







目录
一、 发送 GET 请求
当用户在浏览器的地址栏中直接输入某个 URL
地址或者单击网页上的某个超链接时,浏
览器会使用
GET
方法向服务器发送请求。例如,在浏览器的地址栏中分别输入
https://www.baidu.com/
和
https://www.baidu.com/s?wd=python
,按
Enter
键后打开百度首页和
python
关键词的查询结果页面。此时我们用
Fiddler
工具捕获刚刚发送的两个请求,可以看到
这两个请求的请求方法都是
GET
。
在 Requests
库中,
get()
函数用于向服务器发送
GET
请求。该函数会根据传入的
URL
构
建一个请求(每个请求都是
Request
类的对象),之后将该请求发送给服务器。
get()
函数的声
明如下:
get(url, params=None, headers=None, cookies=None, verify=True,proxies=None, timeout=None, **kwargs)
上述函数中各参数的含义如下。
- url:必选参数,表示请求的 URL。
- params:可选参数,表示请求的查询字符串。该参数支持 3 种类型的取值,分别为字
典、元组列表、字节序列。当该参数的值是一个字典时,字典的键为
url
参数,字典的值为
url
参数对应的值,例如
{"ie": "utf-8","wd": "python"}
。
- headers:可选参数,表示请求的请求头,该参数只支持字典类型的值。
- cookies:可选参数,表示请求的 Cookie 信息,该参数支持字典或 CookieJar 类的对象。第 3 章 抓取静态网页数据 045
- verify:可选参数,表示是否启用 SSL 证书,默认值为 True。
- proxies:可选参数,用于设置代理服务器,该参数只支持字典类型的值。
- timeout:可选参数,表示请求网页时设定的超时时长,以秒为单位。
下面分别以访问百度首页和 python
关键词的查询结果页面为例,演示如何使用
get()
函数
发送不携带
url
参数和携带
url
参数的
GET
请求。
1.不携带 url 参数的 GET 请求
若 GET
请求的
URL
中不携带参数,我们在调用
get()
函数发送
GET
请求时只需要给
url
参
数传入指定的
URL
即可。例如,使用
get()
函数发送
GET
请求访问百度首页,具体代码如下。
import requests
# 准备 URL
base_url = 'https://www.baidu.com/'
# 根据 URL 构造请求,发送 GET 请求,接收服务器返回的响应信息
response = requests.get(url=base_url)
# 查看响应码
print(response.status_code)
上述代码中,首先定义了一个代表请求 URL
地址的变量
base_url
,然后调用
requests
库
中的
get()
函数发送
GET
请求。当百度服务器接收到请求后会返回响应信息,并将响应信息保
存到
response
中。最后通过访问
response
的
status_code
属性查看响应状态码,以确认此次访
问是否成功。
运行代码,输出如下结果。
200
从输出的结果可以看出,服务器返回的响应状态码为
200
,说明成功访问了百度首页。
2.携带 url 参数的 GET 请求
如果 GET
请求的
URL
中携带参数,那么我们在调用
get()
函数时可以采用两种方式发送
GET
请求。第
1
种方式是将参数以“
?
参数名
1=
值
1&
参数名
2=
值
2...
”的形式拼接到
URL
后
面,进而手动构建完整的
URL
,例如
https://www.baidu.com/s?wd=python
,并将完整的
URL
传入
url
参数;第
2
种方式是将
url
参数转换为字典,之后将该字典传入
params
参数。
第
1
种方式的实现代码如下。
import requests
base_url = 'https://www.baidu.com/s'
param = 'wd=python'
# 拼接完整的 URL
full_url = base_url + '?' + param
# 根据 URL 构造请求,发送 GET 请求,接收服务器返回的响应信息
response = requests.get(full_url)
# 查看响应码
print(response.status_code)
运行代码,输出如下结果。
200
第
2
种方式的实现代码如下。
import requests
base_url = 'https://www.baidu.com/s'
wd_params = {'wd': 'python'}
# 根据 URL 构造请求,发送 GET 请求,接收服务器返回的响应
response = requests.get(base_url, params=wd_params)
# 查看响应码
print(response.status_code)
运行代码,输出如下结果。
200
通过观察两次的输出结果可知,服务器返回的响应状态码都为
200
。这说明我们成功访问
了
python
关键词的查询结果页面。
二、发送 POST 请求
如果网页上 form
表单的
method
属性的值为
POST
,那么当用户提交表单时,浏览器将使
用
POST
方法提交表单内容,并将各个表单元素及数据作为
HTTP
请求信息中的请求数据发
送给服务器。例如登录美多商城时发送的请求是
POST
请求。此时使用
Fiddler
工具捕获该请
求,可以看到发送该请求时的请求数据,具体如图
3-1
所示。
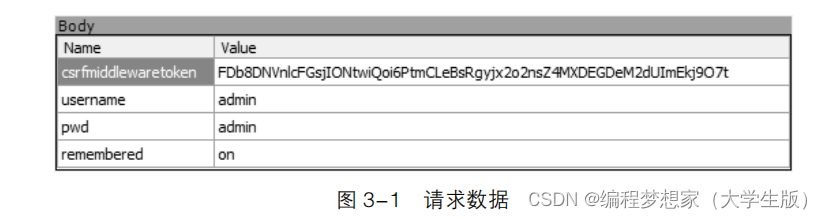
在
Requests
中,
post()
函数用于向服务器发送
POST
请求。该函数会根据传入的
URL
构建
一个请求,将该请求发送给服务器,并接收服务器成功响应后返回的响应信息。
post()
函数的
声明如下:
post(url, data=None, headers=None, cookies=None, verify=True,
proxies=None, timeout=None, json=None, **kwargs)
post()与
get()
函数的参数大致相同,除了
get()
函数中介绍过的参数以外,
post()
函数中其
他参数的含义如下。
- data:可选参数,表示请求数据。该参数可以接收 3 种类型的值,分别为字典、字节
序列和文件对象。当参数值是一个字典时,字典的键为请求数据的字段,字典的值为请求数
据中该字段对应的值,例如
{"ie": "utf-8","wd": "python"}
。
- json:可选参数,表示请求数据中的 JSON 数据。
下面以美多商城网站为例,为大家演示如何使用
post()
函数请求美多商城网站首页,具体
代码如下。
import requests
base_url = 'http://mp-meiduo-python.itheima.net/login/'
# 准备请求数据
form_data = {
'csrfmiddlewaretoken':
'FDb8DNVnlcFGsjIONtwiQoi6PtmCLeBsRgyjx2o2nsZ4MXDEGDeM2dUImEkj9O7t',
'username': 'admin',
'pwd': 'admin',
'remembered': 'on'
}
# 根据 URL 构造请求,发送 POST 请求,接收服务器返回的响应信息
response = requests.post(base_url, data=form_data)
# 查看响应信息的状态码
print(response.status_code)
运行代码,输出如下结果。
200
从输出结果可以看出,服务器返回的响应状态码为
200
。这说明我们成功访问了美多商
城网站首页。
三、处理响应
当服务器返回的响应状态码为 200
时,说明本次
HTTP
请求成功,此时可以接收到由服
务器返回的响应信息。在
Requests
库中,
Response
类的对象中封装了服务器返回的响应信息,
那些响应信息包括响应头和响应内容等。除了前面介绍的
status_code
属性之外,
Response
类
还提供了一些其他属性。
Response
类的常用属性如表
3-1
所示。
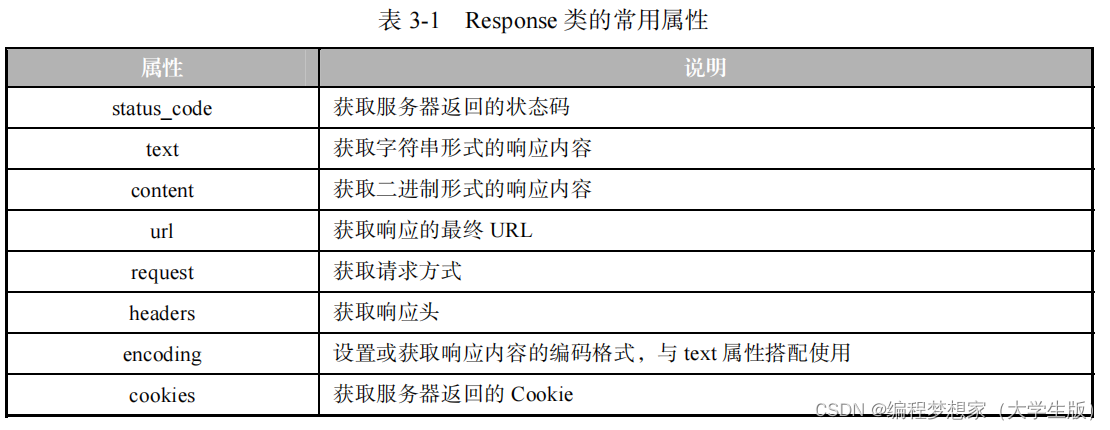
在表 3-1
中,
text
属性和
content
属性都可以获取响应内容。其中,
text
属性会根据
Requests
库推测的编码方式将响应内容编码为字符串类型的数据;
content
属性用于获取二进
制形式的响应内容。若需要从响应内容中提取文本,则可以使用
text
属性获取响应内容;若
需要从响应内容中提取图片、文件等,则可以使用
content
属性获取响应内容。
接下来,为大家演示如何使用
text
属性和
content
属性获取网页源代码和图片。
1.获取网页源代码
通过访问 Response
类的对象的
text
属性可以获取字符串形式的网页源代码。例如,访问
3.2.1
节请求百度首页示例中
Response
对象的
text
属性获取百度首页源代码,具体代码如下。
# 获取网页源代码
print(response.text)
运行代码,控制台输出了一段 HTML
代码。由于这段代码的格式比较混乱,所以我们在
这里按
HTML
标准格式调整了代码,调整后的结果如下。
<!DOCTYPE html>
<!--STATUS OK-->
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge" />
<meta content="always" name="referrer" />
<link rel="stylesheet" type="text/css" href="https://ss1.bdstatic.com/ 5eN1bjq8A
AUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" />
<title>ç™¾åº¦ä¸ ä¸‹ï
¼Œä½ 就知é "</title>
</head>
<body link="#0000cc">
......(部分省略)
</div>
</div>
</div>
</body>
</html>
对照浏览器中查看的百度首页的源代码可知,标签<title>
中的中文没有正常显示,而是出
现了乱码。这是因为
Requests
库推测的编码格式
ISO-8859-1
与百度首页实际使用的编码格式
UTF-8
不一致。此时需要通过
Response
对象的
encoding
属性将编码格式设置为
UTF-8
。
在 3.2.1
节请求百度首页示例中发送请求的代码之后,增加设置
Response
对象编码格式的
代码,改后的代码如下。
import requests
# 准备 URL
base_url = 'https://www.baidu.com/'
# 根据 URL 构造请求,发送 GET 请求,接收服务器返回的响应信息
response = requests.get(url=base_url)
# 设置响应内容的编码格式
response.encoding = 'utf-8'
# 查看响应内容
print(response.text)再次运行代码,输出如下结果。
<html>
<head></head>
<body link="#0000cc">
<!--STATUS OK-->
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge" />
<meta content="always" name="referrer" />
<link rel="stylesheet" type="text/css" href="https://ss1.bdstatic.com/5eN1bjq8
AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" />
<title>百度一下,你就知道</title>
……(部分省略)
</body>
</html>
从输出结果可以看出,网页源代码中的中文已经能够正常显示了。
2.获取图片
百度首页上除了文字信息之外,还包含一个百度标志(Logo
)图片。若希望获取百度
Logo
的图片,则需要先根据该图片对应的请求
URL
发送请求,再使用
content
属性获取该图片对
应的二进制数据,并将数据写入本地文件中,具体代码如下。
import requests
base_url = 'https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png'
response = requests.get(base_url)
# 获取百度 Logo 图片对应的二进制数据
print(response.content)
# 将二进制数据写入程序所在目录下的 baidu_logo.png 文件中
with open('baidu_logo.png', 'wb') as file:
file.write(response.content)
运行代码,在程序所在的目录下可以看到新创建的文件
baidu_logo.png
,打开该文件后显
示的内容如图
3-2
所示。
















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









