







本系列为大数据学习个人笔记,如有错误,欢迎指正,也欢迎各路朋友交流讨论。
MapReduce是啥?
- MapReduce是一种计算模型,它将大型数据操作作业分解为可以跨服务器集群并行执行的单个任务
- 用于大规模数据处理
- 每个节点处理存储在该节点上的数据
- 每个MapReduce作业都包含两个阶段
- Map
- Reduce
几点解释
- map阶段就是将原数据(存储在HDFS上的)按照处理的业务逻辑转换为key-value数据格式。
- reduce阶段,对map阶段处理完的数据进行汇总,然后按照需求进行处理,最终输出到HDFS。reduce阶段最终输出到HDFS的时候也是key-value的数据格式。
- 由 map 到 reduce 的过程就称作 shuffle,具体操作包含数据排序,聚合,分发。相同key的数据会到达同一个Reduce Worker。
- map任务的并行度无法设置,map任务的并行度就是根据数据块的数量决定的,在map端处理数据的时候改变不了。
思考
-
512M——4个block,默认情况由4个Map Task来进行处理。如何通过2个Map Task来实现?
- 设置数据块的大小,上传的时候,一个数据块设置为256M,HDFS的java客户端上传数据可以指定block大小。
自动运算框架MapReduce
- MapReduce计算是并行和自动分布的
- 并行度:有多少个数据块Map任务的并行度就是多少
- 如何分布:把程序分发到数据所在节点,在处理数据的时候直接本地化处理 - 开发人员只需要关注map和reduce函数的实现
- M/R是用Java编写的,但也支持Python
MapReduce - Word Count

- MapReduce - Combine :实质是本地聚合,提升处理效率
- Combine 代码和 Reduce 代码可以复用
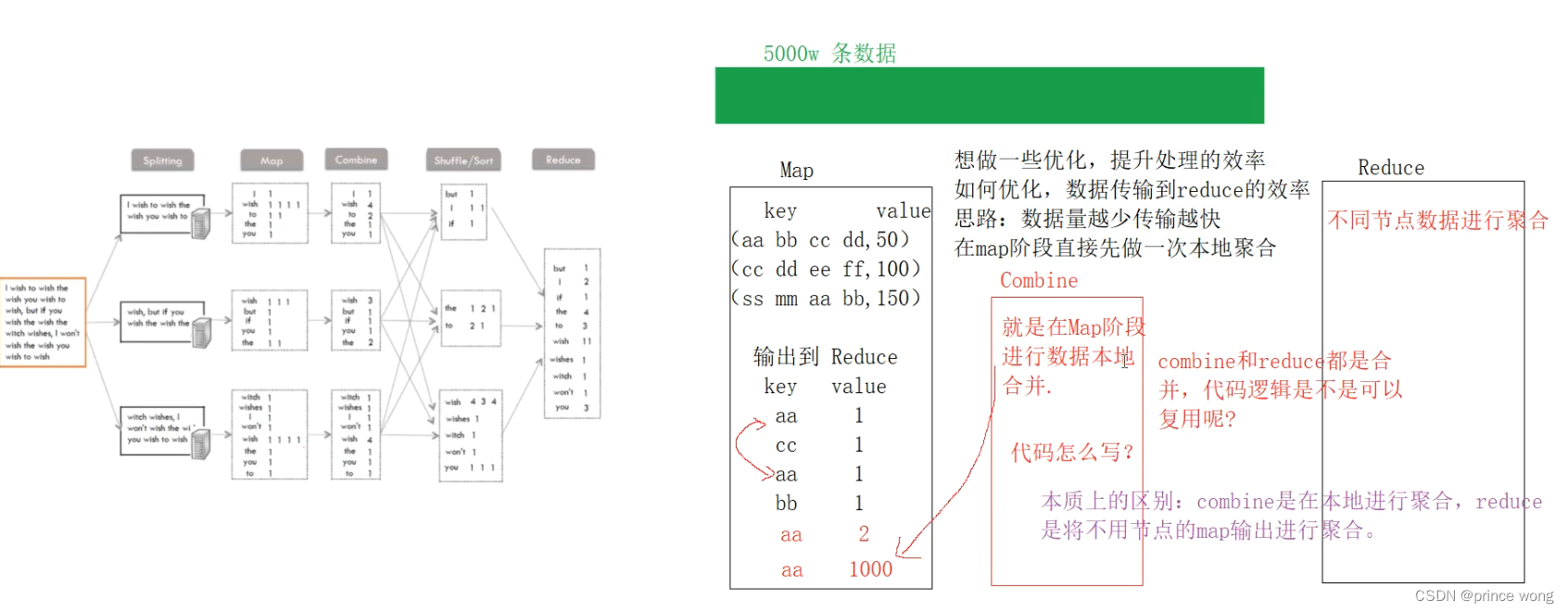
- Combine 代码和 Reduce 代码可以复用
- MapReduce - Partitioner
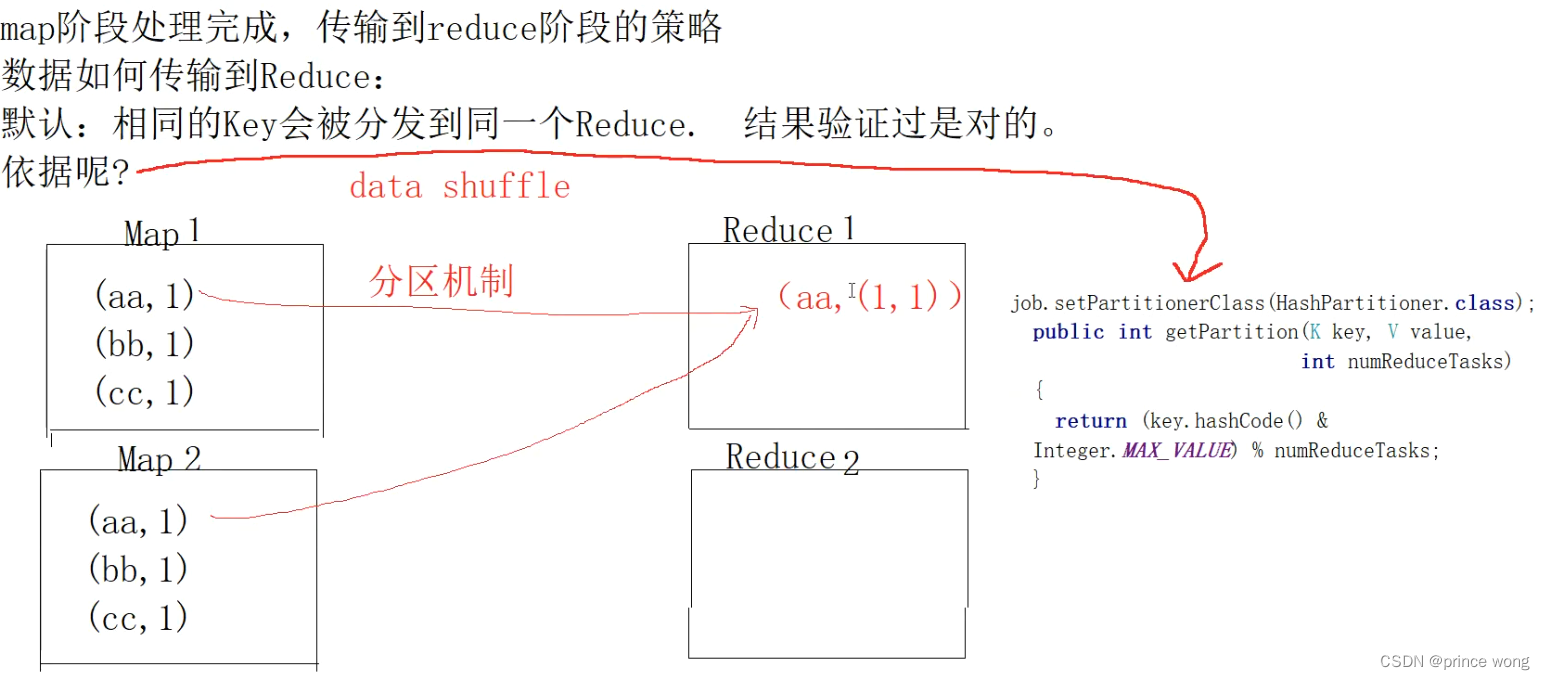
- MapReduce - Shuffle and Sort
- 数据由map到reduce的过程
- 数据经过网络传输和排序
What is InputSplit? (切片)
- InputSplit表示由单个Mapper处理的数据
- 块是数据的物理表示。 Split是Block中数据的逻辑表示
- Map处理的是逻辑块,不是物理块(HDFS存储的是物理块)
- InputSplit尊重逻辑记录边界
- Map任务处理的时候会将物理块封装为逻辑块,逻辑块包含了记录的边界
- 在MapReduce执行期间,Hadoop扫描块并创建InputSplits,每个InputSplit将分配给各个mapper进行处理
- 如何控制map的数量?
- 一个逻辑块对应一个map任务进行处理
- 自定义inputSplit
- 修改数据块的大小
- 一个逻辑块对应一个map任务进行处理
Distributed Cache
- 分布式缓存有助于在执行M / R作业时将只读文件发送到Hadoop集群中的任务节点
- 文件可以是查找表,文本文件,JAR等
- 文件的大小应该是“小”
- 每个作业只复制一次文件
- 类似于SQL里面的Join操作
- 使用场景:当要处理的数据集一大一小的时候,就非常合适,把小的数据集缓存到运行mapper任务的内存中,直接在mapper处理的时候读取出来就可以了
- mapreduce程序可以只有mao端没有reduce端
- 如果在map端就可以处理完成,可以不写reduce
Speculative Execution - SE (投机执行- SE)
-
Problem: (MapReduce存在的问题)
- 当100个map任务中的99个已经完成时,系统仍在等待最终的map任务输入,这比所有其他节点花费的时间长得多
-
Resolution: Using SE (解决方案)
- 相同的输入可以并行处理多次,以利用机器功能的差异
- 跨多个没有其他工作要执行的节点,调度缓慢任务的冗余副本
- 无论任务的哪个副本最先完成,都将成为最终副本















 3201
3201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









