







日志收集分析平台
完整架构图
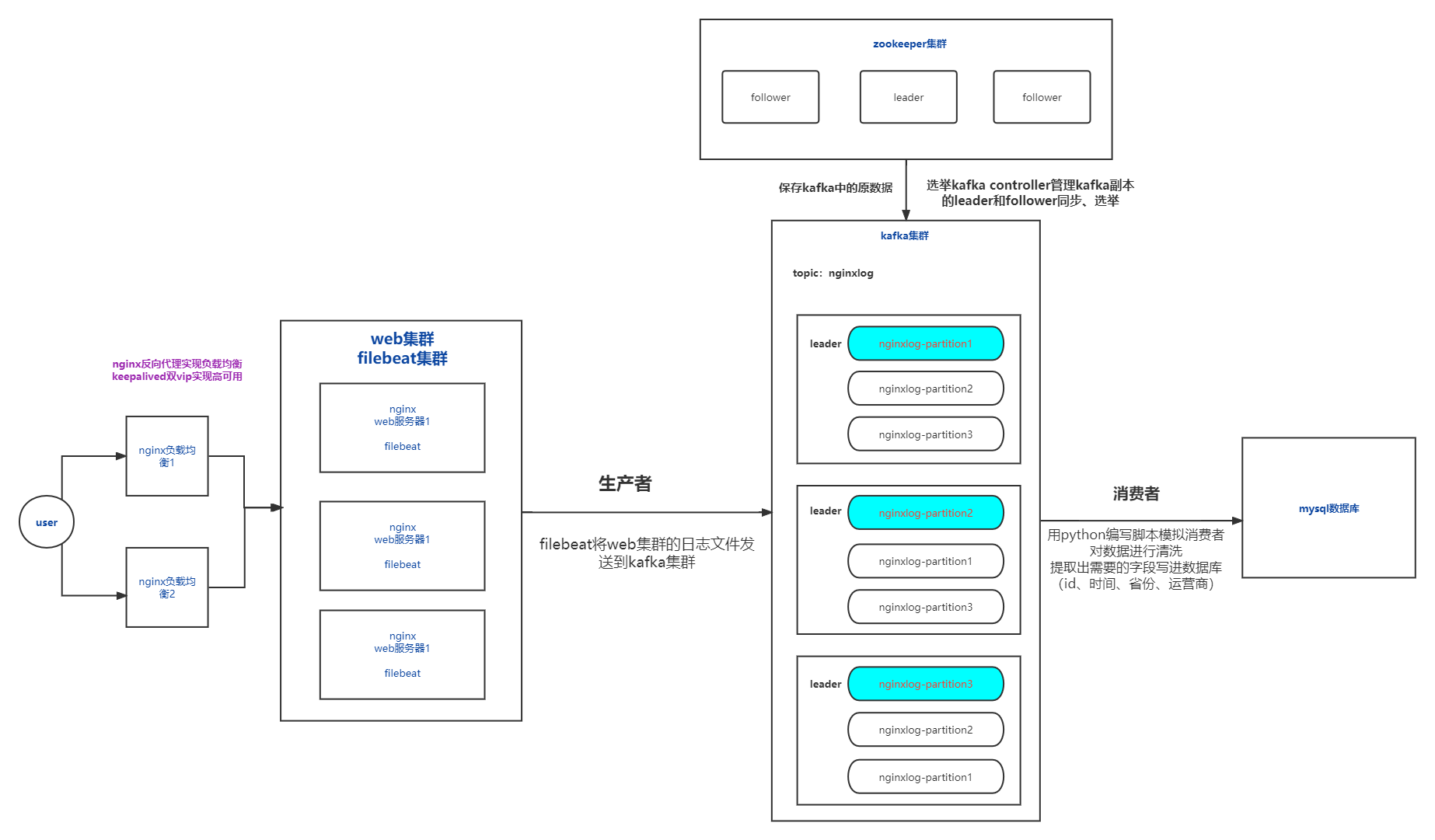
文章目录
一、环境准备
1.准备好3台虚拟机搭建nginx和kafka集群
2.修改三台机器的主机名
# 永久修改主机名 或者也可以选择修改/etc/hostname文件
[root@wh ~]# hostnamestl set-hostname nginx-kafka01
# 重新登录,加载主机名
[root@nginx-kafka01 ~]# su
[root@nginx-kafka02 ~]# hostnamestl set-hostname nginx-kafka02
[root@nginx-kafka03 ~]# hostnamestl set-hostname nginx-kafka03
3.配置ip地址和dns(步骤可参考手工配置ip地址https://blog.csdn.net/weixin_50426379/article/details/125790311?spm=1001.2014.3001.5501)
dhcp动态分配ip地址,重启之后ip地址可能会发生变化,这样导致后面的配置文件里面的ip也要修改,会比较麻烦
[root@nginx-kafka01 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO="none"
NAME="ens33"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.72.130
PREFIX=24
GATEWAY=192.168.72.2
DNS1=114.114.114.114
[root@nginx-kafka02 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO="none"
NAME="ens33"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.72.129
PREFIX=24
GATEWAY=192.168.72.2
DNS1=114.114.114.114
[root@nginx-kafka03 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO="none"
NAME="ens33"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.72.140
PREFIX=24
GATEWAY=192.168.72.2
DNS1=114.114.114.114
[root@nginx-kafka01 ~]# cat /etc/resolv.conf
; generated by /usr/sbin/dhclient-script
search localdomain 168.72.137
nameserver 114.114.114.114
# /etc/resolv.conf 指定本地域名服务器114.114.114.114
4.每台机器上都写好域名解析
[root@nginx-kafka01 ~]# cat /etc/hosts #本地ip和域名的映射关系
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.72.130 nginx-kafka01 # ip 主机名 的格式
192.168.72.129 nginx-kafka02
192.168.72.140 nginx-kafka03
# DNS解析过程:
1. 浏览器的缓存
2. 本地的hosts文件 --linux /etc/hosts
3. 请求本地域名服务器 --linux /etc/resolv.conf
5.每台机器上都安装基本软件
[root@nginx-kafka01 ~]# yum install wget lsof vim -y
6.每台机器上都安装时间同步服务
yum -y install chrony # 安装chrony
systemctl enable chronyd # 设置chrony为开机启动,disable关闭开机自启
systemctl start chronyd # 开启chronyd服务
# 设置时区
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 如果是同一文件就不用复制了
7.关闭防火墙和selinux
[root@nginx-kafka01 ~]# systemctl stop firewalld
[root@nginx-kafka01 ~]# systemctl disable firewalld
# 关闭selinux:
[root@nginx-kafka01 ~]# vim /etc/selinux/config
# 修改下面这行配置
SELINUX=disabled
# selinux关闭 需要重启机器
# selinux 是linux系统内核里一个跟安全相关的子系统
# 规则非常繁琐,一般日常工作里都是关闭的
selinux有三种模式
enforcing 强制模式,必须按照规则
permissive 宽容模式,有的允许,有的不允许
disabled 关闭模式,关闭所有selinu规则
# 查看是否生效
[root@nginx-kafka01 ~]# getenforce
Disabled
二、nginx搭建
1.安装好epel源和nginx:
[root@nginx-kafka01 ~]# yum install epel-release -y
[root@nginx-kafka01 ~]# yum install nginx -y
2.启动nginx
# 启动
[root@nginx-kafka01 ~]# systemctl start nginx
设置开机自启
[root@nginx-kafka01 ~]# systemctl enable nginx
# 查看开机自启的服务
[root@nginx-kafka01 nginx]# cd /etc/systemd/system/multi-user.target.wants/
[root@nginx-kafka01 multi-user.target.wants]# ls
nginx.service
3.编辑配置文件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 8091
8091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









