







 本文介绍了如何使用Python爬取成语并实现一个成语接龙的小程序。通过爬取网站数据,建立成语数据库,并利用字符串匹配判断接龙是否成功。文章还展示了程序的交互功能和运行效果。
本文介绍了如何使用Python爬取成语并实现一个成语接龙的小程序。通过爬取网站数据,建立成语数据库,并利用字符串匹配判断接龙是否成功。文章还展示了程序的交互功能和运行效果。
成语接龙是中华民族传统的文字游戏,它有着悠久的历史,也有广泛的社会基础,是老少皆宜的民间文化娱乐活动!一般聚会时会玩这个游戏做互动,还有就是QQ有一个成语接龙红包,有时会因为自己的成语储备量不够,而接不下去。
那么大家有没有想过自己去实现一个成语接龙的程序呢?接下来,我就用Python来实现一个成语接龙小程序,废话不多说,开始~~~~
成语准备
说到成语接龙,首先就得保证拥有足够多的成语,这个条件就不满足,我没有成语哎,散会~

开玩笑,身为一个Python码农,爬个数据还是没啥子问题的,没有成语不要紧,有办法,
我发现了一个网站:chengyu.t086.com/list/A_1.ht…, 这个网站上有很多的成语及解释啥的,废话不多说,我都给它爬下来。
分析爬取思路:
通过网页抓包,分析出以下特点:每次请求都会发出:http://chengyu.t086.com/list/{A-Z}_{页码}.html这个请求,如下图,是首字母为A的第一页。
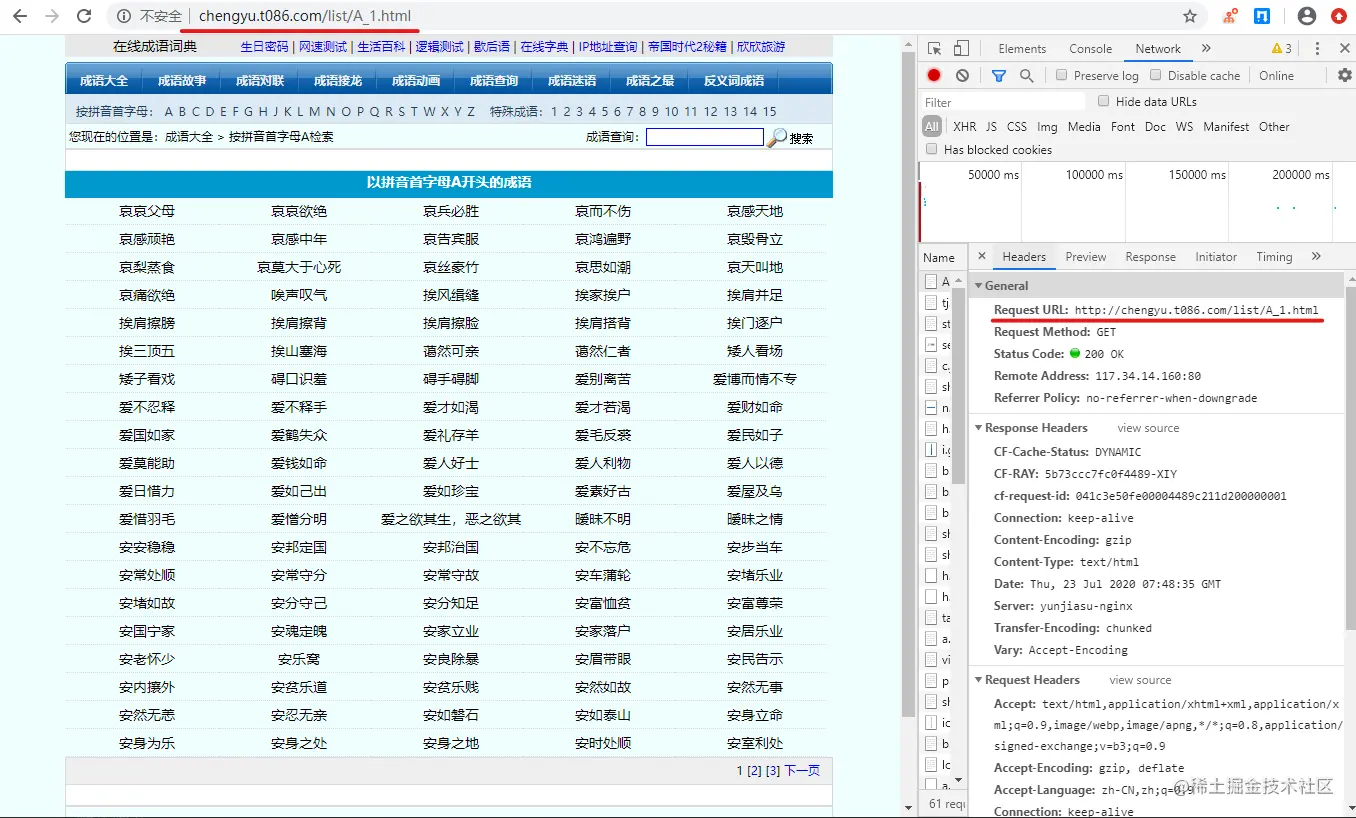
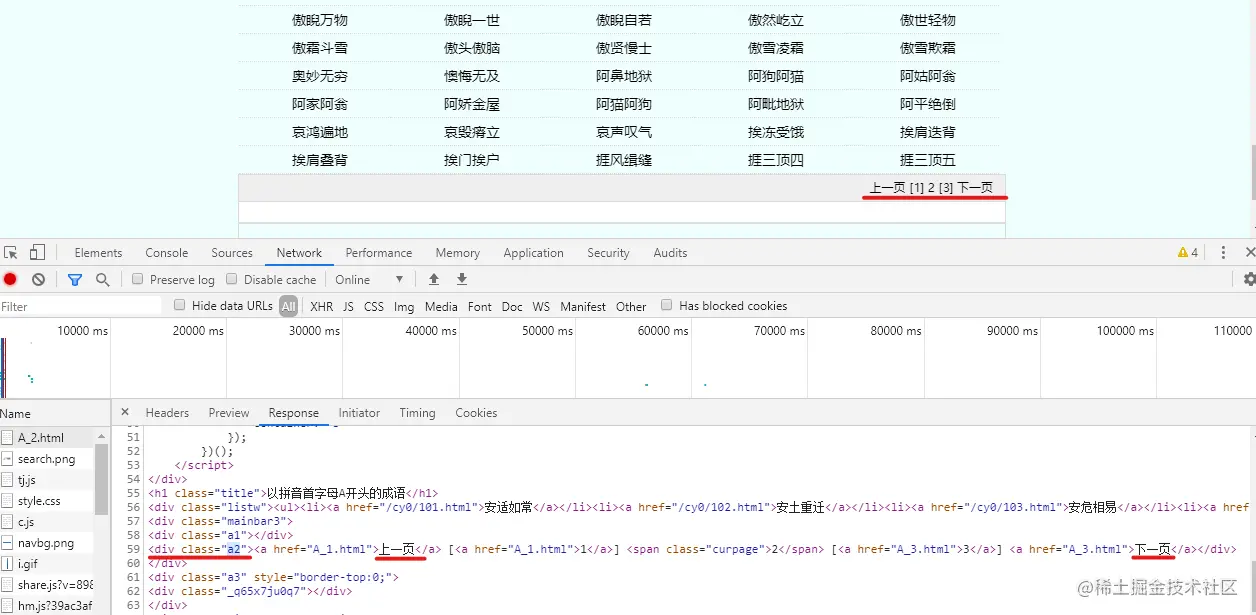
解析网页有“下一页”时,循环翻页,例如从 chengyu.t086.com/list/A_1.ht… 翻页至 chengyu.t086.com/list/A_2.ht…, 当解析网页解析不到“下一页”时,就要请求拼音首字母的下一个chengyu.t086.com/list/B_1.ht…, 依次循环下去,直至爬完。
这样就是有两层循环,第一层循环A-Z,第二层循环页码,然后拼成http://chengyu.t086.com/list/{A-Z}_{页码}.html 去请求,没有下一页时,就跳出第二层循环,循环下一个拼音首字母。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









