






Hadoop
hdfs中小文件的处理
(1)采用har归档方式,将小文件归档
(2)采用Combine TextInputFormat
请列出正常工作的hadoop集群中hadoop都需要启动哪些进程,他们的作用分别是什么?
namenode =>HDFS的守护进程,负责维护整个文件系统,存储着整个文件系统的元数据信息,有image+edit log namenode不会持久化存储这些数据,而是在启动时重建这些数据。
datanode =>是具体文件系统的工作节点,当我们需要某个数据,namenode告诉我们去哪里找,就直接和那个DataNode对应的服务器的后台进程进行通信,由DataNode进行数据的检索,然后进行具体的读/写操作
secondarynamenode =>一个冗余的守护进程,相当于一个namenode的元数据的备份机制,定期的更新,和namenode进行通信,将namenode上的image和edits进行合并,可以作为namenode的备份使用
resourcemanager =>是yarn平台的守护进程,负责所有资源的分配与调度,client的请求由此负责,监控nodemanager
node
manager => 是单个节点的资源管理,执行来自resourcemanager的具体任务和命令
yarn的运行流程
(1)Client向ResourceManager提交作业(可以是Spark/Mapreduce作业)
(2)ResourceManager会为这个作业分配一个container
(3)ResourceManager与NodeManager通信,要求NodeManger在刚刚分配好的container上启动应用程序的Application Master
(4)Application Master先去向ResourceManager注册,而后ResourceManager会为各个任务申请资源,并监控运行情况
(5)Application Master采用轮询(polling)方式向ResourceManager申请并领取资源(通过RPC协议通信)
(6) Application Manager申请到了资源以后,就和NodeManager通信,要求NodeManager启动任务
写入HDFS过程
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client会先对文件进行切分,比如一个blok块128m,文件有300m就会被切分成3个块,一个128M、一个128M、一个44M请求第一个 block该传输到哪些datanode服务器上
4、namenode返回datanode的服务器
5、client请求一台datanode上传数据(本质上是一个RPC调用,建立pipeline),第一个datanode收到请求会继续调用第二个datanode,然后第二个调用第三个datanode,将整个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位(一个packet为64kb),当然在写入的时候datanode会进行数据校验,它并不是通过一个packet进行一次校验而是以chunk为单位进行校验(512byte),第一台datanode收到一个packet就会传给第二台,第二台传给第三台;第一台每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
HDFS读取过程
1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
hive
如何自定义UDF,UDTF函数
用UDF函数解析公共字段,用UDTF函数解析事件字段
自定义UDF:继承UDF,重写evaluate方法
自定义UDTF:继承GenericUDTF,重写3个方法,initialize(自定义输出的列名和类型),process(将结果返回forward(result)),close
Hive的窗口函数有哪些
在SQL处理中,窗口函数都是最后一步执行,仅位于order by之前
over():指定分析函数工作的数据窗口大小随行变化(跟在聚合函数 [wh2]后面,只对聚合函数有效)
current row 当前行
n preceding 往前n行数据
n following 往后n行数据
unbounded:
unbounded preceding 从前面开始 |————>
unbounded following 直到终点 ————>|
lag(col,n) 往前第n行数据
lead(col,n) 往后第n行数据
ntile(n) 把有序分区中的行分化到n个数据组中,各组的编号从1开始,ntile会返回每行所属的组编号(n为int类型)
Hive导入数据的五种方式
- Load方式,可以从本地或HDFS上导入,本地是copy,HDFS是移动
本地:load data local inpath ‘/root/student.txt’ into table student;
HDFS:load data inpath ‘/user/hive/data/student.txt’ into table student;
- Insert方式,往表里插入
insert into table student values(1,’zhanshan’);
- As select方式,根据查询结果创建表并插入数据
create table if not exists stu1 as select id,name from student;
- Location方式,创建表并指定数据的路径
create external if not exists stu2 like student location ‘/user/hive/warehouse/student/student.txt’;
- Import方式,先从hive上使用export导出在导入
import table stu3 from ‘/user/export/student’;
Hive导出数据的五种方式
- Insert方式,查询结果导出到本地或HDFS
Insert overwrite local directory ‘/root/insert/student’ select id,name from student;
Insert overwrite directory ‘/user/ insert /student’ select id,name from student;
- Hadoop命令导出本地
hive>dfs -get /user/hive/warehouse/student/ 000000_0 /root/hadoop/student.txt
- hive Shell命令导出
]$ bin/hive -e ‘select id,name from student;’ > /root/hadoop/student.txt
- Export导出到HDFS
hive> export table student to ‘/user/export/student’;
- Sqoop导出
row_number(),rank()和dense_rank()的区别
都有对数据进行排序的功能
row_number():根据查询结果的顺序计算排序,多用于分页查询
rank():排序相同时序号重复,总序数不变
dense_rank():排序相同时序号重复时,总序数减少
Hive中order by,sort by,distribute by和cluster by的区别
order by:对数据进行全局排序,只有一个reduce工作
sort by:每个mapreduce中进行排序,一般和distribute by使用,且distribute by写在sort by前面。当mapred.reduce.tasks=1时,效果和order by一样
distribute by:类似MR的Partition,对key进行分区,结合sort by实现分区排序
cluster by:当distribute by和sort by的字段相同时,可以使用cluster by代替,但cluster by只能是升序,不能指定排序规则
在生产环境中order by使用的少,容易造成内存溢出(OOM)
生产环境中distribute by和sort by用的多
hive有哪些方式保存元数据,各有哪些特点?
Hive元数据默认存储在derby数据库,不支持多客户端访问,所以需要将元数据存储在MySQL中,才支持多客户端访问。
Hive内部表和外部表的区别
存储:外部表数据由HDFS管理;内部表数据由hive自身管理
存储:外部表数据存储位置由自己指定(没有指定location则在默认地址下新建);内部表数据存储在hive.metastore.warehouse.dir(默认在/uer/hive/warehouse)
创建:被external修饰的就是外部表;没被修饰是内部表
删除:删除外部表仅仅删除元数据;删除内部表会删除元数据和存储数据
hive 行列变换
列转行 (对某列拆分,形成新列)
使用函数:lateral view explode(split(column, ‘,’)) num
行转列 (根据主键,对某列进行合并)
使用函数:concat_ws(’,’,collect_set(column))
hive如何调优
一,数据的压缩与存储格式
二、创建分区表,桶表,拆分表
三、hive参数优化
四、优化sql
五、数据倾斜
六、合并小文件
七、查看sql的执行计划
八、在脚本中并行
hive的工作流程
1.(执行查询操作)Execute Query
命令行或Web UI之类的Hive接口将查询发送给Driver(任何数据库驱动程序,如JDBC、ODBC等)以执行。
2.(获取计划任务)Get Plan
Driver借助查询编译器解析查询,检查语法和查询计划或查询需求
3.(获取元数据信息)Get Metadata
编译器将元数据请求发送到Metastore(任何数据库)。
4.(发送元数据)Send Metadata
Metastore将元数据作为对编译器的响应发送出去。
5.(发送计划任务)Send Plan
编译器检查需求并将计划重新发送给Driver。到目前为止,查询的解析和编译已经完成
6.(执行计划任务)Execute Plan
Driver将执行计划发送到执行引擎。
7.(执行Job任务)Execute Job
在内部,执行任务的过程是MapReduce Job。执行引擎将Job发送到ResourceManager,
ResourceManager位于Name节点中,并将job分配给datanode中的NodeManager。在这里,查询执行MapReduce任务.
7.1.(元数据操作)Metadata Ops
在执行的同时,执行引擎可以使用Metastore执行元数据操作。
8.(拉取结果集)Fetch Result
执行引擎将从datanode上获取结果集;
9.(发送结果集至driver)Send Results
执行引擎将这些结果值发送给Driver。
10.(driver将result发送至interface)Send Results
Driver将结果发送到Hive接口
Hbase
hbase命令行客户端操作
建表
create ‘t_user_info’,‘base_info’,‘extra_info’
表名 列族名 列族名
插入数据
put ‘表名’, ‘行键’, ‘列簇:列名’, ‘单元格单位’, 1(时间戳)
查询数据方式一:scan 扫描
scan ‘t_user_info’
查询数据方式二:get 单行数据
get ‘t_user_info’,‘001’
删除一个kv数据
delete ‘t_user_info’,‘001’,‘base_info:sex’
删除整行数据:deleteall ‘t_user_info’,‘001’
删除整个表
disable ‘t_user_info’
drop ‘t_user_info’
描述 Hbase 的 rowKey 的设计原则
- rowkey 长度原则
rowkey 是一个二进制码流,可以是任意字符串,最大长度 64kb,实际应用中一般为 10-100bytes,以 byte[] 形式保存,一般设计成定长。建议越短越好,不要超过 16 个字节, 原因如下:
数据的持久化文件 HFile 中是按照 KeyValue 存储的,如果 rowkey 过长会极大影响 HFile 的存储效率 MemStore 将缓存部分数据到内存,如果 rowkey 字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率
-
rowkey 散列原则
如果 rowkey 按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将 rowkey 的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个 RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个 RegionServer 上,这样在数据检索的时候负载会集中在个别的 RegionServer 上,造成热点问题,会降低查询效率。 -
rowkey 唯一原则
必须在设计上保证其唯一性,rowkey 是按照字典顺序排序存储的,因此, 设计 rowkey 的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
hbase如何导入数据?
- 通过HBase API进行批量写入数据;
- 使用Sqoop工具批量导数到HBase集群;
- 使用MapReduce批量导入;
- HBase BulkLoad的方式。
从hbase中读取数据
-
利用HBase的原生的API
-
HBase整合phonix,用jdbc的方式读取。
-
HBase作为一个数据源,用spark.read读取数据源。
15. HBase优化方法
1. 减少调整
减少调整这个如何理解呢?HBase中有几个内容会动态调整,如region(分区)、HFile,所以通过一些方法来减少这些会带来I/O开销的调整
2. 减少启停
数据库事务机制就是为了更好地实现批量写入,较少数据库的开启关闭带来的开销,那么HBase中也存在频繁开启关闭带来的问题。
3. 减少数据量
虽然我们是在进行大数据开发,但是如果可以通过某些方式在保证数据准确性同时减少数据量,何乐而不为呢?
4. 合理设计
在一张HBase表格中RowKey和ColumnFamily的设计是非常重要,好的设计能够提高性能和保证数据的准确性
Scala
1. scala语⾔有什么特点?什么是函数式编程?有什么优点?
- scala同时具有⾯向对象和函数式编程的多种编程范式。
- 函数式编程是一种编程范式,主要思想就是将程序写成一系列函数嵌套的形式,让程序的条例更清晰,灵活性更强。
2. 什么是scala中的闭包?
- 闭包(closure /ˈkloʊʒər/)
- 闭包就是能够读取其他函数内部变量的函数。
val a = 3
def add(b:Int) = a + b
// add就是是一个闭包COPY
3. 什么是scala中的纯函数?有什么好处?
- 是什么
- 纯函数(Pure Function /pjʊr/ /ˈfʌŋkʃn/)所有的输入通过参数传递到函数内部,所有的输出通过返回值传递到函数外部;
- 闭包或者带有打印语句的函数为非纯函数。
- 好处
- 无状态,线程安全,不需要线程同步;
- 纯函数相互调用组装起来的函数,还是纯函数;
- 应用程序或者运行环境(Runtime)可以对纯函数的运算结果进行缓存,运算加快速度。
//纯函数 输入都来自参数 输出都通过返回值
def f1(a:Int,b:Int) = a + b
//非纯函数
val x = 1
// 输入变量x不是通过参数输入
def f2(y:Int) = x + y
// 除了返回值还包含打印语句
def f3(x:Int) = {
println(x)
x+1
}COPY
4. 什么是scala中的模式匹配?
- 类似java中的swich-case;
- scala的模式匹配包括了⼀系列的匹配选项,匹配选项以关键字case为单位,每个匹配选项包括⼀个模式或多个表达式,如果匹配成功将执行或返回=>后面的表达式;
val x:Any = 1
val res = x match {
case x:Int => "这是一个Int"
case x:String => "这是一个String"
case _ => "这是一个非Int,非String的对象"
}COPY
5. case class和class的区别
- case class是一个样例类;
- 样例类默认将主构造器的参数使用val声明,即作为类的成员属性;
- 样例类默认添加伴生对象和全参的apply方法,方便对象构建;
- 样例类默认添加伴生对象和全参的unapply方法,方便模式匹配和属性提取;
- 样例类默认实现了toString,equals,hashcode,copy⽅法;
- class是一个不具有上述样例类特点的普通类
6. 什么是scala中的隐式转换
- scala中通过implicit关键字修饰的变量、函数或者类,在调用时,不用显式书写调用过程的一种语法。
7. 什么是scala中的伴生类和伴生对象
- 在scala中,object与class名字完全相同,且声明在同一个scala源代码文件中,那么该对象被称为该类的伴⽣对象,该类被称为该对象的伴⽣类;
- 伴⽣对象和伴⽣类可以互相访问其私有成员。
8. scala和java的区别
| 区别 | Scala | Java |
|---|---|---|
| 变量声明 | scala:使用var或val声明,类型可以省略不写,编译器通过赋值自动推断类型 | 需要在变量前明确声明变量类型 |
| 返回值 | 可以省略return关键字,编译器根据代码块最后一行自动返回 | 需要显式使用return关键字 |
| 结束符 | 非必要使⽤分号作为结束符 | 必须使用分号作为语句结束符 |
| 循环 | for中可以使用守卫,但没有continue和break关键字 | 没有守卫语法有continue和break关键字 |
| 通配符 | _ | * |
| 构造器 | 主构造器直接跟在类的声明之后,辅助构造器命名为this,辅助构造器必须直接或间接调用主构造器 | 构造器名称与类名一致 |
| 内部类 | scala实例化的内部类是不同的,可以使⽤类型投影,例如 Outer#Inner表示Outer的Inner类 | 内部类从属于外部类 |
| 接口 | scala中接口称为特质(trait),特质中可以写抽象⽅法,也可以写具体的⽅法。且类可以实现多个特质;特质中未被实现的⽅法默认就是抽象的;⼦类的实现或继承统⼀使⽤extends关键字,如需实现或继承多个使⽤with关键字拼接;特质中可以有构造器特质可以继承普通的类,并且这个类称为所有继承trait的⽗类 | java中的接口(interface),接口中的⽅法只能是抽象⽅法,不可以写具体包含⽅法体的⽅法;接口中不能有抽象的属性,且属性的修饰符都是public static final;类实现接口需要使⽤implements关键字,实现多个接口,需要⽤逗号隔开;接口中不可以有构造器;接口不可以继承普通的类 |
| 赋值 | scala中的赋值语句返回结果是unit,不可以串联,例如x=y=1,x没有被赋值为1 | x=y=1,这样没问题 |
9. 什么是scala的高阶函数
- 一个函数作为其他函数的参数
- 一个函数作为其他函数的返回值
//例如
//函数作为参数
def f1(f:Int => Int,x:Int) ={
f(x)
}
//函数作为返回值
def f1(x:Int) : Int => Int ={
(y:Int) => x + y
}COPY
10. 隐式参数使用的优先顺序是什么
- 当前类声明的implicits ;
- 导入包中的 implicits;
- 外部域(声明在外部域的implicts);
- 继承的父类中的;
- 所属包对象中的;
- 伴生对象的以上作用域。
11. Option类型的定义和使用场景?
- 在Java中, null是⼀个关键字,不是⼀个对象,当开发者希望返回⼀个空对象时,却返回了⼀个关键字,为了解决这个问题, Scala建议开发者返回值是空值时,使⽤Option类型,在Scala中null是Null的唯⼀对象,会引起异常, Option则可以避免。 Option有两个⼦类型, Some和None(空值)。
12. Unit类型是什么?
- Unit代表没有任何意义的值类型,类似于java中的void类型,他是anyval的⼦类型,仅有⼀个实例对象"( )"
13. Scala类型系统中Nil, Null, None, Nothing四个类型的区别?
- Null是⼀个trait(特质),是所以引⽤类型AnyRef的⼀个⼦类型, null是Null唯⼀的实例。
- Nothing也是⼀个trait(特质),是所有类型Any(包括值类型和引⽤类型)的⼦类型,它不在有⼦类型,它也没有实例,实际上为了⼀个⽅法抛出异常,通常会设置⼀个默认返回类型。
- Nil代表⼀个List空类型,等同List[Nothing]。
- None是Option的一个实例,代表空结果集的返回。
讲解Scala伴生对象和伴生类
单例对象与类同名时,这个单例对象被称为这个类的伴生对象,而这个类被称为这个单例对象的伴生类。伴生类和伴生对象要在同一个源文件中定义,伴生对象和伴生类可以互相访问其私有成员。不与伴生类同名的单例对象称为孤立对象。
import scala.collection.mutable.Map
class ChecksumAccumulator {
private var sum = 0
def add(b: Byte) {
sum += b
}
def checksum(): Int = ~(sum & 0xFF) + 1
}
object ChecksumAccumulator {
private val cache = Map[String, Int]()
def calculate(s: String): Int =
if (cache.contains(s))
cache(s)
else {
val acc = new ChecksumAccumulator
for (c <- s)
acc.add(c.toByte)
val cs = acc.checksum()
cache += (s -> cs)
println("s:"+s+" cs:"+cs)
cs
}
def main(args: Array[String]) {
println("Java 1:"+calculate("Java"))
println("Java 2:"+calculate("Java"))
println("Scala :"+calculate("Scala"))
}
}
Scala里trait有什么功能,与class有何异同?什么时候用trait什么时候该用class
它可以被继承,而且支持多重继承,其实它更像我们熟悉的接口(interface),但它与接口又有不同之处是:
trait中可以写方法的实现,interface不可以(java8开始支持接口中允许写方法实现代码了),这样看起来trait又很像抽象类
18、Scala 语法中to 和 until有啥区别
to 包含上界,until不包含上界
Spark
RDD机制
- 分布式弹性数据集,简单的理解成一种数据结构,是spark框架上的通用货币
- 所有算子都是基于rdd来执行的
- rdd执行过程中会形成dag图,然后形成lineage保证容错性等
- 从物理的角度来看rdd存储的是block和node之间的映射
RDD的弹性表现在哪几点?
- 自动的进行内存和磁盘的存储切换;
- 基于Lingage的高效容错;
- task如果失败会自动进行特定次数的重试;
- stage如果失败会自动进行特定次数的重试,而且只会计算失败的分片;
- checkpoint和persist,数据计算之后持久化缓存
- 数据调度弹性,DAG TASK调度和资源无关
- 数据分片的高度弹性,a.分片很多碎片可以合并成大的,b.par
Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?
在我们的开发过程中,能避免则尽可能避免使用 reduceByKey、join、distinct、repartition 等会进行 shuffle 的算子,尽量使用 map 类的非 shuffle 算子。这样的话,没有 shuffle 操作或者仅有较少 shuffle 操作的 Spark 作业,可以大大减少性能开销。
哪些spark算子会有shuffle?
- 去重,distinct
- 排序,groupByKey,reduceByKey等
- 重分区,repartition,coalesce
- 集合或者表操作,interection,join
spark有哪些组件
- master:管理集群和节点,不参与计算。
- worker:计算节点,进程本身不参与计算,和master汇报。
- Driver:运行程序的main方法,创建spark context对象。
- spark context:控制整个application的生命周期,包括dagsheduler和task scheduler等组件。
- client:用户提交程序的入口。
什么是shuffle,以及为什么需要shuffle?
- shuffle中文翻译为洗牌,需要shuffle的原因是:某种具有共同特征的数据汇聚到一个计算节点上进行计算
- Spark shuffle 处于一个宽依赖,可以实现类似混洗的功能,将相同的 Key 分发至同一个 Reducer上进行处理。
为什么要进行序列化
- 减少存储空间,高效存储和传输数据,缺点:使用时需要反序列化,非常消耗CPU
Spark提交你的jar包时所用的命令是什么?
- spark-submit
reduceByKey与groupByKey的区别,哪一种更具优势?
reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v]。
groupByKey:按照key进行分组,直接进行shuffle
所以,在实际开发过程中,reduceByKey比groupByKey,更建议使用。但是需要注意是否会影响业务逻辑。
spark的运行流程
1.Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
2.ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
3.Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
4.一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
5.Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6.应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
spark作业执行流程
- 设置环境变量spark.local.dir和spark.ui.port。NodeManager启动ApplicationMaster的时候会传递LOCAL_DIRS(YARN_LOCAL_DIRS)变量,这个变量会被设置为spark.local.dir的值。后续临时文件会存放在此目录下。
- 获取NodeManager传递给ApplicationMaster的appAttemptId。
- 创建AMRMClient,即ApplicationMaster与ResourceManager的通信连接。
- 启动用户程序,startUserClass(),使用一个线程通过发射调用用户程序的main方法。这时候,用户程序中会初始化SparkContext,它包含DAGScheduler和TaskScheduler。
- 向ResourceManager注册。
- 向ResourceManager申请containers,它根据输入数据和请求的资源,调度Executor到相应的NodeManager上,这里的调度算法会考虑输入数据的locality。
spark开发调优
(1)避免创建重复的RDD
(2)尽可能复用同一个RDD
(3)对多次使用的RDD进行持久化
(4)尽量避免使用shuffle类算子
(5)使用map-side预聚合功能的shuffle类算子
(6)使用高性能的算子
使用mapPartitions替代普通map
使用foreachPartitions替代foreach
使用filter之后进行coalesce操作
使用repartitionAndSortWithinPartitions替代repartition与sort类操作
(7)广播大变量
(8)使用Kryo优化序列化性能
Kryo序列化机制,一旦启用以后,会生效的几个地方:
1、算子函数中使用到的外部变量,使用Kryo以后:优化网络传输的性能,可以优化集群中内存的占用和消耗
2、持久化RDD,StorageLevel.MEMORY_ONLY_SER优化内存的占用和消耗;持久化RDD占用的内存越少,task执行的时候,创建的对象,就不至于频繁的占满内存,频繁发生GC。
3、shuffle:可以优化网络传输的性能。
(9)优化数据结构
(10)数据本地化
简述Spark的宽窄依赖,以及Spark如何划分stage,每个stage又根据什么决定task个数?
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)
那Stage是如何划分的呢?
根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
每个stage又根据什么决定task个数?
Stage是一个TaskSet,将Stage根据分区数划分成一个个的Task。
task有几种类型?2种
- resultTask类型,最后一个task
- shuffleMapTask类型,除了最后一个task都是
简述 SparkSQL 中 RDD、 DataFrame、 DataSet 三者的区别与联系? (笔试重点)
1) RDD
优点:
编译时类型安全
编译时就能检查出类型错误
面向对象的编程风格
直接通过类名点的方式来操作数据
缺点:
序列化和反序列化的性能开销,无论是集群间的通信, 还是 IO 操作都需要对对象的结构和数据进行序列化和反序列化。
GC 的性能开销,频繁的创建和销毁对象, 势必会增加 GC
2) DataFrame
DataFrame 引入了 schema 和 off-heap
schema : RDD 每一行的数据, 结构都是一样的,这个结构就存储在 schema 中。 Spark 通过 schema 就能够读懂数据, 因此在通信和 IO 时就只需要序列化和反序列化数据, 而结构的部分就可以省略了。
3) DataSet
DataSet 结合了 RDD 和 DataFrame 的优点,并带来的一个新的概念 Encoder。当序列化数据时, Encoder 产生字节码与 off-heap 进行交互,能够达到按需访问数据的效果,而不用反序列化整个对象。 Spark 还没有提供自定义 Encoder 的 API,但是未来会加入。
简述 SparkStreaming 窗口函数的原理(重点)
窗口函数就是在原来定义的 SparkStreaming 计算批次大小的基础上再次进行封装,
每次计算多个批次的数据,同时还需要传递一个滑动步长的参数,用来设置当次计算任务
完成之后下一次从什么地方开始计算。
图中 time1 就是 SparkStreaming 计算批次大小,虚线框以及实线大框就是窗口的大
小,必须为批次的整数倍。虚线框到大实线框的距离(相隔多少批次),就是滑动步长
Flink
1、公司怎么提交的实时任务,有多少 Job Manager?
解答: 1. 我们使用 yarn session 模式提交任务。每次提交都会创建一个新的
Flink 集群,为每一个 job 提供一个 yarn-session,任务之间互相独立,互不影响,
方便管理。任务执行完成之后创建的集群也会消失。线上命令脚本如下:
bin/yarn-session.sh -n 7 -s 8 -jm 3072 -tm 32768 -qu root.*.* -nm *-* -d
其中申请 7 个 taskManager,每个 8 核,每个 taskmanager 有 32768M 内存。2. 集群默认只有一个 Job Manager。但为了防止单点故障,我们配置了高可用。
我们公司一般配置一个主 Job Manager,两个备用 Job Manager,然后结合
ZooKeeper 的使用,来达到高可用。
2、怎么做压力测试和监控?
解答:我们一般碰到的压力来自以下几个方面:
一,产生数据流的速度如果过快,而下游的算子消费不过来的话,会产生背压。
背压的监控可以使用 Flink Web UI(localhost:8081) 来可视化监控,一旦报警就能知
道。一般情况下背压问题的产生可能是由于 sink 这个 操作符没有优化好,做一下
优化就可以了。比如如果是写入 ElasticSearch, 那么可以改成批量写入,可以调
大 ElasticSearch 队列的大小等等策略。二,设置 watermark 的最大延迟时间这个参数,如果设置的过大,可能会造成
内存的压力。可以设置最大延迟时间小一些,然后把迟到元素发送到侧输出流中去。
晚一点更新结果。或者使用类似于 RocksDB 这样的状态后端, RocksDB 会开辟
堆外存储空间,但 IO 速度会变慢,需要权衡。三,还有就是滑动窗口的长度如果过长,而滑动距离很短的话,Flink 的性能
会下降的很厉害。我们主要通过时间分片的方法,将每个元素只存入一个“重叠窗
口”,这样就可以减少窗口处理中状态的写入
3、为什么使用 Flink 替代 Spark?
解答:主要考虑的是 flink 的低延迟、高吞吐量和对流式数据应用场景更好的支
持;另外,flink 可以很好地处理乱序数据,而且可以保证 exactly-once 的状态一致
性。
4.Flink 的 checkpoint 存在哪里?
解答:可以是内存,文件系统,或者 RocksDB。
5、如果下级存储不支持事务,Flink 怎么保证 exactly-once?
解答:端到端的 exactly-once 对 sink 要求比较高,具体实现主要有幂等写入和
事务性写入两种方式。幂等写入的场景依赖于业务逻辑,更常见的是用事务性写入。
而事务性写入又有预写日志(WAL)和两阶段提交(2PC)两种方式。
如果外部系统不支持事务,那么可以用预写日志的方式,把结果数据先当成状
态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统。
6、说一下 Flink 状态机制?
解答:Flink 内置的很多算子,包括源 source,数据存储 sink 都是有状态的。在
Flink 中,状态始终与特定算子相关联。Flink 会以 checkpoint 的形式对各个任务的
状态进行快照,用于保证故障恢复时的状态一致性。Flink 通过状态后端来管理状态
和 checkpoint 的存储,状态后端可以有不同的配置选择。
7、海量 key 去重
解答:使用类似于 scala 的 set 数据结构或者 redis 的 set 显然是不行的,
因为可能有上亿个 Key,内存放不下。所以可以考虑使用布隆过滤器(Bloom Filter)
来去重。
8、checkpoint 与 spark 比较
解答:spark streaming 的 checkpoint 仅仅是针对 driver 的故障恢复做了数据
和元数据的 checkpoint。而 flink 的 checkpoint 机制 要复杂了很多,它采用的是
轻量级的分布式快照,实现了每个算子的快照,及流动中的数据的快照。
**9、**watermark 机制
解答:Watermark 本质是 Flink 中衡量 EventTime 进展的一个机制,主要用来处
理乱序数据。
**10、**exactly-once 如何实现
Exactly-Once是指发送到消息系统的消息只能被消费端处理且仅处理一次,即使生产端重试消息发送导致某消息重复投递,该消息在消费端也只被消费一次。
解答:Flink 依靠 checkpoint 机制来实现 exactly-once 语义,如果要实现端到端
的 exactly-once,还需要外部 source 和 sink 满足一定的条件。状态的存储通过状态
后端来管理,Flink 中可以配置不同的状态后端。
**11、**Flink CEP 编程中当状态没有到达的时候会将数据保存在哪里?
解答:在流式处理中,CEP 当然是要支持 EventTime 的,那么相对应的也要
支持数据的迟到现象,也就是 watermark 的处理逻辑。CEP 对未匹配成功的事件序
列的处理,和迟到数据是类似的。在 Flink CEP 的处理逻辑中,状态没有满足的和
迟到的数据,都会存储在一个 Map 数据结构中,也就是说,如果我们限定判断事件
序列的时长为 5 分钟,那么内存中就会存储 5 分钟的数据,这在我看来,也是对内
存的极大损伤之一。
**12、**三种时间语义
解答:
1. Event Time:这是实际应用最常见的时间语义,具体见文档第七章。
2. Processing Time:没有事件时间的情况下,或者对实时性要求超高的情况下。
3. Ingestion Time:存在多个 Source Operator 的情况下,每个 Source Operator
可以使用自己本地系统时钟指派 Ingestion Time。后续基于时间相关的各种操作,
都会使用数据记录中的 Ingestion Time。
13、数据高峰的处理
解答:使用大容量的 Kafka 把数据先放到消息队列里面作为数据源,再使用
Flink 进行消费,不过这样会影响到一点实时性。
**14、**Flink是如何做容错的?
Flink 实现容错主要靠强大的CheckPoint机制和State机制。Checkpoint 负责定时制作分布式快照、对程序中的状态进行备份;State 用来存储计算过程中的中间状态。
15、Flink有没有重启策略?说说有哪几种?
- 固定延迟重启策略(Fixed Delay Restart Strategy)
- 故障率重启策略(Failure Rate Restart Strategy)
- 没有重启策略(No Restart Strategy)
- Fallback重启策略(Fallback Restart Strategy)
16、说说Flink中的状态存储?
Flink在做计算的过程中经常需要存储中间状态,来避免数据丢失和状态恢复。选择的状态存储策略不同,会影响状态持久化如何和 checkpoint 交互。
Flink提供了三种状态存储方式:MemoryStateBackend、FsStateBackend、RocksDBStateBackend。
17、Flink 中的时间有哪几类?
Flink 中的时间和其他流式计算系统的时间一样分为三类:事件时间,摄入时间,处理时间三种。
如果以 EventTime 为基准来定义时间窗口将形成EventTimeWindow,要求消息本身就应该携带EventTime。
如果以 IngesingtTime 为基准来定义时间窗口将形成 IngestingTimeWindow,以 source 的systemTime为准。
如果以 ProcessingTime 基准来定义时间窗口将形成 ProcessingTimeWindow,以 operator 的systemTime 为准。
18、Flink 中水印是什么概念,起到什么作用?
Watermark 是 Apache Flink 为了处理 EventTime 窗口计算提出的一种机制, 本质上是一种时间戳。一般来讲Watermark经常和Window一起被用来处理乱序事件。
19、Flink 分布式快照的原理是什么?
Flink的分布式快照是根据Chandy-Lamport算法量身定做的。简单来说就是持续创建分布式数据流及其状态的一致快照。
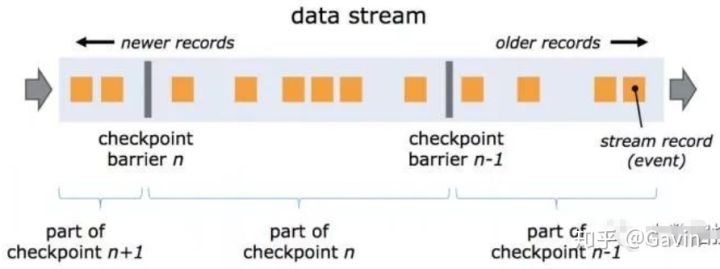
核心思想是在 input source 端插入 barrier,控制 barrier 的同步来实现 snapshot 的备份和 exactly-once 语义。
20、Flink 是如何保证Exactly-once语义的?
Flink通过实现两阶段提交和状态保存来实现端到端的一致性语义。分为以下几个步骤:
- 开始事务(beginTransaction)创建一个临时文件夹,来写把数据写入到这个文件夹里面
- 预提交(preCommit)将内存中缓存的数据写入文件并关闭
- 正式提交(commit)将之前写完的临时文件放入目标目录下。这代表着最终的数据会有一些延迟
- 丢弃(abort)丢弃临时文件
若失败发生在预提交成功后,正式提交前。可以根据状态来提交预提交的数据,也可删除预提交的数据。
21、Flink 的 kafka 连接器有什么特别的地方?
Flink源码中有一个独立的connector模块,所有的其他connector都依赖于此模块,Flink 在1.9版本发布的全新kafka连接器,摒弃了之前连接不同版本的kafka集群需要依赖不同版本的connector这种做法,只需要依赖一个connector即可。
22、说说 Flink的内存管理是如何做的?
Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上。此外,Flink大量的使用了堆外内存。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。Flink 为了直接操作二进制数据实现了自己的序列化框架。
理论上Flink的内存管理分为三部分:
- Network Buffers:这个是在TaskManager启动的时候分配的,这是一组用于缓存网络数据的内存,每个块是32K,默认分配2048个,可以通过“taskmanager.network.numberOfBuffers”修改
- Memory Manage pool:大量的Memory Segment块,用于运行时的算法(Sort/Join/Shuffle等),这部分启动的时候就会分配。下面这段代码,根据配置文件中的各种参数来计算内存的分配方法。(heap or off-heap,这个放到下节谈),内存的分配支持预分配和lazy load,默认懒加载的方式。
- User Code,这部分是除了Memory Manager之外的内存用于User code和TaskManager本身的数据结构。
23、说说 Flink的序列化如何做的?
Java本身自带的序列化和反序列化的功能,但是辅助信息占用空间比较大,在序列化对象时记录了过多的类信息。
Apache Flink摒弃了Java原生的序列化方法,以独特的方式处理数据类型和序列化,包含自己的类型描述符,泛型类型提取和类型序列化框架。
TypeInformation 是所有类型描述符的基类。它揭示了该类型的一些基本属性,并且可以生成序列化器。TypeInformation 支持以下几种类型:
- BasicTypeInfo: 任意Java 基本类型或 String 类型
- BasicArrayTypeInfo: 任意Java基本类型数组或 String 数组
- WritableTypeInfo: 任意 Hadoop Writable 接口的实现类
- TupleTypeInfo: 任意的 Flink Tuple 类型(支持Tuple1 to Tuple25)。Flink tuples 是固定长度固定类型的Java Tuple实现
- CaseClassTypeInfo: 任意的 Scala CaseClass(包括 Scala tuples)
- PojoTypeInfo: 任意的 POJO (Java or Scala),例如,Java对象的所有成员变量,要么是 public 修饰符定义,要么有 getter/setter 方法
- GenericTypeInfo: 任意无法匹配之前几种类型的类
针对前六种类型数据集,Flink皆可以自动生成对应的TypeSerializer,能非常高效地对数据集进行序列化和反序列化。
24、Flink中的Window出现了数据倾斜,你有什么解决办法?
window产生数据倾斜指的是数据在不同的窗口内堆积的数据量相差过多。本质上产生这种情况的原因是数据源头发送的数据量速度不同导致的。出现这种情况一般通过两种方式来解决:
- 在数据进入窗口前做预聚合
- 重新设计窗口聚合的key
25、Flink中在使用聚合函数 GroupBy、Distinct、KeyBy 等函数时出现数据热点该如何解决?
数据倾斜和数据热点是所有大数据框架绕不过去的问题。处理这类问题主要从3个方面入手:
(1)在业务上规避这类问题
例如一个假设订单场景,北京和上海两个城市订单量增长几十倍,其余城市的数据量不变。这时候我们在进行聚合的时候,北京和上海就会出现数据堆积,我们可以单独数据北京和上海的数据。
(2)Key的设计上
把热key进行拆分,比如上个例子中的北京和上海,可以把北京和上海按照地区进行拆分聚合。
(3)参数设置
Flink 1.9.0 SQL(Blink Planner) 性能优化中一项重要的改进就是升级了微批模型,即 MiniBatch。原理是缓存一定的数据后再触发处理,以减少对State的访问,从而提升吞吐和减少数据的输出量。
26、Flink任务延迟高,想解决这个问题,你会如何入手?
在Flink的后台任务管理中,我们可以看到Flink的哪个算子和task出现了反压。最主要的手段是资源调优和算子调优。资源调优即是对作业中的Operator的并发数(parallelism)、CPU(core)、堆内存(heap_memory)等参数进行调优。作业参数调优包括:并行度的设置,State的设置,checkpoint的设置。
27、Flink是如何处理反压的?
Flink 内部是基于 producer-consumer 模型来进行消息传递的,Flink的反压设计也是基于这个模型。Flink 使用了高效有界的分布式阻塞队列,就像 Java 通用的阻塞队列(BlockingQueue)一样。下游消费者消费变慢,上游就会受到阻塞。
28、Flink的反压和Strom有哪些不同?
Storm 是通过监控 Bolt 中的接收队列负载情况,如果超过高水位值就会将反压信息写到 Zookeeper ,Zookeeper 上的 watch 会通知该拓扑的所有 Worker 都进入反压状态,最后 Spout 停止发送 tuple。
Flink中的反压使用了高效有界的分布式阻塞队列,下游消费变慢会导致发送端阻塞。
二者最大的区别是Flink是逐级反压,而Storm是直接从源头降速。
29、Operator Chains(算子链)这个概念你了解吗?
为了更高效地分布式执行,Flink会尽可能地将operator的subtask链接(chain)在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。这就是我们所说的算子链。
30、Flink什么情况下才会把Operator chain在一起形成算子链?
两个operator chain在一起的的条件:
- 上下游的并行度一致
- 下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
- 上下游节点都在同一个 slot group 中(下面会解释 slot group)
- 下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
- 上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
- 两个节点间数据分区方式是 forward(参考理解数据流的分区)
- 用户没有禁用 chain
31、说说Flink1.9的新特性?
- 支持hive读写,支持UDF
- Flink SQL TopN和GroupBy等优化
- Checkpoint跟savepoint针对实际业务场景做了优化
- Flink state查询
32、消费kafka数据的时候,如何处理脏数据?
可以在处理前加一个fliter算子,将不符合规则的数据过滤出去。
Window
Flink 中 Window 可以将无限流切分成有限流,是处理有限流的核心组件,现在Flink 中 Window 可以是时间驱动的(Time Window),也可以是数据驱动的(Count Window)
一共有四种窗口类型,可以根据业务环境使用不同的窗口
- tumbling window(滚动窗口):窗口间的元素无重复,翻滚窗具有固定的尺寸,不重叠。
- sliding window(滑动窗口):窗口间的元素可能重复,
该滑动窗口分配器分配元件以固定长度的窗口。与翻滚窗口分配器类似,窗口大小由窗口大小参数配置。附加的窗口滑动参数控制滑动窗口的启动频率。因此,如果幻灯片小于窗口大小,则滑动窗口可以重叠。在这种情况下,数据元被分配给多个窗口。 - session window(会话窗口)
在会话窗口中按活动会话分配器组中的数据元。与翻滚窗口和滑动窗口相比,会话窗口不重叠并且没有固定的开始和结束时间。相反,当会话窗口在一段时间内没有接收到数据元时,即当发生不活动的间隙时,会关闭会话窗口。 - global window(全局窗口)
一个全局性的窗口分配器分配使用相同的Keys相同的单个的所有数据元全局窗口。
Checkpoint容错机制
Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator/task的状态来生成一个轻量级的分布式快照,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。
Savepoint保存点
Savepoint 是命令触发的 Checkpoint,对流式程序做一次完整的快照并将结果写到 State backend,可用于停止、恢复或更新 Flink 程序。整个过程依赖于 Checkpoint 机制。另一个不同之处是,Savepoint 不会自动清除。
Sqoop
Sqoop 导入导出 Null 存储一致性问题
Hive 中的 Null 在底层是以“\N”来存储,而 MySQL 中的 Null 在底层就是 Null,为了
保证数据两端的一致性。在导出数据时采用–input-null-string 和–input-null-non-string 两个参
数。导入数据时采用–null-string 和–null-non-string。
Sqoop 数据导出一致性问题
1)场景 1:如 Sqoop 在导出到 Mysql 时,使用 4 个 Map 任务,过程中有 2 个任务失败,
那此时 MySQL 中存储了另外两个 Map 任务导入的数据,此时老板正好看到了这个报表数
据。而开发工程师发现任务失败后,会调试问题并最终将全部数据正确的导入 MySQL,那
后面老板再次看报表数据, 发现本次看到的数据与之前的不一致,这在生产环境是不允许的。
2)场景 2:设置 map 数量为 1 个(不推荐,面试官想要的答案不只这个)
多个 Map 任务时,采用–staging-table 方式, 仍然可以解决数据一致性问题。
Sqoop 底层运行的任务是什么
只有 Map 阶段,没有 Reduce 阶段的任务。
Sqoop 数据导出的时候一次执行多长时间
Sqoop 任务 5 分钟-2 个小时的都有。 取决于数据量。
Zookeeper
说说zookeeper是什么?
ZooKeeper 是一个开源的分布式协调服务。它是一个为分布式应用提供一致性服务的软件,分布式应用程序可以基于 Zookeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
ZooKeeper 的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
广播模式
一旦 leader 已经和多数的 follower 进行了状态同步后,它就可以开始广播消息了,即进入广播状态。这时候当一个 server 加入 ZooKeeper 服务中,它会在恢复模式下启动,发现 leader,并和 leader 进行状态同步。待到同步结束,它也参与消息广播。ZooKeeper 服务一直维持在 Broadcast 状态,直到 leader 崩溃了或者 leader 失去了大部分的 followers 支持。
ZooKeeper 提供了什么?
- 文件系统
- 通知机制
Kafka
1.Kafka 的设计时什么样的呢?
Kafka 将消息以 topic 为单位进行归纳
将向 Kafka topic 发布消息的程序成为 producers.
将预订 topics 并消费消息的程序成为 consumer.
Kafka 以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个 broker.
producers 通过网络将消息发送到 Kafka 集群,集群向消费者提供消息
2.数据传输的事物定义有哪三种?
(1)最多一次: 消息不会被重复发送,最多被传输一次,但也有可能一次不传输
(2)最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输.
(3)精确的一次(Exactly once): 不会漏传输也不会重复传输,每个消息都传输被一次而且仅仅被传输一次,这是大家所期望的
3.Kafka 判断一个节点是否还活着有那两个条件?
(1)节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每个节点的连接
(2)如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太久
4.producer 是否直接将数据发送到 broker 的 leader(主节点)?
producer 直接将数据发送到 broker 的 leader(主节点),不需要在多个节点进行分发,为了帮助 producer 做到这点,所有的 Kafka 节点都可以及时的告知:哪些节点是活动的,目标topic 目标分区的 leader 在哪。这样 producer 就可以直接将消息发送到目的地了
5、Kafa consumer 是否可以消费指定分区消息?
Kafa consumer 消费消息时,向 broker 发出"fetch"请求去消费特定分区的消息,consumer指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer 拥有了 offset 的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的
9.Kafka 与传统消息系统之间有三个关键区别
(1).Kafka 持久化日志,这些日志可以被重复读取和无限期保留
(2).Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据提升容错能力和高可用性
(3).Kafka 支持实时的流式处理
14.Kafka 的消费者如何消费数据
消费者每次消费数据的时候,消费者都会记录消费的物理偏移量(offset)的位置等到下次消费时,他会接着上次位置继续消费
15.消费者负载均衡策略
一个消费者组中的一个分片对应一个消费者成员,他能保证每个消费者成员都能访问,如果组中成员太多会有空闲的成员
16.数据有序
一个消费者组里它的内部是有序的
消费者组与消费者组之间是无序的
17.kafaka 生产数据时数据的分组策略
生产者决定数据产生到集群的哪个 partition 中
每一条消息都是以(key,value)格式
Key 是由生产者发送数据传入
所以生产者(key)决定了数据产生到集群的哪个 partition
flume
1.Flume 采集数据会丢失吗?
不会,Channel 存储可以存储在 File 中,数据传输自身有事务。
2.Flume 与 Kafka 的选取?
采集层主要可以使用 Flume、Kafka 两种技术。
Flume:Flume 是管道流方式,提供了很多的默认实现,让用户通过参数部署,及扩展 API。
Kafka:Kafka 是一个可持久化的分布式的消息队列。3.数据怎么采集到 Kafka,实现方式?
3.数据怎么采集到 Kafka,实现方式?
使用官方提供的 flumeKafka 插件,插件的实现方式是自定义了 flume 的 sink,将数据从channle 中取出,通过 kafka 的producer 写入到 kafka 中,可以自定义分区等。
4.flume 管道内存,flume 宕机了数据丢失怎么解决?
1)Flume 的 channel 分为很多种,可以将数据写入到文件。
2)防止非首个 agent 宕机的方法数可以做集群或者主备
5.flume 和 kafka 采集日志区别,采集日志时中间停了,怎么记录之前的日志?
Flume 采集日志是通过流的方式直接将日志收集到存储层,而 kafka 是将缓存在 kafka集群,待后期可以采集到存储层。
Flume 采集中间停了,可以采用文件的方式记录之前的日志,而 kafka 是采用 offset 的方式记录之前的日志。
flume 调优
source :
1 ,增加 source 个数,可以增大 source 读取能力。
2 ,具体做法 : 如果一个目录下生成的文件过多,可以将它拆分成多个目录。每个目录都配置一个 source 。
3 ,增大 batchSize : 可以增大一次性批处理的 event 条数,适当调大这个参数,可以调高 source 搬运数据到 channel 的性能。
channel :
1 ,memory :性能好,但是,如果发生意外,可能丢失数据。
2 ,使用 file channel 时,dataDirs 配置多个不同盘下的目录可以提高性能。
3 ,transactionCapacity 需要大于 source 和 sink 的 batchSize 参数
sink :
增加 sink 个数可以增加消费 event 能力
在使用flume具体做了哪些配置
#配置一个agent,agent的名称可以自定义(如a1)
#指定agent的sources(如s1)、sinks(如k1)、channels(如c1)
#分别指定agent的sources,sinks,channels的名称 名称可以自定义
a1.sources = s1
a1.sinks = k1
a1.channels = c1
#描述source
#配置目录scource
a1.sources.s1.type =spooldir
a1.sources.s1.spoolDir =/home/hadoop/logs
a1.sources.s1.fileHeader= true
a1.sources.s1.channels =c1
#配置sink
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
#配置channel(内存做缓存)
a1.channels.c1.type = memory
Oozie
在项目中,对Oozie做了哪些具体配置
1、oozie.processing.timezone
解释:更改时间为东八区的时间
参数:GMT+0800
linux:
查看时间:date -R
参数:
+0800:代表东八区
-400:代表西四区
GMT:格林尼治时间
2、oozie.action.max.output.data
解释:输出的数据字节数量
值:20480
报错:Output data exceeds its limit
3、oozie.service.coord.check.maximum.frequency
解释:设置定时调度频次大小(true的情况下,频次不能低于5分钟)
值:false
4、更改hue的时间戳
Asia/Shanghai
5、oozie.service.LiteWorkflowStoreService.user.retry.max
解释:workflow失败后,重试次数
值:20(默认是3)
6、oozie.service.LiteWorkflowStoreService.user.retry.inteval
解释:工作流操作的自动重试时间间隔为分钟,默认值为10分钟。
值:10
7、oozie.service.CallableQueueService.callable.concurrency
解释:给定可调用类型的最大并发性
每个命令都是可调用的类型(提交,启动,运行,信号,作业,作业,挂起,恢复等)。
每个动作类型都是可调用类型(Map-Reduce,Pig,SSH,FS,子工作流等)。
所有使用动作执行者的命令(action-start,action-end,action-kill和action-check)都会使用作为可调用类型的动作类型。
值:200(默认是3)
8、oozie.action.retries.max
解释:oozie对action节点调度过程中的瞬态错误会有重试机制
值:20(默认是3)
9、oozie.command.default.lock.timeout
解释:获取对一个实体的独占锁的超时时间
值:5000(毫秒)
10、oozie.email.smtp.socket.timeout.ms
解释:在电子邮件操作期间完成所有SMTP服务器套接字操作的超时。
值:10000(毫秒)
11、oozie.notification.url.connection.timeout
解释:定义Oozie HTTP通知回调的超时时间(以毫秒为单位)
值:10000(毫秒)
12、oozie.service.coord.default.max.timeout
解释:coordinator操作输入检查的默认最大超时(以分钟为单位)。
值:86400 = 60天
13、oozie.service.coord.normal.default.timeout
解释:正常job的coordinator操作输入检查的默认超时(分钟)。-1表示无限超时
值:120
数仓
数仓为什么要分层
清晰数据结构:
每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
方便数据血缘追踪:
简单来说,我们最终给业务呈现的是一个能直接使用业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
减少重复开发:
规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
把复杂问题简单化:
将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
屏蔽原始数据的异常:
屏蔽业务的影响,不必改一次业务就需要重新接入数据
拉链表
拉链表就是随着时间变迁产生历史数据。
拉链表的含义:就是记录历史。记录一个事务从开始一直到当前状态的所有变化信息。
数仓构建流程
1.需求分析(客户访谈和调查问卷)
2.逻辑分析 (处理逻辑分析,支撑数据分析,业务元数据建立)
3.ods建模(逻辑模型:逻辑结构、存储粒度、存储周期。物理模型:数据的存储结构,索引策略、数据存放位置,存储分配,分区设计)
4.数据仓库建模(数据的存储结构,索引策略,数据存放位置,存储分配,分区设计)
5.数据源分析(数据源的范围、格式、更新频率、数据量和数据质量)
6.数据获取和整合(直接抽取,web服务和数据收集工具,文件收集,数据的整合)
7.应用分析(分析方法、预定义表表、即席查询、数据挖掘)
8.数据展现(汇报文案、报表、图形)
9.性能调优(优化指标,优化步骤,优化系统)
10.元数据管理()
谈谈你对数仓的理解
数据仓库(Data Warehouse)简称 DW 或 DWH,是数据库的一种概念上的升级,可以说是为满足新需求设计上的一种新数据库,而这个数据库是需容纳更多的数据,更加庞大的数据集, 从逻辑上讲数据仓库和数据库没有什么区别的。
ods,dwd,dws层如何建模
ODS:操作型数据(Operational Data Store),指结构与源系统基本保持一致的增量或者全量数据。
DWD:数据仓库明细层数据(Data Warehouse Detail)。对ODS层数据进行清洗转化,以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细事实表。
DWS:数据仓库汇总层数据(Data Warehouse Summary),基于指标需求,构建初步汇总事实表,一般是宽表。基于上层的应用和产品的指标需求,构建公共粒度的汇总指标表。以宽表化手段物理化模型,构建命名规范、口径一致的统计指标,为上层提供公共指标。
DIM:建立一致数据分析维表,可以降低数据计算口径不统一的风险,同时可以方便进行交叉探查。以维度作为建模驱动,基于每个维度的业务含义,通过添加维度属性、关联维度等定义计算逻辑,完成属性定义的过程并建立一致的数据分析维表。
ADS:面向应用的数据服务层(Application Data Service)。整合汇总成分析某一个主题域的服务数据,面向应用逻辑的数据加工。
分区,分桶区别,分桶底层怎么实现的?
1)从表现形式上:
分区表是一个目录,分桶表是文件
(2)从创建语句上:
分区表使用partitioned by 子句指定,以指定字段为伪列,需要指定字段类型
分桶表由clustered by 子句指定,指定字段为真实字段,需要指定桶的个数
(3)从数量上:
分区表的分区个数可以增长,分桶表一旦指定,不能再增长
(4)从作用上:
分区避免全表扫描,根据分区列查询指定目录提高查询速度
分桶保存分桶查询结果的分桶结构(数据已经按照分桶字段进行了hash散列)。
分桶表数据进行抽样和JOIN时可以提高MR程序效率
dwd层 为什么要用 paurate存储和snappy 压缩
Parquet是为了使Hadoop生态系统中的任何项目都可以使用压缩的,高效的列式数据表示形式
Snappy的压缩速度非常快
流处理
流式处理常见方法有哪些
定长记录
定义每个记录的固定长度。读方读取到了固定的长度之后,即认为获得了完整数据,每读取固定长度之后,就认定为获取了完整数据。
变长记录+分隔符
记录长度不固定,定义一个符号作为记录的分隔符,并在每个记录中间插入该符号来界定记录边界。
定长长度+变长记录
定义一个固定长度的块来作为记录头,该记录头用来存放后面记录的长度。记录头后始终跟着该块描述的长度的记录;每个记录头的长度都是固定的。
读方读取了记录头获取了记录长度,再读取对应长度的数据获得完整数据。
TLV格式
基于定长长度+边长记录的方式,多加了一个类型字段。这样读方就可以根据不同类型的记录做不同的处理逻辑。
Sql
五张十亿数据表join很慢,如何优化?
1.提高集群配置
2.方案2.双表hash 再join,join完以后在union
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
sql中join有哪几种
left join:会保全左表数据,如果右表没相关数据,会显示null
right join:会保全右表数据,如果左表没相关数据,会显示null
inner join:部分主从表,结果会取两个表针对on条件相匹配的最小集
cross join:交叉连接,也称为笛卡尔积,查询返回结果的行数等于两个表行数的乘积
full join:全外连接其实是左连接和右连接的一个合集,也就是说他会查询出左表和右表的全部数据,匹配不上的会显示为null
项目
物流数仓
广告实时流
据分析维表,可以降低数据计算口径不统一的风险,同时可以方便进行交叉探查。以维度作为建模驱动,基于每个维度的业务含义,通过添加维度属性、关联维度等定义计算逻辑,完成属性定义的过程并建立一致的数据分析维表。
ADS:面向应用的数据服务层(Application Data Service)。整合汇总成分析某一个主题域的服务数据,面向应用逻辑的数据加工。
分区,分桶区别,分桶底层怎么实现的?
1)从表现形式上:
分区表是一个目录,分桶表是文件
(2)从创建语句上:
分区表使用partitioned by 子句指定,以指定字段为伪列,需要指定字段类型
分桶表由clustered by 子句指定,指定字段为真实字段,需要指定桶的个数
(3)从数量上:
分区表的分区个数可以增长,分桶表一旦指定,不能再增长
(4)从作用上:
分区避免全表扫描,根据分区列查询指定目录提高查询速度
分桶保存分桶查询结果的分桶结构(数据已经按照分桶字段进行了hash散列)。
分桶表数据进行抽样和JOIN时可以提高MR程序效率
dwd层 为什么要用 paurate存储和snappy 压缩
Parquet是为了使Hadoop生态系统中的任何项目都可以使用压缩的,高效的列式数据表示形式
Snappy的压缩速度非常快
流处理
流式处理常见方法有哪些
定长记录
定义每个记录的固定长度。读方读取到了固定的长度之后,即认为获得了完整数据,每读取固定长度之后,就认定为获取了完整数据。
变长记录+分隔符
记录长度不固定,定义一个符号作为记录的分隔符,并在每个记录中间插入该符号来界定记录边界。
定长长度+变长记录
定义一个固定长度的块来作为记录头,该记录头用来存放后面记录的长度。记录头后始终跟着该块描述的长度的记录;每个记录头的长度都是固定的。
读方读取了记录头获取了记录长度,再读取对应长度的数据获得完整数据。
TLV格式
基于定长长度+边长记录的方式,多加了一个类型字段。这样读方就可以根据不同类型的记录做不同的处理逻辑。
Sql
五张十亿数据表join很慢,如何优化?
1.提高集群配置
2.方案2.双表hash 再join,join完以后在union
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
sql中join有哪几种
left join:会保全左表数据,如果右表没相关数据,会显示null
right join:会保全右表数据,如果左表没相关数据,会显示null
inner join:部分主从表,结果会取两个表针对on条件相匹配的最小集
cross join:交叉连接,也称为笛卡尔积,查询返回结果的行数等于两个表行数的乘积
full join:全外连接其实是左连接和右连接的一个合集,也就是说他会查询出左表和右表的全部数据,匹配不上的会显示为null















 2184
2184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









