




一、下载CUDA
https://developer.nvidia.com/cuda-12-6-2-download-archive
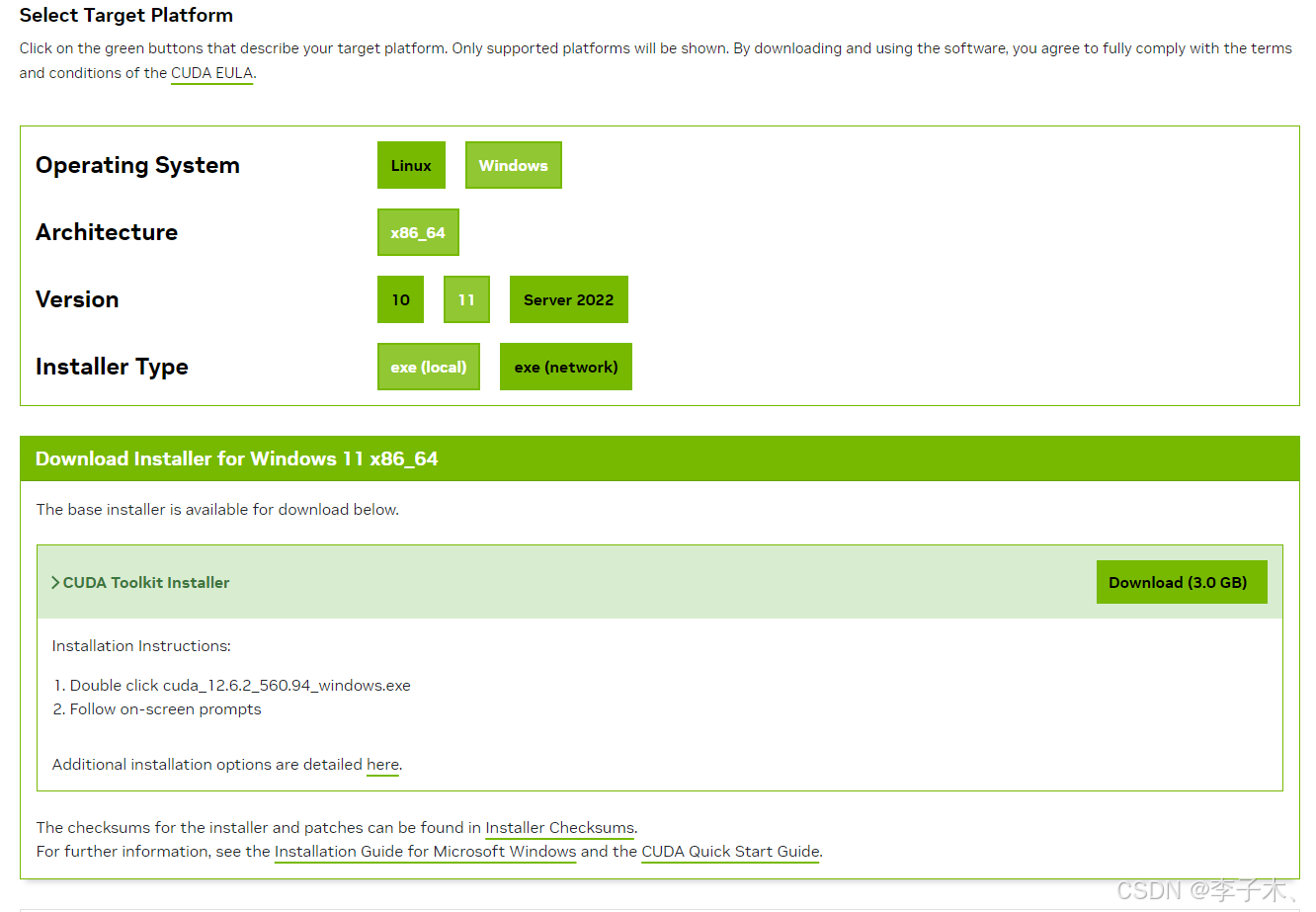
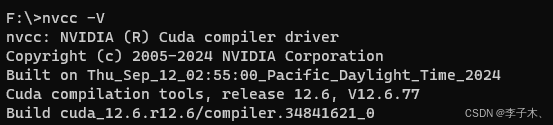
根据提示安装,安装完成后输入 nvcc -V 显示如下即安装成功
二、安装Pytorch
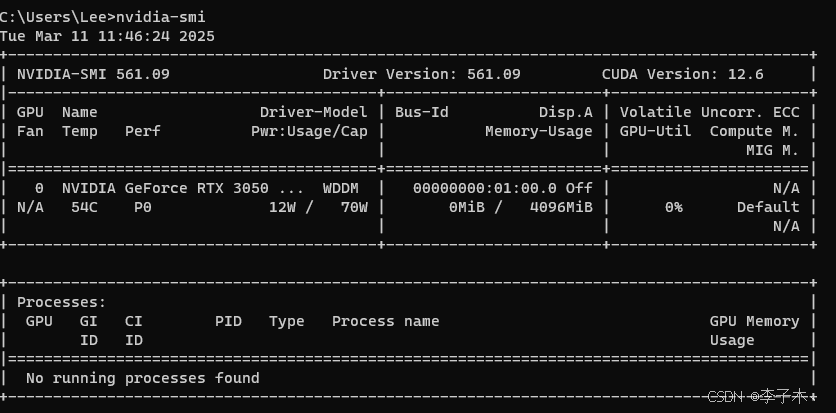
使用nvidia-smi查看CUDA版本
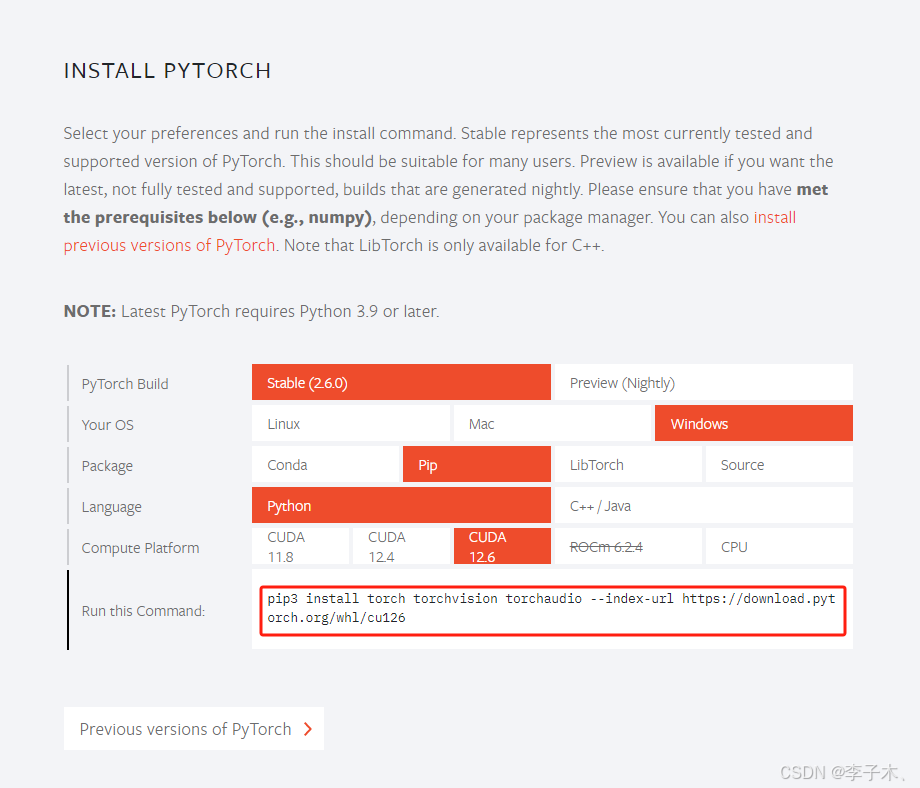
安装Pytorch 选择合适的版本安装
三、安装conda
下载地址:https://www.anaconda.com/download
配置环境变量
检查版本,有输出即安装成功

修改.condarc文件
envs_dirs:
- F:\conda3\envs
pkgs_dirs:
- F:\conda3\pkgs
四、安装LLaMA-Factory
项目地址:https://github.com/hiyouga/LLaMA-Factory
下载
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd ./LLaMA-Factory
创建环境、使用环境
conda create -n llama_factory python=3.10
conda activate llama_factory
安装依赖,运行llamafactory-cli version出现版本信息安装成功
pip install -e ".[torch,metrics]"
llamafactory-cli version
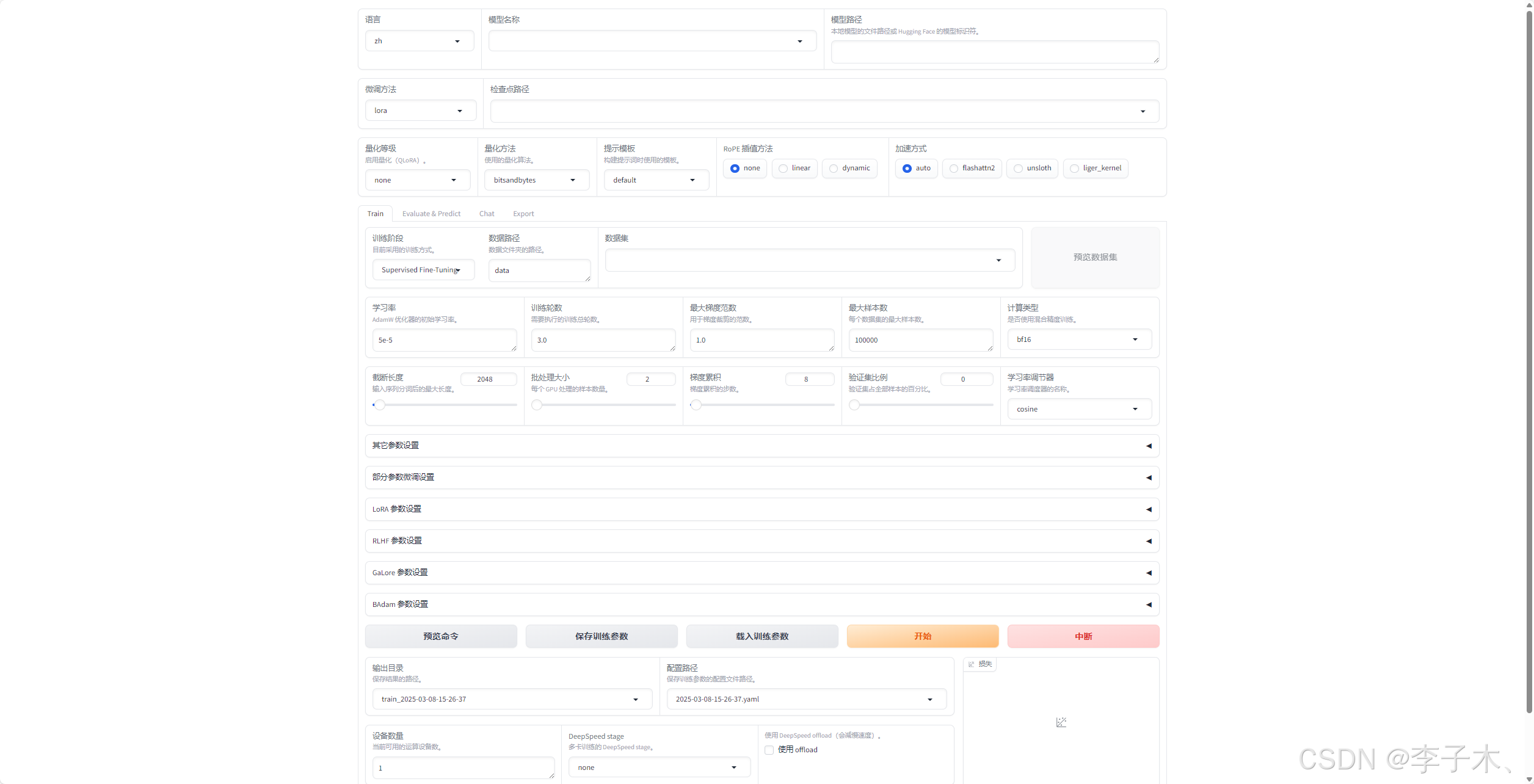
启动项目 llamafactory-cli webui
五、下载模型
下载地址:https://modelscope.cn/models
这里我下载的是 Qwen2.5-1.5B 模型
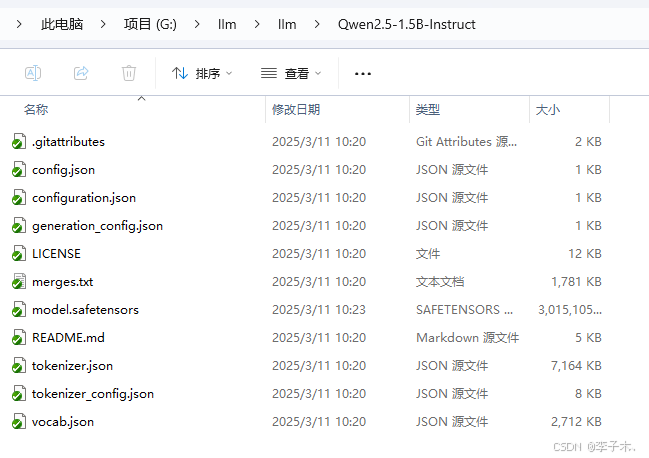
下载好后配置模型名称和路径

六、训练
设置数据路径
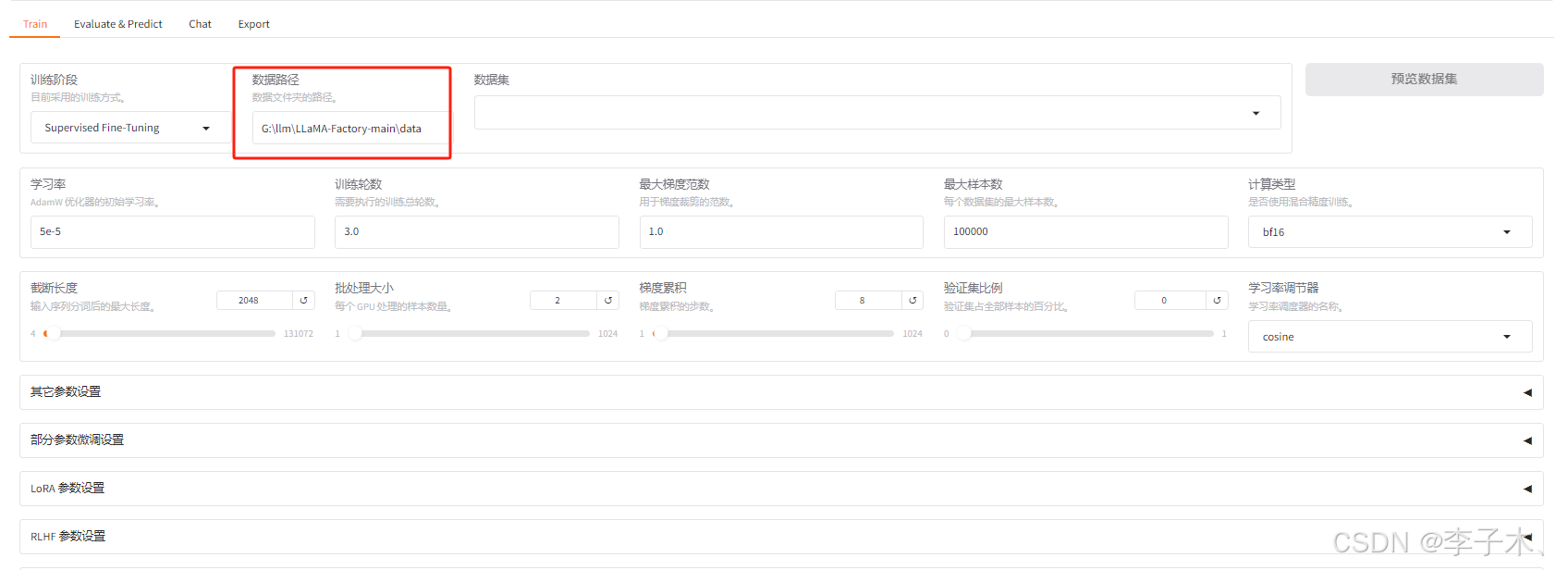
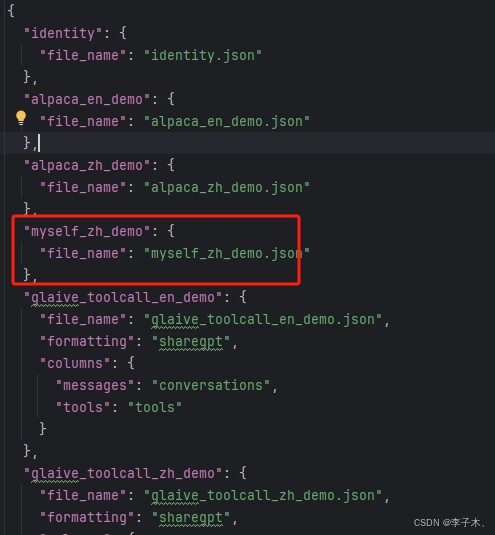
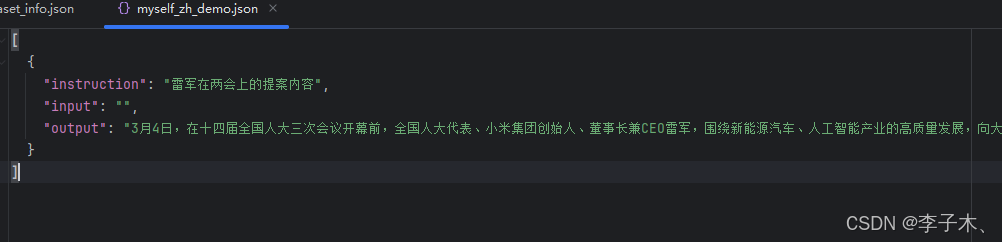
仿照data目录下alpaca_zh_demo.json格式注册自己的数据集,例如:
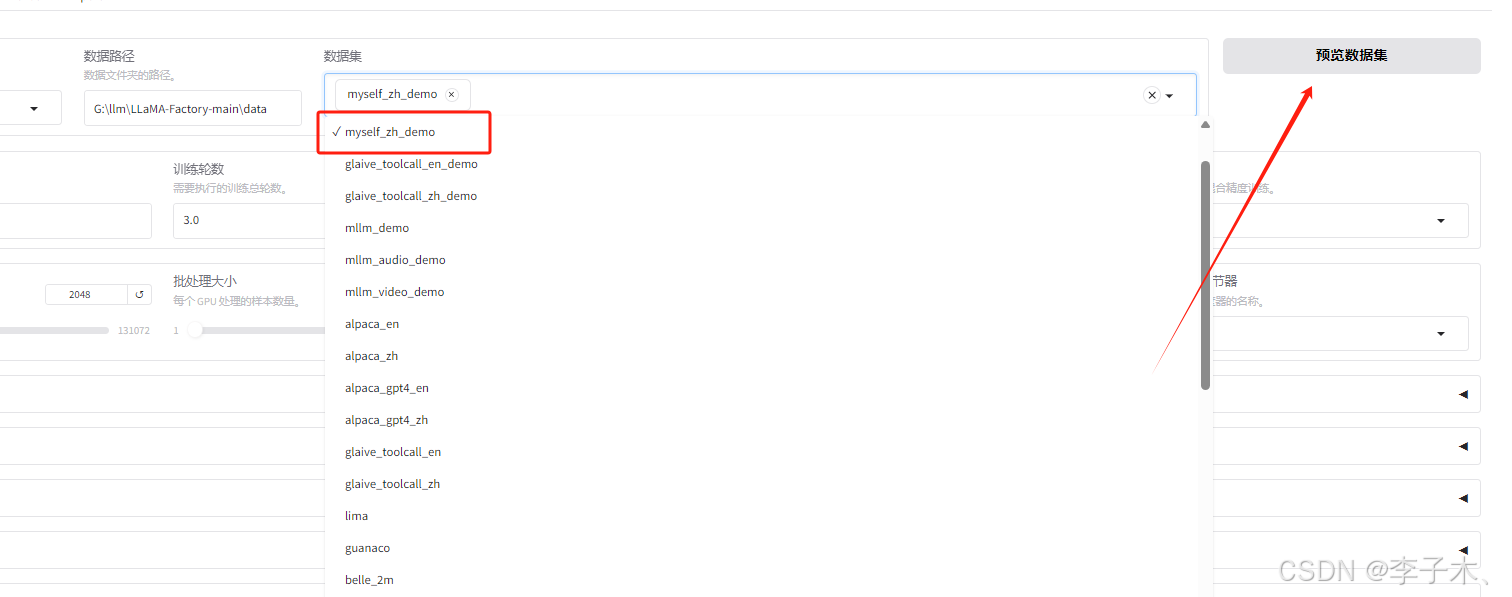
在训练页面选择该数据集,点击开始
训练完成
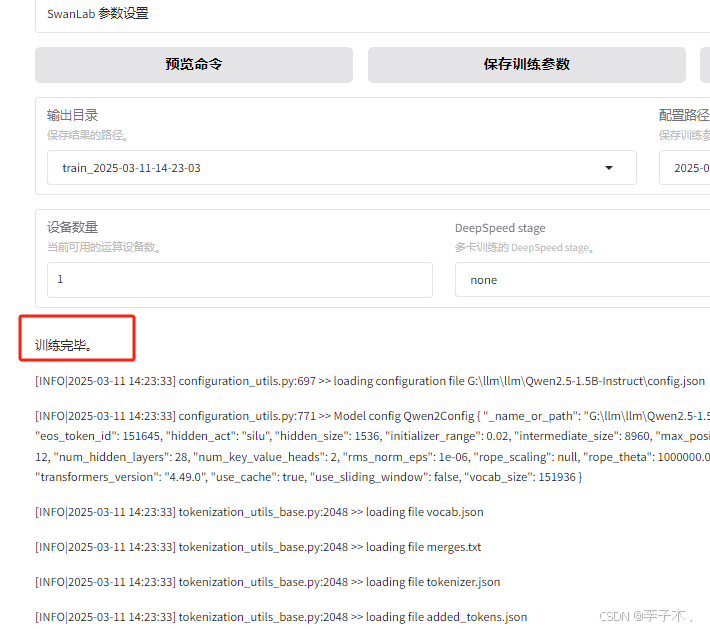
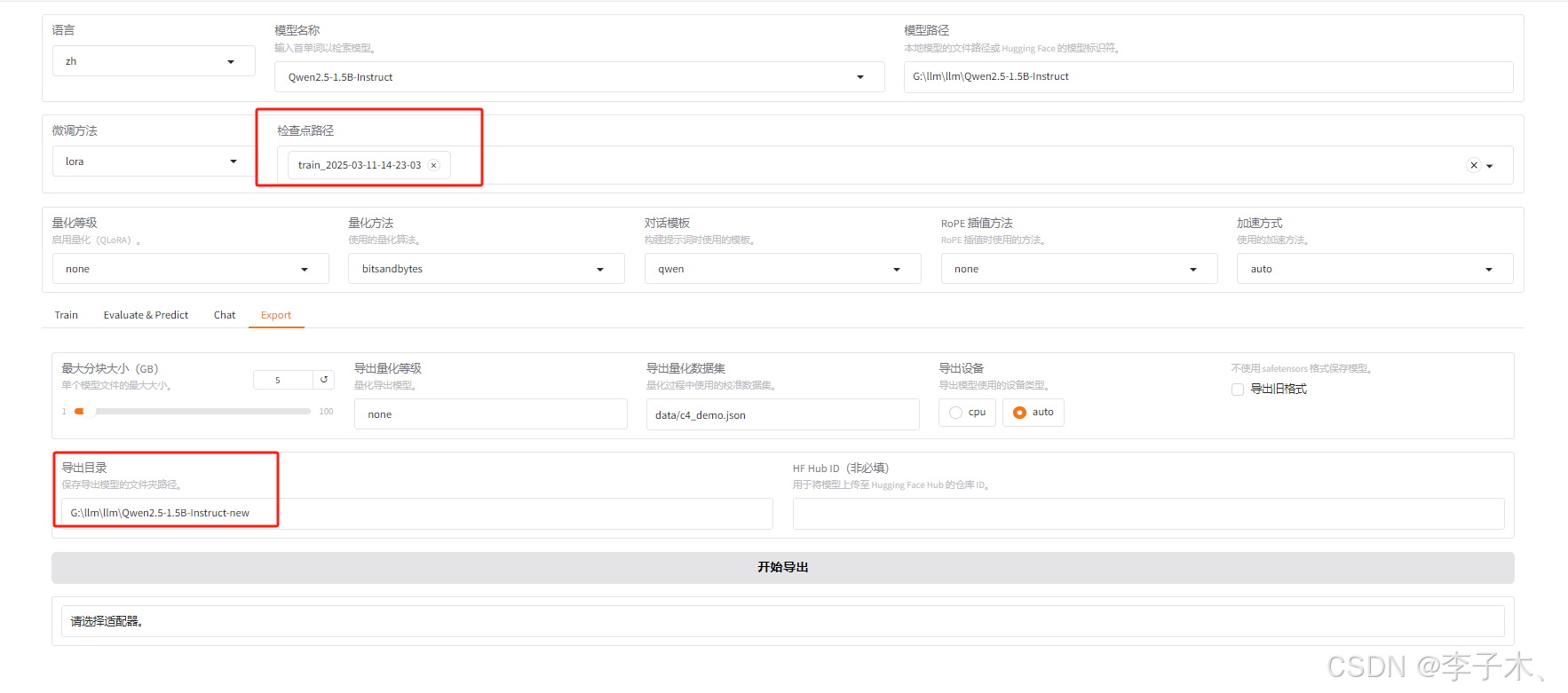
导出
问题
如果出现为检测到CUDA环境,可能是torch是cpu版本,需要先卸载在安装gpu版本
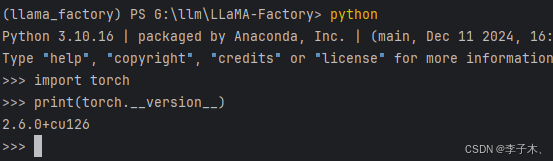
查看版本
import torch
print(torch.__version__)

重新安装
pip uninstall torch
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126


















 2034
2034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











