






目录
最近项目做到根据订单生成pdf合同。要求像阿里云的合同一样,有骑缝章,并且合同末尾处要进行盖章。为了做出这个功能搜集了很多博主的内容,最后终于做出了。现在做一个从头到尾的详细总结,也供大家参考一下,免得向我一样搜罗太多资料,浪费时间。废话不多说 直接开始上代码。第一次写博客,可能有表达的不好的地方,望见谅。不明白的可以私信,看到了尽量解答。
涉及的依赖如下:
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.13</version>
</dependency>
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext-asian</artifactId>
<version>5.2.0</version>
</dependency>
<dependency>
<groupId>com.itextpdf.tool</groupId>
<artifactId>xmlworker</artifactId>
<version>5.5.13</version>
</dependency>
<dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>fr.opensagres.poi.xwpf.converter.pdf-gae</artifactId>
<version>2.0.1</version>
</dependency>涉及的jar包链接:私我
核心步骤和代码如下:
1、准备一个word格式的模板
主要内容如下:

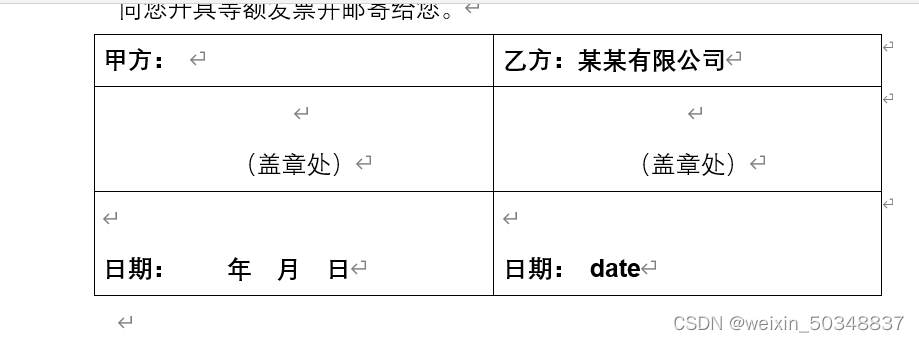
2、生成和同类
/**
* @Description:获取合同,保存云端
* @Date: 2021/12/8 15:46
* @Param orderInfos: 订单信息
* @Param contInfo: 合同信息
* @return: java.lang.String 返回云端地址
**/
private String makeCont(List<OrderInfo> orderInfos, ContInfo contInfo) throws Exception {
String urlPath;
String id = contInfo.getContFileName();// 合同ID
String contractPath = System.getProperty("user.dir") + "/website/cont/templet/";
//获取合同信息
Map<String, String> replaceMap = getReplaceMap(contInfo, orderInfos);
String userId = replaceMap.get("userId");
StringBuilder destPathDOCX = new StringBuilder(contractPath).append(userId); //合同信息填充后的保存路径
// 判断用户文件夹是否存在,不存在则新建
File userNumFile = new File(destPathDOCX.toString());
if (!userNumFile.exists()) {
userNumFile.mkdirs();
}
destPathDOCX.append(File.separator).append(userId).append(".docx");
Map<String, String> replaceTableMap = new HashMap<String, String>();
replaceTableMap.put("totalAmount", replaceMap.remove("totalAmount"));
replaceTableMap.put("date", replaceMap.remove("date"));
replaceTableMap.put("totalCapitalizeAmount", replaceMap.remove("totalCapitalizeAmount"));
// 替换合同里面的参数
WordUtil.replaceAndGenerateWord(contractPath + "templet.docx", destPathDOCX.toString(), replaceMap, replaceTableMap);
//更新合同中的产品服务信息
updateContTableInfo(destPathDOCX.toString(), orderInfos);
//设置转换后pdf文件的保存路径
StringBuilder pdfFile = new StringBuilder(contractPath).append(userId).append(File.separator).append(id).append(".pdf");
// 将word转pdf文件
Boolean bool = WordUtil.wordConverterToPdf(destPathDOCX.toString(), pdfFile.toString());
//盖章
InputStream inputStream = new FileInputStream(pdfFile.toString());
PdfUtil.itextPDFAddPicture(inputStream, pdfFile.toString());
//将盖章后的pdf文档保存到云端
urlPath = aliyunOSS.uploadFile("files/contract/", id + ".pdf", new File(pdfFile.toString()));
// 删除word电子合同
File fileDOCX = new File(destPathDOCX.toString());
if (fileDOCX.exists()) {
fileDOCX.delete();
}
//删除pdf电子合同
File filePdf = new File(pdfFile.toString());
if (filePdf.exists()) {
filePdf.delete();
}
return urlPath;
}
3、word工具类
package com.tantela.util.contutil;
import java.io.*;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import com.aspose.words.License;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFRun;
import org.apache.poi.xwpf.usermodel.XWPFTable;
import org.apache.poi.xwpf.usermodel.XWPFTableCell;
import org.apache.poi.xwpf.usermodel.XWPFTableRow;
import com.aliyuncs.utils.StringUtils;
/**
* @ClassName:WordUtil
* @Description:操作word文档工具类
* @Version:V1.0
* @Date:2021/12/7 13:53:32
*/
public class WordUtil {
/**
* @Description:替换word中需要替换的特殊字符
* @Date: 2021/12/7 16:59
* @Param srcPath: 需要替换的文档全路径
* @Param exportFile: 替换后文档的保存路径
* @Param contentMap: {key:将要被替换的内容,value:替换后的内容}
* @Param replaceTableMap: {key:将要被替换的表格内容,value:替换后的表格内容}
* @return: boolean 返回成功状态
**/
public static boolean replaceAndGenerateWord(String srcPath, String exportFile, Map<String, String> contentMap, Map<String, String> replaceTableMap) throws IOException {
boolean bool = true;
FileInputStream inputStream = new FileInputStream(srcPath);
XWPFDocument document = new XWPFDocument(inputStream);
// 替换段落中的指定文字
Iterator<XWPFParagraph> itPara = document.getParagraphsIterator();
while (itPara.hasNext()) {
XWPFParagraph paragraph = itPara.next();
commonCode(paragraph, contentMap);
}
// 替换表格中的指定文字
Iterator<XWPFTable> itTable = document.getTablesIterator();
while (itTable.hasNext()) {
XWPFTable table = itTable.next();
int rcount = table.getNumberOfRows();
for (int i = 0; i < rcount; i++) {
XWPFTableRow row = table.getRow(i);
List<XWPFTableCell> cells = row.getTableCells();
for (XWPFTableCell cell : cells) {
//单元格中有段落,得做段落处理
List<XWPFParagraph> paragraphs = cell.getParagraphs();
for (XWPFParagraph paragraph : paragraphs) {
commonCode(paragraph, replaceTableMap);
}
}
}
}
FileOutputStream outStream = new FileOutputStream(exportFile);
document.write(outStream);
outStream.close();
inputStream.close();
return bool;
}
/**
* @Description:替换内容
* @Date: 2021/12/7 16:56
* @Param paragraph: 被替换的文本信息
* @Param contentMap: {key:将要被替换的内容,value:替换后的内容}
* @return: void
**/
private static void commonCode(XWPFParagraph paragraph,Map<String, String> contentMap){
List<XWPFRun> runs = paragraph.getRuns();
for (XWPFRun run : runs) {
String oneparaString = run.getText(run.getTextPosition());
if (StringUtils.isEmpty(oneparaString)){
continue;
}
for (Map.Entry<String, String> entry : contentMap.entrySet()) {
oneparaString = oneparaString.replace(entry.getKey(), StringUtils.isEmpty(entry.getValue()) ? "--" : entry.getValue());
}
run.setText(oneparaString, 0);
}
}
/**
* @Description:验证license许可凭证
* @Date: 2021/12/7 16:57
* @return: boolean 返回验证License状态
**/
private static boolean getLicense() {
boolean result = true;
try {
String path = System.getProperty("user.dir")+"/website/cont/license.xml";
new License().setLicense(new FileInputStream(new File(path).getAbsolutePath()));
} catch (Exception e) {
result = false;
e.printStackTrace();
}
return result;
}
/**
* @Description:word转pdf
* @Date: 2021/12/7 16:58
* @Param wordPath: word 全路径,包括文件全称
* @Param pdfPath: pdf 保存路径,包括文件全称
* @return: boolean 返回转换状态
**/
public static boolean wordConverterToPdf(String wordPath, String pdfPath) {
boolean bool = false;
// 验证License,若不验证则转化出的pdf文档会有水印产生
if (!getLicense()) return bool;
try {
FileOutputStream os = new FileOutputStream(new File(pdfPath));// 新建一个pdf文档输出流
com.aspose.words.Document doc = new com.aspose.words.Document(wordPath);// Address是将要被转化的word文档
doc.save(os, com.aspose.words.SaveFormat.PDF);// 全面支持DOC, DOCX, OOXML, RTF HTML, OpenDocument, PDF, EPUB, XPS, SWF 相互转换
os.close();
bool = true;
} catch (Exception e) {
e.printStackTrace();
System.out.println("word转PDF转换异常!!");
}
return bool;
}
/**
* @Description: 在word表格中指定位置插入一行,并将某一行的样式复制到新增行
* @Date: 2021/12/7 16:58
* @Param table: 需要插入的表格
* @Param copyrowIndex: 需要复制的行位置
* @Param newrowIndex: 需要新增一行的位置
* @return: void 返回类型
**/
public static void insertRow(XWPFTable table, int copyrowIndex, int newrowIndex) {
// 在表格中指定的位置新增一行
XWPFTableRow targetRow = table.insertNewTableRow(newrowIndex);
// 获取需要复制行对象
XWPFTableRow copyRow = table.getRow(copyrowIndex);
//复制行对象
targetRow.getCtRow().setTrPr(copyRow.getCtRow().getTrPr());
//获取需要复制的行的列
List<XWPFTableCell> copyCells = copyRow.getTableCells();
//复制列对象
XWPFTableCell targetCell = null;
for (int i = 0; i < copyCells.size(); i++) {
XWPFTableCell copyCell = copyCells.get(i);
targetCell = targetRow.addNewTableCell();
targetCell.getCTTc().setTcPr(copyCell.getCTTc().getTcPr());
if (copyCell.getParagraphs() != null && copyCell.getParagraphs().size() > 0) {
targetCell.getParagraphs().get(0).getCTP().setPPr(copyCell.getParagraphs().get(0).getCTP().getPPr());
if (copyCell.getParagraphs().get(0).getRuns() != null
&& copyCell.getParagraphs().get(0).getRuns().size() > 0) {
XWPFRun cellR = targetCell.getParagraphs().get(0).createRun();
cellR.setBold(copyCell.getParagraphs().get(0).getRuns().get(0).isBold());
}
}
}
}
}
4、license.xml内容
<License>
<Data>
<Products>
<Product>Aspose.Total for Java</Product>
<Product>Aspose.Words for Java</Product>
</Products>
<EditionType>Enterprise</EditionType>
<SubscriptionExpiry>20991231</SubscriptionExpiry>
<LicenseExpiry>20991231</LicenseExpiry>
<SerialNumber>8bfe198c-7f0c-4ef8-8ff0-acc3237bf0d7</SerialNumber>
</Data>
<Signature>sNLLKGMUdF0r8O1kKilWAGdgfs2BvJb/2Xp8p5iuDVfZXmhppo+d0Ran1P9TKdjV4ABwAgKXxJ3jcQTqE/2IRfqwnPf8itN8aFZlV3TJPYeD3yWE7IT55Gz6EijUpC7aKeoohTb4w2fpox58wWoF3SNp6sK6jDfiAUGEHYJ9pjU=</Signature>
</License>
5、pdf工具类
package com.tantela.util.contutil;
import com.itextpdf.awt.geom.Rectangle2D;
import com.itextpdf.text.Image;
import com.itextpdf.text.Rectangle;
import com.itextpdf.text.pdf.PdfContentByte;
import com.itextpdf.text.pdf.PdfReader;
import com.itextpdf.text.pdf.PdfStamper;
import com.itextpdf.text.pdf.parser.PdfReaderContentParser;
import com.tantela.model.wyqiang.filemanage.contfile.ContInfo;
import com.tantela.model.ygc.order.OrderInfo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.*;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @ClassName:CreateContPdf
* @Description:建立PDF合同
* @Version:V1.0
* @Date:2021/12/7 15:00:59
*/
public class PdfUtil {
/**
* @param inputStream 电子合同pdf文件流
* @param targetPath 保存路径
* @throws Exception 异常参数
* @Title: itextPDFAddPicture
* @Description: 为pdf加图片(电子合同盖公章)
*/
public static void itextPDFAddPicture(InputStream inputStream, String targetPath) throws Exception {
// 1.1 读取模板文件
PdfReader reader = new PdfReader(inputStream);
// 1.2 创建文件输出流
FileOutputStream out = new FileOutputStream(targetPath);
// 2、创建PdfStamper对象
PdfStamper stamper = new PdfStamper(reader, out);
// 4、读取公章
String path = System.getProperty("user.dir") + "/website/cont/officialSeal/officialSeal.png";
BufferedImage bufferedImage = ImageIO.read(new FileInputStream(path));// 整个公章图片流
BufferedImage[] imgs = ImageUtil.splitImage(bufferedImage, 1, 2);
BufferedImage leftBufferedImage = imgs[0];// 左边公章图片流
BufferedImage rightBufferedImage = imgs[1];// 右边公章图片流
// 5、读公章图片
Image image = Image.getInstance(ImageUtil.imageToBytes(bufferedImage));
Image leftImage = Image.getInstance(ImageUtil.imageToBytes(leftBufferedImage));
Image rightImage = Image.getInstance(ImageUtil.imageToBytes(rightBufferedImage));
int chunkWidth = 250;// 公章大小,x轴
int chunkHeight = 250;// 公章大小,y轴
// 获取pdf页面的高和宽
Rectangle pageSize = reader.getPageSize(1);
float height = pageSize.getHeight();
float width = pageSize.getWidth();
// 6、为pdf每页加印章
// 设置公章的位置
float xL = width - chunkWidth / 2 - 2;
float yL = height / 2 - chunkHeight / 2 - 280;
float xR = width - chunkHeight / 2 + chunkHeight / 8 + 4;
float yR = yL;
// 6.1 第一页盖左章
leftImage.scaleToFit(chunkWidth, chunkHeight);// 公章大小
leftImage.setAbsolutePosition(xL, yL);// 公章位置
// 6.2 第二页盖右章
rightImage.scaleToFit(chunkWidth, chunkHeight);// 公章大小
rightImage.setAbsolutePosition(xR, yR);// 公章位置
int pdfPages = reader.getNumberOfPages();// pdf页面页码
// 遍历为每页盖左章或右章
for (int i = 1; i <= pdfPages; i++) {
if (i % 2 == 0) {// 盖右章
stamper.getOverContent(i).addImage(rightImage);
} else {// 盖左章
stamper.getOverContent(i).addImage(leftImage);
}
}
// 6.3 最后一页盖公章
image.scaleToFit(chunkWidth, chunkHeight);
//新建一个PDF解析对象
PdfReaderContentParser parser = new PdfReaderContentParser(reader);
Rectangle2D.Float position = getPosition(stamper, reader, "盖章处");
// image.setAbsolutePosition(width/2 + 32, height-chunkHeight -350);
//得到的位置有些许偏差,自行调节
image.setAbsolutePosition(position.x + 150, position.y - 110);
stamper.getOverContent(pdfPages).addImage(image);
// 7、关闭相关流
stamper.close();
out.close();
reader.close();
inputStream.close();
}
/**
* @Description:获取pdf中关键字位置,得到的位置有些许偏差,根据实际显示结果自行调节
* @Date: 2021/12/7 9:53
* @Param stamper:
* @Param reader:
* @Param str:
* @return: com.itextpdf.awt.geom.Rectangle2D.Float
**/
public static Rectangle2D.Float getPosition(PdfStamper stamper, PdfReader reader, String str) throws IOException {
//新建一个PDF解析对象
PdfReaderContentParser parser = new PdfReaderContentParser(reader);
Rectangle2D.Float position = null;
for (int i = 1; i <= reader.getNumberOfPages(); i++) {
PdfContentByte pdfContentByte = stamper.getOverContent(i);
//新建一个ImageRenderListener对象,该对象实现了RenderListener接口,作为处理PDF的主要类
TestRenderListener listener = new TestRenderListener();
//解析PDF,并处理里面的文字
parser.processContent(i, listener);
//获取文字的矩形边框
List<Rectangle2D.Float> rectText = listener.rectText;
List<String> textList = listener.textList;
List<Float> listY = listener.listY;
List<Map<String, Rectangle2D.Float>> list_text = listener.rows_text_rect;
for (String strtext : textList) {
if (strtext.contains(str)) {
int index = textList.indexOf(strtext);
position = rectText.get(index);
}
}
}
return position;
}
}
6、image工具类
package com.tantela.util.contutil;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
/**
* @ClassName:ImageUtil
* @Description:公章图片处理类
* @Version:V1.0
* @Date:2021/12/7 16:16:50
*/
public class ImageUtil {
/**
* @Description:分割图片
* @Date: 2021/12/9 8:34
* @Param image: 图片BufferedImage流
* @Param rows: 分割行
* @Param cols: 分割列
* @return: java.awt.image.BufferedImage[] 返回分割后的图片流
**/
public static BufferedImage[] splitImage(BufferedImage image, int rows, int cols) {
// 分割成4*4(16)个小图
int chunks = rows * cols;
// 计算每个小图的宽度和高度
int chunkWidth = image.getWidth() / cols + 3;// 向右移动3
int chunkHeight = image.getHeight() / rows;
int count = 0;
BufferedImage[] imgs = new BufferedImage[chunks];
for (int x = 0; x < rows; x++) {
for (int y = 0; y < cols; y++) {
//设置小图的大小和类型
imgs[count] = new BufferedImage(chunkWidth, chunkHeight, BufferedImage.TYPE_INT_RGB);
//写入图像内容
Graphics2D gr = imgs[count].createGraphics();
// 增加下面代码使得背景透明
imgs[count] = gr.getDeviceConfiguration().createCompatibleImage(chunkWidth, chunkHeight, Transparency.TRANSLUCENT);
gr.dispose();
gr = imgs[count].createGraphics();
gr.drawImage(image, 0, 0,
chunkWidth, chunkHeight,
chunkWidth * y, chunkHeight * x,
chunkWidth * y + chunkWidth,
chunkHeight * x + chunkHeight, null);
gr.dispose();
count++;
}
}
return imgs;
}
/**
* @Description: 将BufferedImage转换成字节数组
* @Date: 2021/12/6 17:31
* @Param bufferedImage:
* @return: byte[]
**/
public static byte[] imageToBytes(BufferedImage bufferedImage) throws IOException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ImageIO.write( bufferedImage, "png", baos );
baos.flush();
byte[] imageInByte = baos.toByteArray();
baos.close();
return imageInByte;
}
}
7、数字转中文工具类
package com.tantela.util.contutil;
import java.math.BigDecimal;
/**
* @ClassName:NumberTOChinese
* @Description:数字转中文
* @Version:V1.0
* @Date:2021/12/8 10:54:51
*/
public class NumberToChinese {
/**
* 汉语中数字大写
*/
private static final String[] CN_UPPER_NUMBER = { "零", "壹", "贰", "叁", "肆",
"伍", "陆", "柒", "捌", "玖" };
/**
* 汉语中货币单位大写,这样的设计类似于占位符
*/
private static final String[] CN_UPPER_MONETRAY_UNIT = { "分", "角", "元",
"拾", "佰", "仟", "万", "拾", "佰", "仟", "亿", "拾", "佰", "仟", "兆", "拾",
"佰", "仟" };
/**
* 特殊字符:整
*/
private static final String CN_FULL = "整";
/**
* 特殊字符:负
*/
private static final String CN_NEGATIVE = "负";
/**
* 金额的精度,默认值为2
*/
private static final int MONEY_PRECISION = 2;
/**
* 特殊字符:零元整
*/
private static final String CN_ZEOR_FULL = "零元" + CN_FULL;
/**
* @Description: 把输入的金额转换为汉语中人民币的大写
* @Date: 2021/12/8 10:58
* @Param numberOfMoney: 输入的金额
* @return: java.lang.String 对应的汉语大写
**/
public static String toChinese(BigDecimal numberOfMoney) {
StringBuffer sb = new StringBuffer();
// -1, 0, or 1 as the value of this BigDecimal is negative, zero, or
// positive.
int signum = numberOfMoney.signum();
// 零元整的情况
if (signum == 0) {
return CN_ZEOR_FULL;
}
//这里会进行金额的四舍五入
long number = numberOfMoney.movePointRight(MONEY_PRECISION)
.setScale(0, 4).abs().longValue();
// 得到小数点后两位值
long scale = number % 100;
int numUnit = 0;
int numIndex = 0;
boolean getZero = false;
// 判断最后两位数,一共有四中情况:00 = 0, 01 = 1, 10, 11
if (!(scale > 0)) {
numIndex = 2;
number = number / 100;
getZero = true;
}
if ((scale > 0) && (!(scale % 10 > 0))) {
numIndex = 1;
number = number / 10;
getZero = true;
}
int zeroSize = 0;
while (true) {
if (number <= 0) {
break;
}
// 每次获取到最后一个数
numUnit = (int) (number % 10);
if (numUnit > 0) {
if ((numIndex == 9) && (zeroSize >= 3)) {
sb.insert(0, CN_UPPER_MONETRAY_UNIT[6]);
}
if ((numIndex == 13) && (zeroSize >= 3)) {
sb.insert(0, CN_UPPER_MONETRAY_UNIT[10]);
}
sb.insert(0, CN_UPPER_MONETRAY_UNIT[numIndex]);
sb.insert(0, CN_UPPER_NUMBER[numUnit]);
getZero = false;
zeroSize = 0;
} else {
++zeroSize;
if (!(getZero)) {
sb.insert(0, CN_UPPER_NUMBER[numUnit]);
}
if (numIndex == 2) {
if (number > 0) {
sb.insert(0, CN_UPPER_MONETRAY_UNIT[numIndex]);
}
} else if (((numIndex - 2) % 4 == 0) && (number % 1000 > 0)) {
sb.insert(0, CN_UPPER_MONETRAY_UNIT[numIndex]);
}
getZero = true;
}
// 让number每次都去掉最后一个数
number = number / 10;
++numIndex;
}
// 如果signum == -1,则说明输入的数字为负数,就在最前面追加特殊字符:负
if (signum == -1) {
sb.insert(0, CN_NEGATIVE);
}
// 输入的数字小数点后两位为"00"的情况,则要在最后追加特殊字符:整
if (!(scale > 0)) {
sb.append(CN_FULL);
}
return sb.toString();
}
}
8、文字处理类
package com.tantela.util.contutil;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.itextpdf.awt.geom.Rectangle2D;
import com.itextpdf.awt.geom.RectangularShape;
import com.itextpdf.text.pdf.parser.ImageRenderInfo;
import com.itextpdf.text.pdf.parser.RenderListener;
import com.itextpdf.text.pdf.parser.TextRenderInfo;
/**
* @ClassName:TestRenderListener
* @Description:
* @Version:V1.0
* @Date:2021/12/7 09:31:06
*/
public class TestRenderListener implements RenderListener{
//用来存放文字的矩形
List<Rectangle2D.Float> rectText = new ArrayList<Rectangle2D.Float>();
//用来存放文字
List<String> textList = new ArrayList<String>();
//用来存放文字的y坐标
List<Float> listY = new ArrayList<Float>();
//用来存放每一行文字的坐标位置
List<Map<String, Rectangle2D.Float>> rows_text_rect = new ArrayList<Map<String, Rectangle2D.Float>>();
//PDF文件的路径
//protected String filepath = null;
/**
* 文字主要处理方法
*/
@Override
public void renderText(TextRenderInfo renderInfo) {
String text = renderInfo.getText();
if (text.length() > 0) {
RectangularShape rectBase = renderInfo.getBaseline().getBoundingRectange();
//获取文字下面的矩形
Rectangle2D.Float rectAscen = renderInfo.getAscentLine().getBoundingRectange();
//计算出文字的边框矩形
float leftX = (float) rectBase.getMinX();
float leftY = (float) rectBase.getMinY() - 1;
float rightX = (float) rectAscen.getMaxX();
float rightY = (float) rectAscen.getMaxY() + 1;
Rectangle2D.Float rect = new Rectangle2D.Float(leftX, leftY, rightX - leftX, rightY - leftY);
System.out.println("text:" + text + "--x:" + rect.x + "--y:" + rect.y + "--width:" + rect.width + "--height:" + rect.height);
if (listY.contains(rect.y)) {
int index = listY.indexOf(rect.y);
float tempx = rect.x > rectText.get(index).x ? rectText.get(index).x : rect.x;
rectText.set(index, new Rectangle2D.Float(tempx, rect.y, rect.width + rectText.get(index).width, rect.height));
textList.set(index, textList.get(index) + text);
} else {
rectText.add(rect);
textList.add(text);
listY.add(rect.y);
}
Map<String, Rectangle2D.Float> map = new HashMap<String, Rectangle2D.Float>();
map.put(text, rect);
rows_text_rect.add(map);
}
}
}
最终效果截图如下:

参考众多博客内容做出来的,不为盈利,只为方便大家早日做出来。不懂的可以私信,尽量解答。


















 3714
3714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









