







采集参数:TOP200热门电影名称、导演、演员、评分、评论数、评论文本、电影类型、制片国家/地区、上映日期、时长
一、单页电影链接获取
1-发送网页请求,获取网页信息
设置合适的请求头信息来模拟真实浏览器行为,设置合适的 User-Agent 和其他请求头信息,使请求看起来更像是来自正常的浏览器访问。
import requests
from bs4 import BeautifulSoup
movie_a = []
url = "https://movie.douban.com/top250?start=0&filter="
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
# 发送请求, 获取响应 这里的headers=是一个关键字
res = requests.get(url, 'lxml',headers= headers) # 标头里面的请求方法是GET, 所以这里我们使用get请求方法
print(res.text)
soup = BeautifulSoup(res.text, 'lxml')
a_tag = soup.find("ol", class_="grid_view")
for a in a_tag.findAll("li"):
movie_a.append(a.find("a")['href'])
print(movie_a)
'''
['https://movie.douban.com/subject/1292052/', 'https://movie.douban.com/subject/1291546/', 'https://movie.douban.com/subject/1292720/', 'https://movie.douban.com/subject/1292722/', 'https://movie.douban.com/subject/1291561/', 'https://movie.douban.com/subject/1295644/', 'https://movie.douban.com/subject/1292063/', 'https://movie.douban.com/subject/1889243/', 'https://movie.douban.com/subject/3541415/', 'https://movie.douban.com/subject/1292064/', 'https://movie.douban.com/subject/1295124/', 'https://movie.douban.com/subject/3011091/', 'https://movie.douban.com/subject/1292001/', 'https://movie.douban.com/subject/3793023/', 'https://movie.douban.com/subject/1291549/', 'https://movie.douban.com/subject/2131459/', 'https://movie.douban.com/subject/25662329/', 'https://movie.douban.com/subject/1307914/', 'https://movie.douban.com/subject/1296141/', 'https://movie.douban.com/subject/1292213/', 'https://movie.douban.com/subject/5912992/', 'https://movie.douban.com/subject/1291841/', 'https://movie.douban.com/subject/6786002/', 'https://movie.douban.com/subject/1849031/', 'https://movie.douban.com/subject/20495023/']
'''二、获取TOP200电影链接
'''
1. 构造新的url
2. for循环
第1页:0—-24
第2页:25-49
....
'''
import requests
from bs4 import BeautifulSoup
movie_a = []
pagen = [0, 25, 50, 75, 100, 125, 150, 175]
for n in pagen:
url = "https://movie.douban.com/top250?start="+str(n)+"&filter="
# 添加请求头信息
'''
为什么有些情况下要加headers?
不加headers,默认是 python-requests发送的请求,
加headers,伪装成浏览器发送的请求
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 发送请求, 获取响应 这里的headers=是一个关键字
res = requests.get(url,'lxml',headers=headers)
soup = BeautifulSoup(res.text, 'lxml') # 空
a_tag = soup.find("ol", class_="grid_view")
for a in a_tag.findAll("li"):
movie_a.append(a.find("a")['href'])
print(movie_a)
三 获取单个电影数据
采集参数:“title”(电影名称)、“director”(导演)、“actors”(演员列表)、“rating”(评分)、“comments_count”(评论数)、“genres”(电影类型)、“country_region”(制片国家/地区)、“release_date”(上映日期) “duration”(时长)。
以"泰坦尼克号"为例子 :https://movie.douban.com/subject/1292722/
import requests
from bs4 import BeautifulSoup
movie_no = [] #电影序号 0~199
title = []
director = []
actors = []
rating = []
comments_count = []
genres = []
country_region = []
release_date = []
duration = []
url = "https://movie.douban.com/subject/1292722/"
# 添加请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
res = requests.get(url, 'lxml',headers = headers)
soup = BeautifulSoup(res.text,'lxml')
print(soup)
movie = {}
# 1.提取电影名称
tit = soup.find("span", property = 'v:itemreviewed') #第2种
print(tit.text)
data = soup.find("div", id="info").text
a_tag = data.split("\n")
print(len(a_tag))
for i in range(0, len(a_tag)):
print(i, a_tag[i])
movie["电影名称"] = tit.text
movie["导演"] = a_tag[1].split(": ")[1]
movie["演员列表"] = a_tag[3].split(": ")[1].split(" / ")
'''
批量注释:ctr + ?/
'''
movie['评分'] = soup.find("strong", class_ = "ll rating_num").text
movie['评论数'] = soup.find("span",property="v:votes").text +"人评价"
movie['电影类型'] = a_tag[4].split(": ")[1].split(" / ")
movie['制片国家/地区'] = a_tag[5].split(": ")[1].split(" / ")
movie['上映时间'] = a_tag[7].split(": ")[1].split(" / ")
movie['时长'] = a_tag[8].split(": ")[1].split(" / ")
print(movie)
# print("成功采集", 1,"条数据!")输出结果:
泰坦尼克号 Titanic
12
0
1 导演: 詹姆斯·卡梅隆
2 编剧: 詹姆斯·卡梅隆
3 主演: 莱昂纳多·迪卡普里奥 / 凯特·温斯莱特 / 比利·赞恩 / 凯西·贝茨 / 弗兰西丝·费舍 / 格劳瑞亚·斯图尔特 / 比尔·帕克斯顿 / 伯纳德·希尔 / 大卫·沃纳 / 维克多·加博 / 乔纳森·海德 / 苏茜·爱米斯 / 刘易斯·阿伯内西 / 尼古拉斯·卡斯柯恩 / 阿那托利·萨加洛维奇 / 丹尼·努齐 / 杰森·贝瑞 / 伊万·斯图尔特 / 艾恩·格拉法德 / 乔纳森·菲利普斯 / 马克·林赛·查普曼 / 理查德·格拉翰 / 保罗·布赖特威尔 / 艾瑞克·布里登 / 夏洛特·查顿 / 博纳德·福克斯 / 迈克尔·英塞恩 / 法妮·布雷特 / 马丁·贾维斯 / 罗莎琳·艾尔斯 / 罗切尔·罗斯 / 乔纳森·伊万斯-琼斯 / 西蒙·克雷恩 / 爱德华德·弗莱彻 / 斯科特·安德森 / 马丁·伊斯特 / 克雷格·凯利 / 格雷戈里·库克 / 利亚姆·图伊 / 詹姆斯·兰开斯特 / 艾尔莎·瑞雯 / 卢·帕尔特 / 泰瑞·佛瑞斯塔 / 凯文·德·拉·诺伊
4 类型: 剧情 / 爱情 / 灾难
5 制片国家/地区: 美国 / 墨西哥
6 语言: 英语 / 意大利语 / 德语 / 俄语
7 上映日期: 1998-04-03(中国大陆) / 2023-04-03(中国大陆重映) / 1997-11-01(东京电影节) / 1997-12-19(美国)
8 片长: 194分钟 / 227分钟(白星版)
9 又名: 铁达尼号(港/台)
10 IMDb: tt0120338
11
{'电影名称': '泰坦尼克号 Titanic', '导演': '詹姆斯·卡梅隆', '演员列表': ['莱昂纳多·迪卡普里奥', '凯特·温斯莱特', '比利·赞恩', '凯西·贝茨', '弗兰西丝·费舍', '格劳瑞亚·斯图尔特', '比尔·帕克斯顿', '伯纳德·希尔', '大卫·沃纳', '维克多·加博', '乔纳森·海德', '苏茜·爱米斯', '刘易斯·阿伯内西', '尼古拉斯·卡斯柯恩', '阿那托利·萨加洛维奇', '丹尼·努齐', '杰森·贝瑞', '伊万·斯图尔特', '艾恩·格拉法德', '乔纳森·菲利普斯', '马克·林赛·查普曼', '理查德·格拉翰', '保罗·布赖特威尔', '艾瑞克·布里登', '夏洛特·查顿', '博纳德·福克斯', '迈克尔·英塞恩', '法妮·布雷特', '马丁·贾维斯', '罗莎琳·艾尔斯', '罗切尔·罗斯', '乔纳森·伊万斯-琼斯', '西蒙·克雷恩', '爱德华德·弗莱彻', '斯科特·安德森', '马丁·伊斯特', '克雷格·凯利', '格雷戈里·库克', '利亚姆·图伊', '詹姆斯·兰开斯特', '艾尔莎·瑞雯', '卢·帕尔特', '泰瑞·佛瑞斯塔', '凯文·德·拉·诺伊'], '评分': '9.5', '评论数': '2295844人评价', '电影类型': ['剧情', '爱情', '灾难'], '制片国家/地区': ['美国', '墨西哥'], '上映时间': ['1998-04-03(中国大陆)', '2023-04-03(中国大陆重映)', '1997-11-01(东京电影节)', '1997-12-19(美国)'], '时长': ['194分钟', '227分钟(白星版)']}四 单个电影数据转换为DataFrame存储
import requests
from bs4 import BeautifulSoup
# 共10个 第1步 建数组
no = []
title = []
director = []
actors = []
rating = []
comments_count =[]
genres = []
country_region = []
release_date = []
duration = []
url = "https://movie.douban.com/subject/1292722/"
# 添加请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
res = requests.get(url, 'lxml',headers = headers)
soup = BeautifulSoup(res.text,'lxml')
movie = {}
# 1.提取电影名称
tit = soup.find("span", property = 'v:itemreviewed') #第2种
data = soup.find("div", id="info").text
a_tag = data.split("\n")
# print(len(a_tag))
# for i in range(0, len(a_tag)):
# print(i, a_tag[i])
movie["电影名称"] = tit.text
movie["导演"] = a_tag[1].split(": ")[1]
movie["演员列表"] = a_tag[3].split(": ")[1].split(" / ")
movie['评分'] = soup.find("strong", class_ = "ll rating_num").text
movie['评论数'] = soup.find("span",property="v:votes").text +"人评价"
movie['电影类型'] = a_tag[4].split(": ")[1].split(" / ")
movie['制片国家/地区'] = a_tag[5].split(": ")[1].split(" / ")
movie['上映时间'] = a_tag[7].split(": ")[1].split(" / ")
movie['时长'] = a_tag[8].split(": ")[1].split(" / ")
# 第2步 放数据
no.append(1)
title.append(movie["电影名称"])
director.append(movie["导演"])
actors.append(movie["演员列表"])
rating.append(movie['评分'])
comments_count.append(movie['评论数'])
genres.append(movie['电影类型'])
country_region.append(movie['制片国家/地区'])
release_date.append(movie['上映时间'])
duration.append(movie['时长'])
#print(movie)
# print("成功采集", 1,"条数据!")# 第3步,按照对应的列,放进dataFrame
import pandas as pd
df = pd.DataFrame()
df['序号'] = no
df['电影名称'] = title
df['导演'] = director
df['演员列表'] = actors
df['评分'] = rating
df['评论数'] = comments_count
df['电影类型'] = genres
df['制片国家/地区'] = country_region
df['上映时间'] = release_date
df['时长'] = duration
display(df)
五 多个电影数据获取,将数据转换为DataFrame格式
import requests
from bs4 import BeautifulSoup
starts = [0,25,50,75,100,125,150,175]
# 200条电影的链接
movie_a = []
for n in starts:
url = "https://movie.douban.com/top250?start=" + str(n) + "&filter="
# 添加请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
# 发送请求, 获取响应 这里的headers=是一个关键字
res = requests.get(url, headers=headers) # 标头里面的请求方法是GET, 所以这里我们使用get请求方法
soup = BeautifulSoup(res.text, 'lxml')
a_tag = soup.find('div', class_="article").find("ol", class_="grid_view")
# print(a_tag)
# print(a_tag.findAll("li"))
for a in a_tag.findAll("li"):
movie_a.append(a.find("a")['href'])
print("获取",len(movie_a),"条电影链接")
# 查看前10条电影链接
print(movie_a[0:10])获取 200 条电影链接
['https://movie.douban.com/subject/1292052/', 'https://movie.douban.com/subject/1291546/', 'https://movie.douban.com/subject/1292720/', 'https://movie.douban.com/subject/1292722/', 'https://movie.douban.com/subject/1291561/', 'https://movie.douban.com/subject/1295644/', 'https://movie.douban.com/subject/1292063/', 'https://movie.douban.com/subject/1889243/', 'https://movie.douban.com/subject/3541415/', 'https://movie.douban.com/subject/1292064/']# 共10个 第1步 建数组
no = []
title = []
director = []
actors = []
rating = []
comments_count =[]
genres = []
country_region = []
release_date = []
duration = []
'''
以上代码不动
修改以下代码
'''
n = 0
for url in movie_a:
# 添加请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
res = requests.get(url, 'lxml',headers = headers)
soup = BeautifulSoup(res.text,'lxml')
movie = {}
# 1.提取电影名称
tit = soup.find("span", property = 'v:itemreviewed') #第2种
data = soup.find("div", id="info").text
a_tag = data.split("\n")
# print(len(a_tag))
# for i in range(0, len(a_tag)):
# print(i, a_tag[i])
movie["电影名称"] = tit.text
movie["导演"] = a_tag[1].split(": ")[1]
movie["演员列表"] = a_tag[3].split(": ")[1].split(" / ")
movie['评分'] = soup.find("strong", class_ = "ll rating_num").text
movie['评论数'] = soup.find("span",property="v:votes").text +"人评价"
movie['电影类型'] = a_tag[4].split(": ")[1].split(" / ")
movie['制片国家/地区'] = a_tag[5].split(": ")[1].split(" / ")
movie['上映时间'] = a_tag[7].split(": ")[1].split(" / ")
movie['时长'] = a_tag[8].split(": ")[1].split(" / ")
# 第2步 放数据
no.append(n)
n = n + 1
title.append(movie["电影名称"])
director.append(movie["导演"])
actors.append(", ".join(movie["演员列表"]))
rating.append(movie['评分'])
comments_count.append(movie['评论数'])
genres.append(", ".join(movie['电影类型']))
country_region.append(", ".join(movie['制片国家/地区']))
release_date.append(", ".join(movie['上映时间']))
duration.append(", ".join(movie['时长']))
#print(movie)
#print("成功采集", 1,"条数据!")'''
代码不动
'''
# 第3步,按照对应的列,放进dataFrame
import pandas as pd
df = pd.DataFrame()
df['序号'] = no
df['电影名称'] = title
df['导演'] = director
df['演员列表'] = actors
df['评分'] = rating
df['评论数'] = comments_count
df['电影类型'] = genres
df['制片国家/地区'] = country_region
df['上映时间'] = release_date
df['时长'] = duration
df.head(25)输出结果,存在问题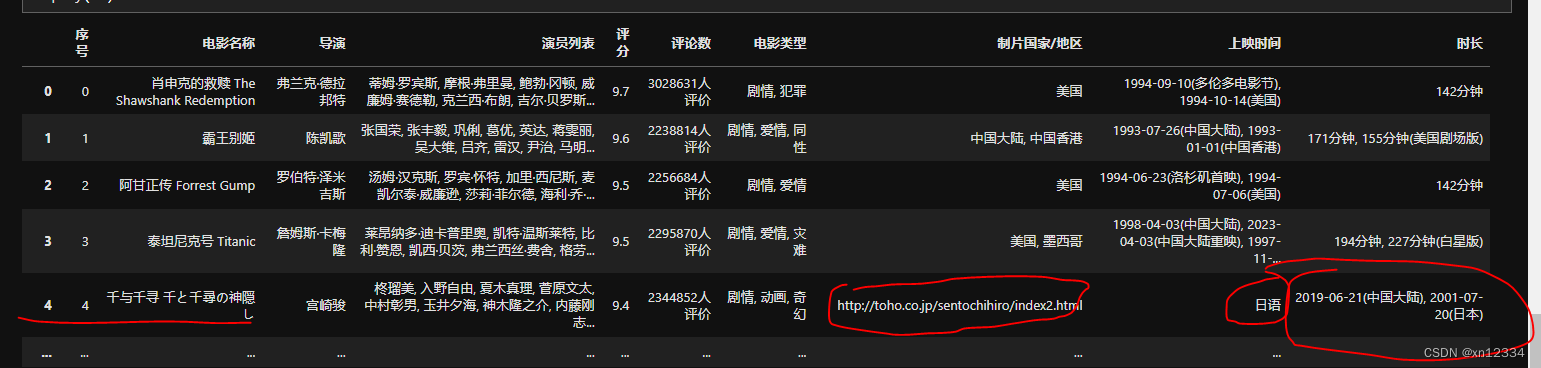
以“千与千寻”为例:分析错误原因,修改代码
导演: 罗伯特·泽米吉斯
编剧: 埃里克·罗思 / 温斯顿·格鲁姆
主演: 汤姆·汉克斯 / 罗宾·怀特 / 加里·西尼斯 / 麦凯尔泰·威廉逊 / 莎莉·菲尔德 / 海利·乔·奥斯蒙 / 迈克尔·康纳·亨弗里斯 / 哈罗德·G·赫瑟姆 / 山姆·安德森 / 伊俄涅·M·特雷奇 / 彼得·道博森 / 希芳·法隆 / 伊丽莎白·汉克斯 / 汉娜·豪尔 / 克里斯托弗·琼斯 / 罗布·兰德里 / 杰森·麦克奎尔 / 桑尼·施罗耶 / 艾德·戴维斯 / 丹尼尔C.斯瑞派克 / 大卫·布里斯宾 / 德博拉·麦克蒂尔 / 艾尔·哈林顿 / 阿非莫·奥米拉 / 约翰·沃德斯塔德 / 迈克尔·伯吉斯 / 埃里克·安德伍德 / 拜伦·明斯 / 斯蒂芬·布吉格沃特 / 约翰·威廉·高尔特 / 希拉里·沙普兰 / 伊莎贝尔·罗斯 / 理查德·达历山德罗 / 迪克·史迪威 / 迈克尔-杰斯 / 杰弗里·布莱克 / 瓦妮莎·罗斯 / 迪克·卡维特 / 马拉·苏查雷特扎 / 乔·阿拉斯奇 / W·本森·泰瑞
类型: 剧情 / 爱情
制片国家/地区: 美国
语言: 英语
上映日期: 1994-06-23(洛杉矶首映) / 1994-07-06(美国)
片长: 142分钟
又名: 福雷斯特·冈普
IMDb: tt0109830
1 导演: 罗伯特·泽米吉斯 -> 用": " ->s = ['导演','罗伯特·泽米吉斯'] ->构建字典 -> movie[s[0]] = s[1] -> movie['导演'] = '罗伯特·泽米吉斯'
2 编剧: 埃里克·罗思 / 温斯顿·格鲁姆
3 主演: 汤姆·汉克斯 / 罗宾·怀特 / 加里·西尼斯 / 麦凯尔泰·威廉逊 / 莎莉·菲尔德 / 海利·乔·奥斯蒙 / 迈克尔·康纳·亨弗里斯 / 哈罗德·G·赫瑟姆 / 山姆·安德森 / 伊俄涅·M·特雷奇 / 彼得·道博森 / 希芳·法隆 / 伊丽莎白·汉克斯 / 汉娜·豪尔 / 克里斯托弗·琼斯 / 罗布·兰德里 / 杰森·麦克奎尔 / 桑尼·施罗耶 / 艾德·戴维斯 / 丹尼尔C.斯瑞派克 / 大卫·布里斯宾 / 德博拉·麦克蒂尔 / 艾尔·哈林顿 / 阿非莫·奥米拉 / 约翰·沃德斯塔德 / 迈克尔·伯吉斯 / 埃里克·安德伍德 / 拜伦·明斯 / 斯蒂芬·布吉格沃特 / 约翰·威廉·高尔特 / 希拉里·沙普兰 / 伊莎贝尔·罗斯 / 理查德·达历山德罗 / 迪克·史迪威 / 迈克尔-杰斯 / 杰弗里·布莱克 / 瓦妮莎·罗斯 / 迪克·卡维特 / 马拉·苏查雷特扎 / 乔·阿拉斯奇 / W·本森·泰瑞
4 类型: 剧情 / 爱情
5 制片国家/地区: 美国
6 语言: 英语
7 上映日期: 1994-06-23(洛杉矶首映) / 1994-07-06(美国)
8 片长: 142分钟
9 又名: 福雷斯特·冈普
10 IMDb: tt0109830import requests
from bs4 import BeautifulSoup
# 共10个 第1步 建数组
no = []
title = []
director = []
actors = []
rating = []
comments_count =[]
genres = []
country_region = []
release_date = []
duration = []
# 以错误“千与千寻”为例
url = "https://movie.douban.com/subject/1291561/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
res = requests.get(url, 'lxml',headers = headers)
soup = BeautifulSoup(res.text,'lxml')
movie = {}
tit = soup.find("span", property = 'v:itemreviewed') #第2种
data = soup.find("div", id="info").text
a_tag = data.split("\n")
'''
修改以下代码,解决错误
开始
'''
print(len(a_tag))
# 修改1
for i in a_tag:
if len(i)> 0:
s = i.split(": ")
movie[s[0]] = ", ".join(s[1].split(" / "))
'''
问题原因 :使用a_tag[序号],而序号位置可能会变化
'''
movie["电影名称"] = tit.text
movie['评分'] = soup.find("strong", class_ = "ll rating_num").text
movie['评论数'] = soup.find("span",property="v:votes").text +"人评价"
print(movie)
# 第2步 放数据
no.append(4)
# n = n + 1
# 修改 2
title.append(movie["电影名称"])
director.append(movie["导演"])
actors.append(movie["主演"])
rating.append(movie['评分'])
comments_count.append(movie['评论数'])
genres.append(movie['类型'])
country_region.append(movie['制片国家/地区'])
release_date.append(movie['上映日期'])
duration.append(movie['片长'])
'''
结束
'''六、最终代码
import requests
from bs4 import BeautifulSoup
starts = [0,25,50,75,100,125,150,175]
# 200条电影的链接
movie_a = []
for n in starts:
url = "https://movie.douban.com/top250?start=" + str(n) + "&filter="
# 添加请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
# 发送请求, 获取响应 这里的headers=是一个关键字
res = requests.get(url, headers=headers) # 标头里面的请求方法是GET, 所以这里我们使用get请求方法
soup = BeautifulSoup(res.text, 'lxml')
a_tag = soup.find('div', class_="article").find("ol", class_="grid_view")
# print(a_tag)
# print(a_tag.findAll("li"))
for a in a_tag.findAll("li"):
movie_a.append(a.find("a")['href'])
print("获取",len(movie_a),"条电影链接")
# 查看前10条电影链接
print(movie_a[0:10])# 共10个 第1步 建数组
no = []
title = []
director = []
actors = []
rating = []
comments_count =[]
genres = []
country_region = []
release_date = []
duration = []
'''
以上代码不动
修改以下代码
'''
n = 0
for url in movie_a:
# 添加请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
res = requests.get(url, 'lxml',headers = headers)
soup = BeautifulSoup(res.text,'lxml')
movie = {}
# 1.提取电影名称
tit = soup.find("span", property = 'v:itemreviewed') #第2种
data = soup.find("div", id="info").text
a_tag = data.split("\n")
for i in a_tag:
if len(i)> 0:
s = i.split(": ")
# print(i,s) # i = "官方小站:" ->['官方小站:'] 只有s[0],没有s[1]
if len(s)>1:
movie[s[0]] = ", ".join(s[1].split(" / "))
movie["电影名称"] = tit.text
movie['评分'] = soup.find("strong", class_ = "ll rating_num").text
movie['评论数'] = soup.find("span",property="v:votes").text +"人评价"
# 第2步 放数据
no.append(n)
n = n + 1
title.append(movie["电影名称"])
director.append(movie["导演"])
actors.append(movie["主演"])
rating.append(movie['评分'])
comments_count.append(movie['评论数'])
genres.append(movie['类型'])
country_region.append(movie['制片国家/地区'])
release_date.append(movie['上映日期'])
duration.append(movie['片长'])
#print(movie)
print("成功采集", n,"条数据!")'''
代码不动
'''
# 第3步,按照对应的列,放进dataFrame
import pandas as pd
df = pd.DataFrame()
df['序号'] = no
df['电影名称'] = title
df['导演'] = director
df['演员列表'] = actors
df['评分'] = rating
df['评论数'] = comments_count
df['电影类型'] = genres
df['制片国家/地区'] = country_region
df['上映时间'] = release_date
df['时长'] = duration
df.head(25)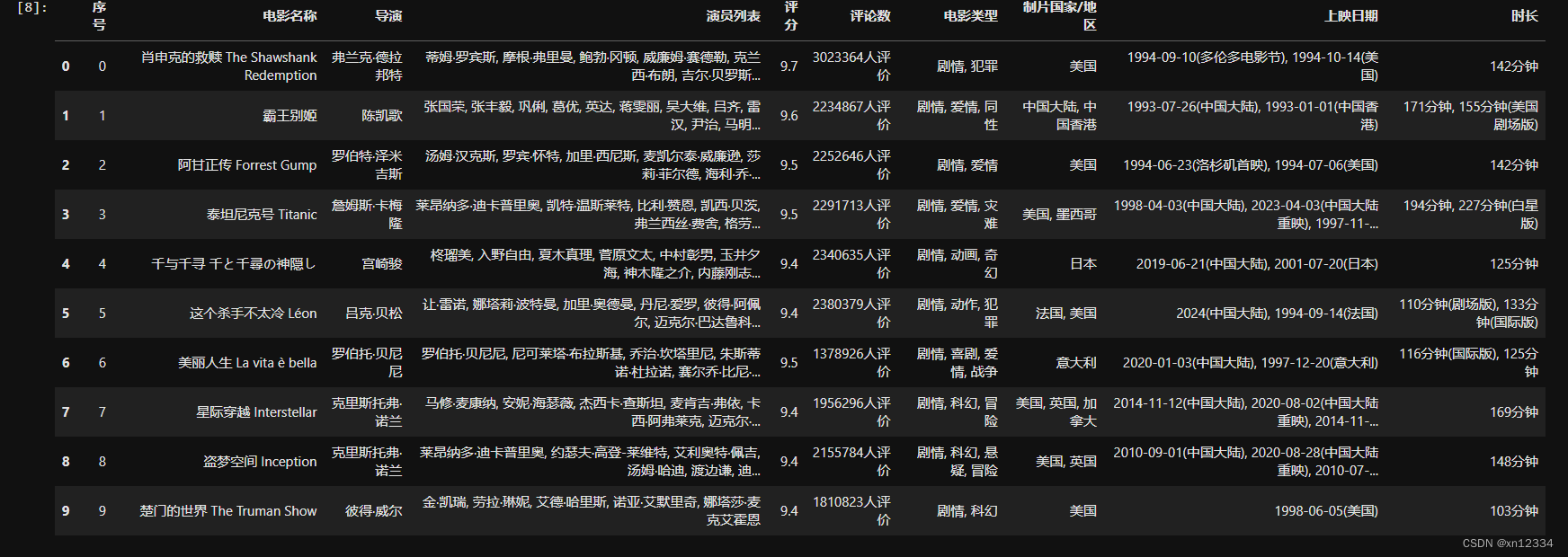

















 1527
1527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









