







终极目标就是运用DDT思想+POM思想+pytest框架来最终实现项目
但是这样虽然松耦合了但是pom思想多维护了一个类,视情况而定,可以不用pom思想
最基本的逻辑就是:
test_user_login调用UserLoginPage文件调用basePage文件
test_category调用categoryPage文件调用basePage文件
文件目录:
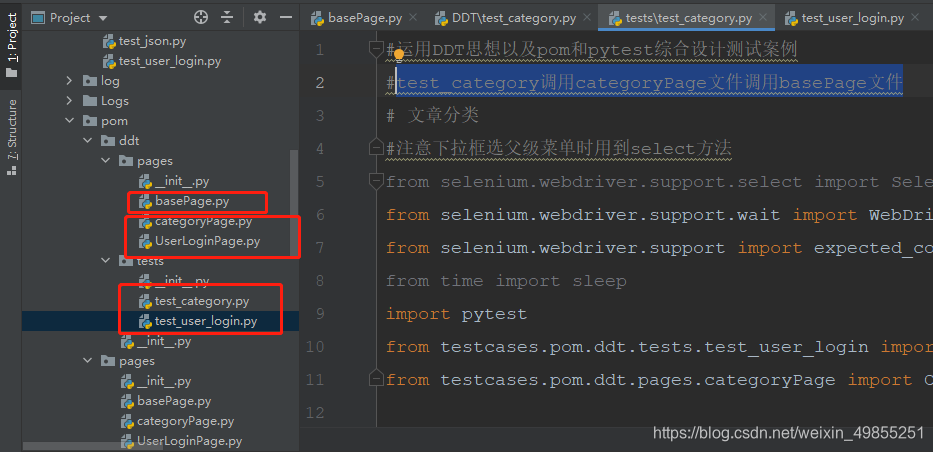
具体例子:
BasePage方法中的代码是:
#这是个基类 封装一些定位方法
class BasePage(object):
def __init__(self, driver):
self.driver = driver #初始化
#找定位元素
def find_element(self, *loc):
return self.driver.find_element(*loc)
#输入值
def type_text(self, text, *loc):
self.find_element(*loc).send_keys(text)
#点击确认
def click(self, *loc):
self.find_element(*loc).click()
#清空
def clear(self, *loc):
self.find_element(*loc).clear()
#获取title标题
def get_title(self):
return self.driver.title
登录的页面设计,调用basepage方法 处理登录
UserLoginPage:
#设计页面对象
from time import sleep
from selenium.webdriver.common.by import By
from testcases.pom.pages.basePage import BasePage
class UserLoginPage(BasePage):
#先找到定位器
username_input = (By.NAME, 'username')
pwd_input = (By.NAME, 'password')
login_btn = (By.CLASS_NAME, 'btn')
#先初始化,用BasePage的init方法
def __init__(self, driver):
BasePage.__init__(self, driver)
#登录入口
def goto_login_page(self):
self.driver.get('http://localhost:8080/jpress/user/login')
self.driver.maximize_window()
#用户名的定位和输入值
def input_username(self, username):
#调用basePage方法
self.clear(*self.username_input)
self.type_text(username, *self.username_input)
#输入密码
def input_pwd(self, pwd):
# 调用basePage方法
self.clear(*self.pwd_input)
self.type_text(pwd, *self.pwd_input)
#点击确定
def click_login_btn(self):
# 调用basePage方法
self.click(*self.login_btn)
sleep(2)
然后测试案例运行,执行用户登录:
#运用DDT思想以及pom和pytest综合设计测试案例
#test_user_login调用UserLoginPage文件调用basePage文件
from time import sleep
import pytest
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from testcases.pom.ddt.pages.UserLoginPage import UserLoginPage
import pyautogui #通过定位坐标来找到元素
class TestUserLogin(object):
login_data = [
('', 'root', '信息提交错误'),
('root', 'root', 'Jpress'),
]
def setup_class(self):
#初始化
self.driver = webdriver.Chrome()
#登录的初始化
self.loginPage = UserLoginPage(self.driver)
#调用登录入口
self.loginPage.goto_login_page()
# 测试用户登录,用户名错误
# 测试用户登录成功
#为了后面的依赖关系
@pytest.mark.dependency(name='admin_login')
@pytest.mark.parametrize('username, pwd, expected', login_data)
def test_user_login(self,username, pwd, expected):
# 输入用户名 #调用UserLoginPage文件中的方法
self.loginPage.input_username(username)
# 输入密码#调用UserLoginPage文件中的方法
self.loginPage.input_pwd(pwd)
# 点击登录#调用UserLoginPage文件中的方法
self.loginPage.click_login_btn()
sleep(3)
# 等待提示框
if username == '':
WebDriverWait(self.driver, 5).until(EC.alert_is_present())
alert = self.driver.switch_to.alert
# 验证(断言) 还是改成se自带的断言
assert alert.text == expected
alert.accept()
else:
# 等待提示框
WebDriverWait(self.driver, 5).until(EC.title_is(expected))
sleep(3)
#验证 因为没有弹窗 所以用到了title断言判断
assert self.driver.title == expected
# @classmethod
# def teardown_class(cls):
# cls.driver.quit()
if __name__ == '__main__':
pytest.main(['-sv','test_user_login.py'])
这样就实现登录了 也实现了解耦合。
下面是文章分类实现,有一个登录依赖关系
先看一下categoryPage文件
文章分类的处理:
#设计页面对象
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
from testcases.pom.pages.basePage import BasePage
class CategoryPage(BasePage):
def __init__(self, login): #先初始化
BasePage.__init__(self, login.driver)
# 文章loc
click_article_loc = (By.XPATH, '//*[@id="article"]/a/span')
# 分类loc
click_category_loc = (By.XPATH, '//*[@id="category"]/a')
# 分类名称loc
category_name_loc = (By.NAME, 'taxonomy.title')
# 父分类loc
parent_category_loc = (By.NAME, 'taxonomy.parent_id')
# slug loc
slug_loc = (By.NAME, 'taxonomy.slug')
# 添加按钮
add_btn_loc = (By.XPATH, '//*[@id="form"]/button')
# 点击文章
def click_article(self):
#调用basepage基类的方法
self.click(*self.click_article_loc)
sleep(1)
# 点击分类
def click_category(self):
# 调用basepage基类的方法
self.click(*self.click_category_loc)
sleep(1)
# 输入分类名称
def input_category_name(self, name):
# 调用basepage基类的方法
self.type_text(name, *self.category_name_loc)
sleep(1)
# 选择父分类
def select_parent_category(self, parent_name):
# 调用basepage基类的方法
parent_category_elem = self.find_element(*self.parent_category_loc)
Select(parent_category_elem).select_by_visible_text(parent_name)
# 输入slug
def input_slug(self, slug):
# 调用basepage基类的方法
self.type_text(slug, *self.slug_loc)
# 点击添加
def click_add_btn(self):
# 调用basepage基类的方法
self.click(*self.add_btn_loc)
然后运行文章分类的测试案例:
test_category文件:
#运用DDT思想以及pom和pytest综合设计测试案例
#test_category调用categoryPage文件调用basePage文件
# 文章分类
#注意下拉框选父级菜单时用到select方法
from selenium.webdriver.support.select import Select
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
import pytest
from testcases.pom.ddt.tests.test_user_login import TestUserLogin
from testcases.pom.ddt.pages.categoryPage import CategoryPage
class TestCategory(object):
#先初始化登录
def setup_class(self):
self.login = TestUserLogin()
self.categoryPage = CategoryPage(self.login)
#成功和失败
category_data = [
('', 'python', 'test', '名称不能为空!'),
('test', 'python', 'test',''),
]
# 测试文章分类成功 因为需要依赖登录
@pytest.mark.dependency(depends=['admin_login'], scope="module")
#参数化
@pytest.mark.parametrize('name,parent,slug,expected', category_data)
def test02_add_category(self,name,parent,slug,expected):
if name == '':
# 点击文章 #调用categoryPage文件的方法
self.categoryPage.click_article()
# 点击分类#调用categoryPage文件的方法
self.categoryPage.click_category()
# 输入分类名称#调用categoryPage文件的方法
self.categoryPage.input_category_name(name)
# 选择父分类#调用categoryPage文件的方法
self.categoryPage.select_parent_category(parent)
# 输入slug#调用categoryPage文件的方法
self.categoryPage.input_slug(slug)
# 点击添加#调用categoryPage文件的方法
self.categoryPage.click_add_btn()
if name=='':
# 因为有弹窗所以需要切换到弹窗上
WebDriverWait(self.login.driver, 7).until(EC.alert_is_present())
alert = self.login.driver.switch_to.alert
# python 的断言
# 获取弹窗上的文字来比较
assert alert.text == expected
alert.accept()
else:
#没有异常就添加成功直接断言成功就好了
assert 1 == 1
if __name__ == '__main__':
# 这里可以跳过登录错误
pytest.main(['test_category.py'])
这样下来整个项目就是跑通了,后期会有分布测试以及持续集成和交付就全部结束了。敬请期待!!!!















 926
926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









