→
=
(
w
1
,
w
2
,
w
3
,
…
,
w
n
)
⋅
(
v
1
→
v
2
→
v
3
→
⋮
v
n
→
)
\overrightarrow{v}=\begin{pmatrix}w_1, w_2, w_3, \dots,w_n\end{pmatrix}\cdot \begin{pmatrix}\overrightarrow{v_1}\\\overrightarrow{v_2}\\\overrightarrow{v_3}\\\vdots\\\overrightarrow{v_n}\\\end{pmatrix}
v=(w1,w2,w3,…,wn)⋅
v1v2v3⋮vn
上面这种表示方式,在数学中叫做线性变换 (Linear Transform)。
语义表征
Transformer最开始内应用于机器翻译。
Step.1 Initialization
任意随机初始化了向量组V1, v2, ..., vn,分别用于表示n个单词 (准确的说应该是token,因为词组是连在一起的),我们期望得到的结果是——意思越相近的两token,其v值之间的距离越近。
那么我们现在假设向量组中每个v是k维的
v
i
→
=
(
v
i
1
,
v
i
2
,
v
i
3
,
⋯
,
v
i
k
)
k
\overrightarrow{v_i} = (v_{i1}, v_{i2}, v_{i3}, \cdots, v_{ik})_k
vi=(vi1,vi2,vi3,⋯,vik)k
Step.2 Positional Encoding
生活中我们经常用到这样一些句子,单词 (token) 一样但可以打乱顺序表达不一样的意思,比如
- 好吃嘛
- 吃嘛好
- 嘛好吃
容易理解,导致上述句子语义不同的原因在于token在句子中出现的位置不同,因此我们想到需要在token的表征过程中囊括位置信息 (Positional Encoding)。
Positional Encoding其实有多种实现方式,但是GPT的论文中使用了一种非常有意思的encoding方式。
便于说明,假设现在k=4,而我们要表示一句包含6个token的句子
v
1
→
=
(
v
11
,
v
12
,
v
13
,
v
14
)
v
2
→
=
(
v
21
,
v
22
,
v
23
,
v
24
)
v
3
→
=
(
v
31
,
v
32
,
v
33
,
v
34
)
v
4
→
=
(
v
41
,
v
42
,
v
43
,
v
44
)
v
5
→
=
(
v
51
,
v
52
,
v
53
,
v
54
)
v
6
→
=
(
v
61
,
v
62
,
v
63
,
v
64
)
\overrightarrow{v_1} = (v_{11}, v_{12}, v_{13}, v_{14})\\ \overrightarrow{v_2} = (v_{21}, v_{22}, v_{23}, v_{24})\\ \overrightarrow{v_3} = (v_{31}, v_{32}, v_{33}, v_{34})\\ \overrightarrow{v_4} = (v_{41}, v_{42}, v_{43}, v_{44})\\ \overrightarrow{v_5} = (v_{51}, v_{52}, v_{53}, v_{54})\\ \overrightarrow{v_6} = (v_{61}, v_{62}, v_{63}, v_{64})\\
v1=(v11,v12,v13,v14)v2=(v21,v22,v23,v24)v3=(v31,v32,v33,v34)v4=(v41,v42,v43,v44)v5=(v51,v52,v53,v54)v6=(v61,v62,v63,v64)
GPT的做法是,在四条不同的sin和cos曲线上找到6个点,当表示第一个token也就是向量v1时,就取四条曲线上第一个点所对应的y值 (即下图绿框部分)。
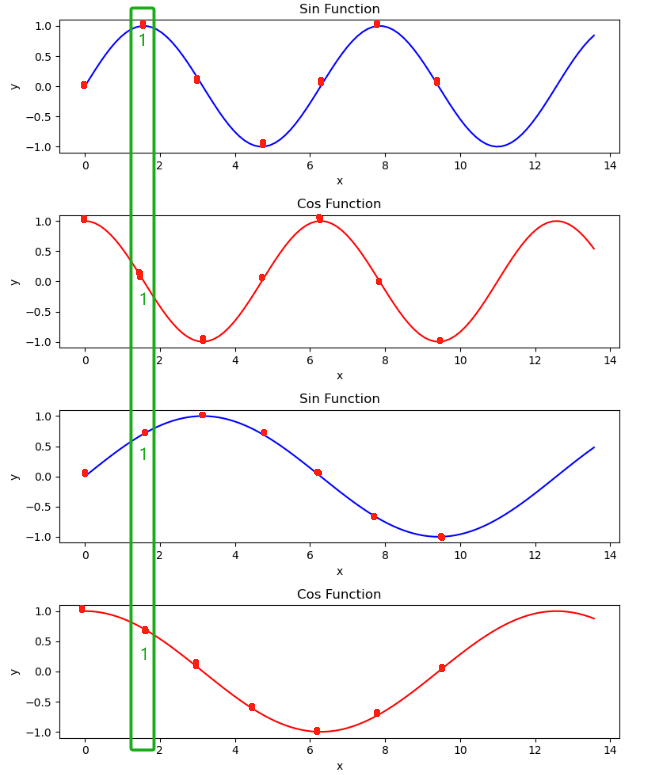
同理其他token。
这种Positional Encoding的好处在于
- 能够表示不同信息且值在[-1, 1]之间。
- 周期性:
我们经常发现,当一句话里出现重复的token,虽然位置不同,但是意思一样(“他不知道吃嘛好,我也不知道吃嘛好)
周期性地取值可以保证——虽然位置不同,但用于表示的值有可能是一样的,
这是普通的函数 (比如一个二次函数) 所无法做到的。 - 多样性:
至于使用维数k来决定使用多少三角函数,原因在于我们需要能表征理论上无限多的token,
那么当k足够大时 (想象一下曲线变得很平),我们总能在第k维找到与先前不同的值来使这个v区别于之前,
这是普通的周期函数所无法做到的
Step.3 Self-Attention
那么接下来,我们仔细想一想出了位置信息,还有哪些信息对于语义识别是必要的。
假设现在有这么一句话,我(v1)喜欢(v2)打(v3)网球(v4),它(v5)真的(v6)很(v7)有(v8)意思(v9)。
那么经过上面的Positional Encoding之后,每个token都将包含各自的位置信息
v
i
→
=
v
i
→
+
p
i
→
\overrightarrow{v_i} =\overrightarrow{v_i} + \overrightarrow{p_i}
vi=vi+pi
可是一个明显的问题,上面那句话中的v4和v5指代的显然是同一个东西 (网球),但是编码过后的结果并不能包含这个信息。所以一个token可能和其他某个token有关 (v5 = 0.95v4)。
如果我们将它这个token拿走,根据上下文语义能判断出来,这里不管是什么代词,指代的很大可能就是网球
所以,一个token具体表示什么含义,不光与位置有关,还与它的上下文有关 (v1`v4`和`v6`v9)。
除此之外,token的含义当然还与它自己是什么有关。
总结一下,除了位置信息,一个token还应该与
- 其他某个token
- 上下文信息
- 它自己
有关。
基于以上论述,我们期望的一个表达应该是这样的
v
i
,
=
w
1
v
1
→
+
w
2
v
2
→
+
w
3
v
3
→
+
⋯
+
w
n
v
n
→
v_i^, = w_1\overrightarrow{v_1} + w_2\overrightarrow{v_2} + w_3\overrightarrow{v_3} + \cdots + w_n\overrightarrow{v_n}
vi,=w1v1+w2v2+w3v3+⋯+wnvn
这就好比一个人根据自己所在团体中其他人的行为来决定自己应该作何行为,对自己影响大的就给予更多的“关注” (赋予更大的权重w)。
而这种“关注”,就是论文中提出的Self-Attention机制,同时也是一种线性变换 (这就是为什么GPT的T指代的就是Transformer)。
Step.4 Feedback
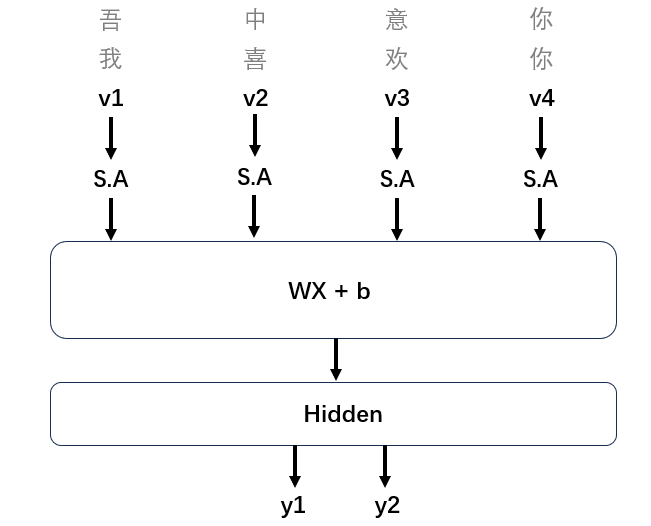
假如我们现在有两句不同的句子S1和S2,我们拆分token将v送入WX+b得到Hidden层,然后根据Hidden层信息得到y1和y2。
因为这两句话本质上的含义相同,所以用于训练的y1和y2值也是相同的。神经网络根据后向传播原理进行feedback,去调整W、b以及最重要的S.A中的那些“关注”。这样一来,即便“我”和“吾”、“喜欢”和“中意”内容不一样,但是根据它们相同的位置信息和上下文,最终训练得到的"关注"将会是一样的。
Step.5 Attention Matrix
假设现有n个token,向量v的维度是k,那么
Self-Attetion中用到的注意力矩阵形如下式
(
w
11
,
w
12
,
w
13
,
⋯
,
w
1
n
w
21
,
w
22
,
w
23
,
⋯
,
w
2
n
w
31
,
w
32
,
w
33
,
⋯
,
w
3
n
.
.
.
w
n
1
,
w
n
2
,
w
n
3
,
⋯
,
w
n
n
)
n
×
n
⋅
(
v
1
v
2
v
3
⋮
v
n
)
n
×
k
\begin{pmatrix} w_{11}, w_{12}, w_{13}, \cdots, w_{1n}\\ w_{21}, w_{22}, w_{23}, \cdots, w_{2n}\\ w_{31}, w_{32}, w_{33}, \cdots, w_{3n}\\ ...\\ w_{n1}, w_{n2}, w_{n3}, \cdots, w_{nn}\\ \end{pmatrix}_{n\times n}\cdot \begin{pmatrix} v_1\\v_2\\v_3\\\vdots\\v_n \end{pmatrix}_{n\times k}
w11,w12,w13,⋯,w1nw21,w22,w23,⋯,w2nw31,w32,w33,⋯,w3n...wn1,wn2,wn3,⋯,wnn
n×n⋅
v1v2v3⋮vn
n×k
可是经过试验发现,这样设置的注意力矩阵拟合效果不好,原因在于其中的权重w对于变化太敏感、或者说不够精细。
所以论文中将注意力矩阵进行了拆分,把原来的n x n的矩阵拆分成了n x d和d x n两个矩阵相乘。其中,前一个矩阵被称为Q(Query),后一个矩阵被称为K(Key)
(
Q
11
,
Q
12
,
Q
13
,
⋯
,
Q
1
d
Q
21
,
Q
22
,
Q
23
,
⋯
,
Q
2
d
Q
31
,
Q
32
,
Q
33
,
⋯
,
Q
3
d
.
.
.
Q
n
1
,
Q
n
2
,
Q
n
3
,
⋯
,
Q
n
d
)
n
×
d
⋅
(
K
11
,
K
12
,
K
13
,
⋯
,
K
1
n
K
21
,
K
22
,
K
23
,
⋯
,
K
2
n
K
31
,
K
32
,
K
33
,
⋯
,
K
3
n
.
.
.
K
d
1
,
K
d
2
,
K
d
3
,
⋯
,
K
d
n
)
d
×
n
\begin{pmatrix} Q_{11}, Q_{12}, Q_{13}, \cdots, Q_{1d}\\ Q_{21}, Q_{22}, Q_{23}, \cdots, Q_{2d}\\ Q_{31}, Q_{32}, Q_{33}, \cdots, Q_{3d}\\ ...\\ Q_{n1}, Q_{n2}, Q_{n3}, \cdots, Q_{nd}\\ \end{pmatrix}_{n\times d}\cdot \begin{pmatrix} K_{11}, K_{12}, K_{13}, \cdots, K_{1n}\\ K_{21}, K_{22}, K_{23}, \cdots, K_{2n}\\ K_{31}, K_{32}, K_{33}, \cdots, K_{3n}\\ ...\\ K_{d1}, K_{d2}, K_{d3}, \cdots, K_{dn}\\ \end{pmatrix}_{d\times n}
Q11,Q12,Q13,⋯,Q1dQ21,Q22,Q23,⋯,Q2dQ31,Q32,Q33,⋯,Q3d...Qn1,Qn2,Qn3,⋯,Qnd
n×d⋅
K11,K12,K13,⋯,K1nK21,K22,K23,⋯,K2nK31,K32,K33,⋯,K3n...Kd1,Kd2,Kd3,⋯,Kdn
d×n
Step.6 Equation
我们在论文中看到的自注意力等式长这样
V
s
e
l
f
−
a
t
t
e
n
t
i
o
n
=
S
o
f
t
m
a
x
(
Q
K
T
d
)
V
V_{self-attention} = Softmax(\frac{QK^T}{\sqrt{d}})V
Vself−attention=Softmax(dQKT)V
我们一点一点来解释
-
为什么使用
K的转置而不直接使用K?因为
K转置的大小和Q是一样的,这样可以避免额外定义第二个大小的矩阵。 -
为什么要使用Softmax?
因为我们要将权重 (“注意力”) 控制在0~1之间。
-
为什么要×
V?我们正在用自注意力机制优化
V。 -
为什么要÷
根号d?因为对于
(X1, X2, ... Xn),softmax的数学形式是
S i = e x i ∑ e x j S_i = \frac{e^{x_i}}{\sum{e^{x_j}}} Si=∑exjexi
而指数函数很容易因为指数过大而发生爆炸。
对于一堆被随机初始化在0~1范围内的数,什么时候会发生爆炸呢?显然是当d被设置得非常大的时候,当巨量的参数相乘后再相加,这时可能会导致指数变得很大。
这也就是为什么论文中会在Q和K相乘之后除以一个根号d。
Step.7 Multi-Head
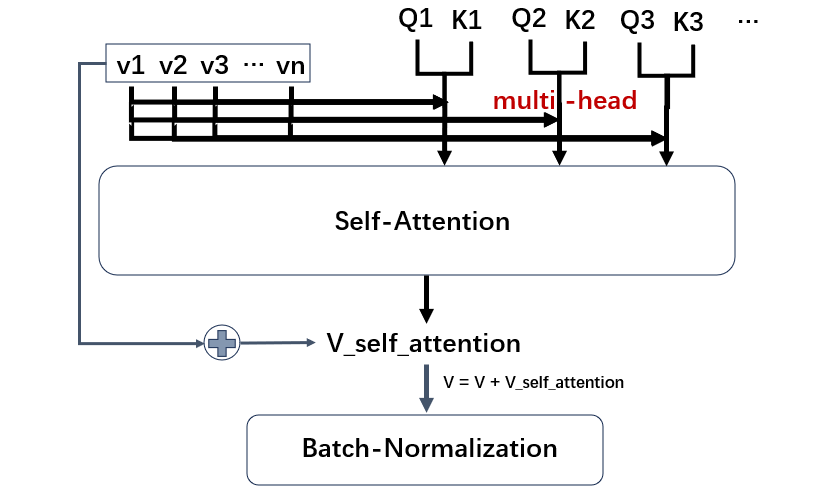
现在整个自注意力机制的结果图如下,其中V与QK相乘的位置被叫做一个head。
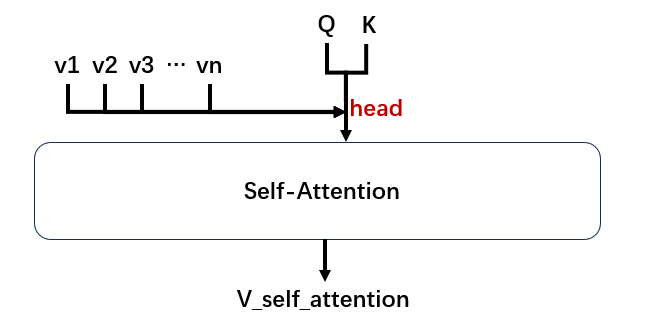
由于QK中每一行和列的相乘与其他行和列无关,所以这种计算还可以通过并行计算来加速 (GPU),所以这种计算速度会非常快。
那么既然计算速度非常快,我们不妨多来几个Q和K,以防止初始化导致的权重不理想 (类似于避免局部最优解)
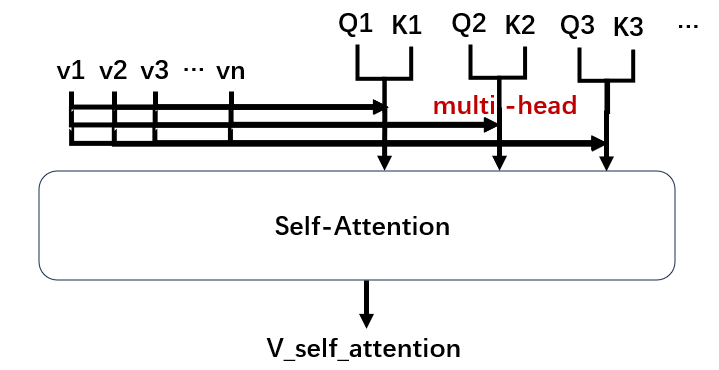
这种方法就被叫做多头注意力机制 (Multi-head Self-attention)。
除了多头,论文还采用了类似残差网络的设置将原始V与S.A之后的V相加作为新的V,以尽可能多地保留原来V的特性。
此外,得到的结果还需要进行Batch-Normalization进行归一化。
机器翻译
明白了Transformer的原理,我们就可以理解机器翻译乃至文本生成的原理了。
Encoder & Decoder
首先总结一下上面的内容
-
我们把
我喜欢打网球这句话拆成了4个token。 -
用sin和cos函数给它们加上各自的位置信息,得到新的
V。 -
初始化
Q和K,一起输入Self Attention层。 -
对输出结果进行残差、归一化,然后前向传播,再归一化。
-
得到最终的结果
E。
可以发现这个其实就是一个Encoder,把输入数据变成了一种中间状态,这种状态包含了句子的完整信息。
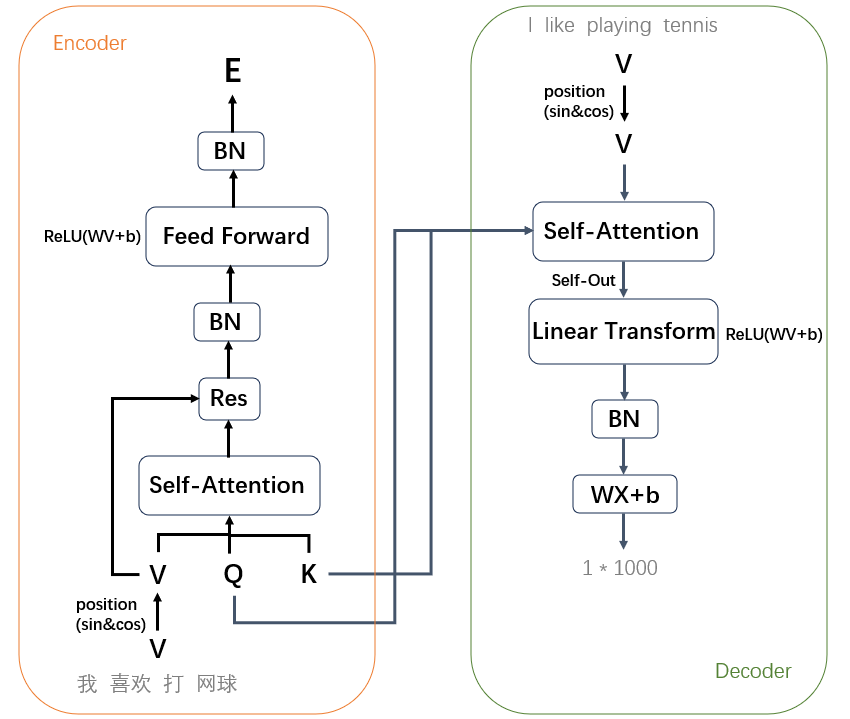
与Encoder相对应的是Decoder,Decoder的目的是将中间状态E进行拆分,从而还原出句子所包含的那些信息。
拆分的过程类似于Encoder的逆过程
- 我们把对应的翻译文本也进行tokenization。
- 加上位置信息与
Q和K一起输入Self Attention层。
不过值得注意的是,这里的Q和k是直接从Encoder部分取过来的,它们将包含Encoder的信息,因此我们输入的每一个字和它们的位置,最终都会影响Decoder部分的Self-Out。 - 对输出结果进行一些线性变换和归一化。
- 最后我们通过控制
W的维度使之输出1*N大小的向量
这里N的大小取决于我们的词表长度,比如我们有一个大小为1000的词表,当中包含常用的英文token,我们希望的是在decode喜欢这个token的时候,如果like在词表中所对应的index是99,那么这个向量中对应index的值会最大。
注意:在最开始我们当然不能直接告诉Decoder,
喜欢对应的是like。一开始Decoder的输入其实是一个<SOS>(Start of Sentence),它需要通过梯度下降的手段 (比如Cross Entropy) 来使得最终拟合得到的词表中like的值最大。
可是这样的一个一个token去训练比较低效,因此有人就想到使用批量的输入来训练,训练的目标是
<SOS>->I<SOS> I->I like<SOS> I like->I like playing<SOS> I like playing->I like playing tennis
关于机器翻译的批训练还有一个trick:逆向输入
很简单,举个例子,当我们想把一种语言中的一句话
ABCD翻译成另一种语言中的一句话αβγδ。
如果正向输入当然是可以的,但是如果逆向输入,ABCD与δγβα有一半的token与它对应token之间的距离更近了。因此,论文中采用的输入其实是:
<EOS> tennis playing like I
所以,最后的训练目标应该是
<EOS>->I<EOS> tennis->I like<EOS> tennis palying->I like playing<EOS> tennis playing like->I like playing tennis
至此,机器翻译的原理已经讲解完毕。
BERT
在介绍GPT之前,BERT也是一个值得一说的概念。
BERT 全称 Bidirectional Encoder Representations from Transformers,用于文本分类、语义分析、情感分析类的问题比较多。
BERT的原理其实就是我们上面所讲机器翻译原理的左半部分 (Encoder),那么为什么叫这个名字也就很清楚了
- Bidirectional:双向的,意思是每个token和前后的上下文token有关。
- Encoder:将句子转换成了一种中间信息。
- Representations:它是某种语义表征方法。
- Transformers:该方法涉及很多的线性变换。
GPT
Mask
讲到这里我们需要纠正前面机器翻译的一个内容。
根据前面讲的,假设还是I like playing tennis这句话。那么
v
l
i
k
e
=
w
1
⋅
v
I
+
w
2
⋅
v
l
i
k
e
+
w
3
⋅
v
p
l
a
y
i
n
g
+
w
4
⋅
v
t
e
n
n
i
s
v_{like} = w_1\cdot v_{I} + w_2\cdot v_{like} + w_3\cdot v_{playing} + w_4\cdot v_{tennis}
vlike=w1⋅vI+w2⋅vlike+w3⋅vplaying+w4⋅vtennis
可是由于我们训练的是一个生成式的模型,v_like其实不应该获得它后面的信息。
所以很容易理解,我们需要对QK^T进行一下处理
(
w
11
,
−
∞
,
−
∞
,
⋯
,
−
∞
w
21
,
w
22
,
−
∞
,
⋯
,
−
∞
w
31
,
w
32
,
w
33
,
⋯
,
−
∞
.
.
.
w
n
1
,
w
n
2
,
w
n
3
,
⋯
,
w
n
n
)
n
×
n
\begin{pmatrix} w_{11}, -\infty, -\infty, \cdots, -\infty\\ w_{21}, w_{22}, -\infty, \cdots, -\infty\\ w_{31}, w_{32}, w_{33}, \cdots, -\infty\\ ...\\ w_{n1}, w_{n2}, w_{n3}, \cdots, w_{nn}\\ \end{pmatrix}_{n\times n}
w11,−∞,−∞,⋯,−∞w21,w22,−∞,⋯,−∞w31,w32,w33,⋯,−∞...wn1,wn2,wn3,⋯,wnn
n×n
因为右上角是负无穷大,所以经过softmax之后会变成0。这个过程就叫做Mask。
GPT
GPT 全称 Generative Pretrained Transformer,与BERT一对比,我们很容易发现GPT用到的正是机器翻译原理的右半部分——一个生成式的模型。
只要有足够多的语料给到Decoder,它就能实现:给定前半段话,生成后半段。
这也就是为什么,如果你使用过2022年12月份的ChatGPT的话,会发现那时的GPT其实更类似一个续写功能——它会将你的问题重复一遍然后接着回答。
而现在的ChatGPT显然有迭代更新了许多,不会傻傻地重复我们的问题。原因是研发人员在训练好一个GPT的基础上,有加入了很多QA对用于训练
比如
: … …
: … …
从而实现了问答的生成效果。
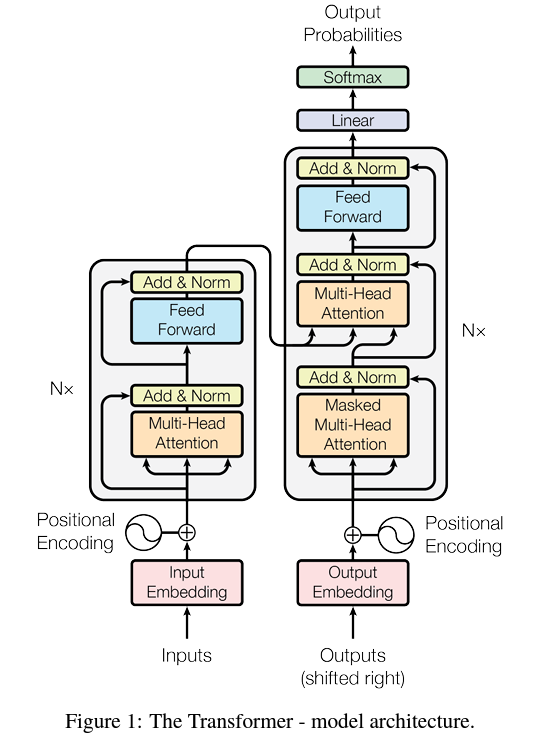
原始论文中的模型结构如上。
代码
Transformer
import torch
import torch.nn.functional as F
from torch import nn
首先,我们生成4句话,每句话包含10个单词,每个单词用k=32维来表示
batch = 4
length = 10
dim = 32
x = torch.radn(batch, length, dim)
torch.randn(batch, length, dim)[0][1]
### Output:
### tensor([-0.4044, 0.2266, 1.4815, 1.1106, 0.4096, 0.1700, 0.4340, -0.8538,
### 0.5718, 0.2863, 0.8569, 0.6653, -1.0324, 1.3156, -0.0550, -1.2413,
### -0.1136, -1.5654, -1.8861, 2.0968, -0.9345, 1.2409, -1.8750, -1.7113,
### -1.5986, -0.1449, -1.2132, -0.9459, 0.8799, -0.3710, 2.0002, 0.2066])
可以看到每一个单词用到了32个维度表示
接下来我们定义W=QK^T矩阵
weights = torch.randn(length, length)
### Shape: 10 * 10
tril = torch.tril(torch.ones(length, length))
F.softmax(weights.masked_fill(tril == 0, float('-inf')), dim=1) # 对一行做softmax,每行和为1
其中
torch.tril(torch.ones(length, length)) ### Output: ### tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], ### [1., 1., 0., 0., 0., 0., 0., 0., 0., 0.], ### [1., 1., 1., 0., 0., 0., 0., 0., 0., 0.], ### [1., 1., 1., 1., 0., 0., 0., 0., 0., 0.], ### [1., 1., 1., 1., 1., 0., 0., 0., 0., 0.], ### [1., 1., 1., 1., 1., 1., 0., 0., 0., 0.], ### [1., 1., 1., 1., 1., 1., 1., 0., 0., 0.], ### [1., 1., 1., 1., 1., 1., 1., 1., 0., 0.], ### [1., 1., 1., 1., 1., 1., 1., 1., 1., 0.], ### [1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]])weights.masked_fill(tril == 0, float('-inf')) ### Output: ### tensor([[-0.9948, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf], ### [-2.1458, -0.8541, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf], ### [ 1.4799, -0.0119, 0.0408, -inf, -inf, -inf, -inf, -inf, -inf, -inf], ### [-1.4272, -0.5384, 0.7607, 1.2860, -inf, -inf, -inf, -inf, -inf, -inf], ### [ 0.6735, 1.0775, -0.8327, 0.4255, -0.4259, -inf, -inf, -inf, -inf, -inf], ### [-0.3188, 0.8820, 0.2283, -0.2220, -0.3183, 0.4187, -inf, -inf, -inf, -inf], ### [ 0.8952, 0.1396, 0.6274, 0.1733, 0.3232, -0.3459, -0.1853, -inf, -inf, -inf], ### [ 0.0332, -0.1327, -0.3655, -0.6761, 1.4244, 0.3059, 0.0925, -1.4423, -inf, -inf], ### [-1.1770, -1.4961, -0.2148, -0.4129, -0.8316, -1.0020, 1.4585, 0.6684, 0.9888, -inf], ### [ 0.4760, -0.9807, 0.3479, 0.5790, -0.9908, -0.7411, -1.3312, -0.8196, -0.0580, -0.2273]])以上对应的就是原理部分讲解的Mask的实现。
接下来我们拆分Q和K,attention_size对应的就是我们自己定义的参数d
attetion_size = 16
query = nn.Linear(dim, attetion_size)
key = nn.Linear(dim, attetion_size)
k = key(x)
q = query(x)
k.shape
### Output:
### torch.Size([4, 10, 16])
q.shape
### Output:
### torch.Size([4, 10, 16])
至此,我们其实实现了一个单头注意力,把上面的内容整合成一个类方法,唯一的增加是使用了Dropout将一些数据在训练中置零
n_embsize = 32
class SelfAttention(nn.Module):
def __init__(self, att_size):
super().__init__()
self.query = nn.Linear(n_embsize, att_size, bias=False)
self.key = nn.Linear(n_embsize, att_size, bias=False)
self.value = nn.Linear(n_embsize, att_size, bias=False)
self.dropout = nn.Dropout(dropout=0.75) # 增加难度,随机将一些位置置为0
def forward(self, x):
B, L, D = x.shape
q = self.query(x)
k = self.key(x)
v = self.value(x)
weights = q @ k.transpose(1, 2)
self.tril = torch.tril(torch.ones(L, L))
weights = F.softmax(weights.masked_fill(tril == 0, float('-inf')), dim=-1)
weights = self.dropout(weights)
out = weights @ v
return out
多头注意力就是循环地重复调用单头注意力
class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, att_size):
super().__init__()
self.heads = nn.ModuleList(SelfAttention(att_size) for _ in range(num_heads))
self.proj = nn.Linear(num_heads * att_size, n_embsize) # 映射:一个线性变换将输出降为n_embsize维
self.dropout = nn.Dropout(dropout=0.75)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out
还记得Transformer的流程吗?多头 -> 残差 -> 前馈,所以我们还需要定义一个前馈网络
class FeedForward(nn.Module):
def __init__(self, n_embd):
super().__init__()
hidden_size = 4 * n_embd # 这是一个任意的中间状态
self.net = nn.Sequential(
nn.Linear(n_embd, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, n_embd), # 变回n_embd维
nn.Dropout()
)
def forward(self, x):
return self.net(x)
至此,就可以组装我们的Transformer了
class TransformerBlock(nn.Module):
def __init__(self, n_embd, att_size):
super().__init__()
head_size = n_embd / att_size # 这里head_size即多头个数,理论上可以任意设置,不过这里采用谷歌推荐的写法
self.mul_head_self_att = MultiHeadAttention(head_size, att_size)
self.ffw = FeedForward(n_embd)
self.ln1 = nn.LayerNorm(n_embd) # Layer Normalization有助于稳定训练,通过标准化输入的均值和方差,以减少梯度消失问题,也是为了确保残差连接的稳定性
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
x = x + self.sa(self.ln1(x)) # self.sa 是多头自注意力(Multi-Head Self-Attention)操作的组件。多头自注意力接受规范化后的输入 self.ln1(x),然后执行注意力操作,将输入序列中不同位置的信息进行交互。这可以理解为模型在不同位置对输入进行关注,以便更好地理解输入的上下文。
x = x + self.ffw(self.ln1(x)) # 前馈
return x
GPT-Model
有了Transformer,一个GPT的核心就已经成型了,接下来就是建模的过程
device = torch.device("cuda")
n_embsize = 32
max_length = 100 # 文本块最大长度
att_size = 10
head_size = n_embsize / att_size
n_layer = 2
class GPTLanguageModle(nn.Module):
def __init__(self):
super().__init__()
self.token_embedding_table = nn.Embedding(vocab_size, n_embsize)
self.position_embedding_table = nn.Embedding(max_length, n_embsize)
self.stacked_transformers = nn.Sequential(*[TransformerBlock(n_embsize, att_size) for _ in n_layer])
self.ln_f = nn.LayerNorm(n_embsize)
self.lm_head = nn.Linear(n_embsize, vocab_size)
def _init_weight(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward(self, idx, target):
B, L = idx.shape
tok_emb = self.token_embedding_table(idx) # (B, L, D)
pos_emb = self.position_embedding_table(torch.arange(L, device=device))
x = tok_emb + pos_emb # (B, L, D)
x = self.stacked_transformers(x)
x = self.ln_f(x)
logits = F.softmax(self.lm_head(x))
if target:
B, L, D = logits.shape()
logits = logits.view(B * L, D)
target = target.view(B * L)
loss = F.cross_entropy(logits, target)
else:
loss = None
return logits, loss
这段代码实现了一个简单的 GPT(Generative Pretrained Transformer)语言模型:
-
self.token_embedding_table是一个嵌入层,用于将输入的整数标记(tokens)转换为密集的词嵌入向量。这些嵌入向量是模型学习的参数,用于表示不同的词或标记。vocab_size表示词汇表的大小,n_embsize表示嵌入维度。 -
self.position_embedding_table是另一个嵌入层,用于为输入的每个位置添加位置嵌入。这是因为语言模型需要考虑文本中不同位置的关系。max_length表示文本块的大小,n_embsize表示。 -
self.stacked_transformers是一个由多个 Transformer 模块组成的堆叠。每个 Transformer 模块被称为TransformerBlock,并且n_layer决定了堆叠的层数。每个 TransformerBlock 接受输入,并在内部执行自注意力和前馈神经网络操作。这些 Transformer 模块有助于模型学习文本序列之间的依赖关系。 -
self.ln_f是最后一层的 Layer Normalization,用于规范化最终的输出。 -
self.lm_head是一个线性层,它将模型的输出映射到词汇表的大小,以便生成下一个标记的概率分布。 -
_init_weights方法用于初始化模型的权重。它采用了合适的初始化策略,以帮助模型更好地训练。 -
forward方法是模型的前向传播。它接受输入idx,这是一个整数标记的张量,表示输入文本的标记序列。模型首先将这些标记转换为嵌入向量,并加上位置嵌入。然后,输入经过堆叠的 Transformer 模块,最后经过 Layer Normalization。-
logits = logits.view(B * T, C)将logits从维度 (B, T, C) 的三维张量重塑为维度 (B * T, C) 的二维张量。这是为了将批次(B)和时间步(T)维度合并为一个单独的维度,以便进行损失计算。logits包含了模型的预测概率分布,它的维度是 (B * T, C),其中 B * T 表示批次大小与序列长度的乘积,C 表示词汇表的大小。 -
targets = target.view(B * T)类似地,将target从维度 (B, T) 的二维张量重塑为维度 (B * T) 的一维张量。这是为了将目标标签与预测概率分布对齐,以便计算损失。target包含了实际的目标标签,它的维度是 (B * T),其中 B * T 表示批次大小与序列长度的乘积。
在这两行代码执行后,
logits和targets现在都是一维张量,其中logits包含了模型的预测概率,targets包含了实际目标标签。这些变换是为了方便之后的交叉熵损失计算。通常,我们将logits和targets传递给损失函数,用于计算模型的损失。 -
-
模型的输出是一个概率分布
logits,表示模型对每个标记的生成概率。如果提供了targets,则计算损失。损失采用交叉熵损失函数,用于衡量模型的输出与目标标记之间的差异。
这里可能有人好奇,得到了logits后,GPT如何从其对应的vocabulary中找到概率最高的下一个token呢?
下面是openai的GPT接口官方文档,可以看到有一个参数叫做temperature = 72
这个temperature的作用是——temperature值越小,越根据logits的大小取token;temperature值越大,token的取法就越随机。
下面是一个简单的演示
import numpy as np def softmax(x): return np.exp(x) / np.sum(np.exp(x)) temperature = 100 logits = softmax(np.array([10, 20, 30]) / temperature) print(logits) np.random.choice([0, 1, 2], p=logits)假设现在有一组概率分布
logits = [10, 20, 30]
- 当
temperature = 1时,我们将logits送入参数p,极大概率取得的结果是2- 当
temperature = 100时,我们将logits送入参数p,0、1、2都有可能出现,但2出现概率稍大一些- 当
temperature = 1000时,我们将logits送入参数p,0、1、2出现概率相同,随机选择
Training of GPT model
with open('./shakespeare.txt') as f:
text = f.read()
text = text.lower()
batch_size = 8 # How many independent sequences will we process in parallel?
block_size = 128 # What is the maximum context length for prediction?
att_size = 16
max_iters = 314000
eval_interval = 500
learning_rate = 3e-4
device = 'cuda' if torch.cuda.is_available() else 'cpu'
eval_iters = 200
n_embd = 200
n_head = 6
n_layer = 6
dropout = 0.2
import re
def token(string):
return re.findall('\w+', string)
words = list(token(text))
vocab_size = len(set(words))
vocab_size
### Output:
### 32171
stoi = { ch:i for i,ch in enumerate(set(words))}
itos = { i:ch for ch,i in stoi.items()}
encode = lambda s : [stoi[c] for c in s] # encoder: take a string, output a list of integers
decode = lambda l : ' '.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
data = torch.tensor(encode(words), dtype=torch.long)
n = int(0.9*len(data)) # first 90% will be train, rest val
train_data = data[:n]
val_data = data[:n]
words[:10]
### Output:
### ['i', 'want', 'you', 'now', 'to', 'imagine', 'a', 'wearable', 'robot', 'that']
data[:10]
### Output:
### tensor([25910, 13589, 3702, 7387, 131, 2978, 399, 11599, 7816, 15976])
torch.cuda.empty_cache() # 释放未使用的 GPU 内存
torch.backends.cudnn.benchmark = True # 提高性能,但可能会增加 GPU 内存使用
torch.backends.cudnn.deterministic = True # 使运行更可重复,但可能会减少性能
class SelfAttention(nn.Module):
def __init__(self, att_size):
super().__init__()
self.query = nn.Linear(n_embd, att_size, bias=False)
self.key = nn.Linear(n_embd, att_size, bias=False)
self.value = nn.Linear(n_embd, att_size, bias=False)
self.dropout = nn.Dropout(dropout) # 增加难度,随机将一些位置置为0
def forward(self, x):
B, L, D = x.shape
q = self.query(x)
k = self.key(x)
v = self.value(x)
weights = q @ k.transpose(1, 2)
self.tril = torch.tril(torch.ones(L, L)).to(device)
weights = F.softmax(weights.masked_fill(self.tril[:L, :L] == 0, float('-inf')), dim=-1)
weights = self.dropout(weights)
out = weights @ v
return out
class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, att_size):
super().__init__()
self.heads = nn.ModuleList(SelfAttention(att_size) for _ in range(num_heads))
self.proj = nn.Linear(num_heads * att_size, n_embd) # 映射:一个线性变换将输出降为n_embsize维
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out
class FeedForward(nn.Module):
def __init__(self, n_embd):
super().__init__()
hidden_size = 4 * n_embd # 这是一个任意的中间状态
self.net = nn.Sequential(
nn.Linear(n_embd, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, n_embd), # 变回n_embd维
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class TransformerBlock(nn.Module):
def __init__(self, n_embd, att_size):
super().__init__()
head_size = n_embd // att_size # 这里head_size即多头个数,理论上可以任意设置,不过这里采用谷歌推荐的写法
self.sa = MultiHeadAttention(head_size, att_size)
self.ffw = FeedForward(n_embd)
self.ln1 = nn.LayerNorm(n_embd) # Layer Normalization有助于稳定训练,通过标准化输入的均值和方差,以减少梯度消失问题,也是为了确保残差连接的稳定性
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
x = x + self.sa(self.ln1(x)) # self.sa 是多头自注意力(Multi-Head Self-Attention)操作的组件。多头自注意力接受规范化后的输入 self.ln1(x),然后执行注意力操作,将输入序列中不同位置的信息进行交互。这可以理解为模型在不同位置对输入进行关注,以便更好地理解输入的上下文。
x = x + self.ffw(self.ln2(x)) # 前馈
return x
class GPTLanguageModel(nn.Module):
def __init__(self):
super().__init__()
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
self.position_embedding_table = nn.Embedding(block_size, n_embd)
self.stacked_transformers = nn.Sequential(*[TransformerBlock(n_embd, att_size) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embd)
self.lm_head = nn.Linear(n_embd, vocab_size)
# better init
self.apply(self._init_weight)
def _init_weight(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward(self, idx, target=None):
B, L = idx.shape
tok_emb = self.token_embedding_table(idx) # (B, L, D)
pos_emb = self.position_embedding_table(torch.arange(L, device=device))
x = tok_emb + pos_emb # (B, L, D)
x = self.stacked_transformers(x)
x = self.ln_f(x)
# logits = F.softmax(self.lm_head(x))
logits = self.lm_head(x)
if target is None:
loss = None
else:
B, L, D = logits.shape
logits = logits.view(B * L, D)
target = target.view(B * L)
loss = F.cross_entropy(logits, target)
return logits, loss
def generate(self, idx, max_new_tokens):
for _ in range(max_new_tokens):
idx_cond = idx[:, -block_size:]
logits, loss = self(idx_cond)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
return idx
model = GPTLanguageModel()
m = model.to(device)
# print the number of parameters in the model
print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')
### Output:
### 15.780171 M parameters
# create a PyTorch optimizer
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
# data loading
def get_batch(split):
data = train_data if split == 'trian' else val_data
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1:i+block_size+1] for i in ix])
x, y = x.to(device), y.to(device)
return x, y
@torch.no_grad()
def estimate_loss():
out = {}
model.eval()
for split in ['train', 'val']:
losses = torch.zeros(eval_iters)
for k in range(eval_iters):
X, Y = get_batch(split)
logits, loss = model(X, Y)
losses[k] = loss.item()
out[split] = losses.mean()
model.train()
return out
losses = []
loss_history = []
for iter in range(max_iters):
# every once in a while evaluate the loss on trian and val sets
if iter % eval_interval == 0 or iter == max_iters - 1:
losses = estimate_loss()
print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
# sample a batch of data
xb, yb = get_batch('train')
# evaluate the loss
logits, loss = model(xb, yb)
loss_history.append(loss)
print(f'iter: {iter}, loss: {loss}')
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
受限于设备,训练过后我只下降到了0.5。有能力的可以尝试使用内存更大的GPU,或者使用characters而非words进行训练,理论上可以下降到0.1以下。
Using of GPT Model
# 保存模型
torch.save(model.state_dict(), 'model.pth')
# 加载模型
model = GPTLanguageModel() # 创建一个新的模型实例
model.load_state_dict(torch.load('model.pth')) # 加载已保存的权重和参数
model.eval() # 设置模型为评估模式
m = model.to(device)
prompt = 'to be'
idx_input = [stoi[w] for w in prompt.split()]
context = torch.tensor([idx_input], device=device)
print(decode(m.generate(context, max_new_tokens=10)[0].tolist()))
# Output:
### to be limber destroyer strays tear traducement neighbour leaf hoodwink dials forewarned















 1102
1102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









