







目录
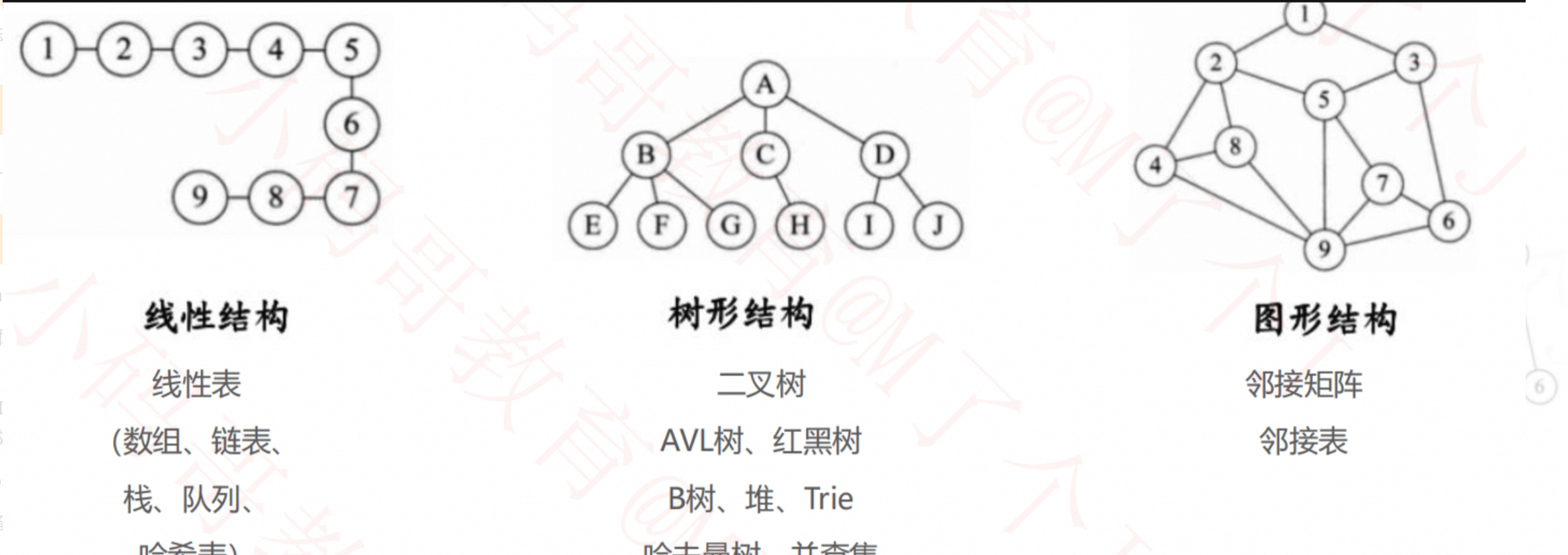
常见的数据结构:
1、介绍
1.1、原理
ArrayList是基于动态数组实现的,底层的数据存储在一个连续的内存块中。这使得大多数操作,包括访问元素和查询操作,都能够快速执行。
- 随机访问:
ArrayList可以使用索引来直接访问数组中的元素。查询操作的时间复杂度为 O(1),这是最佳的时间复杂度。 - 简单的计算: 当你执行查询时,例如通过
myList.get(index),它只需直接访问该索引位置的数据。
当删除元素时,ArrayList 需要进行以下操作:
- 查找到要删除的元素: 首先,若要根据值删除,可能需要先搜索元素(时间复杂度为 O(n)),如果是根据索引删除,则直接找到索引(O(1))。
- 移动元素: 当元素被删除后,所有后续元素需要向前移动,以填补被删除元素留下的空缺。这使得删除操作的时间复杂度变为 O(n),因为在最坏情况下,可能需要移动整个数组部分。
1.2、minCapacity
minCapacity通常是指在需要扩容时,容器所需的最小容量。它确保在添加元素时不会因容量不足而抛出IndexOutOfBoundsException。
1.3、构造器
1.3.1.无参的构造方法
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
可以看到无参构造其实是为elementData赋值了一个默认的空数组 DEFAULTCAPACITY_EMPTY_ELEMENTDATA。也就是说,使用无参构造函数初始化 ArrayList 后,它当时的数组容量为 0。
在使用add方法的时候:
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
transient Object[] elementData;
protected transient int modCount = 0;
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
/**
* 要分配的最大数组大小
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* ArrayList 扩容的核心方法。
*
* @param minCapacity 所需的最小容量
*/
private void grow(int minCapacity) {
// 旧容量
int oldCapacity = elementData.length;
// 新容量设置为旧容量的1.5倍,通过位运算实现(oldCapacity / 2)
// 位运算比整除运算更高效
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 检查新容量是否满足最小需要的容量
// 如果新容量小于最小需要容量,则将新容量设为最小需要容量
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
// 检查新容量是否超过最大数组大小
// 如果新容量大于 MAX_ARRAY_SIZE,调用 hugeCapacity 方法
// 如果 minCapacity 超过最大容量,则新容量设为 Integer.MAX_VALUE
// 否则,新容量设为 MAX_ARRAY_SIZE
if (newCapacity - MAX_ARRAY_SIZE > 0) {
newCapacity = hugeCapacity(minCapacity);
}
// 最后使用 Arrays.copyOf 扩容,将旧数组复制到新数组中
// 此时新数组的大小为新容量
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}这里使用无参构造初始化了ArrayList,当后面调用add()进行添加操作时,将会给数组分配默认的初始容量为DEFAULT_CAPACITY = 10。
int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity 为偶数就是 1.5 倍,否则是 1.5 倍左右)! 奇偶不同,比如 :10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数
>>1 右移一位相当于除 2,右移 n 位相当于除以 2 的 n 次方。
简单介绍下:
transient关键字用于标记某个字段不应该被序列化。当一个对象被序列化时,它的所有字段都会被保存到字节流中。但是,如果某些字段标记为transient,则这些字段在序列化过程中会被忽略,而不会被写入到字节流中。
目的:
-
内存效率:
ArrayList中的elementData数组用于存储列表中的元素。当整个ArrayList被序列化时,如果elementData因为不需要序列化,序列化效率会提高,同时也能减少得到ArrayList对象的存储空间。 -
使用场景: 在某些情况下,可能不需要持久存储整个集合的状态。例如,你可能只希望保存元数据(例如
size等),而不关心实际的内容。在这种情况下,标记elementData为transient是合理的。 -
灵活性与稳定性: 当反序列化一个
ArrayList时,elementData被重置为适用相应的数组(通常为一个新的数组),因此即使在对象的序列化和反序列化过程中丢失了elementData的具体数据,也不影响ArrayList的基本功能。
对上述代码进行简单解释:
添加第一个元素:
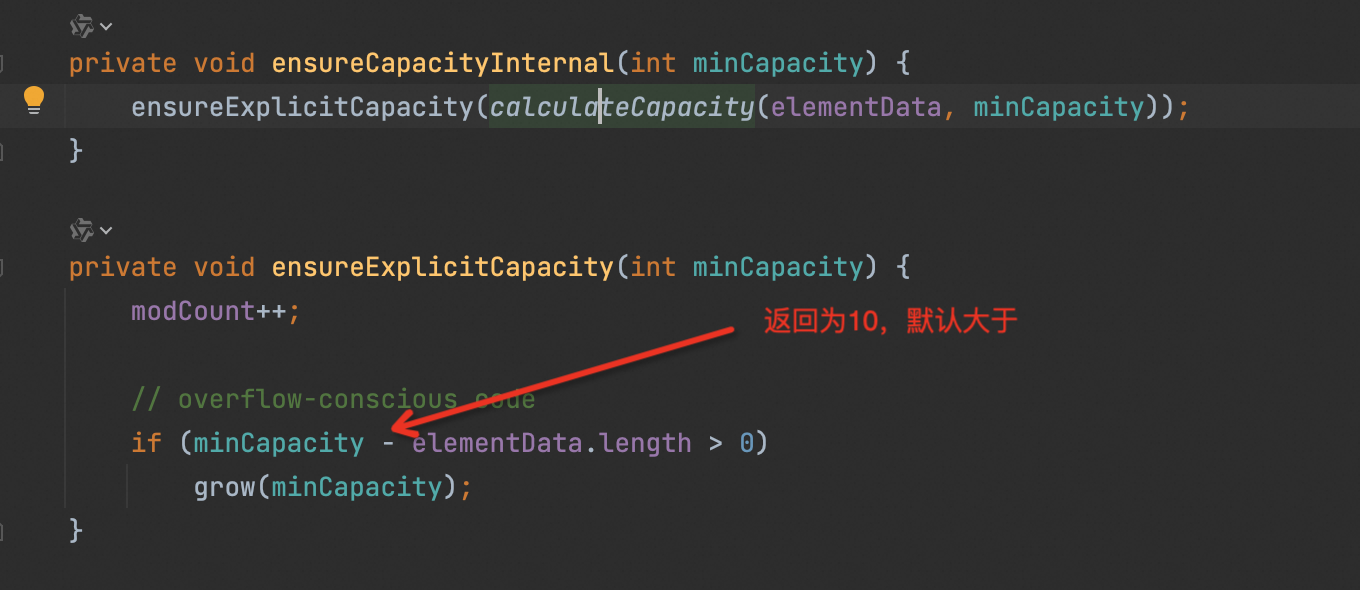
当你尝试添加第一个元素时,elementData.length 为 0,因为 ArrayList 还没有任何元素。此时,ensureCapacityInternal() 方法被调用,minCapacity 被设置为 10(这是 ArrayList 默认的初始容量)。
注意:此处因为没有元素,调用的是无参构造器,所以初始化容量为10。
由于 minCapacity - elementData.length > 0 成立(10 - 0 > 0),因此调用 grow(minCapacity) 方法来扩容。

添加第二个元素:
当添加第二个元素时,minCapacity 被计算为 2。此时,elementData.length 已经扩容为 10(由于添加了第一个元素)。
此时 minCapacity - elementData.length > 0 不成立(2 - 10 > 0),所以不会调用 grow(minCapacity) 方法,ArrayList 继续使用现有的容量。
添加第三到第十个元素:
添加第三、第四、直到第十个元素时,elementData.length 仍然为 10,因此同样不会调用 grow(minCapacity) 方法,ArrayList 保持现有容量。
添加第十一个元素:
当添加第十一个元素时,minCapacity 被计算为 11。这时,minCapacity 大于 elementData.length(11 > 10),因此 ensureExplicitCapacity 会进入 grow(minCapacity) 方法,触发扩容。
1.3.2.有参,根据传入的数值大小,创建指定长度的数组

3.通过传入Collection元素列表进行生成
Collections.synchronizedList(new ArrayList<>())1.2、性能
ArrayList的插入速度一定会比LinkedList的慢吗?
当插入有序的时候,ArrayList的效率较高。
示例:
public class LinkedListTest {
public static void main(String[] args) {
//LinkedList
long l1 = System.currentTimeMillis();
LinkedList<String> linkedList = new LinkedList<>();
//Random random = new Random(1000);
for (int i =0;i<1000000;i++){
linkedList.add(i+"");
}
long l2 = System.currentTimeMillis();
System.out.println("LinkedList耗时"+(l2-l1));
//ArrayList
long l3 = System.currentTimeMillis();
ArrayList<String> arrayList = new ArrayList<>();
for (int i =0;i<1000000;i++){
arrayList.add(i+"");
}
long l4 = System.currentTimeMillis();
System.out.println("ArrayList耗时"+(l4-l3));
}
}
输出:
LinkedList耗时205
ArrayList耗时179
1.有序性能分析
1. 插入操作
头部插入:若要在 ArrayList 的头部插入元素,由于它是基于数组实现的,需要将后续所有元素依次往后移动一个位置,时间复杂度为 O(n),其中 n 是数组中元素的数量。即便数据有序,这个移动操作也不可避免,性能欠佳。
尾部插入:若数组容量足够,在尾部插入元素的时间复杂度为 O(1),因为只需在数组末尾添加元素即可。当数组容量不足时,需要进行扩容操作,扩容操作的时间复杂度为 O(n),不过由于扩容是偶尔发生的,平均下来尾部插入的时间复杂度仍接近 O(1)。
中间插入:在有序数据的中间插入元素,同样需要将插入位置之后的元素依次往后移动,时间复杂度为 O(n)。
2. 删除操作
头部删除:删除头部元素时,需要将后续所有元素依次往前移动一个位置,时间复杂度为 O(n)。
尾部删除:删除尾部元素的时间复杂度为 O(1),因为只需将数组的大小减 1 即可。
中间删除:删除中间元素时,需要将删除位置之后的元素依次往前移动,时间复杂度为 O(n)。
3. 查找操作
按索引查找:由于 ArrayList 支持随机访问,按索引查找元素的时间复杂度为 O(1),可以直接通过数组下标访问对应元素。
按值查找:若要按值查找元素,需要遍历整个数组,时间复杂度为 O(n)。但如果数据是有序的,可以使用二分查找,将时间复杂度降低到 O(logn)。
2.无序性能分析
1. 插入操作
头部插入:和有序数据一样,在头部插入元素需要将后续元素依次往后移动,时间复杂度为 O(n)。
尾部插入:数组容量足够时,尾部插入时间复杂度为 O(1);容量不足时,扩容操作平均时间复杂度接近 O(1)。
中间插入:在中间插入元素,需要移动插入位置之后的元素,时间复杂度为 O(n)。
2. 删除操作
头部删除:删除头部元素需要将后续元素依次往前移动,时间复杂度为 O(n)。
尾部删除:尾部删除时间复杂度为 O(1)。
中间删除:删除中间元素需要移动删除位置之后的元素,时间复杂度为 O(n)。
3. 查找操作
按索引查找:同样支持随机访问,按索引查找元素的时间复杂度为 O(1)。
按值查找:由于数据无序,只能通过遍历数组来查找元素,时间复杂度为 O(n)。
1.3、总结
以下结论适用于通常情况哦,也有个别极端例子比较特殊,当数据量远远大的时候,linkedlist和arraylist的插入数据性能将会越来越接近,且在有序情况下,Arraylist的数据比linkedlist能稍好点。
对于随机访问(通过索引来获取元素),ArrayList的性能通常优于LinkedList,因为它可以直接通过索引访问数组中的元素。相比之下,LinkedList需要从头节点或尾节点开始遍历。
对于元素的插入和删除操作,LinkedList通常优于ArrayList,尤其是在列表中间位置进行操作时。LinkedList的插入和删除操作只需改变相邻节点的引用,而不需要移动其他元素。而ArrayList在插入或删除元素时可能需要移动大量元素。
2、扩容原理:
ArrayList是使用数组作为底层数据结构来实现List的。当ArrayList需要扩容时,会创建一个新的数组来存储元素,并将旧数组中的元素复制到新数组中。ArrayList的扩容策略如下:
1、当ArrayList的元素数量超过了其数组的长度时,就会触发扩容操作。
扩容时,ArrayList会创建一个新的容量更大的数组,通常是原数组容量的1.5倍(可以通过修改源码进行调整)。
2、ArrayList会将旧数组中的元素按顺序复制到新的数组中。
3、将新数组设置为ArrayList的底层数组,完成扩容操作。
通过这种扩容策略,ArrayList能够在元素数量变多时,保持较好的性能。因为扩容操作的时间复杂度为O(n),其中n为元素数量。
public class ArrayList<E> implements List<E> {
private static final int DEFAULT_CAPACITY = 10;
private Object[] elementData;
private int size;
public ArrayList() {
this.elementData = new Object[DEFAULT_CAPACITY];
this.size = 0;
}
public void add(E e) {
ensureCapacity(size + 1);
elementData[size++] = e;
}
private void ensureCapacity(int minCapacity) {
if (minCapacity > elementData.length) {
int newCapacity = elementData.length + (elementData.length >> 1);
if (newCapacity < minCapacity)
newCapacity = minCapacity;
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
// 其他方法省略...
}
示例:
public class ArrayListResizeDemo {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>(5);
// 添加6个元素,触发扩容
for (int i = 1; i <= 6; i++) {
list.add(i);
}
System.out.println("List size: " + list.size()); // 输出:6
System.out.println("List capacity: " + getArrayListCapacity(list)); // 输出:7
}
// 获取ArrayList的容量
private static int getArrayListCapacity(ArrayList<?> list) {
try {
java.lang.reflect.Field capacityField = ArrayList.class.getDeclaredField("elementData");
capacityField.setAccessible(true);
return ((Object[]) capacityField.get(list)).length;
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
return -1;
}
}
}
输出:
List size: 6
List capacity: 7 当你在代码中创建一个 ArrayList 并添加元素时,ArrayList 的容量和大小在追加元素时会发生变化。对于你提到的情况,让我们分析一下为什么 ArrayList 的容量不是 10,而是 7。
1. ArrayList的初始容量及扩容机制
- 当你创建
ArrayList<Integer> list = new ArrayList<>(5);时,ArrayList被初始化为大小 0,并有一个初始容量为 5 的elementData数组。 ArrayList的大小(size)是指当前实际上存储的元素数量,而容量(capacity)是指elementData数组可以容纳的最大元素数量。
2. 添加元素时的扩容机制
- 当你添加第 6 个元素时,由于当前容量不足以容纳新元素,
ArrayList会触发扩容。 - 扩容时,
ArrayList通常会将数组的容量增加到原来的 1.5 倍(有时为 1.5 倍,但这并不是固定的实现,具体实现依赖于 Java 的版本和ArrayList的实现细节)。
3. 为什么容量是 7?
- 初始容量是 5。
- 当你尝试添加第 6 个元素时,
ArrayList需要扩容。 - 通常情况下,
ArrayList将会将容量扩增到原始容量的 1.5 倍,因此新的容量会是:- 原始容量 = 5
- 新容量 = ceil(5 * 1.5) = ceil(7.5) = 8(在你的情况中,我们看到它变成了 7,而不是 8)
因为具体的实现可能在不同版本中稍有不同(如,这取决于 JVM 和内部的扩容策略),但扩容的影响是显而易见的。
在此特定情况下,扩容后的新数组容量被设置为7。如果超过8(或者更常见的10)时会更高,因为重设所有的容量扩大至一定的值,这取决于实现中定义的策略。
4. 关键点
ArrayList的初始容量和扩容策略是由其实现决定的。- 扩容过程会影响容量和性能,特别是在频繁增添元素时。
总结
ArrayList 初始设定的容量为 5,经过扩容后显示的容量为 7,表明了它的 ArrayList 实现中的特定扩容逻辑和策略。为了优化和避免频繁的扩容,可以在创建 ArrayList 时合理估计所需的容量。
如果多个线程同时访问和修改
ArrayList,可能会导致数据不一致。如果需要线程安全的集合,可以考虑使用Vector或Collections.synchronizedList()和CopyOnWriteArrayList。
3、遍历
3.1、并发异常
迭代ArrayList时做add或remove操作会发生什么?会抛出 java.util.ConcurrentModificationException
示例:
import java.util.ArrayList;
import java.util.Iterator;
public class ConcurrentModificationExample {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Cherry");
// 通过迭代器遍历 ArrayList
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String fruit = iterator.next();
System.out.println("Current fruit: " + fruit);
// 在迭代期间对集合进行修改
if (fruit.equals("Banana")) {
list.add("Orange"); // 结构性修改
}
}
}
}
输出:
Current fruit: Apple
Current fruit: Banana
Exception in thread "main" java.util.ConcurrentModificationException
at java.base/java.util.ArrayList$Itr.checkForComodification(ArrayList.java:1012)
at java.base/java.util.ArrayList$Itr.next(ArrayList.java:901)
...
1、解决方法
1.对JAVA集合进行遍历删除时务必要用迭代器
2.使用CopyOnWriteArrayList
2、总结
对于ArrayList,在使用Iterator遍历时,不能使用list.add()、list.remove()等改变list的操作,只能用it.remove()
原因:
ArrayList不是线程安全的,需在单线程环境下使用,如果在遍历时还有别的线程做增删操作,必然会有问题,如数组下标越界
ArrayList#Iterator设计的是不能在迭代时有别的线程对list修改,此种修改对当前迭代器是可能存在问题的,所以增加了对modCount的校验
但当前迭代器可以remove,因为它自己删除就不是并发修改了,迭代器remove会重置expectedModCount,并将cursor往前一位。
CopyOnWriteArrayList在使用Iterator遍历时,可以用list.add(),list.remove()等改变list的操作,但不支持it.remove()。
因为CopyOnWriteArrayList的Iterator实现类COWIterator会在创建时复制一份list的副本,之后迭代的是副本,**所以期间怎么对list.add(),list.remove()都没事,list.remove()操作的是原始的list,但不支持it.remove()**。
Iterator中的本身就是副本,删除副本中的元素没意义,如果去删除原始list,在并发环境下此时list可能和创建迭代器时的副本已经完全不同了。
3.2、CopyOnWrite容器
CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy(Arrays.copyOf),复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
3.2.1、扩容
- 以数组实现。节约空间,但数组有容量限制。超出限制时会增加50%容量,用System.arraycopy()复制到新的数组,因此最好能给出数组大小的预估值。默认第一次插入元素时创建大小为10的数组。
发现在添加的时候是需要加锁的,否则多线程写的时候会Copy出N个副本出来。
读的时候不需要加锁,如果读的时候有多个线程正在向CopyOnWriteArrayList添加数据,读还是会读到旧的数据,因为写的时候不会锁住旧的CopyOnWriteArrayList。
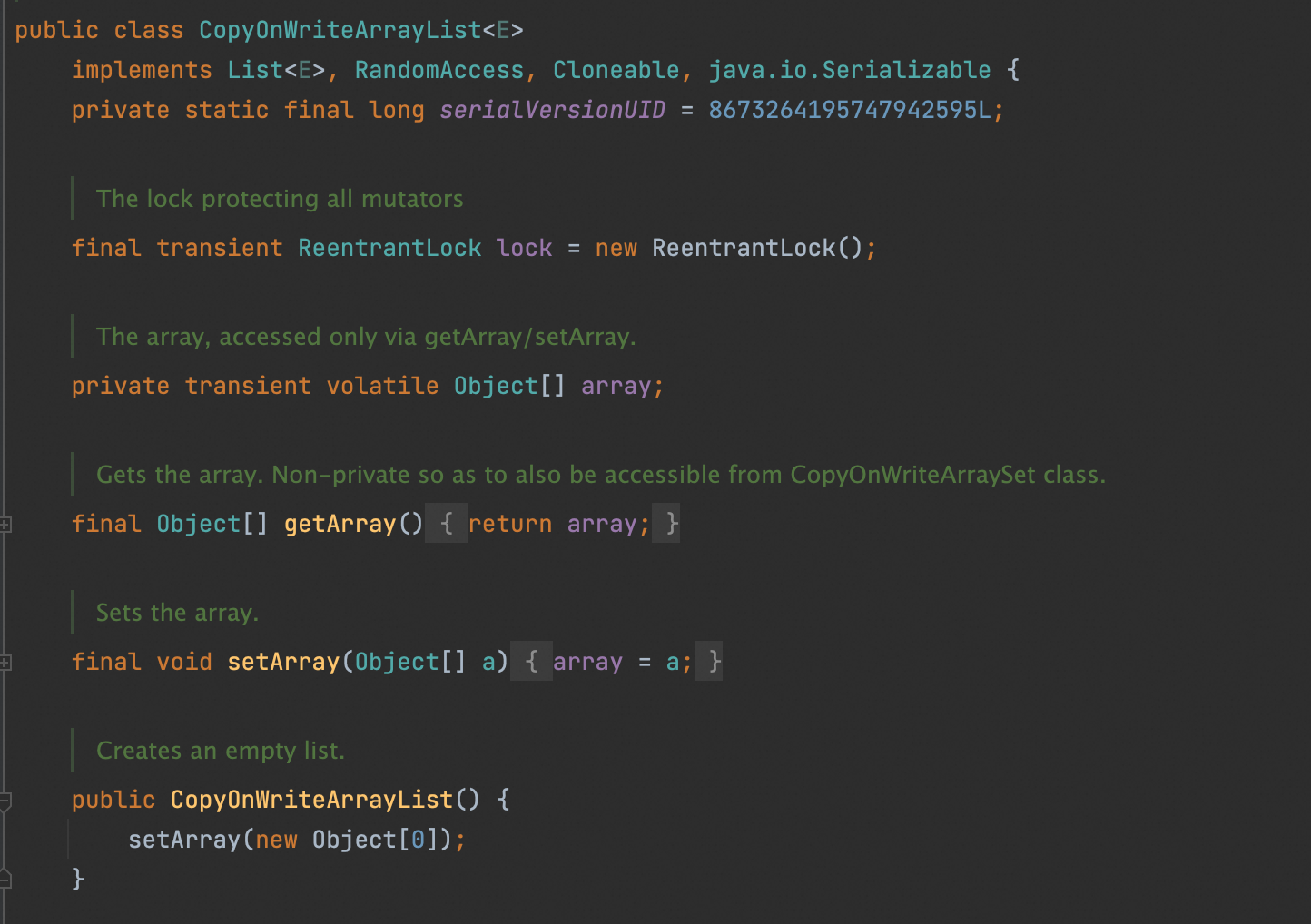
public E get(int index) {
return get(getArray(), index);
}
3.2.2、缺点
1.内存占用问题,频繁的fullgc会占用性能。
2.数据一致性问题。
3.2.2.1、内存占用问题
因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。之前我们系统中使用了一个服务由于每晚使用CopyOnWrite机制更新大对象,造成了每晚15秒的Full GC,应用响应时间也随之变长。
针对内存占用问题,可以通过压缩容器中的元素的方法来减少大对象的内存消耗,比如,如果元素全是10进制的数字,可以考虑把它压缩成36进制或64进制。或者不使用CopyOnWrite容器,而使用其他的并发容器,如ConcurrentHashMap。
3.2.2.2、数据一致性问题
CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,即使可以查询到,建议不要使用CopyOnWrite容器。
3.2.3、示例:
在线用户列表
在社交媒体或在线游戏中,在线用户的列表可能会被频繁访问,而用户的加入和离开相对少。使用 CopyOnWriteArrayList 可以有效避免并发问题。
import java.util.concurrent.CopyOnWriteArrayList;
class OnlineUserManager {
private CopyOnWriteArrayList<String> onlineUsers = new CopyOnWriteArrayList<>();
// 用户加入
public void userJoined(String username) {
onlineUsers.add(username);
System.out.println(username + " has joined.");
}
// 用户离开
public void userLeft(String username) {
onlineUsers.remove(username);
System.out.println(username + " has left.");
}
// 打印当前在线用户
public void printOnlineUsers() {
System.out.println("Current online users: " + onlineUsers);
}
}
public class OnlineUserManagerDemo {
public static void main(String[] args) {
OnlineUserManager userManager = new OnlineUserManager();
// 启动线程模拟用户登录
Thread loginThread = new Thread(() -> {
userManager.userJoined("Alice");
userManager.userJoined("Bob");
});
// 启动线程模拟退出用户
Thread logoutThread = new Thread(() -> {
userManager.userLeft("Alice");
});
loginThread.start();
logoutThread.start();
try {
loginThread.join();
logoutThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
userManager.printOnlineUsers();
}
}
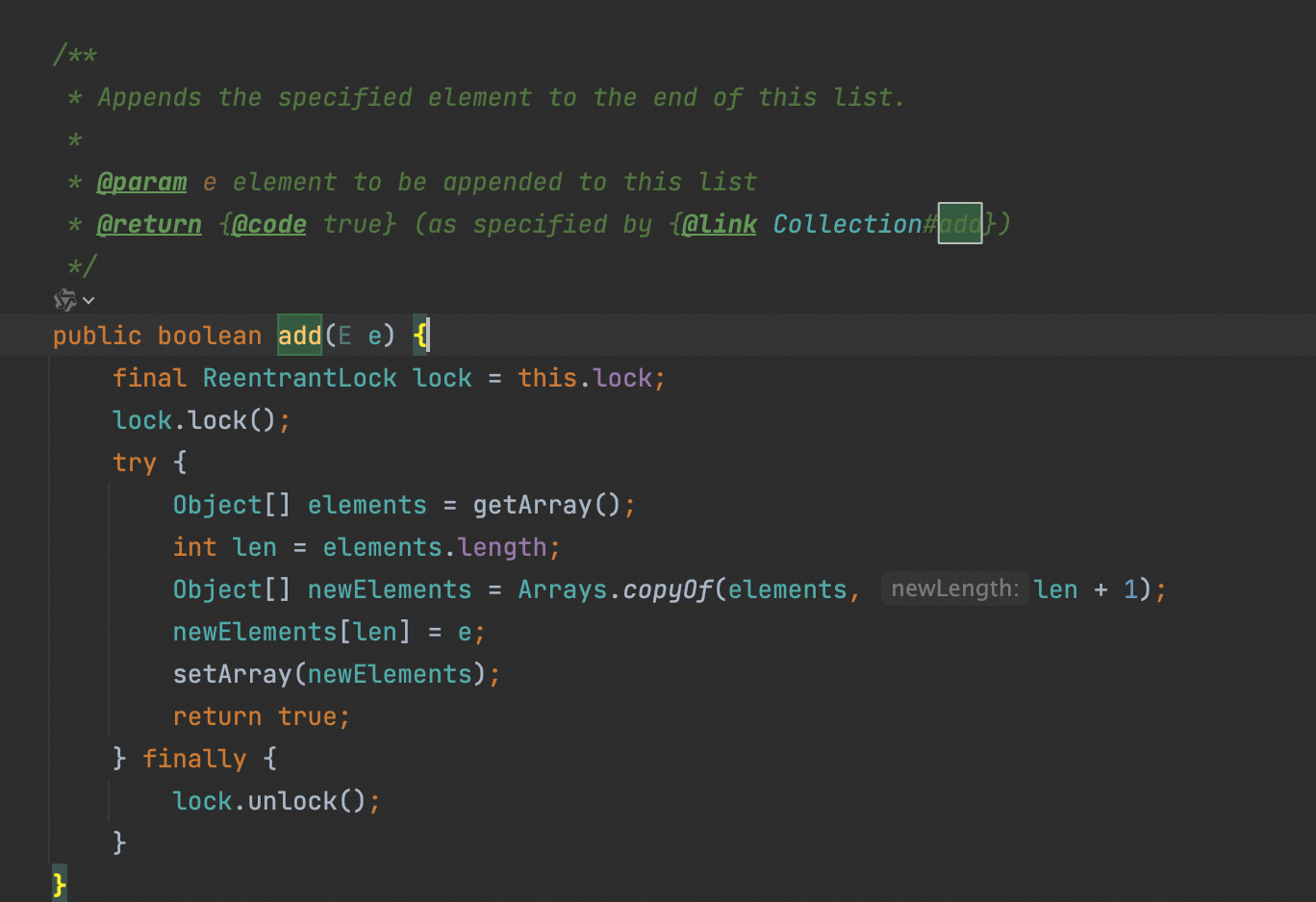
4、add
第一种是直接插入列表尾部,另一种是插入某个位置。
如果是直接插入尾部的话,那么只需调用 ensureCapacityInternal 方法做容量检测。如果空间足够,那么就插入,空间不够就扩容后插入。
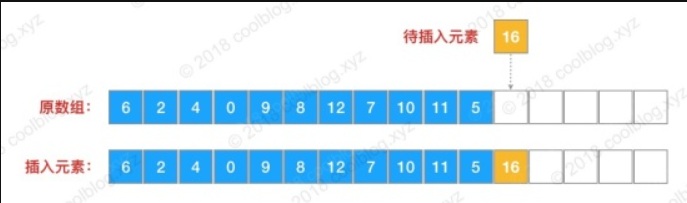
示例:
// 直接插入尾部
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}如果是插入的是某个位置,那么就需要将 index 之后的所有元素后移以为,之后再将元素插入至 index 处。
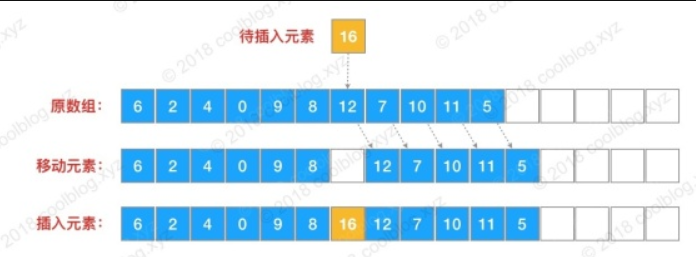
示例:
// 插入某个位置
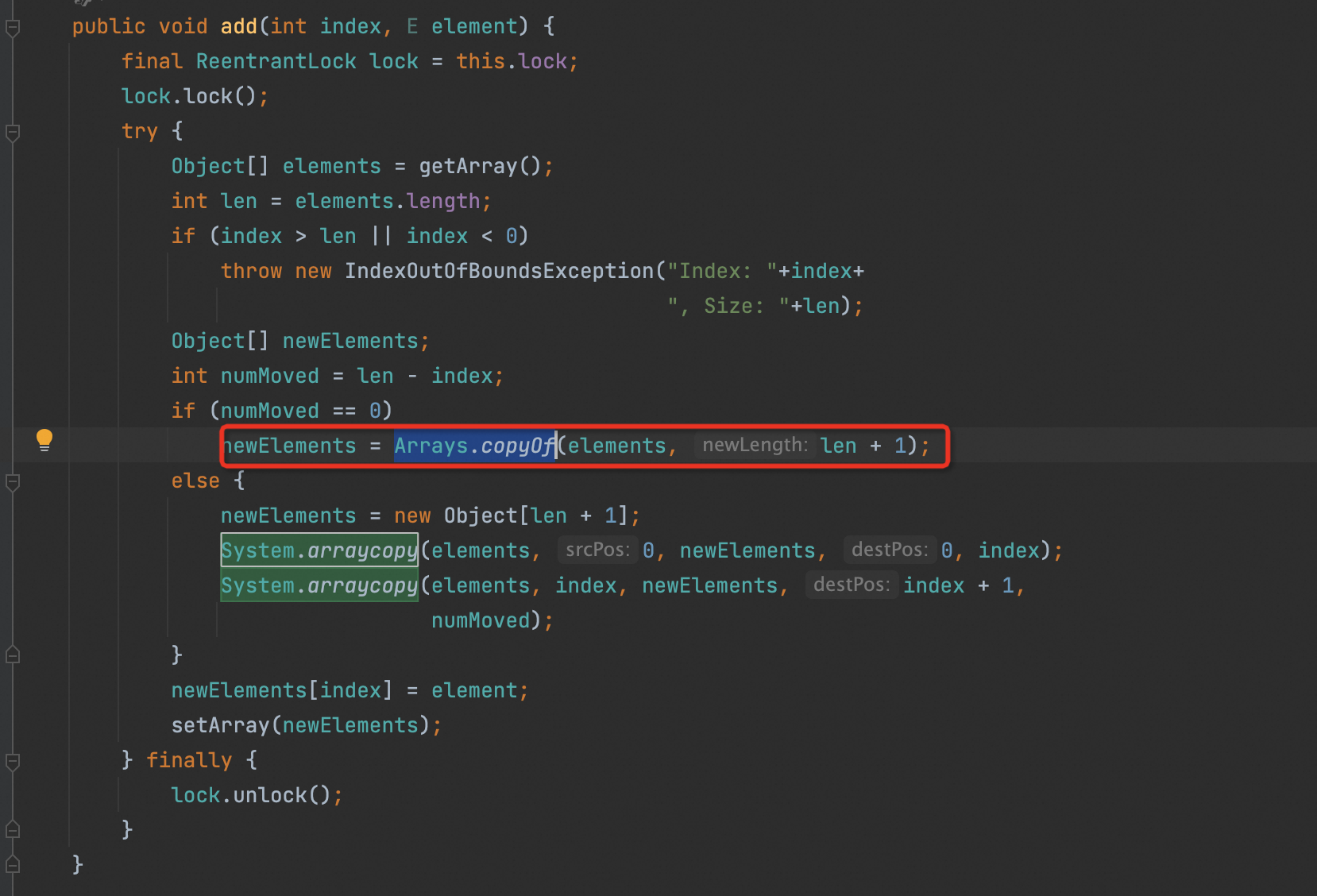
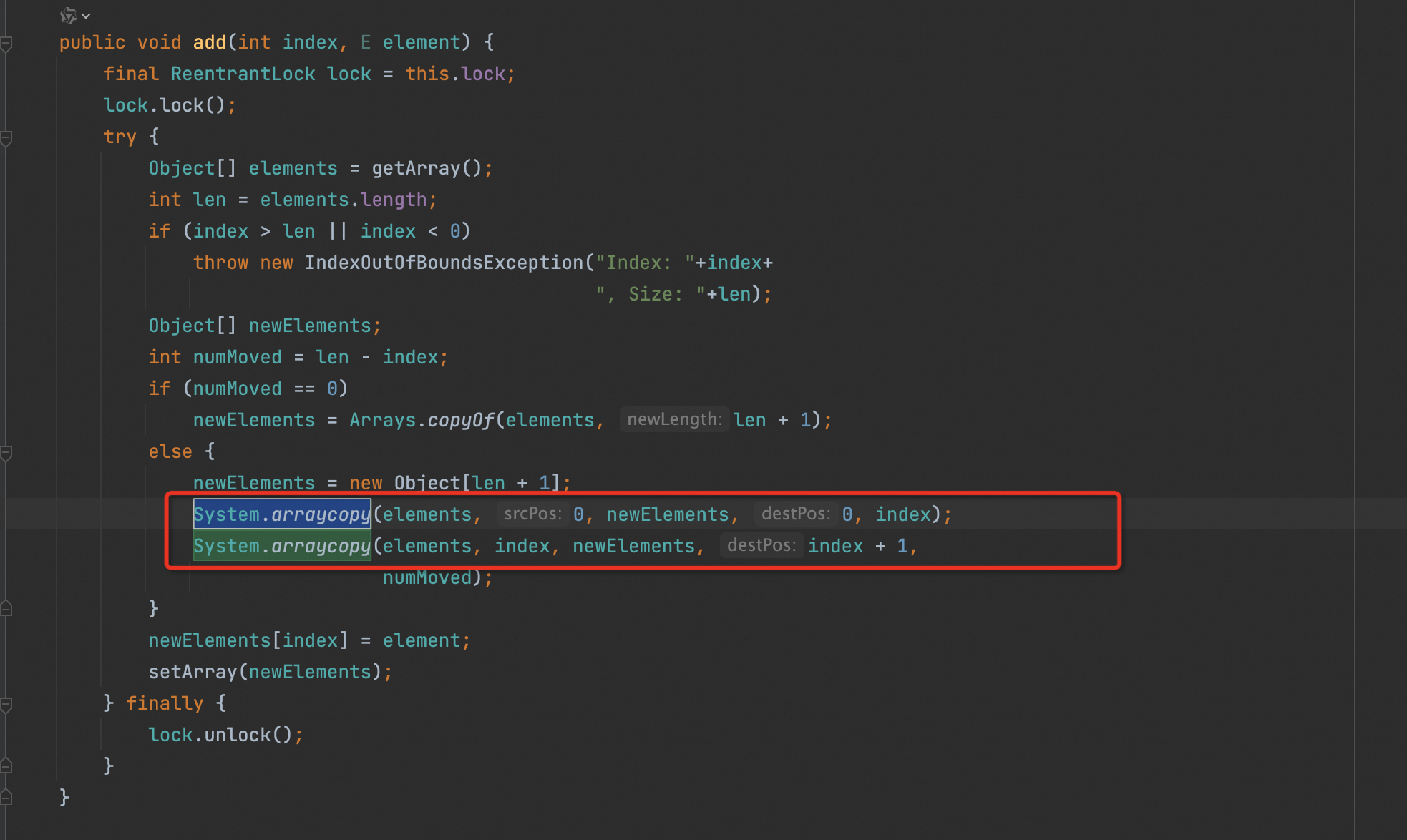
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}5、remove
ArrayList 的删除方法有两个,分别是:
- 删除某个位置的元素:remove(int index)
- 删除某个具体的元素:remove(Object o)
5.1.remove(int index)
第一个删除方法:删除某个位置的元素
// 删除某个位置的元素
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}首先做参数范围检查,接着将 index 位置后的所有元素都往前挪一位,最后减少列表大小。
删除某个特定的元素。
5.2.remove(Object o)
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}1.fastRemove
1.作用:
方法跳过边界检查,不返回删除值。
这里会有一个疑问,那就是为什么不直接复用 remove(int index) 方法,而要新写一个方法呢?答案在 fastRemove 方法的注释中已经写了,就是为了跳过边界检查,提高效率。
/*
* 用私有的方法 fastRemove 方法跳过边界检查,不返回删除值。
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}首先,遍历列表的所有元素,找到需要删除的元素索引,最后调用 fastRemove 方法删除该元素。
示例:
import java.util.ArrayList;
public class NormalRemoveExample {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
try {
// 正常删除索引为 2 的元素,会进行边界检查并返回删除的值
int removedValue = list.remove(2);
System.out.println("Removed value: " + removedValue);
System.out.println("Updated list: " + list);
// 尝试删除一个越界的索引,会抛出 IndexOutOfBoundsException
list.remove(10);
} catch (IndexOutOfBoundsException e) {
System.out.println("Error: " + e.getMessage());
}
}
} 在上述代码中,当调用 list.remove(2) 时,Java 会先检查索引 2 是否在列表的合法范围内,然后删除该索引对应的元素并返回它。
而当尝试调用 list.remove(10) 时,由于索引越界,会抛出 IndexOutOfBoundsException 异常。
2、特点:
1.跳过边界检查:
在
fastRemove方法中,没有对传入的index进行边界检查。这意味着如果调用者传入一个非法的索引(比如超出数组长度的索引),程序可能会抛出ArrayIndexOutOfBoundsException异常或者产生其他未定义的行为。这种做法的好处是可以节省边界检查的时间开销,提高方法的执行效率,但同时也要求调用者自己确保传入的索引是合法的。
2.不返回删除值:
fastRemove方法的返回类型是void,它只负责从数组中移除指定索引的元素,而不会返回被删除的元素。这样可以避免为了保存和返回删除值而进行的额外操作,进一步提高性能。
6、Fail-Fast机制
1.原理
ArrayList 在其内部使用一个称为 modCount 的计数器来跟踪集合的修改次数。当创建迭代器时,该计数器的当前值会被记录下来。在迭代过程中,若在迭代器的生命周期内发现 modCount 的值发生变化(即发生了结构性修改),则迭代器会抛出 ConcurrentModificationException。
7、内存溢出
7.1、堆内存溢出 OutOfMemoryError
1.从jvm的角度看发生的情况是:
1、动态扩展的栈内存无法满足内存分配。
2、建立新的线程没有足够内存创建栈。
2.从编码角度看发生的情况是:
1、内存中加载的数据量过于庞大,如一次从数据库取出过多数据;
2、集合类中有对对象的引用,使用完后未清空,使得JVM不能回收;
3、代码中存在死循环或循环产生过多重复的对象实体;
4、使用的第三方软件中的BUG;
5、启动参数内存值设定的过小;
3.解决方案:
1、检查代码中是否存在一次性取出大量数据
2、检查循环体、递归调用中是否有大量导致gc无法回收的对象
3、-Xms -Xmx 配置最大最小堆内存大小,默认 -Xms256m -Xmx512m
示例:
/** * 堆内存溢出 */
private static void OutOfMemoryErrorExample() {
List list = new ArrayList<>();
String str = "";
while (true) {
str += new Date().toString();
list.add(str);
}
}7.2、栈内存溢出 StackOverflowError
1.从jvm的角度看发生的情况是:
方法执行时申请不到新的空间存储(局部变量表, 操作数栈 , 动态链接 , 方法出口信息)。
2.从编码角度看发生的情况是: 一般出现在递归和循环依赖调用的代码块中。
3.解决方案:
1、检查递归和循环依赖调用的代码块,尽可能严谨。
2、-Xss 通过这个参数配置默认的jvm栈大小,这个标识即可以通过项目的配置也可以通过命令行来指定,默认 -Xss1m 或者 -Xss0.5m。
示例:
private static void StackOverflowErrorExample(int index) {
if (index != 0) {
StackOverflowErrorExample(++index);
}
}总结:
一般来说,方法在调用时发生的内存不足 会抛StackOverflowError ,发生在方法执行过程中的内存不足会抛 OutOfMemoryError、StackOverflowError(方法调用层次太深,内存不够新建栈帧),OutOfMemoryError(线程太多,内存不够新建线程),模拟内存溢出的时候可以设置jvm的启动参数,设置小点的内存量,让它尽快达到内存溢出的效果。
关于更多集合的介绍可以参考以下文章:


















 6651
6651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









