






文章目录
前言
你可能听说过,最近几个月出现了很多人工智能的应用程序。你可能也在用一些这样的应用。
比如ChatPDF和CustomGPT AI这些AI工具,它们可以帮我们省去很多麻烦,我们不用再翻来覆去地看文档,就能找到想要的答案。它们让AI为我们做了很多工作。
那么,开发这些工具的人是怎么做到的呢?其实,他们都用了一个叫LangChain的开源框架。
01 LangChain简介
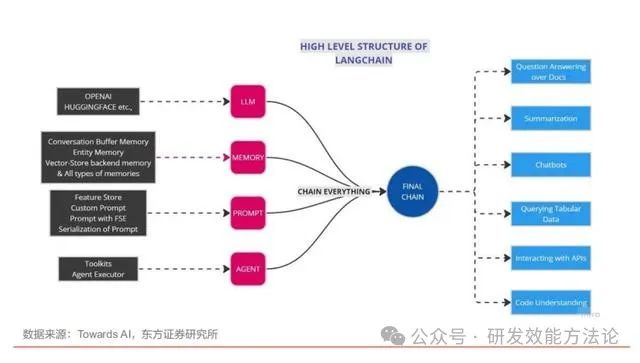
LangChain是一个专门为LLM应用开发设计的框架,旨在简化LLM应用的开发难度。它将LLM的各个组件进行封装和链接,提供了一个统一的开发环境,让开发者可以更加便捷地进行LLM应用的开发。从某种程度上来说,LangChain类似于Java开发中的Spring或SpringBoot框架,为开发者提供了丰富的工具和库,帮助开发者快速构建出功能强大的LLM应用。
- 模块化设计:LangChain框架采用了模块化设计,将LLM应用的各个组件拆分成独立的模块,方便开发者进行模块化的开发和维护。
- 易用性强:LangChain框架提供了丰富的API和文档,让开发者可以更加便捷地进行LLM应用的开发。同时,框架还提供了详细的教程和示例代码,帮助新手快速入门。
- 高性能:LangChain框架在底层进行了优化,保证了LLM应用的高性能。开发者可以在保证性能的前提下,更加专注于业务逻辑的实现。
02 LangChain工作原理
你可能觉得LangChain听起来很复杂,但其实它很容易上手。
简单来说,LangChain就是把大量的数据组合起来,让LLM能够尽可能少地消耗计算力就能轻松地引用。它的工作原理是把一个大的数据源,比如一个50页的PDF文件,分成一块一块的,然后把它们嵌入到一个向量存储(Vector Store)里。
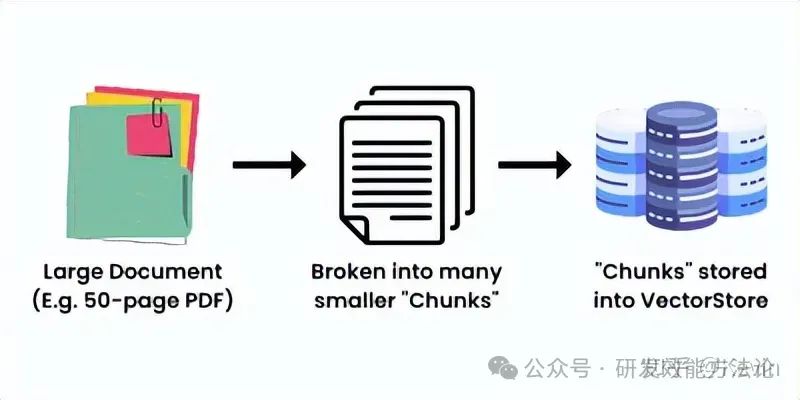
创建向量存储的简单示意图
现在我们有了大文档的向量化表示,我们就可以用它和LLM一起工作,只检索我们需要引用的信息,来创建一个提示-完成(prompt-completion)对。
当我们把一个提示输入到我们新的聊天机器人里,LangChain就会在向量存储里查询相关的信息。你可以把它想象成一个专门为你的文档服务的小型谷歌。一旦找到了相关的信息,我们就用它和提示一起喂给LLM,生成我们的答案。
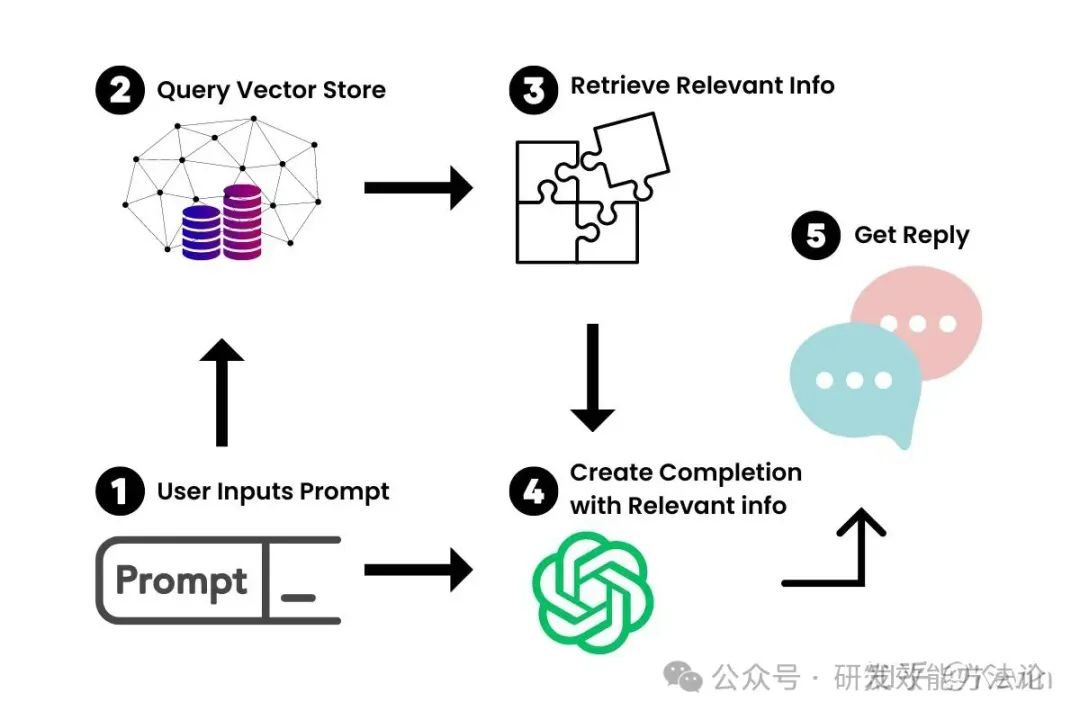
LangChain 如何与 OpenAI 的 LLM 合作
LangChain还可以让你创建一些可以执行动作的应用程序,比如上网、发邮件、完成其他API相关的任务。你可以看看AgentGPT,这是一个很好的例子。
这样的应用程序有很多可能的用途,这里只是我随便想到的一些:
- 个人AI邮件助手
- AI学习伙伴
- AI数据分析
- 定制公司客服聊天机器人
- 社交媒体内容创作助手
这样的案例还有更多。
03、LangChain框架
LangChain 是一个开发由语言模型驱动的应用程序的框架。 LangChain 由前 Robust Intelligence 的机器学习工程师 Chase Harrison 在 22 年 10 月底推出,是一个封装了大量大语言模型(LLM) 应用开发逻辑和工具集成的开源 Python 库,提供了标准的模块化组件,集成了不同的大语言模 型并将其进行整合,并将它们连接到各种外部数据源和 API。
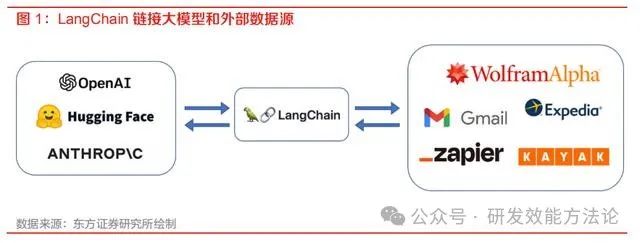
22 年 11 月初,Hacker News 上 “如何入门 AI”的帖子回复中,LangChain 第一次被列进 AI 入门套装; 在 23 年 1 月的 AI Hackathon 决赛中,有大量项目使用了 LangChain。LangChain 在 Github 上的星数迅速破万,成 为 LLM 应用开发者选择中间件时的优先选择。
大模型本身存在应用局限,LangChain 可以加快基于大模型的应用构建速度。 以 ChatGPT 为例, 其训练数据只截至 2021 年底,无法实时获取外部信息,同时通用大模型仅训练了公开的数据知 识,对于一些较为专业的问题大模型会给出胡说八道的答案。目前这些缺陷都可以通过外接 API 的方式来进行改善,比如 OpenAI 官方给出了 Plugin 让 ChatGPT 可以接入互联网,用向量数据库 作为知识库对 prompt 进行处理后再对大模型进行提问等。
LangChain 为开发者们提供了方便,它 封装好了大量的 API 相关逻辑和代码实现,开发者们可以直接调用,大大加快了构建一个应用的 速度。有了 LangChain,做一个基于公司内部文档的问答机器人通常只需要两天,而直接 fork 别 人基于 LangChain 的代码构建个人的 Notion 问答机器人则只需要几个小时。
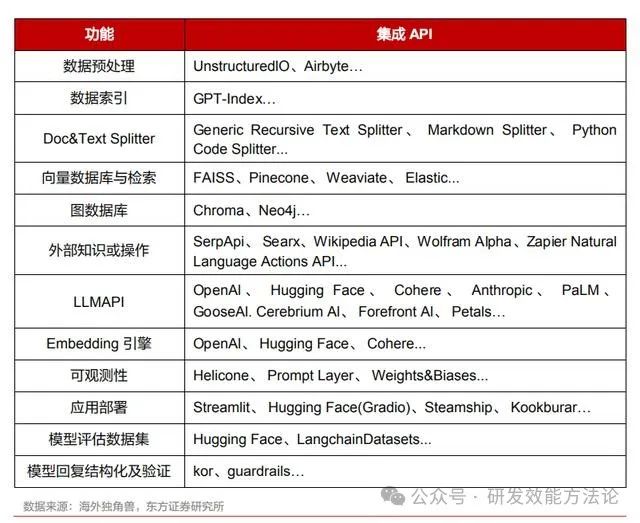
针对大模型应用上的不足,LangChain 提供模块化组件进行优化。针对通用大模型难以获取外部 信息、无法保存上下文记忆等不足,LangChain 提供了多个组件模块:
-
Model:Model 模块主要包含了大语言模型(LLM),借助 LangChain,与 LLM 的交互将变 得更加便捷,LangChain 提供的接口和功能有助于将 LLM 的强大能力轻松集成到工作应用 程序中。LangChain 还提供异步支持,能够满足同时并发调用多个 LLM 的场景,最大限度 地提高资源利用率。LangChain 还支持编写自定义的 LLM 包装器,而不仅限于 LangChain 所支持的模型。
-
Prompt:prompt 是向 LLM 提供的输入,LangChain 提供了完备的管理和优化 prompt 的功 能。最基础的功能是 prompt template(提示模板),模板指的是我们希望获得答案的具体 格式或蓝图。LangChain 支持通过提示模板单独定义 prompt 的输入输出格式,其输出解析 器可以将 LLM 的输出解析为所需要的格式。
-
Chain:Chain(链)提供了将各种组件合并成一个统一应用程序的方式,通过链式结构可 以实现多个模型的序列调用,也能集成提示模板对用户输入进行格式化。LangChain 提供了 多种基础链式结构,包含简单的单向序列 SimpleSequentialChain、可以让 LLM 查询 API 的 API Chain、图谱检索查询的 GraphQAChain 等。通过将多个 Chain 与其他组件集成,可以 生成更复杂的链式结构。
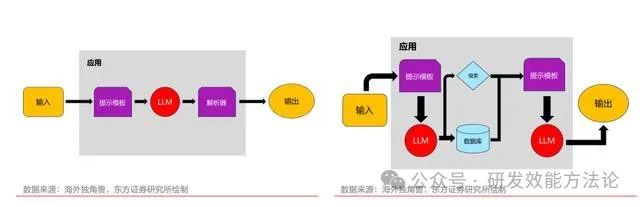
- Agent:Agent(代理)是 LangChain 最强大的功能模块之一。Agent 将 LLM 作为推理引擎, 只要给它提供文本或其他信息源,它就会利用互联网上学习到的背景知识或你提供的新信息, 来回答问题、推理内容或决定下一步的操作。Agent 可以访问多种工具比如搜索引擎、数据 库等,根据用户的输入,Agent 能决定是否调用这些工具,并确定调用时的输入。在得到工 具返回的结果后,Agent 会判断下一步应该采取的步骤,直到 Agent 决定不再需要使用工具, 然后直接回应用户。
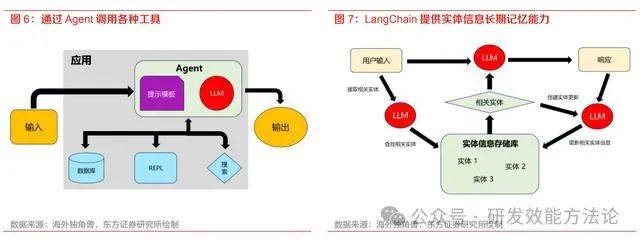
- Memory:一般在与 LLM 的交互过程中,模型是无法记住之前对话的历史消息的,无法实现 跨越上下文的流畅对话应用。ChatGPT 提供了短期的 Memory(记忆),在每个交互 session 的问答里 ChatGPT 都能记住这个对话的上文(通过每次请求时把之前的问答 token 传给 OpenAI 来实现),但在新的交互 session 里 ChatGPT 就没有之前 session 的记忆。LangChain 提供了多种不同的记忆形式,开发者可以选择存储完整记忆、仅保留最后几轮对 话记忆或是限制存储的 token 数等。除此之外,开发者也可以选择将对话历史存储在向量数 据库中,或是将某些特定实体的信息记忆起来。
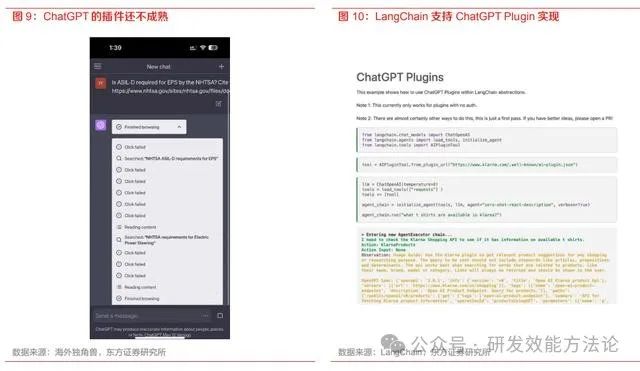
ChatGPT Plugin 和 LangChain 并非竞争关系,LangChain 已支持直接调用 ChatGPT Plugin。 随着 ChatGPT 公布其 Plugin 插件生态,部分开发者认为 LangChain 的价值会被插件直接取代, 但 LangChain 和插件并非竞争关系,LangChain 在插件推出后两天就更新了在 LangChain 抽象下 的 Plugin 实现。
目前 ChatGPT 的插件生态仍处于非常早期阶段,插件数量不多,用户数量也只 有几十万量级,插件本身的 UI 也非常粗糙,难以拥有统一的产品体验。LangChain 在复杂的 2B 应用场景中仍具有显著的价值,在底层大模型和上层应用之间提供一层对业务复杂逻辑的抽象, 满足复杂业务快速部署的需求。例如Langchain的Agent和Memory两个功能模块,现有的plugin 不具备这样的能力。
一站式框架或成为未来大模型应用开发和部署的首选
04、LangChain应用实战
1、AI应用开发步骤
环境搭建:首先,开发者需要安装LangChain框架所需的环境,包括Python、PyTorch等依赖库。然后,按照官方文档的指引,进行框架的安装和配置。
- 模型选择:根据具体的应用场景,开发者需要选择合适的LLM模型。LangChain框架支持多种主流LLM模型,如GPT、BERT等。开发者可以根据自己的需求选择合适的模型进行开发。
- 模型训练与调优:在选择了合适的模型后,开发者需要进行模型的训练和调优。LangChain框架提供了丰富的工具和库,帮助开发者进行模型的训练、评估和调优。通过不断地调整模型参数和策略,开发者可以得到更加优秀的LLM模型。
- 应用开发:在模型训练和调优完成后,开发者可以开始进行LLM应用的开发。LangChain框架提供了丰富的API和工具,让开发者可以更加便捷地实现各种LLM应用的功能。同时,框架还提供了详细的教程和示例代码,帮助新手快速入门。
2、LangChain应用实战
一个LangChain应用程序由5个主要部分组成:
- 模型(LLM包装器)
- 提示
- 链
- 嵌入和向量存储
- 代理
我会给你分别来介绍每个部分,让你能够对LangChain的工作原理有一个高层次的理解。接下来,你应该能够运用这些概念,开始设计你自己的用例和创建你自己的应用程序。
接下来我会用Rabbitmetrics(Github)的一些简短的代码片段来进行介绍。他提供了有关此主题的精彩教程。这些代码片段应该能让你准备好使用LangChain。
首先,让我们设置我们的环境。你可以用pip安装3个你需要的库:
pip install -r requirements.txt
python-dotenv==1.0.0
langchain==0.0.137
pinecone-client==2.2.1
Pinecone是我们将要和LangChain一起使用的向量存储(Vector Store)。在这里,你要把你的OpenAI、Pinecone环境和Pinecone API的API密钥存储到你的环境配置文件里。你可以在它们各自的网站上找到这些信息。然后我们就用下面的代码来加载那个环境文件:
现在,我们准备好开始了!
# 加载环境变量
from dotenv import loaddotenv,finddotenv
loaddotenv(finddotenv())
2.1、模型(LLM包装器)
为了和我们的LLM交互,我们要实例化一个OpenAI的GPT模型的包装器。在这里,我们要用OpenAI的GPT-3.5-turbo,因为它是最划算的。但是如果你有权限,你可以随意使用更强大的GPT4。
要导入这些,我们可以用下面的代码:
# 为了查询聊天模型GPT-3.5-turbo或GPT-4,导入聊天消息和ChatOpenAI的模式(schema)。
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model_name="gpt-3.5-turbo",temperature=0.3)
messages = [
SystemMessage(content="你是一个专业的数据科学家"),
HumanMessage(content="写一个Python脚本,用模拟数据训练一个神经网络")
]
response=chat(messages)
print(response.content,end='\n')
实际上,SystemMessage为GPT-3.5-turbo模块提供了每个提示-完成对的上下文信息。HumanMessage是指您在ChatGPT界面中输入的内容,也就是您的提示。
但是对于一个自定义知识的聊天机器人,我们通常会将提示中重复的部分抽象出来。例如,如果我要创建一个推特生成器应用程序,我不想一直输入“给我写一条关于…的推特”。
因此,让我们来看看如何使用提示模板(PromptTemplates)来将这些内容抽象出来。
2.2、提示
LangChain提供了PromptTemplates,允许你可以根据用户输入动态地更改提示,类似于正则表达式(regex)的用法。
# 导入提示并定义PromptTemplate
from langchain import PromptTemplate
template = """
您是一位专业的数据科学家,擅长构建深度学习模型。
用几行话解释{concept}的概念
"""
prompt = PromptTemplate(
input_variables=["concept"],
template=template,
)
# 用PromptTemplate运行LLM
llm(prompt.format(concept="autoencoder"))
llm(prompt.format(concept="regularization"))
你可以用不同的方式来改变这些提示模板,让它们适合你的应用场景。如果你熟练使用ChatGPT,这应该对你来说很简单。
2.3、链
链可以让你在简单的提示模板上面构建功能。本质上,链就像复合函数,让你可以把你的提示模板和LLM结合起来。
使用之前的包装器和提示模板,我们可以用一个单一的链来运行相同的提示,它接受一个提示模板,并把它和一个LLM组合起来:
# 导入LLMChain并定义一个链,用语言模型和提示作为参数。
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# 只指定输入变量来运行链。
print(chain.run("autoencoder"))
除此之外,顾名思义,我们还可以把这些链连起来,创建更大的组合。
比如,我可以把一个链的结果传递给另一个链。在这个代码片段里,Rabbitmetrics把第一个链的完成结果传递给第二个链,让它用500字向一个五岁的孩子解释。
你可以把这些链组合成一个更大的链,然后运行它。
# 定义一个第二个提示
second_prompt = PromptTemplate(
input_variables=["ml_concept"],
template="把{ml_concept}的概念描述转换成用500字向我解释,就像我是一个五岁的孩子一样",
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# 用上面的两个链定义一个顺序链:第二个链把第一个链的输出作为输入
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)
# 只指定第一个链的输入变量来运行链。
explanation = overall_chain.run("autoencoder")
print(explanation)
有了链,你可以创建很多功能,这就是LangChain功能强大的原因。但是它真正发挥作用的地方是和前面提到的向量存储一起使用。接下来我们开始介绍一下这个部分。
2.4、嵌入和向量存储
这里我们将结合LangChain进行自定义数据存储。如前所述,嵌入和向量存储的思想是把大数据分成小块,并存储起来。
LangChain有一个文本分割函数来做这个:
# 导入分割文本的工具,并把上面给出的解释分成文档块
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 100,
chunk_overlap = 0,
)
texts = text_splitter.create_documents([explanation])
分割文本需要两个参数:每个块有多大(chunk_size)和每个块有多少重叠(chunk_overlap)。让每个块之间有重叠是很重要的,可以帮助识别相关的相邻块。
每个块都可以这样获取:
texts[0].page_content
在我们有了这些块之后,我们需要把它们变成嵌入。这样向量存储就能在查询时找到并返回每个块。我们将使用OpenAI的嵌入模型来做这个。
# 导入并实例化 OpenAI embeddings
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model_name="ada")
# 用嵌入把第一个文本块变成一个向量
query_result = embeddings.embed_query(texts[0].page_content)
print(query_result)
最后,我们需要有一个地方来存储这些向量化的嵌入。如前所述,我们将使用Pinecone来做这个。使用之前环境文件里的API密钥,我们可以初始化Pinecone来存储我们的嵌入。
# 导入并初始化Pinecone客户端
import os
import pinecone
from langchain.vectorstores import Pinecone
pinecone.init(
api_key=os.getenv('PINECONE_API_KEY'),
environment=os.getenv('PINECONE_ENV')
)
# 上传向量到Pinecone
index_name = "langchain-quickstart"
search = Pinecone.from_documents(texts, embeddings, index_name=index_name)
# 做一个简单的向量相似度搜索
query = "What is magical about an autoencoder?"
result = search.similarity_search(query)
print(result)
现在我们能够从我们的Pinecone向量存储里查询相关的信息了!剩下要做的就是把我们学到的东西结合起来,创建我们特定的用例,给我们一个专门的AI“代理”。
2.5、代理
一个智能代理就是一个能够自主行动的AI,它可以根据输入,依次完成一系列的任务,直到达成最终的目标。这就意味着我们的AI可以利用其他的API,来实现一些功能,比如发送邮件或做数学题。如果我们再加上我们的LLM+提示链,我们就可以打造出一个适合我们需求的AI应用程序。
这部分的原理可能有点复杂,所以让我们来看一个简单的例子,来演示如何用LangChain中的一个Python代理来解决一个简单的数学问题。这个代理是通过调用我们的LLM来执行Python代码,并用NumPy来求解方程的根:
# 导入Python REPL工具并实例化Python代理
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
from langchain.python import PythonREPL
from langchain.llms.openai import OpenAI
agent_executor = create_python_agent(
llm=OpenAI(temperature=0, max_tokens=1000),
tool=PythonREPLTool(),
verbose=True
)
# 执行Python代理
agent_executor.run("找到二次函数3 * x ** 2 + 2 * x - 1的根(零点)。")
一个定制知识的聊天机器人,其实就是一个能够把问题和动作串起来的智能代理。它会把问题发送给向量化存储,然后把得到的结果和原来的问题结合起来,给出答案
05、和其他四个框架的对比
以下是四种框架(LangChain, LlamaIndex, Haystack, Hugging Face)的详细解释,包括它们的优势、劣势和理想用例,以帮助您选择适合您的生成式AI应用的正确框架:
| 框架 | 优势 | 劣势 | 理想用例 |
|---|---|---|---|
| LangChain | - 灵活性和扩展性高 - 可扩展性强 - 开源 | - 学习曲线较陡 - 用户界面不够友好 | - 研究项目 - 高性能应用 |
| LlamaIndex | - 搜索和检索效率高 - 易用性好 - 与Hugging Face无缝集成 - 开源 | - 功能有限 - 黑箱性质 | - 信息检索 - 个性化内容生成 |
| Haystack | - 全面的NLP流水线 - 灵活性和定制性 - 开源和社区驱动 | - 设置更复杂 - 资源密集型 | - 信息提取 - 问题回答 - 情感分析 |
| Hugging Face | - 丰富的模型库 - 用户友好平台 - 协作开发 - 开源 | - 功能有限 - 成本 | - 模型训练和微调 - 模型评估和比较 - 协作研究 |
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 5775
5775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









