







大模型推理优化原理及实现步骤细节研究,持续更新。。。。
一、大模型为什么要进行推理优化?
大模型在实际应用中,通常需要在有限的硬件资源和严格的延迟要求下运行。为了满足这些需求,必须对大模型的推理过程进行优化。以下是大模型推理优化的主要原因及其重要性:
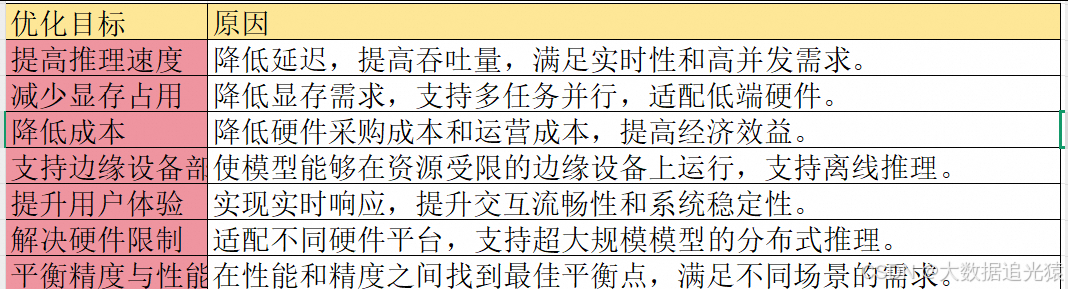
1. 提高推理速度
(1)降低延迟
大模型的计算复杂度较高,直接运行可能导致推理延迟过长,无法满足实时应用场景(如对话系统、推荐系统)的需求。
通过优化(如量化、剪枝、缓存),可以显著减少推理时间。
(2)提高吞吐量
在服务端部署时,优化后的模型能够处理更多的并发请求,提升系统的整体吞吐量。
2. 减少显存占用
(1)降低显存需求
大模型通常需要大量的显存来存储权重和中间计算结果。例如,Qwen-1.8B 模型可能需要数十 GB 的显存。
通过量化(如 FP16/INT8)、剪枝等技术,可以大幅减少显存占用,使模型能够在更小的硬件上运行。
(2)支持多任务并行
显存优化后,可以在同一设备上同时运行多个模型或任务,提高资源利用率。
3. 降低成本
(1)硬件成本
高性能 GPU/TPU 硬件价格昂贵,优化后的模型可以在低端硬件上运行,从而降低硬件采购成本。
例如,通过 INT8 量化,模型可以在边缘设备(如手机、嵌入式设备)上运行,无需依赖云端服务器。
(2)运营成本
推理优化可以减少能源消耗和云服务费用(如 GPU 实例租赁费用)。
4. 支持边缘设备部署
(1)轻量化模型
边缘设备(如手机、IoT 设备)通常资源有限,无法直接运行大模型。
通过蒸馏、量化、剪枝等技术,将大模型压缩为轻量化版本,使其适合边缘设备。
(2)离线推理
优化后的模型可以在没有网络连接的情况下运行,适用于自动驾驶、智能家居等场景。
5. 提升用户体验
(1)实时响应
用户对交互式应用(如聊天机器人、语音助手)有极高的实时性要求。优化后的模型能够快速响应用户输入,提升用户体验。
(2)稳定性
优化后的模型运行更加稳定,减少了因资源不足导致的服务中断或卡顿问题。
6. 解决硬件限制
(1)适配不同硬件平台
不同硬件平台(如 CPU、GPU、TPU、NPU)对模型的支持能力不同。通过优化,可以使模型更好地适配目标硬件。
例如,NVIDIA GPU 对 FP16 和 INT8 有良好的加速支持,而 Intel CPU 更适合 BF16 和 INT8。
(2)分布式推理
超大规模模型可能无法在单个设备上运行,优化技术(如模型并行、张量并行)可以将模型分布到多个设备上。
7. 平衡精度与性能
(1)最小化精度损失
优化技术(如量化、剪枝)可能会导致模型精度下降,但通过微调和校准,可以在性能和精度之间取得平衡。
(2)动态调整
根据应用场景的需求,动态选择不同的优化策略。例如,在高精度场景下使用 FP16,在低延迟场景下使用 INT8。
8. 总结
二、大模型推理优化方案总结
1. 模型量化
1.1 FP16 / BF16
描述:将模型权重从 FP32 转换为 FP16(半精度浮点数)或 BF16(脑浮点数),减少显存占用和计算量。
优点:
减少显存需求约 50%。
提高 GPU 的计算效率(如 NVIDIA Tensor Core 支持 FP16 加速)。
工具:
(1)PyTorch:torch.cuda.amp。
- FP16 量化代码实现:
FP16 是最常用的低精度格式,特别适合 NVIDIA GPU 的 Tensor Core 加速。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1.8B")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-1.8B")
# 将模型移动到 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 使用 FP16 自动混合精度
from torch.cuda.amp import autocast
# 输入文本
input_text = "Hello, world!"
inputs = tokenizer(input_text, return_tensors="pt").to(device)
# 启用 FP16 推理
with autocast():
outputs = model.generate(**inputs, max_length=50)
# 解码生成的文本
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
关键点:
autocast():自动将计算切换到 FP16。
model.half():可选地将模型权重转换为 FP16 格式(适用于训练和推理)。
- BF16 量化
BF16 是一种更适合 TPU 和部分 CPU 的低精度格式,动态范围接近 FP32。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1.8B")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-1.8B")
# 将模型移动到支持 BF16 的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 使用 BF16 自动混合精度
from torch.cuda.amp import autocast
# 输入文本
input_text = "Hello, world!"
inputs = tokenizer(input_text, return_tensors="pt").to(device)
# 启用 BF16 推理
with autocast(dtype=torch.bfloat16):
outputs = model.generate(**inputs, max_length=50)
# 解码生成的文本
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
关键点:
dtype=torch.bfloat16:指定使用 BF16 数据类型。
需要硬件支持(如 Intel CPU 或 NVIDIA Ampere 架构 GPU)。
(2)TensorFlow:t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









