







第十三讲循环神经网络(高级篇)笔记和源码
B站 刘二大人 教学视频 传送门: 循环神经网络(高级篇)
1、先丢出问题,实现一个RNN循环神经网络的分类器
将对应的名字分国家

2、 我们的模型是这样的
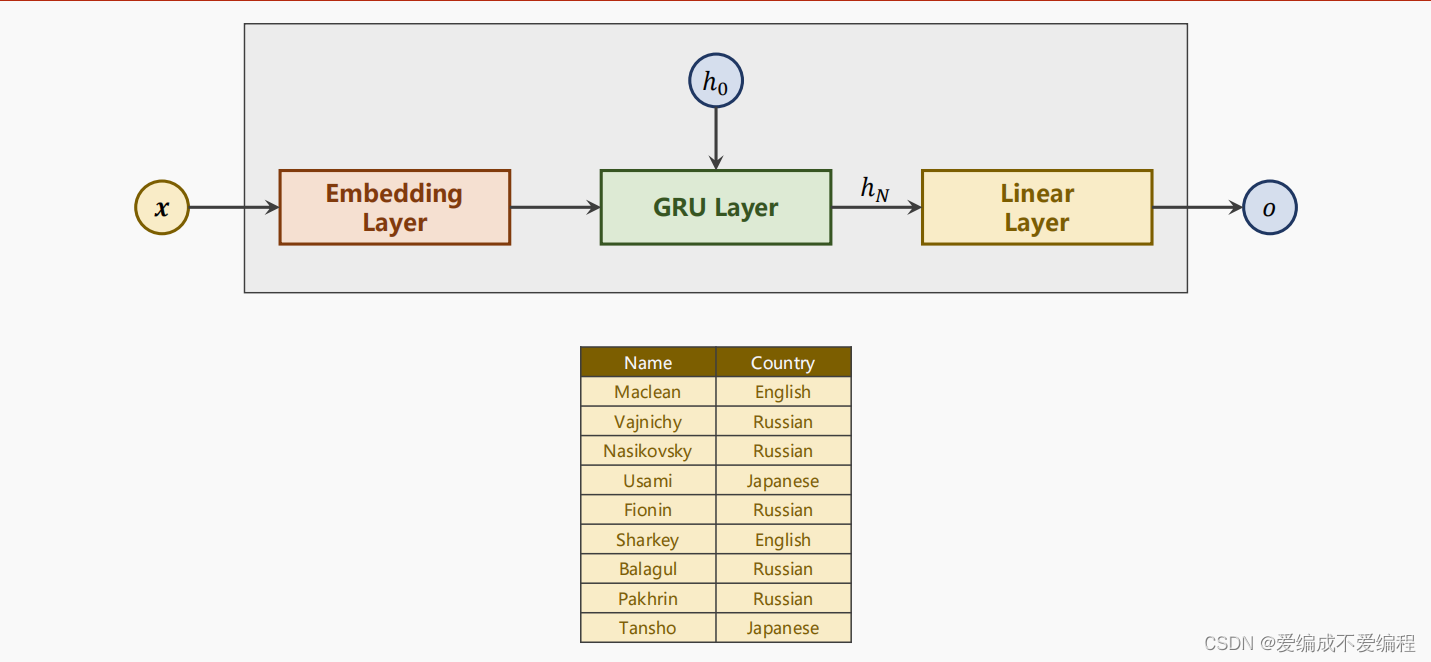
3、模型的使用方法
第一个是字符数量(也就是说英文有多少个元素),第二个参数是隐层数量(GRU输出得隐层的维度),第三个参数是一共要分多少类,第四个就是使用几层GRU
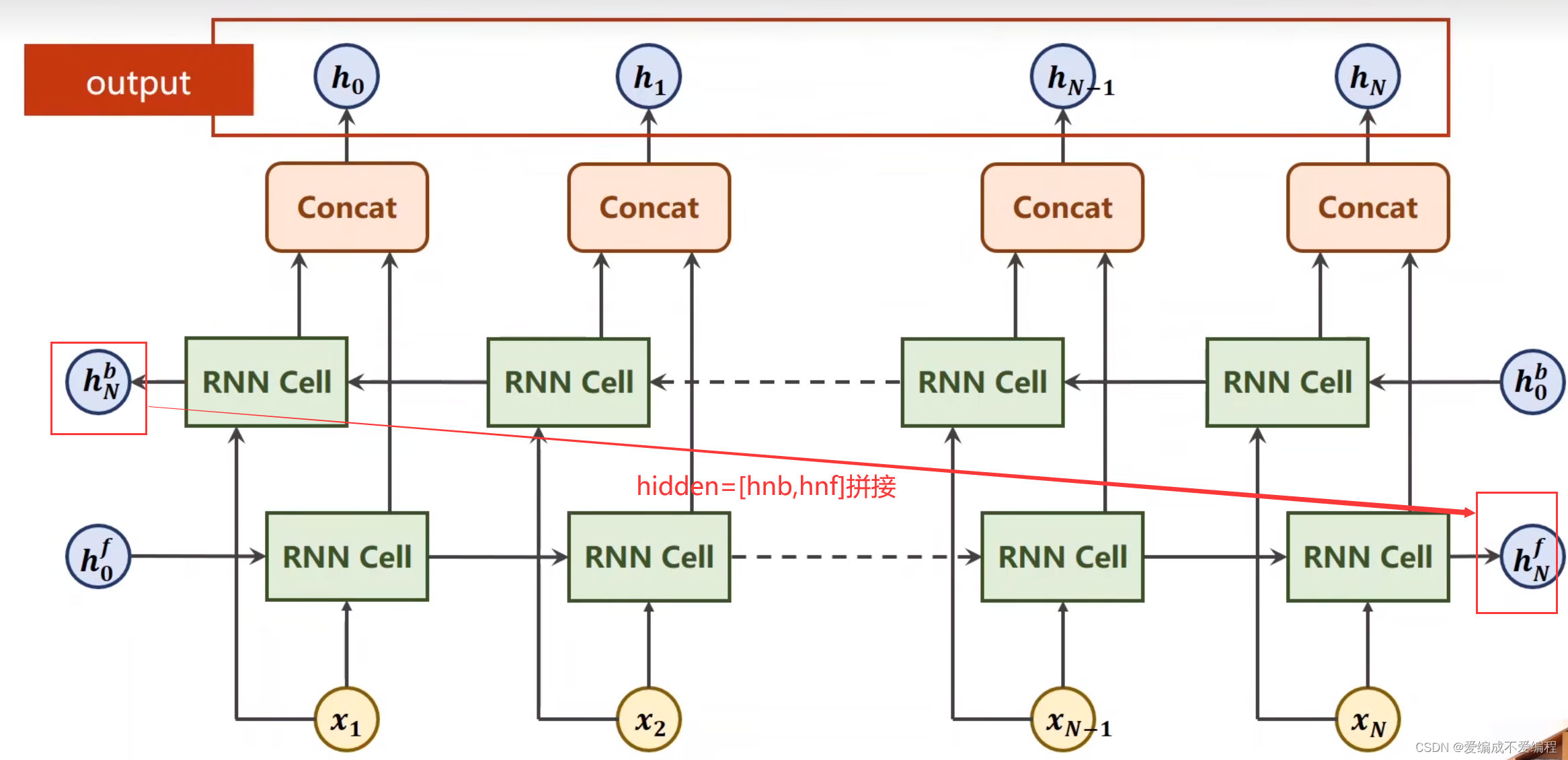
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)4、双向神经网络
badirectional=2为双向,为1为单向
正向反向输出结果 拼接
二、实现分类过程
1、准备数据
①将要预测的名字用ASCLL码做一个字典
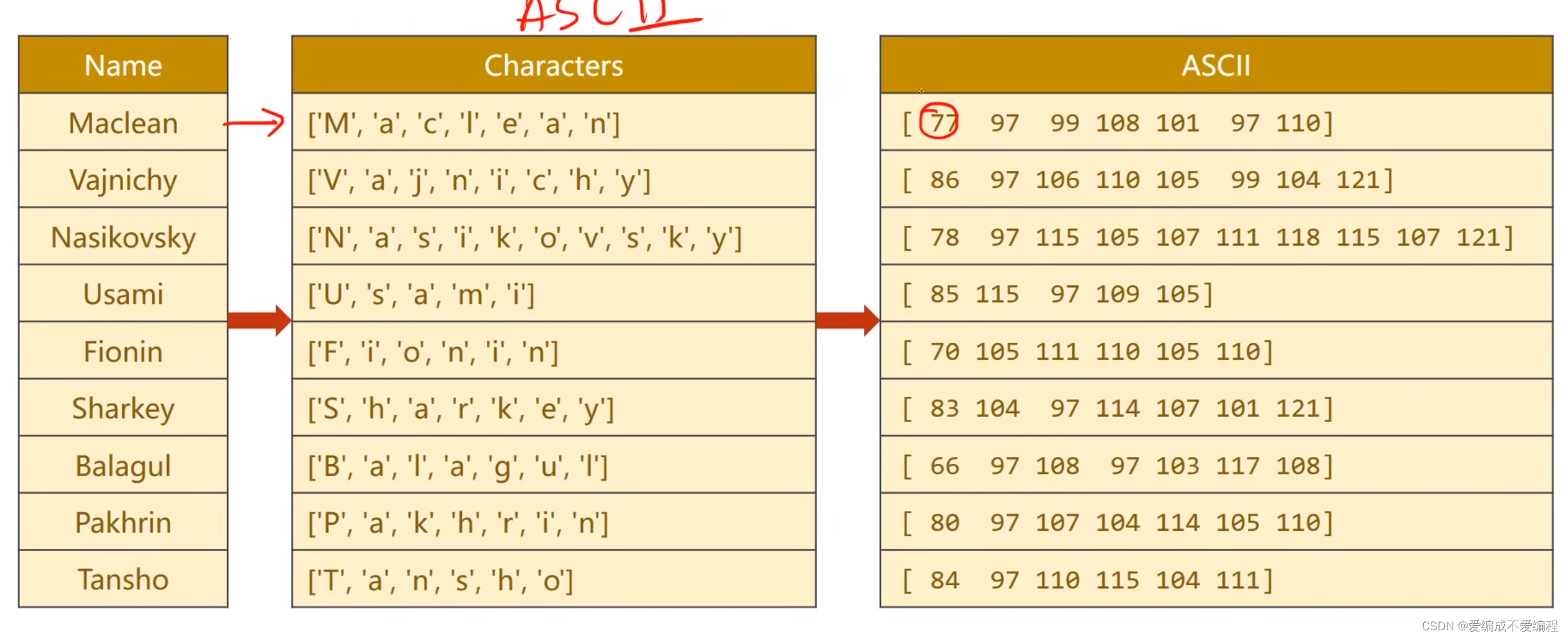
②使用padding把字典补满 必须一样长,填充0

③将国家数据集做一个索引如图所示:

2、建立模型与实现代码
模型:通过第二步模型,再加上步骤4双向神经网络形成
代码源码如下:
说明:我使用的GPU,若要使用CPU跑的话,请将第二十行代码True改为False,然后删掉156行和179行后面的.cpu,进行这三个操作过后,就能使用CPU跑此代码了。
import csv
import gzip
import math
import time
import numpy as np
import torch
import torch.nn
from torch.nn.utils.rnn import pack_padded_sequence
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
hidden_size=100
batch_size=256
n_layers=2
n_epochs=100
n_chars=128 #AscII一共有128个字符
use_GPU=True #没有GPU删除GPU
class NameDataset(Dataset):
def __init__(self,is_train_set=True):
filename='data/names_train.csv.gz' if is_train_set else 'data/names_test.csv.gz'
#rt表示只读模式打开文件并将文件内容解析为文本
with gzip.open(filename,'rt') as f:
reader=csv.reader(f)
#将reader行读出
rows=list(reader)
#(name,language)元组
self.names=[row[0] for row in rows]
self.len=len(self.names)
self.countries=[row[1] for row in rows]
#将country转换为词典
self.country_list=list(sorted(set(self.countries)))
self.country_dict=self.getCountryDict()
self.country_num=len(self.country_list)
def __getitem__(self, index):
return self.names[index],self.country_dict[self.countries[index]]
#返回样本数量
def __len__(self):
return self.len
#返回一个key为国家名,vlaue为索引的字典
def getCountryDict(self):
country_dict=dict()
for idx,country_name in enumerate(self.country_list,0):
country_dict[country_name]=idx
return country_dict
#用索引返回字符串
def idx2country(self,index):
return self.country_list[index]
#返回国家数量
def getCountriesNum(self):
return self.country_num
#实例化数据集
trainset=NameDataset(is_train_set=True)
trainloader=DataLoader(trainset,batch_size=batch_size,shuffle=True)
testset=NameDataset(is_train_set=False)
testloader=DataLoader(testset,batch_size=batch_size,shuffle=False)
#18个国家即18个类
n_country=trainset.getCountriesNum()
#设计模型
class RNNClassifier(torch.nn.Module):
def __init__(self,input_size,hidden_size,output_size,n_layers=1,bidirectional=True):
super(RNNClassifier,self).__init__()
self.hidden_size=hidden_size
self.n_layers=n_layers
#双向2单向1,双向神经网络
self.n_directions=2 if bidirectional else 1
#input of Embedding layer with shape:(seqlen,batchsize)
#the output of Embedding layer with shape:(sqlen,batchsize,hiddensize)
self.embedding=torch.nn.Embedding(input_size,hidden_size)
#GRU(输入维度,输出维度,层,单向还是双向,)
self.gru=torch.nn.GRU(hidden_size,hidden_size,n_layers,bidirectional=bidirectional)
self.fc=torch.nn.Linear(hidden_size*self.n_directions,output_size)
def _init_hidden(self,batch_size):
#初始化隐层
hidden_size=torch.zeros(self.n_layers*self.n_directions,batch_size,self.hidden_size)
return create_tensor(hidden_size)
def forward(self,input,seq_lengths):
#input shape:bxs=sxb
#专职:变成(seq.len,batchsize)
input =input.t()
#256一次训练的样本数,为256个名字 即batchsize
batch_size=input.size(1)
hidden=self._init_hidden(batch_size)
# 1、嵌入层处理,input:(seq_len,batch_size) -> embedding:(seq_len,batch_size,embedding_size)
embedding=self.embedding(input)
#pack then up
gru_input=pack_padded_sequence(embedding, seq_lengths)
output,hidden=self.gru(gru_input,hidden)
if self.n_directions==2:
#拼接
hidden_cat=torch.cat([hidden[-1],hidden[-2]],dim=1)
else:
hidden_cat=hidden[-1]
fc_output=self.fc(hidden_cat)
return fc_output
# 下面该函数属于数据准备阶段的延续部分,因为神经网络只能处理数字,不能处理字符串,所以还需要把姓名转换成数字
def make_tensors(names, countries):
# 传入的names是一个列表,每个元素是一个姓名字符串,countries也是一个列表,每个元素是一个整数
sequences_and_lengths = [name2list(name) for name in
names] # 返回的是一个列表,每个元素是一个元组,元组的第一个元素是姓名字符串转换成的数字列表,第二个元素是姓名字符串的长度
name_sequences = [sl[0] for sl in sequences_and_lengths] # 返回的是一个列表,每个元素是姓名字符串转换成的数字列表
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths]) # 返回的是一个列表,每个元素是姓名字符串的长度
countries = countries.long() # PyTorch 中,张量的默认数据类型是浮点型 (float),这里转换成整型,可以避免浮点数比较时的精度误差,从而提高模型的训练效果
# make tensor of name, (Batch_size,Seq_len) 实现填充0的功能
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths)):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
# sort by length to use pack_padded_sequence
# perm_idx是排序后的数据在原数据中的索引,seq_tensor是排序后的数据,seq_lengths是排序后的数据的长度,countries是排序后的国家
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx]
return create_tensor(seq_tensor), create_tensor(seq_lengths), create_tensor(countries)
# 把名字转换成ASCII码,返回ASCII码值列表和名字的长度
def name2list(name):
arr = [ord(c) for c in name]
return arr, len(arr)
# 是否把数据放到GPU上
def create_tensor(tensor):
if use_GPU:
device = torch.device('cuda:0')
tensor = tensor.to(device)
return tensor
# 训练模型
def trainModel():
total_loss = 0
for i, (names, countries) in enumerate(trainloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths.cpu())#如果没有GPU删除.cpu
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if i % 10 == 0:
print(f'[{timeSince(start)}] Epoch {epoch} ', end='') # end=''表示不换行
print(f'[{i * len(inputs)}/{len(trainset)}] ', end='')
print(f'loss={total_loss / (i * len(inputs))}') # 打印每个样本的平均损失
return total_loss # 返回的是所有样本的损失,我们并没有用上它
# 测试模型
def testModel():
correct = 0
total = len(testset)
print('evaluating trained model ...')
with torch.no_grad():
for i, (names, countries) in enumerate(testloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths.cpu())
pred = output.max(dim=1, keepdim=True)[1] # 返回每一行中最大值的那个元素的索引,且keepdim=True,表示保持输出的二维特性
correct += pred.eq(target.view_as(pred)).sum().item() # 计算正确的个数
percent = '%.2f' % (100 * correct / total)
print(f'Test set: Accuracy {correct}/{total} {percent}%')
return correct / total # 返回的是准确率,0.几几的格式,用来画图
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60) # math.floor()向下取整
s -= m * 60
return '%dmin %ds' % (m, s) # 多少分钟多少秒
if __name__ == '__main__':
classifier = RNNClassifier(n_chars, hidden_size, n_country, n_layers)
if use_GPU:
device = torch.device('cuda:0')
classifier.to(device)
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer =torch.optim.Adam(classifier.parameters(), lr=0.001)
start = time.time()
print('Training for %d epochs...' % n_epochs)
acc_list = []
# 在每个epoch中,训练完一次就测试一次
for epoch in range(1, n_epochs + 1):
# Train cycle
trainModel()
acc = testModel()
acc_list.append(acc)
# 绘制在测试集上的准确率
epoch = np.arange(1, len(acc_list) + 1)
acc_list = np.array(acc_list)
plt.plot(epoch, acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()
运行结果:
.........
Test set: Accuracy 5582/6700 83.31%
[2min 25s] Epoch 98 [2560/13374] loss=0.00012382016611809377
[2min 25s] Epoch 98 [5120/13374] loss=0.00013412294483714505
[2min 25s] Epoch 98 [7680/13374] loss=0.0001319357840354011
[2min 25s] Epoch 98 [10240/13374] loss=0.00014047874965399386
[2min 26s] Epoch 98 [12800/13374] loss=0.0001507062052405672
evaluating trained model ...
Test set: Accuracy 5575/6700 83.21%
[2min 26s] Epoch 99 [2560/13374] loss=0.00011492083176563028
[2min 26s] Epoch 99 [5120/13374] loss=0.00012040333058394026
[2min 27s] Epoch 99 [7680/13374] loss=0.00013128426398907324
[2min 27s] Epoch 99 [10240/13374] loss=0.00013662222836501313
[2min 27s] Epoch 99 [12800/13374] loss=0.0001430403388076229
evaluating trained model ...
Test set: Accuracy 5591/6700 83.45%
[2min 28s] Epoch 100 [2560/13374] loss=0.0001141645792813506
[2min 28s] Epoch 100 [5120/13374] loss=0.000125776029744884
[2min 28s] Epoch 100 [7680/13374] loss=0.00013097280486059997
[2min 28s] Epoch 100 [10240/13374] loss=0.00014439033002418
[2min 29s] Epoch 100 [12800/13374] loss=0.00014488830260233953
evaluating trained model ...
Test set: Accuracy 5569/6700 83.12%
进程已结束,退出代码为 0
还是GPU快 CPU跑了20多分钟

完结完结,若有错误,敬请指正,万分感谢!刘二大人老师的pytorch深度学习实践课程就到这里了,课完课题不完,学习永不停止,咱们继续加油 顶峰相见!!!冲!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









