






论文笔记《A Simple Framework for Contrastive Learning of Visual Representations》(SimCLR)
对比学习:代理任务+目标函数。
有监督和无监督的区别:
有监督学习:模型输出的和真实label(ground truth)通过目标函数计算损失,以此进行模型训练
无监督学习或自监督学习:没有ground truth,用代理任务来定义对比学习的正负样本,再定义合适的目标函数
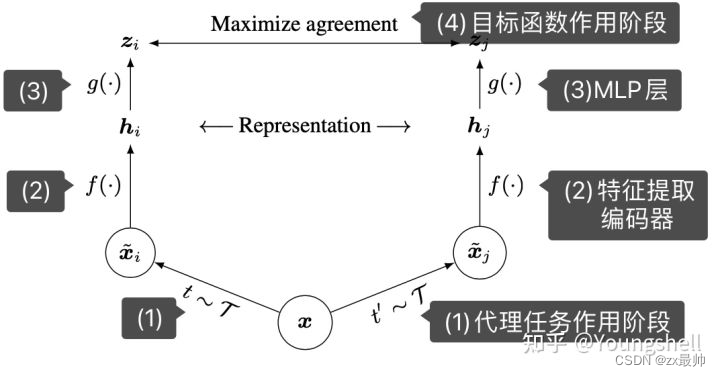
上面的框架一共包含了4部分。
(1)代理任务作用阶段。
simCLR使用数据增强手段来作为代理任务,例如图片的随机裁剪、随机颜色失真、随机高斯模糊,同一张图片的两个不同的增强结果作为一个正样本对,其他图片的增强结果作为负样本。
假设一个batch的样本数为N,通过数据增强的得到2N个样本。对于一个给定的正样本对,剩下的2(N-1)个样本都是负样本,也就是负样本都基于这个batch的数据生成。
(2)特征提取编码器。就是一个编码器,用什么编码器不做限制,SimCLR中使用的是ResNet。
(3)MLP层。通过特征提取之后,再进入MLP层,SimCLR中强调了这个MLP层加上会比不加好,MLP层的输出就是对比学习的目标函数作用的地方。
(4)目标函数作用阶段。对比学习中的损失函数一般是infoNCE loss。
其实就是计算余弦相似度,分子中只计算正样本对的距离,负样本只会在对比损失的分母中出现,当正样本对距离越小,负样本对距离越大,损失越小。















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









