










基本理论介绍
什么是云原生
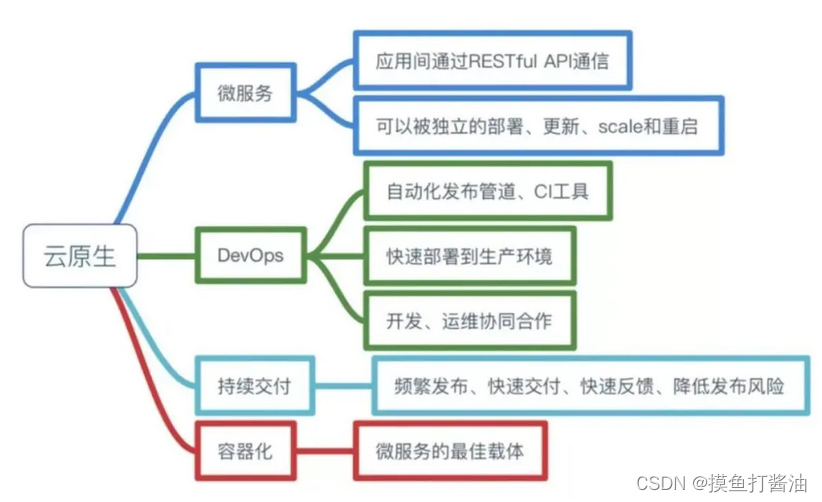
Pivotal公司的Matt Stine于2013年首次提出云原生(Cloud-Native)的概念;2015年,云原生刚推广时,Matt Stine在《迁移到云原生架构》一书中定义了符合云原生架构的几个特征:12因素、微服务、自敏捷架构、基于API协作、扛脆弱性;到了2017年,Matt Stine在接受InfoQ采访时又改了口风,将云原生架构归纳为模块化、可观察、可部署、可测试、可替换、可处理6特质;而Pivotal最新官网对云原生概括为4个要点:DevOps+持续交付+微服务+容器。
总而言之,符合云原生架构的应用程序应该是:采用开源堆栈(K8S+Docker)进行容器化,基于微服务架构提高灵活性和可维护性,借助敏捷方法、DevOps支持持续迭代和运维自动化,利用云平台设施实现弹性伸缩、动态调度、优化资源利用率。
(此处摘选自《知乎-华为云官方帐号》)
什么是kubernetes
kubernetes,简称K8s,是用8代替8个字符"ubernete"而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效,Kubernetes提供了应用部署,规划,更新,维护的一种机制。
传统的应用部署方式:是通过插件或脚本来安装应用。这样做的缺点是应用的运行、配置、管理、所有生存周期将与当前操作系统绑定,这样做并不利于应用的升级更新/回滚等操作,当然也可以通过创建虚拟机的方式来实现某些功能,但是虚拟机非常重,并不利于可移植性。
新的部署方式:是通过部署容器方式实现,每个容器之间互相隔离,每个容器有自己的文件系统 ,容器之间进程不会相互影响,能区分计算资源。相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统解耦的,所以它能在不同云、不同版本操作系统间进行迁移。
容器占用资源少、部署快,每个应用可以被打包成一个容器镜像,每个应用与容器间成一对一关系也使容器有更大优势,使用容器可以在build或release 的阶段,为应用创建容器镜像,因为每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试、生产能提供一致环境。类似地,容器比虚拟机轻量、更"透明",这更便于监控和管理。
Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
在Kubernetes中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
(此处摘选自《百度百科》)
kubernetes核心功能
- 存储系统挂载(数据卷):pod中容器之间共享数据,可以使用数据卷
- 应用健康检测:容器内服务可能进程阻塞无法处理请求,可以设置监控检查策略保证应用健壮性
- 应用实例的复制(实现pod的高可用):pod控制器(deployment)维护着pod副本数量(可以自己进行设置,默认为1),保证一个pod或一组同类的pod数量始终可用,如果pod控制器deployment当前维护的pod数量少于deployment设置的pod数量,则会自动生成一个新的pod,以便数量符合pod控制器,形成高可用。
- Pod的弹性伸缩:根据设定的指标(比如:cpu利用率)自动缩放pod副本数。
- 服务发现:使用环境变量或者DNS插件保证容器中程序发现pod入口访问地址
- 负载均衡:一组pod副本分配一个私有的集群IP地址,负载均衡转发请求到后端容器。在集群内部其他pod可通过这个clusterIP访问应用
- 滚动更新:更新服务不会发生中断,一次更新一个pod,而不是同时删除整个服务。
- 容器编排:通过文件来部署服务,使得应用程序部署变得更高效
- 资源监控:node节点组件集成cAdvisor资源收集工具,可通过Heapster汇总整个集群节点资源数据,然后存储到InfluxDb时序数据库,再由Grafana展示。
- 提供认证和授权:支持角色访问控制(RBAC)认证授权等策略
Pod控制器详解
- 从这里开始,我们使用的kubernetes版本就不是1.17.4了,而是1.21.10。不会安装的可以找到作者的《探索云原生技术之容器编排引擎-kubeadm安装kubernetes1.21.10》
Horizontal Pod Autoscaler(HPA)

概述
-
我们把Horizontal Pod Autoscaler简称为HPA,HPA到底有什么特别的地方呢?
- 我们知道Deployment这个Pod控制器可以实现扩缩容和滚动更新、版本回退等功能,而引入HPA会对Deployment进行加强,也就是说当我们Deployment和HPA一起使用的时候,Deployment的功能就会变得非常强大,会动态调整Deployment的容量。
-
不引入HPA的Deployment的缺陷:
- 我们使用的Deployment的扩缩容有个很大的缺陷,就是无法动态扩缩容。这个缺陷在生产环境下是非常致命的,因为我们的程序在生产环境下的并发量是不确定的,可能现在只有500个并发,过一会儿直接到50000个并发,然后又恢复到了几千个并发这样的场景,如果我们单单使用Deployment的话就无法控制Deployment中的Pod数量只能手动扩缩容,而手动进行扩缩容的数量很难把握,而HPA就是为了解决这个问题的。
-
引入HPA后的Deployment的强大之处:
- 引入HPA之前必须要有metrics-server来监测kubernetes集群的资源使用情况(例如CPU、内存),HPA+Deployment会不断的从metrics-server中获取资源使用情况,当这个资源使用大于我们预先定义好的一个阈值,HPA就会为Deployment自动的扩缩容,会出现并发量越大、Deployment扩容越大的情况,直到并发量逐渐减少后HPA就会为Deployment慢慢的缩容(当然这个过程并不是并发量减少一下子就让Deployment自动缩容,而是会等一段时间,在这一段时间内并发量有所减少才会慢慢的缩容,这个机制是非常好的,因为kubernetes创建Pod是需要占用一定的资源的,而且Pod的创建也是很耗时的一个因素。),这样我们在生产环境中当有了HPA+Deployment这个组合就能够支撑更大的并发量(因为会扩容),并且不会过多的浪费服务器资源(因为会缩容)。
k8s监控工具metrics-server
k8s与metrics-server版本的对应关系
- k8s和metrics-server的版本一定要符合下面的对应关系:(截止到2022/6/22日,目前metrics-server最新版为0.6.X。)
| Metrics-Server version | Supported k8s version |
|---|---|
| 0.6.x | 1.19+ |
| 0.5.x | *1.8+ |
| 0.4.x | *1.8+ |
| 0.3.x | 1.8-1.21 |
在Master节点安装监控工具metrics-server(v0.5.0)
-
metrics-server可以用来做什么?
- metrics-server可以用来监控(收集)kubernetes集群的资源使用情况!
-
注意:记住下面这些操作只在Master节点执行即可!!!!!!
如果我们不安装metrics-server的话就监测不了k8s的资源:
[root@k8s-master ~]# kubectl top pod -n kube-system
W0621 22:23:12.345730 115394 top_pod.go:140] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
error: Metrics API not available
开始安装metrics-server(v0.5.0)
- 1:创建配置文件:
vim components-v0.5.0.yaml
- 并将下面的配置复制进去:
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
- configmaps
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls
image: registry.cn-shenzhen.aliyuncs.com/zengfengjin/metrics-server:v0.5.0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
- 2:开始执行配置文件:
[root@k8s-master ~]# kubectl apply -f ./components-v0.5.0.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
- 3:查看metrics-server的pod运行状态(需要等一会儿,等到这个Pod可以正常运行!)
[root@k8s-master ~]# kubectl get pods -n kube-system| egrep 'NAME|metrics-server'
NAME READY STATUS RESTARTS AGE
metrics-server-675b4f6f66-ll474 1/1 Running 0 89s
- 4:测试kubectl top命令的使用
[root@k8s-master ~]# kubectl top pods -n kube-system
W0621 22:42:00.254069 908 top_pod.go:140] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
NAME CPU(cores) MEMORY(bytes)
calico-kube-controllers-7cc8dd57d9-fqpv7 2m 12Mi
calico-node-dvgbx 41m 70Mi
calico-node-k2qs7 42m 82Mi
calico-node-t7jbx 45m 73Mi
coredns-6f6b8cc4f6-68jmg 3m 10Mi
coredns-6f6b8cc4f6-dq5hd 3m 38Mi
etcd-k8s-master 13m 35Mi
kube-apiserver-k8s-master 65m 371Mi
kube-controller-manager-k8s-master 23m 82Mi
kube-proxy-stpdm 3m 34Mi
kube-proxy-vqm2q 4m 16Mi
kube-proxy-zb6s9 1m 18Mi
kube-scheduler-k8s-master 3m 30Mi
metrics-server-675b4f6f66-ll474 3m 11Mi
- 5:检查节点资源利用:
[root@k8s-master ~]# kubectl top nodes
W0621 22:42:22.612822 1277 top_node.go:119] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master 205m 10% 1126Mi 60%
k8s-slave01 108m 5% 962Mi 51%
k8s-slave02 108m 5% 882Mi 47%
或者下面这种格式也可以,这是官方推荐的写法:
[root@k8s-master ~]# kubectl top nodes --use-protocol-buffers
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master 228m 11% 1127Mi 60%
k8s-slave01 114m 5% 961Mi 51%
k8s-slave02 95m 4% 883Mi 47%
HPA入门
HPA的核心配置
[root@k8s-master ~]# kubectl explain HorizontalPodAutoScaler.spec
KIND: HorizontalPodAutoscaler #类型
VERSION: autoscaling/v1 #版本号
RESOURCE: spec <Object> #spec配置
FIELDS:
minReplicas: 1 #控制Deployment最少有多少个Pod(说白了就是缩容的极限,最少保留1个Pod)
maxReplicas: 10 #当高并发来了,最多能将Deployment扩容到多少个Pod(说白了就是扩容的极限,最多保留10个Pod)
targetCPUUtilizationPercentage: 5 # 监控的目标(也就是Deployment的)CPU使用率指标。注意:默认单位是%,但是不用加%号,这里的5就等于5%,超过这个占用就会自动扩容。
scaleTargetRef: #指定要控制的目标的信息(比如我们这里监控的是Deployment)
apiVersion: apps/v1 #监控对象的版本号,Deployment的版本号是apps/v1
kind: Deployment #监控对象的类型,这里我们监控的是Deployment
name: deployment-xxx # 监控对象的名称,也就是我们监控的Deployment的名称
HPA实战
案例过程:
1:首先一定要安装好metrics-server监控工具(我们采用的是metrics-server0.5.0版本,可以按照上面来进行安装,这里不再演示!)
2:
- 1:创建配置文件(包含namespace+Deployment+Service+HPA)
- 可以看到我们的Deployment没有指定replicas,而是会通过hpa自动扩缩容。
vim hpa-deployment-nginx.yaml
- 内容如下:
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: apps/v1 # 版本号
kind: Deployment # 类型
metadata: # 元数据
name: deployment-nginx # deployment的名称
namespace: test # 名称空间
spec: # 详细描述
selector: # 选择器,通过它指定Deployment可以管理哪些Pod
matchLabels: # Labels匹配规则(也就是Pod的标签)
app: pod-nginx-label
template: # 模块 当副本数据不足的时候,会根据下面的模板创建Pod副本
metadata:
labels:
app: pod-nginx-label
spec:
containers:
- name: nginx # 容器名称
image: nginx:1.19 # 容器镜像
ports:
- containerPort: 80 # 容器所监听的端口
resources: # 资源配置
requests:
cpu: "100m" #1m=1/1000核心,所以100m=(100/1000)核心、故等于10%,也可以等于0.1个CPU
---
apiVersion: v1
kind: Service
metadata:
labels:
app: service-nginx-label
name: service-nginx
namespace: test
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 31666 #指定对外暴露的端口
selector: #Pod的标签
app: pod-nginx-label
type: NodePort
---
apiVersion: autoscaling/v1 # 版本号
kind: HorizontalPodAutoscaler # 类型
metadata: # 元数据
name: hpa-nginx # hpa的名称
namespace: test # 命名空间
spec:
minReplicas: 1 #控制Deployment最少有多少个Pod(说白了就是缩容的极限,最少保留1个Pod)
maxReplicas: 10 #当高并发来了,最多能将Deployment扩容到多少个Pod(说白了就是扩容的极限,最多保留10个Pod)
targetCPUUtilizationPercentage: 5 # 监控的目标(也就是Deployment的)CPU使用率指标。注意:默认单位是%,但是不用加%号,这里的5就等于5%,超过这个占用就会自动扩容。
scaleTargetRef: #指定要控制的目标的信息(比如我们这里监控的是Deployment)
apiVersion: apps/v1 #监控对象的版本号,Deployment的版本号是apps/v1
kind: Deployment #监控对象的类型,这里我们监控的是Deployment
name: deployment-nginx # 监控对象的名称,也就是我们监控的Deployment的名称
- 3:执行配置文件:
[root@k8s-master ~]# kubectl apply -f hpa-deployment-nginx.yaml
namespace/test created
deployment.apps/deployment-nginx created
service/service-nginx created
horizontalpodautoscaler.autoscaling/hpa-nginx created
- 4:查询HPA:(在TARGETS下面可能会出现unknown字样,那是因为metrics-server正在计算当前资源占用,我们只需要过一会儿再去查询即可!)
[root@k8s-master ~]# kubectl get hpa -n test -o wide
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-nginx Deployment/deployment-nginx <unknown>/5% 1 10 1 53s
过一会儿新建一个Shell窗口进行(动态查询HPA,这次下面就没有了unknown,说明已经正常监控中):
[root@k8s-master ~]# kubectl get hpa -n test -o wide -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-nginx Deployment/deployment-nginx 0%/5% 1 10 1 4m48s
- 5:再新建一个Shell窗口进行(动态查询Deployment):
[root@k8s-master ~]# kubectl get deployments -n test -o wide -w
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment-nginx 1/1 1 1 6m36s nginx nginx:1.19 app=pod-nginx-label
- 6:打开Jmeter进行压测:(测试数据是:2500线程+4次循环=1w并发)
- IP:是本服务器的真实IP,而不是k8s提供的虚拟IP,我们本服务器的IP为192.168.184.100。
- 端口:端口为上面设置的端口,我们上面设置的端口是31666。


- 7:等一段时间再去查看HPA和Deployment:
- 可以看到HPA的REPLICAS不断扩容到了10个,然后过了好几分钟之后发现并发量不会大幅度上升之后就开始缩容了,知道Deployment的容量缩减为1个。
[root@k8s-master ~]# kubectl get hpa -n test -o wide -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-nginx Deployment/deployment-nginx 0%/5% 1 10 1 4m48s
hpa-nginx Deployment/deployment-nginx 0%/5% 1 10 1 5m16s
hpa-nginx Deployment/deployment-nginx 1%/5% 1 10 1 13m
hpa-nginx Deployment/deployment-nginx 0%/5% 1 10 1 13m
hpa-nginx Deployment/deployment-nginx 1%/5% 1 10 1 14m
hpa-nginx Deployment/deployment-nginx 0%/5% 1 10 1 14m
hpa-nginx Deployment/deployment-nginx 167%/5% 1 10 1 15m
hpa-nginx Deployment/deployment-nginx 0%/5% 1 10 4 16m
hpa-nginx Deployment/deployment-nginx 0%/5% 1 10 8 16m
hpa-nginx Deployment/deployment-nginx 2%/5% 1 10 10 16m
hpa-nginx Deployment/deployment-nginx 0%/5% 1 10 10 16m
hpa-nginx Deployment/deployment-nginx 0%/5% 1 10 10 20m
hpa-nginx Deployment/deployment-nginx 0%/5% 1 10 10 22m
hpa-nginx Deployment/deployment-nginx 0%/5% 1 10 1 22m
查看Deployment:
[root@k8s-master ~]# kubectl get deployments -n test -o wide -w
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment-nginx 1/1 1 1 6m36s nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 1/4 1 1 15m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 1/4 1 1 15m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 1/4 1 1 15m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 1/4 4 1 15m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 2/4 4 2 15m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 3/4 4 3 15m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 4/4 4 4 15m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 4/8 4 4 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 4/8 4 4 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 4/8 4 4 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 4/8 8 4 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 5/8 8 5 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 6/8 8 6 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 7/8 8 7 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 8/8 8 8 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 8/10 8 8 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 8/10 8 8 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 8/10 8 8 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 8/10 10 8 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 9/10 10 9 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 10/10 10 10 16m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 10/1 10 10 22m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 10/1 10 10 22m nginx nginx:1.19 app=pod-nginx-label
deployment-nginx 1/1 1 1 22m nginx nginx:1.19 app=pod-nginx-label
DaemonSet(DS)

概述
-
DaemonSet有什么作用?
- **DaemonSet类型的Pod控制器可以保证集群中的每一个工作节点node(或指定工作节点node)上都运行一个Pod副本。(这里所说的节点不是Master节点!)**也就是说,如果一个Pod提供的功能是节点级别的(每个节点都需要且只需要一个),那么这类Pod就适合使用DaemonSet类型的控制器创建。
-
DaemonSet的使用场景?
- 日志收集
- 节点监控
-
DaemonSet控制器的特点:
-
- 当我们往k8s集群中添加一个节点的时候,指定的Pod副本也将自动添加到该新增节点上。
-
- 当节点从k8s集群中移除后,DaemonSet所创建出来的那一个Pod也会被回收。
DaemonSet的资源清单
apiVersion: apps/v1 # 版本号
kind: DaemonSet # 类型
metadata: # 元数据
name: # 名称
namespace: #命名空间
labels: #标签
app: daemonset
spec: # 详情描述
revisionHistoryLimit: 3 # 保留历史版本
updateStrategy: # 更新策略
type: RollingUpdate # 滚动更新策略
rollingUpdate: # 滚动更新
maxUnavailable: 1 # 最大不可用状态的Pod的最大值,可用为百分比,也可以为整数
selector: # 选择器,通过它指定该控制器管理那些Pod
matchLabels: # Labels匹配规则
app: nginx-pod
matchExpressions: # Expressions匹配规则(推荐)
- key: app
operator: In
values:
- nginx-pod
template: # 模板,当副本数量不足时,会根据下面的模板创建Pod模板
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.19
ports:
- containerPort: 80
创建DaemonSet
- 1:创建配置文件:
vim podcontroller-daemonset.yaml
- 内容如下:
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: apps/v1 # 版本号
kind: DaemonSet # 类型
metadata: # 元数据
name: podcontroller-daemonset # 名称
namespace: test #命名空间
spec: # 详情描述
selector: # 选择器,通过它指定该控制器管理那些Pod
matchLabels: # Labels匹配规则
app: nginx-pod
template: # 模板,当副本数量不足时,会根据下面的模板创建Pod模板
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17
ports:
- containerPort: 80
- 2:执行配置文件:
[root@k8s-master ~]# kubectl apply -f podcontroller-daemonset.yaml
namespace/test created
daemonset.apps/podcontroller-daemonset created
查看DaemonSet
- 查询集群节点:
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 94m v1.21.10
k8s-slave01 Ready <none> 91m v1.21.10
k8s-slave02 Ready <none> 91m v1.21.10
- 查询DaemonSet:
- 可以看到我们的DaemonSet自动创建了两个容器,因为我们集群只有2个工作节点node(Master节点不算上去,因为Pod不会被调度到Master节点上。)
[root@k8s-master ~]# kubectl get DaemonSet -n test -o wide
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE CONTAINERS IMAGES SELECTOR
podcontroller-daemonset 2 2 2 2 2 <none> 55s nginx nginx:1.17 app=nginx-pod
- 查询Pod:(可以看到slave01和slave02各自都有一个DaemonSet自动创建的容器!!!)
[root@k8s-master ~]# kubectl get pods -n test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
podcontroller-daemonset-fptcj 1/1 Running 0 4m25s 10.244.220.196 k8s-slave02 <none> <none>
podcontroller-daemonset-qr5cw 1/1 Running 0 4m25s 10.244.232.65 k8s-slave01 <none> <none>
删除DaemonSet
- 方式1:用DaemonSet名称删除
[root@k8s-master ~]# kubectl delete DaemonSet podcontroller-daemonset -n test
daemonset.apps "podcontroller-daemonset" deleted
- 方式2:配置文件删除:
[root@k8s-master ~]# kubectl delete -f podcontroller-daemonset.yaml
namespace "test" deleted
daemonset.apps "podcontroller-daemonset" deleted
Job

概述
-
Job主要用于负责批量处理短暂的一次性任务。
-
Job的特点:
-
- 当Job创建的Pod执行成功结束时,Job将记录成功结束的Pod数量。
-
- 当成功结束的Pod达到指定的数量时,Job将完成执行。
Job的资源清单
apiVersion: batch/v1 # 版本号
kind: Job # 类型
metadata: # 元数据
name: # 名称
namespace: #命名空间
labels: # 标签
controller: job
spec: # 详情描述
completions: 1 # 指定Job需要成功运行Pod的总次数,默认为1
parallelism: 1 # 指定Job在任一时刻应该并发运行Pod的数量,默认为1
activeDeadlineSeconds: 30 # 指定Job可以运行的时间期限,超过时间还没结束,系统将会尝试进行终止
backoffLimit: 6 # 指定Job失败后进行重试的次数,默认为6
manualSelector: true # 是否可以使用selector选择器选择Pod,默认为false
selector: # 选择器,通过它指定该控制器管理那些Pod
matchLabels: # Labels匹配规则
app: counter-pod
matchExpressions: # Expressions匹配规则
- key: app
operator: In
values:
- counter-pod
template: # 模板,当副本数量不足时,会根据下面的模板创建Pod模板
metadata:
labels:
app: counter-pod
spec:
restartPolicy: Never # 重启策略只能设置为Never或OnFailure
containers:
- name: counter
image: busybox:1.30
command: ["/bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1;do echo $i;sleep 20;done"]
关于模板中的重启策略的说明:
-
如果设置为OnFailure,则Job会在Pod出现故障的时候重启容器,而不是创建Pod,failed次数不变。
-
如果设置为Never,则Job会在Pod出现故障的时候创建新的Pod,并且故障Pod不会消失,也不会重启,failed次数+1。
-
如果指定为Always的话,就意味着一直重启,意味着Pod任务会重复执行,这和Job的定义冲突,所以不能设置为Always。
创建Job
- 1:创建配置文件:
vim podcontroller-job.yaml
- 内容如下:
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: batch/v1 # 版本号
kind: Job # 类型
metadata: # 元数据
name: podcontroller-job # 名称
namespace: test #命名空间
spec: # 详情描述
manualSelector: true # 是否可以使用selector选择器选择Pod,默认为false
selector: # 选择器,通过它指定该控制器管理那些Pod
matchLabels: # Labels匹配规则
app: counter-pod
template: # 模板,当副本数量不足时,会根据下面的模板创建Pod模板
metadata:
labels:
app: counter-pod
spec:
restartPolicy: Never # 重启策略只能设置为Never或OnFailure
containers:
- name: counter
image: busybox:1.30
command: [ "/bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1;do echo $i;sleep 3;done" ]
- 2:新建一个shell窗口,动态查询Job:
kubectl get job -n test -w
- 3:新建一个shell窗口,动弹查询Pod:
kubectl get pods -n test -w
- 4:执行配置文件:
kubectl apply -f podcontroller-job.yaml
- 5:查看刚刚新建的两个shell窗口:
[root@k8s-master ~]# kubectl get job -n test -w
NAME COMPLETIONS DURATION AGE
podcontroller-job 0/1 0s
podcontroller-job 0/1 0s 0s
podcontroller-job 1/1 46s 46s
[root@k8s-master ~]# kubectl get pods -n test -w
NAME READY STATUS RESTARTS AGE
podcontroller-job-qfgtx 0/1 Pending 0 0s
podcontroller-job-qfgtx 0/1 Pending 0 0s
podcontroller-job-qfgtx 0/1 ContainerCreating 0 0s
podcontroller-job-qfgtx 0/1 ContainerCreating 0 1s
podcontroller-job-qfgtx 1/1 Running 0 19s
podcontroller-job-qfgtx 0/1 Completed 0 46s
podcontroller-job-qfgtx 0/1 Completed 0 46s
查看Job
[root@k8s-master ~]# kubectl get job -n test
NAME COMPLETIONS DURATION AGE
podcontroller-job 1/1 46s 65m
删除Job
[root@k8s-master ~]# kubectl delete -f podcontroller-job.yaml
namespace "test" deleted
job.batch "podcontroller-job" deleted
CronJob(CJ)

概述
-
CronJob通过控制Job,并通过Job来控制Pod资源对象,Job定义的任务在其控制器资源创建之后便会立即执行,但CronJob可以以类似Linux操作系统的周期性任务计划的方式控制器运行时间点及重复运行的方式,换言之,CronJob可以在特定的时间点反复去执行Job任务。
-
schedule:cron表达式,用于指定任务的执行时间。
-
**/1 * * * :依次表示分钟 小时 日 月份 星期。
-
分钟的值从0到59。
-
小时的值从0到23。
-
日的值从1到31。
-
月的值从1到12。
-
星期的值从0到6,0表示星期日。
-
多个时间可以用逗号隔开,范围可以用连字符给出: 可以作为通配符,/表示每…*
-
-
concurrencyPolicy:并发执行策略
-
Allow:运行Job并发运行(默认)。
-
Forbid:禁止并发运行,如果上一次运行尚未完成,则跳过下一次运行。
-
Replace:替换,取消当前正在运行的任务并使用新任务替换它。
-
CronJob资源清单
apiVersion: batch/v1 # 版本号
kind: CronJob # 类型
metadata: # 元数据
name: # 名称
namespace: #命名空间
labels:
controller: cronjob
spec: # 详情描述
schedule: # cron表达式的任务调度运行时间点,用于控制任务时间执行
concurrencyPolicy: # 并发执行策略
failedJobsHistoryLimit: # 为失败的任务执行保留的历史记录数,默认为1
successfulJobsHistoryLimit: # 为成功的任务执行保留的历史记录数,默认为3
jobTemplate: # job控制器模板,用于为cronjob控制器生成job对象,下面其实就是job的定义
metadata: {}
spec:
completions: 1 # 指定Job需要成功运行Pod的总次数,默认为1
parallelism: 1 # 指定Job在任一时刻应该并发运行Pod的数量,默认为1
activeDeadlineSeconds: 30 # 指定Job可以运行的时间期限,超过时间还没结束,系统将会尝试进行终止
backoffLimit: 6 # 指定Job失败后进行重试的次数,默认为6
template: # 模板,当副本数量不足时,会根据下面的模板创建Pod模板
spec:
restartPolicy: Never # 重启策略只能设置为Never或OnFailure
containers:
- name: counter
image: busybox:1.30
command: [ "/bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1;do echo $i;sleep 20;done" ]
创建CronJob
- 1:创建配置文件:
vim podcontroller-cronjob.yaml
- 内容:
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: batch/v1 # 版本号
kind: CronJob # 类型
metadata: # 元数据
name: podcontroller-cronjob # 名称
namespace: test #命名空间
spec: # 详情描述
schedule: "*/1 * * * * " # cron表达式的任务调度运行时间点,用于控制任务时间执行
jobTemplate: # Job控制器模板,用于为cronjob控制器生成job对象,下面其实就是job的定义
metadata: {}
spec:
template: # 模板,当副本数量不足时,会根据下面的模板创建Pod模板
spec:
restartPolicy: Never # 重启策略只能设置为Never或OnFailure
containers:
- name: counter
image: busybox:1.30
command: [ "/bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1;do echo $i;sleep 2;done" ]
- 2:执行配置文件:
[root@k8s-master ~]# kubectl apply -f podcontroller-cronjob.yaml
namespace/test created
cronjob.batch/podcontroller-cronjob created
查看CronJob
- 查看CronJob:
[root@k8s-master ~]# kubectl get cronjob -n test -w
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
podcontroller-cronjob */1 * * * * False 0 <none> 49s
podcontroller-cronjob */1 * * * * False 1 0s 51s
podcontroller-cronjob */1 * * * * False 0 19s 70s
podcontroller-cronjob */1 * * * * False 1 0s 111s
podcontroller-cronjob */1 * * * * False 0 19s 2m10s
- 查看Job:
[root@k8s-master ~]# kubectl get job -n test -w
NAME COMPLETIONS DURATION AGE
podcontroller-cronjob-27599876 1/1 19s 38s
podcontroller-cronjob-27599877 0/1 0s
podcontroller-cronjob-27599877 0/1 0s 0s
podcontroller-cronjob-27599877 1/1 19s 19s
- 查看Pod:
[root@k8s-master ~]# kubectl get pods -n test -w
NAME READY STATUS RESTARTS AGE
podcontroller-cronjob-27599876-gkvc5 1/1 Running 0 13s
podcontroller-cronjob-27599876-gkvc5 0/1 Completed 0 19s
podcontroller-cronjob-27599876-gkvc5 0/1 Completed 0 19s
podcontroller-cronjob-27599877-k9grm 0/1 Pending 0 0s
podcontroller-cronjob-27599877-k9grm 0/1 Pending 0 0s
podcontroller-cronjob-27599877-k9grm 0/1 ContainerCreating 0 0s
podcontroller-cronjob-27599877-k9grm 0/1 ContainerCreating 0 0s
podcontroller-cronjob-27599877-k9grm 1/1 Running 0 1s
podcontroller-cronjob-27599877-k9grm 0/1 Completed 0 19s
podcontroller-cronjob-27599877-k9grm 0/1 Completed 0 19s
删除CronJob
[root@k8s-master ~]# kubectl delete -f podcontroller-cronjob.yaml
namespace "test" deleted
cronjob.batch "podcontroller-cronjob" deleted
❤️💛🧡本章结束,我们下一章见❤️💛🧡















 738
738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











