







Y. Xu et al., "Towards Developing High Performance RISC-V Processors Using Agile Methodology," 2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO), Chicago, IL, USA, 2022, pp. 1178-1199, doi: 10.1109/MICRO56248.2022.00080.
文章链接:
(自我理解表述,解决方案效果我先不展开,欢迎交流)
这篇文章内容有点多,我先写他提出的方案,具体实现去看原文吧。
楔子:
为了加快芯片开发流程周期,希望使用敏捷开发(好像是从软件那边来的词,软件迭代快,成本低,芯片设计就有很大挑战)。但是由于没有好的开发框架、平台、流程、实例,所以没有被广泛接受,所以文章提出了对应的工具方法作为解决思路和自我论证。
主要问题可以概括为:
1) 缺乏支持敏捷芯片设计的工具链和开发框架,尤其是对于大规模现代处理器。
2) 传统的验证方法不太灵活,成为整个过程的主要瓶颈。
背景(文章解决的部分问题)
- 敏捷开发没有强大的案例支撑(文章使用敏捷开发较快地完成两版“香山”流片)
- 处理器功能验证中参考模型和DUT对应关系的不确定性(文章将一对一简化成N对一,减少对参考模型的维护)
- 验证框架,敏捷开发鼓励维护生成器,可以使用高级语言,除了上一条,还存在高级语言便利和生成代码的准确性的矛盾(文章给出了DiffTest框架)
- 仿真调试过程中,调试信息(波形、日志等)的输出会影响调试效率(就像网络测速永远测不到准确的值)(文章提出轻量级快照 LightSSS方式)
- 性能评估如何既准确又快(文章提出NEMU)
上述具体解决方案分析
基于 Diff-Rule 的敏捷验证 (DRAV)
由于参考模型不是emulator,所以DUT一些基于微架构(硬件随机性?)的情况可能会对应不上,导致误判,如果把这些考虑到参考模型的设计中,就会导致维护成本高,适用性差,而敏捷开发追求快速迭代,不断更新,改参考模型就更费劲了。
因此文章提出把原来一对一的判断(DUT的输出-参考模型的输出)改为N对一(N种DUT输出(正确)-参考模型输出)。这里的N种情况是通过设定diff-rule规则来确定的,保持了一定灵活性。
一对一判断条件是,两者相同即通过;N对一则是,先计算参考模型输出的变种情况,即N种DUT可能的正确输出,再比较实际DUT输出是否在其中,若是集合内元素,则通过验证。
DiffTest:用于 RISC-V 处理器的 DRAV
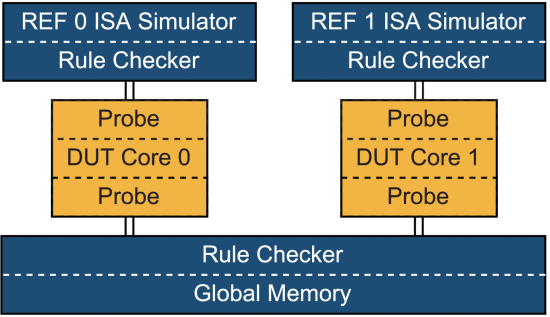
(文献原图)
DiffTest 是一个基于协同仿真的验证框架,它通过采用 DRAV 方法并放宽设计规范中的非关键等效性检查来加速验证收敛。具体来说,DiffTest 提供了添加 diff 规则和动态重新配置参考模型的灵活性,因此具有可扩展性,可同时支持多个设计。(上图应该就是两个设计共用一个规则)
参考模型和DUT协同工作机制如下:每个周期里,通过探针(Probe)获得的DUT输出和Rule Checker进行比较,如果rule只有一条,那就相当于普通的一对一;如果有多条规则且DUT输出符合其中一条,则参考模型也去跑,并进行对比。一旦发生不匹配,检查机制就会识别 DUT 的潜在问题并中止 RTL 仿真。
不确定性的定位
接下去文章介绍了指定diff-rule的关键在于找到哪里会产生不确定性,能找到的场景越多,验证所需的参考模型需要考虑的就越少。因此,可以通过添加更多的diff-rules来不断提高效率。但是,需要平衡 diff 规则的数量与 REF 和框架的设置成本之间的权衡。
同时给出了几个典型的场景(我不展开了,因为我还没太看懂,看原文吧):投机性虚拟地址转换、缓存层次结构和多核场景等等。
信息探针
为了解决高级语言对验证代码可能的破坏,DiffTest使用diff-rule和探针来自动提取所需信息。由于敏捷开发不断变化的特性,传统上的提取信号逻辑就要跟着频繁改,不好。于是使用高级语言将需求封装成探针,只需要定义所需信号包的格式,就能自动生成接口等。在设计阶段将信息探针插入到处理器设计中,并在 RTL 仿真期间提取详细信息。
LightSSS:按需调试
调试信息会降低验证效率,于是提出一种轻量级仿真快照技术,用于在快速模式和调试模式之间按需转换(启用调试信息)。
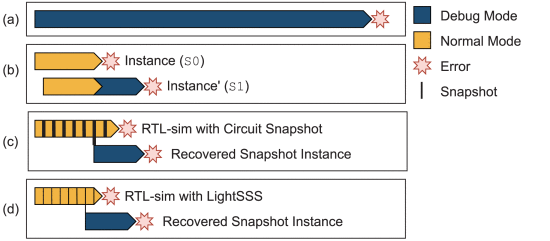
(文献原图,获取调试信息的各种方法。(a) 始终在调试模式下运行 RTL 仿真。(b) 两个 RTL 仿真实例连续运行的方法。(c) 使用电路快照进行 RTL 仿真。(d) 使用 LightSSS 进行 RTL 仿真。) 依次分析
(a) 始终在调试模式下运行 RTL 仿真。很慢。
(b)同时跑两个(开始时间差一点),当一个出现错误,另一个进入调试模式,打开调试信息,当第二个报错的时候就能看到信息了。缺点是需要支持同时跑两个。
(c)加入快照机制,但是是针对电路状态、验证所需信息等,保存成文件。频繁的转储快照会导致严重的性能下降,导致 I/O 或内存面临严重压力。
(d)轻量级快照,即周期性获取快照,只储存独特(和其他快照不同)的地方,和其他快照共享其他状态。由于我们只关心出错前的一段时间,所以只保存最后两个快照周期的快照,出错就重新仿真最后两个周期。同时,不是拍摄仿真电路的快照,而是使用 Linux 内核的系统调用来拍摄 RTL 仿真过程的快照。LightSSS定期从RTL进程中调用 fork(),并将分叉的进程视为快照。当仿真继续且更新时,就用写时复制(Copy-on-Write)来维护快照。这样调用操作系统的方式隔离开了电路实现,降低了开销。
团队做了实验证明,调用fork()所需时间更少&仿真时间几乎不受快照的存在或间隔大小的影响。
NEMU:用于性能评估的快速解释器(图重要,但我没完全理解)
为了实现准确和敏捷的性能评估方法,MINJIE给出了NEMU高性能指令集解释器,不仅对不同插桩和分析任务具有高度灵活性,也可以用作 DiffTest 易于开发的 REF,以减少验证开销(这篇文章里就是用作emulator的,我下一篇写ENCORE: Efficient Architecture Verification Framework with FPGA Acceleration | Proceedings of the 2023 ACM/SIGDA International Symposium on Field Programmable Gate Arrays)。
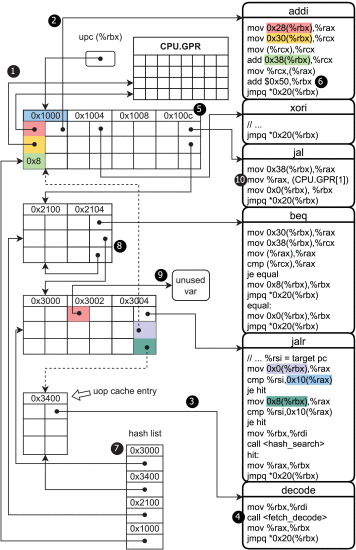
(文献原图,uop 缓存(左)和线程化代码模型(右)。)
显示了 NEMU 的架构。它是一个线程代码解释器,它将所有执行内容(图的右侧部分)内联到执行调度器中。为了实现高性能,NEMU采用了大量的优化技术。
通过 uop cache 优化 Fetch 和 Decode
缓存包含一条指令和这条指令所需数据(➊ 和 ➋),如果未命中,才去取指(fetch)译指(decode)(➌ 和 ➍)。为了减少 uop 缓存未命中的数量,NEMU按照动态指令序列(使用顺序?)来组织 uop 缓存项(➎),从而完全消除冲突遗漏。
因为顺序存的,所以NEMU只需在upc(当作cache的program counter就行)中加1(一个存储区)(➏)就可以获取块内的下一个代码块的缓存条目。对于无条件的间接跳转,使用哈希列表通过目标地址(➐)查询uop缓存条目。对于无条件直接跳转和条件分支,采用区块链技术(不知道是不是这么翻,可以理解成多级索引,先通过哈希表找块,再找条目),比如➑中0x2104 的uop缓存条目(一条 beq 指令)。
写入零寄存器
通过重定向到未使用的变量从而保留零寄存器不被赋值(➒)。
伪指令和压缩指令
对于指令中包含常数(宏定义?本身要做二次翻译?),NEMU 将定义专用的执行例程来内联这些作数(➓)。此技术也可以应用于压缩指令。
浮点指令
主机浮点指令来解释客户机浮点指令(调用 执行NUME的机器 的函数)
检查点的使用(检查点就是设定的跑分指令?)
MINJIE 定义了一种 RISC-V ISA 级架构检查点格式,仅包含基本的 RV64 权限指令。

(文献原图)
在NEMU中计算Basic Block Vector(这个可以去这篇文章里找概念,应该是这个意思checkpoint 学习分析1 —— 1. SimPoint - 松—松 - 博客园)很容易,因为在解释器中收集有关指令的信息非常简单。我们使用选定的检查点对处理器设计进行仿真,并计算每条指令的加权周期数 (CPI) 以进行性能验证。
半总结
MINJIE集成了一组开源工具,通过提出敏捷工具来支持由高级语言实现的设计的功能仿真、软件仿真和基于 FPGA 的原型设计的高效性能建模和验证,以及开发流程每个步骤的调试指标,从而增强传统的验证方法。
当新功能实现时,开发人员只需要启动 RTL 仿真,这些工具就会被自动调用。如果DiffTest没有报告错误,则很有可能在相应的测试用例上设计与设计规范保持一致,并且可以进一步分析性能结果。否则,LightSSS 会提取包括waveform和log在内的调试信息。文章团队开发并开源了更多对 Chisel支持更好的调试工具(ArchDB、Waveform Terminator 等)。开发人员可以使用它们来进一步调查潜在的 bug。
MINJIE 还集成了性能评估工具包,用于自动(nightly咋翻?)性能回归。通过选择具有代表性的检查点,可以显著缩短准确性能验证的结果时间,从而进一步加快高性能处理器的设计空间探索。目前,MINJIE 主要采用基于 RTL 仿真的验证流程,团队认为这本质上是对仿真器和 FPGA 工作流程的补充。
后话
文章后面是对其团队实现的开源高性能处理器“香山”的介绍,可以去看原文,这里先不展开了(放张图好了)
(同时在最后开源了代码GitHub - OpenXiangShan/riscv-gnu-toolchain: GNU toolchain for RISC-V, including GCC以及如何安装使用)
Building An Open-Source High Performance Processor
为了证明MINJIE的有效性,团队使用它来构建一个名为 XIANGSHAN 的高性能 RISC-V 处理器。
(文献原图)

















 3042
3042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









